
최근 내가 만든 서비스인 그라운드 플립의 누적 사용자의 수가 1000명이 넘었다! 1000명이 넘어서 굉장히 기분이 좋았다. 하지만 백엔드 개발자로서 마냥 좋아할 수는 없었다. 사용자가 늘면 그만큼 트래픽도 늘어난다. 이정도의 트래픽을 겪어 본적이 없었기에 여러 문제점이 발생했다… 이 글은 처음으로 많은 트래픽을 받아보고 문제점을 개선해나가는 글이다.
그라운드 플립이란?
우선 그라운드 플립은 어떤 서비스이길래 1000명이나 설치 했을까? 그라운드 플립을 한마디로 소개하자면 땅따먹기 만보기 서비스이다. 단순히 걷는 것에서 끝나지 않고, 걸은 길을 점령할 수 있는 시스템을 제공한다. 내가 걷는 경로가 내 땅이 되고, 다른 사람들이 점령한 영역도 뺏을 수도 있다.
걸으면 걸을수록 점령한 영역이 지도에 표시되고, 다른 사용자와 경쟁하는 재미를 느낄 수 있는 서비스이다. 현재 앱스토어와 플레이스토어에 배포되어 있으니, 언제나 다운로드해서 땅따먹기를 할 수 있다!
[iOS] : https://apps.apple.com/app/ground-flip/id6550922550
[Android] : https://play.google.com/store/apps/details?id=com.m3pro.ground_flip
[랜딩페이지] https://ground-flip2.imweb.me/
문제상황
문재 상황을 소개 하기 앞서 우리 그라운드 플립은 EC2, RDS, ElastiCache 를 사용중이다.
- EC2 : t3.small
- RDS : db.t3.small
- ElastiCache : cache.t2.small
글을 쓰는 시점 누적 가입자 1000명이 이고 어떤 문제가 있었는지 소개해보겠다. 1000명이 넘었을 때 aws의 CloudWatch 를 사용해서 서버에 특이사항은 없었는지 점검하러 갔다. 각종 그래프를 확인했을 때 깜짝 놀랐다. 아래는 그 때 확인한 그래프이다.
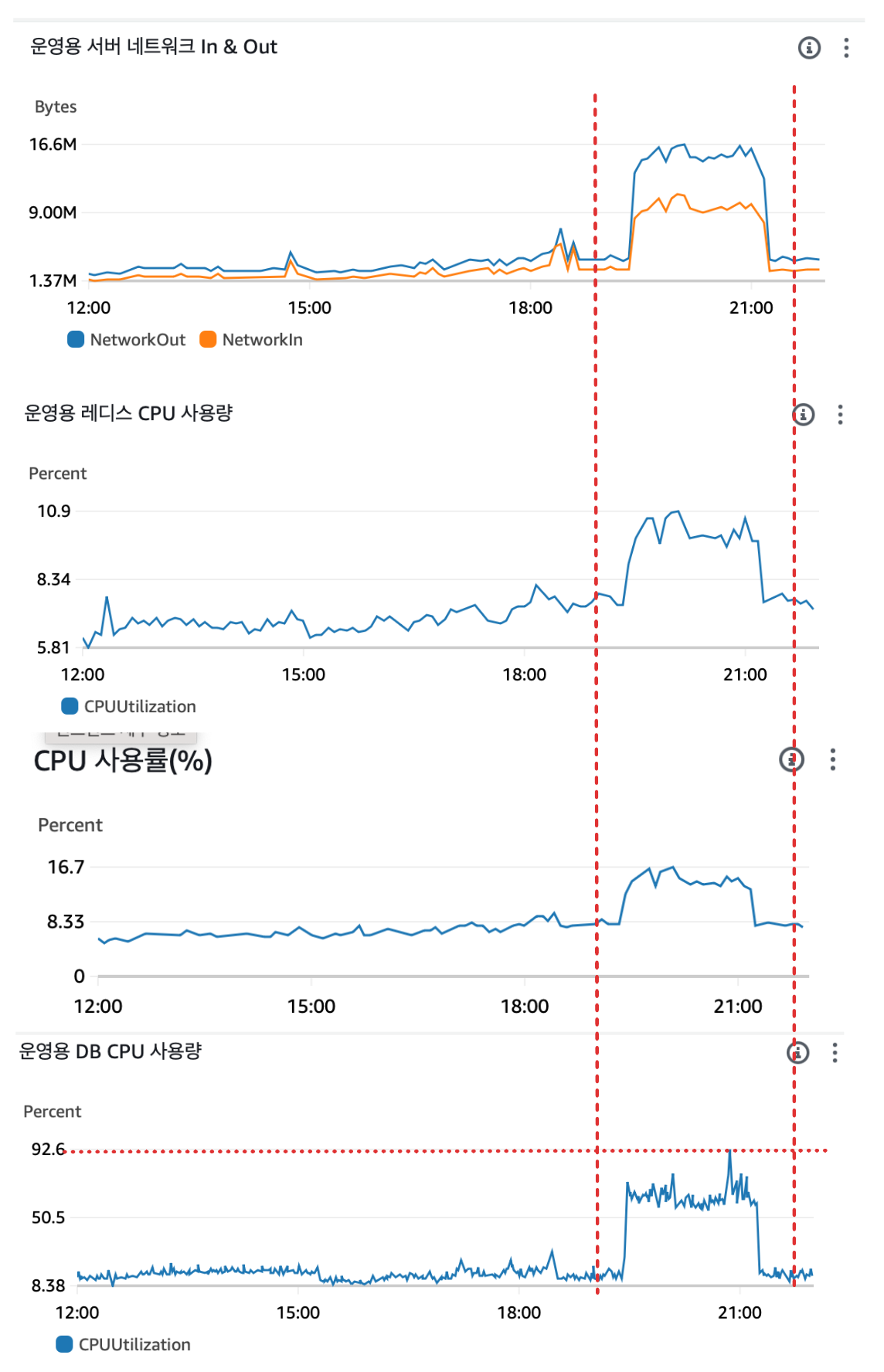
먼저 네트워크 서버 In & Out 그래프를 살펴보면 약 19시에서 21시 사이에 네트워크가 들어오고 나가는 양이 갑자기 급증한 것을 볼 수 있다. 네트워크가 급증함에 따라 EC2, RDS, ElastiCache 의 CPU 사용량이 비례하게 증가 했다. 당연한 결과다. 네트워크 트래픽이 많다는 것은 처리해야할 연산도 많아진다는 뜻이기에 CPU 사용률이 오를 수 밖에 없을 것이다.
하지만 이상한점이 있었다. EC2, ElastiCache 는 납득할 수 있는 수준으로 올랐고, 올랐어도 크게 문제가 발생 할 정도는 아니었다. 근데 RDS 는 다르다. CPU 사용률이 최대 92.6% 까지 올라간 것이었다. 이는 굉장히 심각한 문제라고 판단했다.
사실 1000명이 나한테는 처음 받아보는 숫자라서 많지만 전체적으로 봤을 때 그렇게 많은 사용자는 아닐 것이다. 그런데도 RDS CPU 사용량이 92% 까지 급증했다는 것은 문제가 많아 보였다.
CPU 사용량이 많아지면 뭐가 문제지?
CPU 사용량이 많아지면 그 만큼 다른 작업을 처리 할 여유가 없어진다. 그럼 점점 처리 속도가 느려질 것 이고 시스템 전체적으로 병목 현상이 생겨 응답 속도에 큰 문제가 생길 것이다.
그럼 DB 에서 생긴 지연이 서버로 전파되고 끝에는 클라이언트 까지 전파되어 사용자 경험에 매우 좋지 않은 영향을 끼칠 것 이다.
뭐가 문제지?
문재 상황을 인지 했으니 원인을 찾아야한다.
정말 사용자가 많아지는 것이 맞나?
처음으로 한 것은 정말 네트워크가 급증한 것이 사용자들의 요청이 많아진 것이 원인인지 확인했다. 왜냐하면 트래픽이 급증한 것이 정당한 요청이 아닌 공격을 당해서 정보를 빼앗기는 상황도 생각해보았기 때문이다. 따라서 정말 사용자들의 요청이 맞는지 확인 하는 것이 첫 단계였다.
우리는 평소 서버에 매 요청마다 요청에 대한 로그를 남기게 구현해두었다. 따라서 해당 로그 파일을 가져와 집계해 보면 요청 수는 쉽게 알 수 있었다.
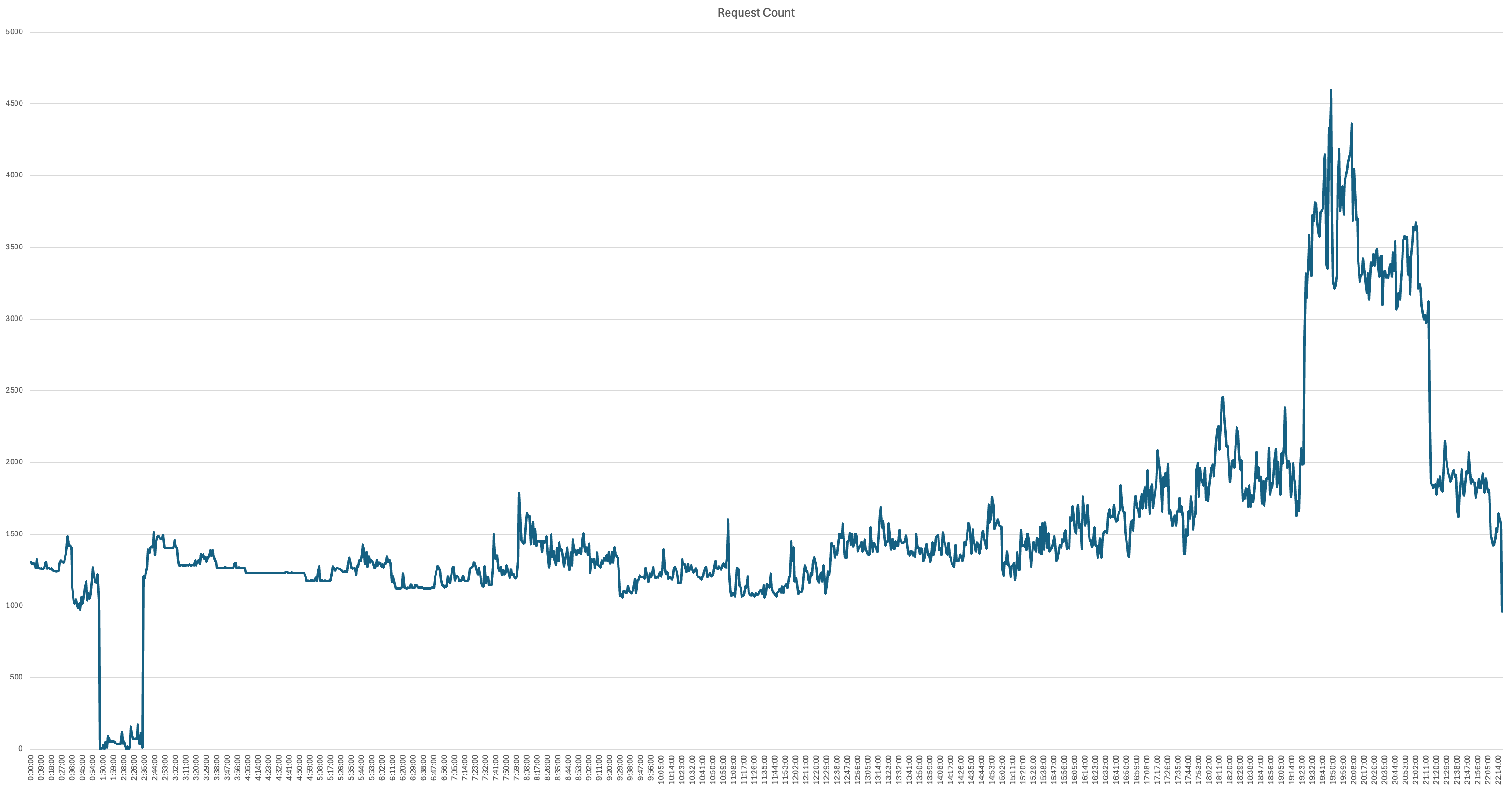
파이썬으로 집계하고 그래프를 그려보니 19시에 21시 사이에 확실히 사용자들의 요청이 많은 것을 알 수 있었다. 이로서 네트워크 트래픽의 급증은 사용자의 사용량이 많아져서라고 확신했다.
아마 시간 19~21 사이인 것으로 트래픽이 늘어난것은 보아 퇴근하고 산책하는 비율이 많아져서라고 예상한다.
어떤 요청이 문제가 있을까?
다음 단계는 어떤 요청이 DB의 CPU를 많이 사용하는지 찾는 것이었다. 로그 파일에는 각 어떤 요청인지 메서드와 엔드포인트를 기록해두었다. 따라서 파이썬을 사용해서 로그 파일을 집계하여 각 요청별 개수를 집계해보았다.
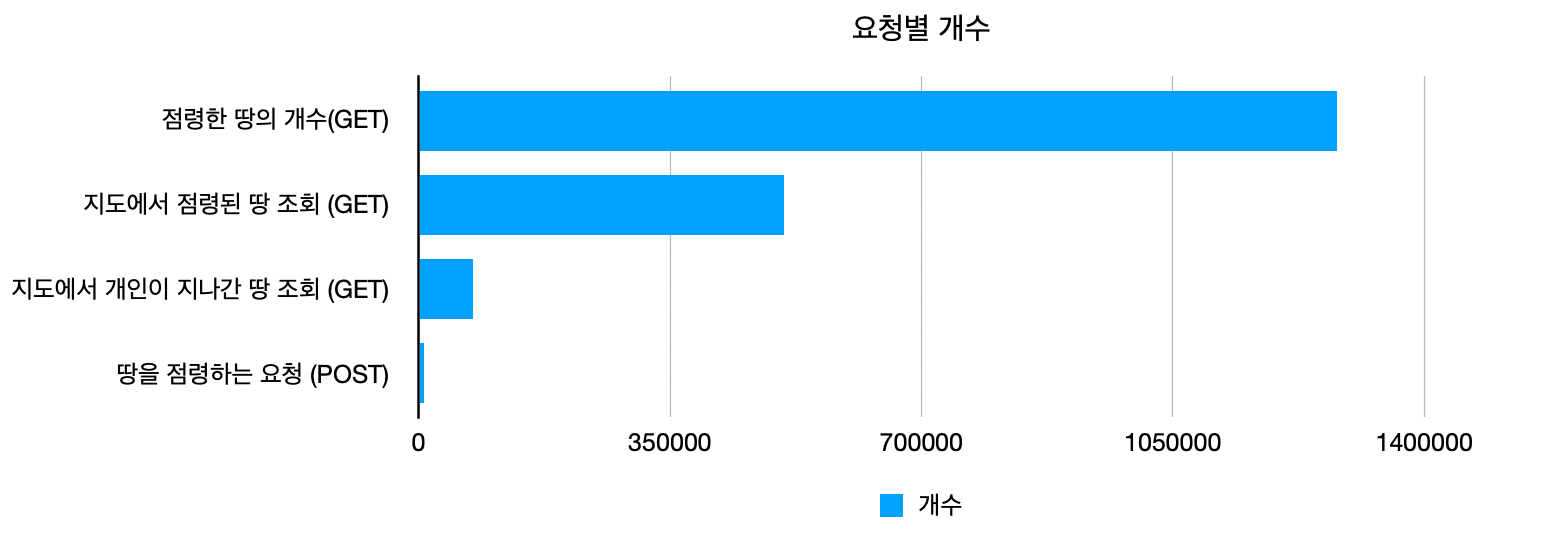
자세한 엔드포인트는 보안 문제 때문에 적지않았다.
결과는 위와 같다. 위 데이터가 요청수 상위 4개의 데이터다. 나머지 요청들은 큰 비중을 차지하지 않아서 용의선상에서는 제외했다.
상위 4개의 요청을 알았으니 CPU 사용량이 급증했을 때의 상황을 재현해서 각 요청 에 따라서 DB에 얼마나 발생하는지 테스트 해보며 원인을 찾을 생각이다.
부하는 발생시키는 방법으로는 Jmeter 를 사용했다. 부하정도는 10분 동안 요청을 쏴볼 것이고, 개수는 로그를 통해 10 분동안의 각 요청별 개수를 집계하여 그 만큼의 요청을 쏠 것이다.
자 이제 각 요청 별로 DB에 가해지는 부하를 확인 해보자.
점령한 땅의 개수
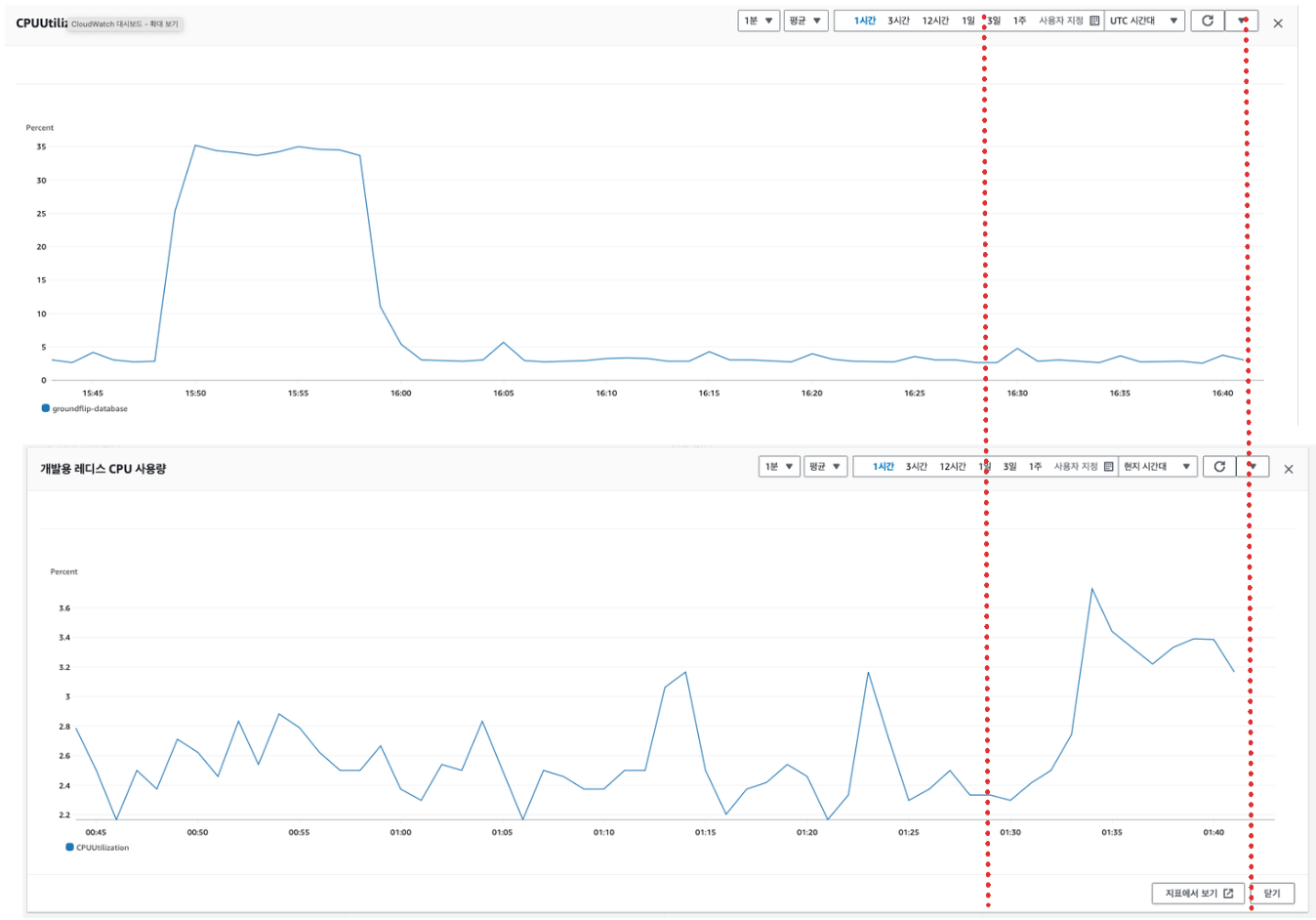
가장 많은 요청이 있었던 api 이다. 하지만 결과를 보면 DB 에 CPU 사용량은 없다고 봐도 무방할 정도로 증가하지 않는다. 다만 Redis 의 사용량은 증가한다.
사실 이 api 는 일찍이 위험성을 알고 DB 의존성을 낮추고 Redis 캐싱 해두었기 때문에 트래픽이 많은 상황에서도 DB 에 무리가 가지 않게 최적화 시켜둔 것이었다. 😁😁 이 글에 최적화 방안은 자세히 써두었다.
땅을 점령하는 요청
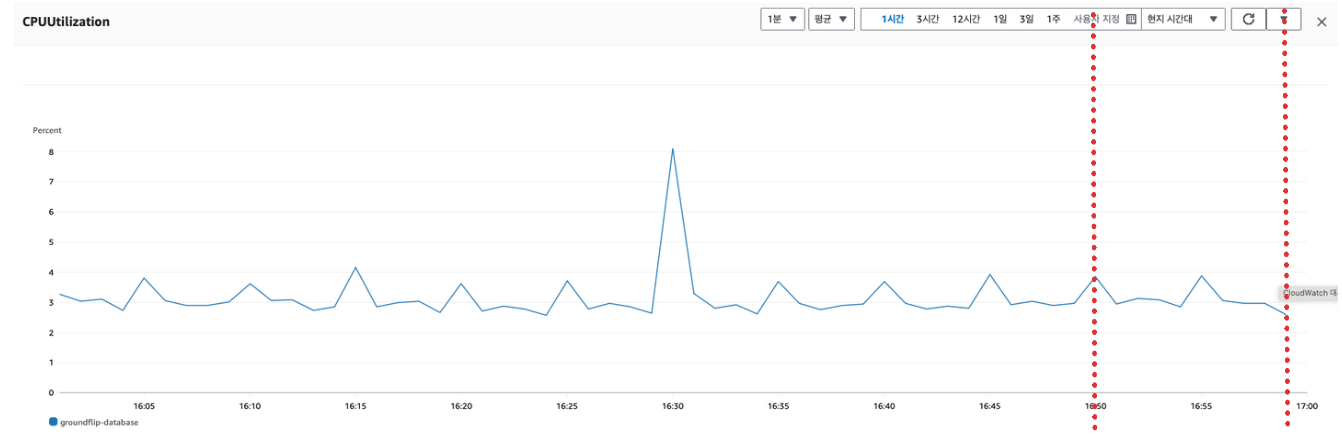
땅을 정렬하는 요청도 DB 사용량이 증가하지 않았다. 동작 방식을 살펴보면 DB 에서는 단순히 방문 했다는 기록을 삽입만 하기 때문에 큰 부하는 없는 것으로 생각된다.
지도에서 점령된 땅 조회
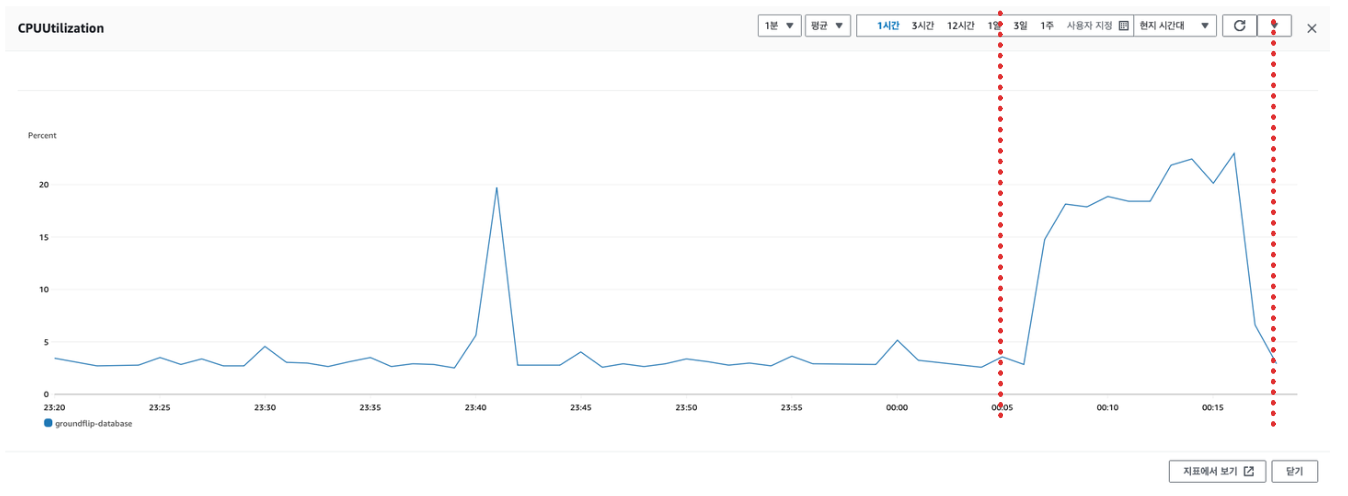
범인을 찾았다!
DB의 CPU 사용량을 높이는 범인을 찾았다! 지도에서 점령된 땅을 조회하는 요청이 문제였던 것이다. 다른 요청 들과 달리 확실히 DB의 사용량이 눈에 띄게 올라 가는 것을 확실히 알 수 있다.
지도에서 개인이 지나간 땅 조회 api 는 위 api 와 동작 방식이 비슷하기 때문에 그래프를 삽입하지는 않았다.
왜 DB의 CPU를 많이 쓸까?
이제 CPU 사용량을 높이는 범인을 찾았으니 이유를 알아봐야한다.
점령된 땅을 조회하는 방식
DB 테이블 구조
우선 DB 에 어떻게 저장 되었는지 설명한다. 대한민국 땅을 저장하는 pixel 테이블이 있다. pixel 테이블은 땅의 좌표, 정보, 소유자 등의 정보가 저장되어있다.
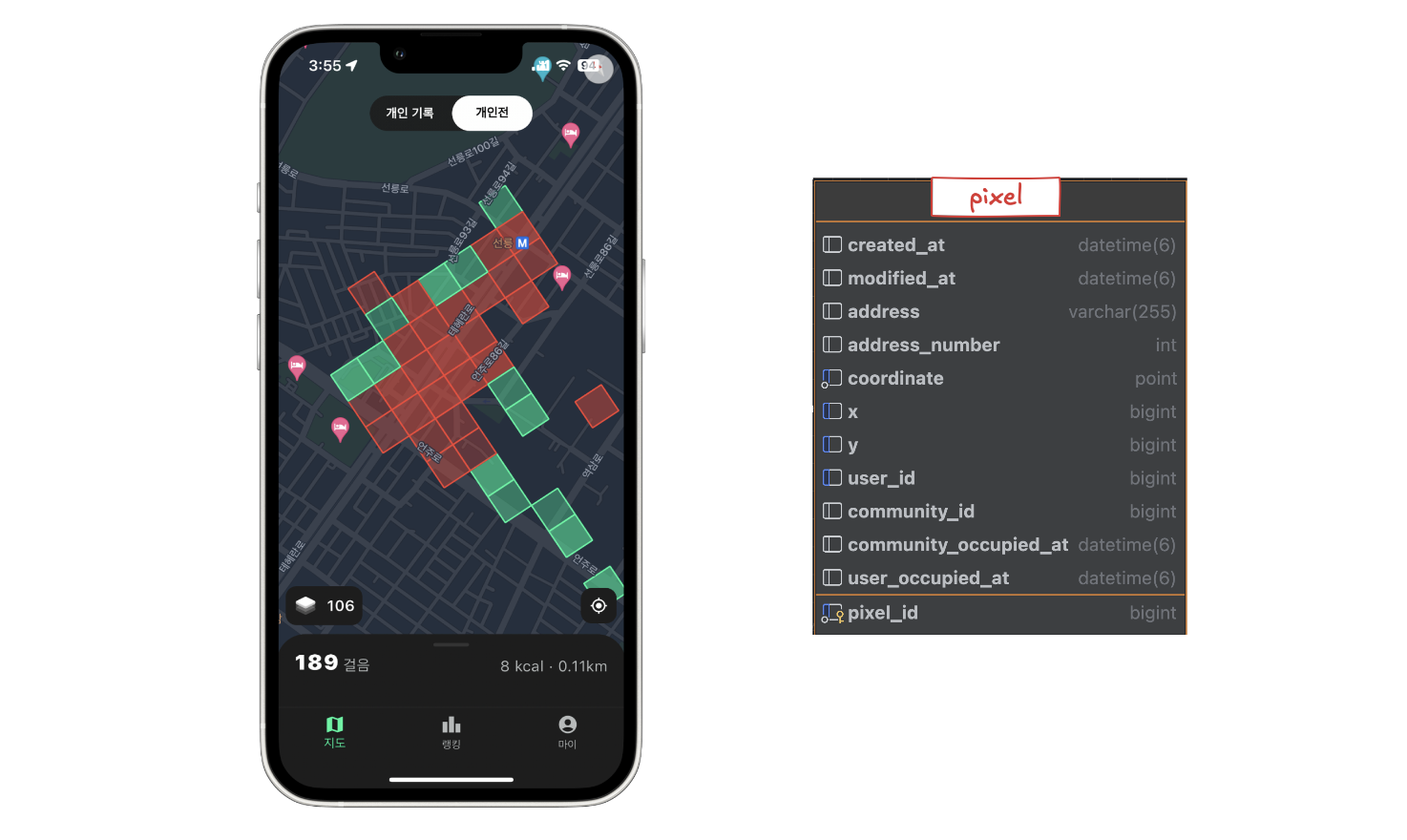
위와 같이 화면의 중심을 기준으로 화면의 보일 만큼의 땅 정보를 불러온다. 따라서 중심 좌표 기준으로 반지름에 해당하는 범위 만큼의 데이터를 불러오기 위해 pixel 테이블에 coordinate 컬럼에 R-Tree 인덱스를 생성하였다.
R-Tree 인덱스란? 공간 정보를 효율 적으로 저정하기 위한 트리 형태의 자료구조. 빠르게 반경 검색이 가능하다.
땅 하나는 80m 80m 의 크기를 가지고 있다. 대한민국의 땅을 80m 80m 로 나누면 약 2900만 개의 땅이 나온다. 우리는 2900만 개의 땅을 전부 pixel 테이블 안에 집어 넣어 두었다.
조회 로직
땅을 조회 하는 로직은
-
조회 하려는 곳의 GPS 좌표와 반경을 요청한다.
-
DB에 반경 내의 땅을 조회하는 쿼리를 보내 데이터를 받아온다.
SELECT pixel.pixel_id AS pixelId, ST_LATITUDE(pixel.coordinate) AS latitude, ST_LONGITUDE(pixel.coordinate) AS longitude, pixel.user_id AS userId, pixel.x, pixel.y FROM pixel WHERE ST_CONTAINS((ST_Buffer(:center, :radius)), pixel.coordinate) AND pixel.user_id IS NOT NULL AND pixel.user_occupied_at >= :weekStartDate
쿼리실행 계획을 확인해 보면
ST-CONTAINS조건을 탈 때 R-Tree 인덱스를 타는 것을 알 수 있다.. -
조회된 데이터를 가공하여 반환한다.
R-Tree 가 문제인가?
처음에는 R-Tree 인덱스가 연산량이 많아 CPU 사용률을 높였나? 하는 생각이 들어 R-Tree 를 사용하지 않고 B-Tree 를 사용한 방식으로 변경해 테스트 해보았다.
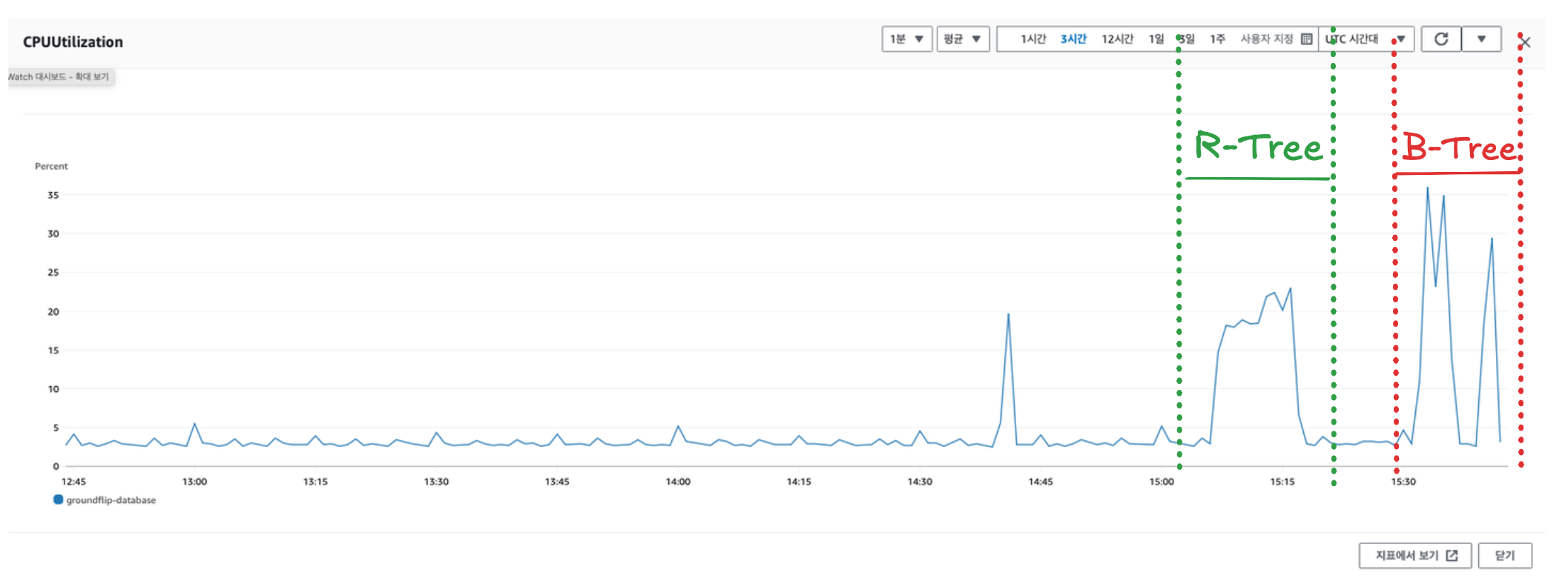
결과는 R-Tree 가 문제는 아닌 것 같았다. B-Tree 로 바꾸어 조회 할 때 오히려 더 사용률이 높아졌다.
데이터양이 문제다!
이제 남은 문제는 2900만 개의 데이터 밖에 없다고 판단했다. 2900만개나 되는 데이터가 트리 형태로 저장 되어있으니 아무래도 데이터를 찾기 위해 탐색해야할 깊이가 길어지면서 CPU 연산이 과도하게 일어나지 않나 싶다.
이 부분은 정확하게 확인하지는 못했다. MySQL 에서 R-Tree 의 깊이를 알 수 있는 방법은 없었다. 혹시 정확한 이유를 아신다면 댓글로 알려주시면 감사하겠다.
해결책
스케일업
우리는 DB 의 인스턴스는 db.t3.small 을 사용한다. 아주 좋은 CPU는 아니다.
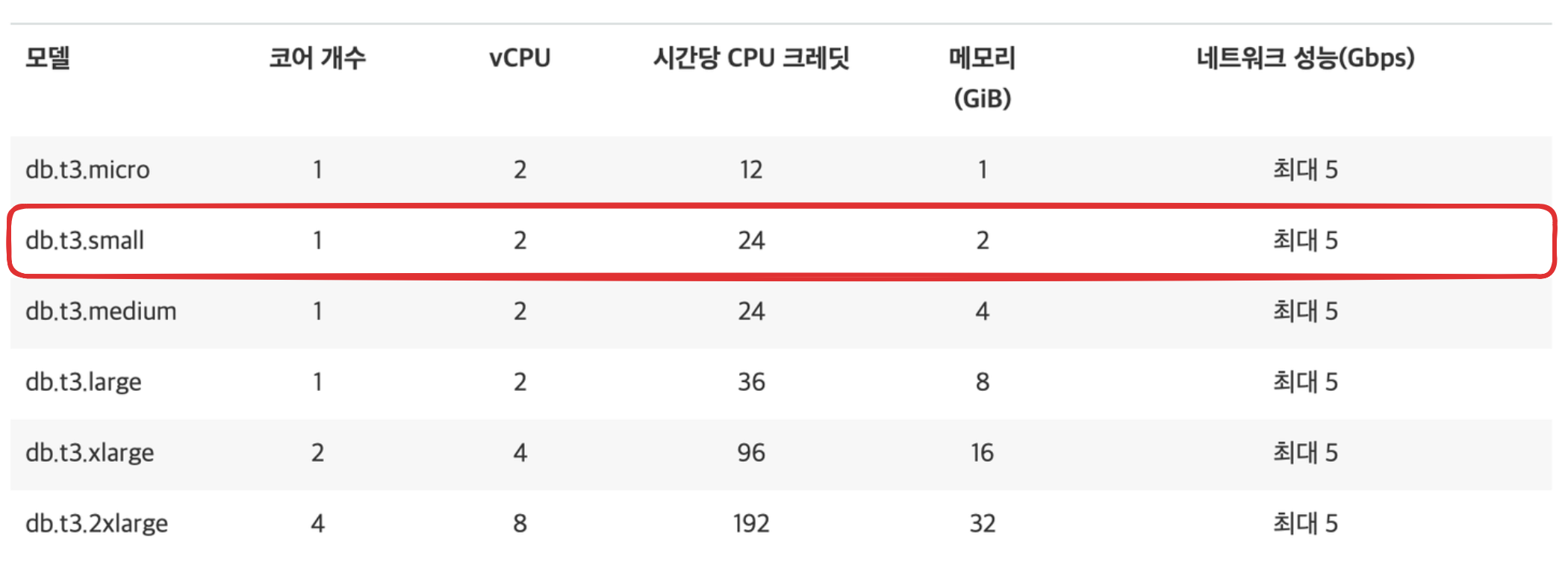
간단한 해결책으로 스케일업 이 생각났다. 그냥 CPU를 더 좋은 것으로 바꿔 버리는 것이다. 이렇게 하면 RDS에서 버튼 몇번 딸깍하는 것으로 해결할 수 있다. 하지만 비용이 비싸진다 ㅠㅜ 수익화도 안되있는데 돈을 더 나가게 할 수는 없었다. 그리고 사용자가 더 많아질수록 사용량이 증가 할 텐데 그 때 마다 CPU를 업그레이드 하는 것은 근본적인 해결책은 아닌 것 같다.
데이터 크기 줄이기
이제는 데이터의 크기를 줄여보면 어떨까 하는 생각이 들었다. 다시 생각해보면 우리의 테이블에는 상당히 비효율적으로 데이터가 저장이 되어있다는 생각이 들었다.
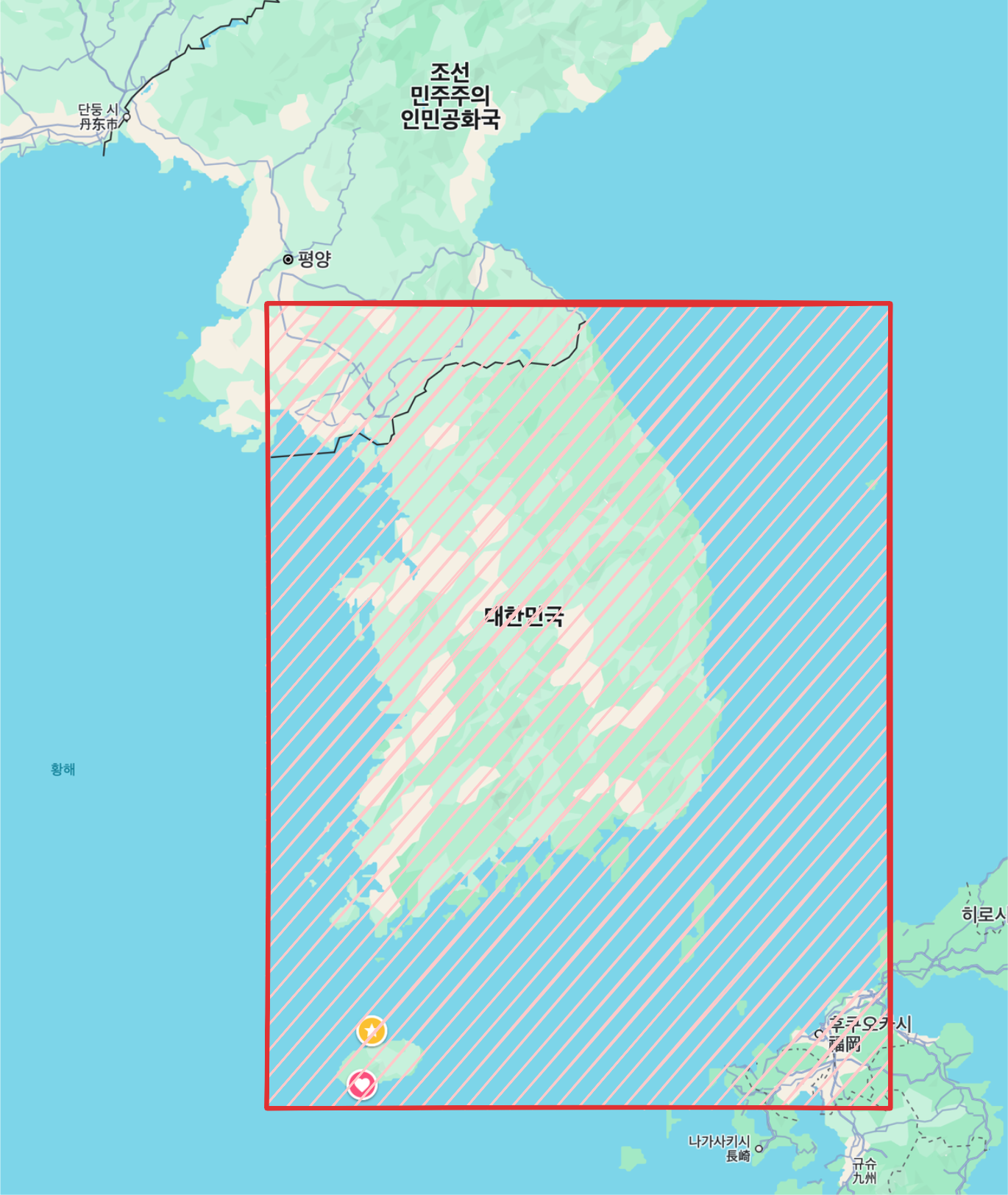
대한민국 전체를 커버 하기 위해 위와 같은 영역을 전부 80m * 80m 로 쪼개어 DB 에 저장을 하였다. 필요없는 땅들이 굉장히 많다.
- 바다
- 산 (올라갈 수 있는 곳도 있긴하다)
- 사람이 살지 않는 지역
- 북한, 일본
이렇게 한번도 방문하지 않을 지역들이 다 DB에 저장되어 리소스를 잡아먹고 있는 것이다. 실제로 2달동안 운영한 DB에서 사용자들이 한번이라도 밟은 지역을 조회 해보니 약 3만개 정도 밖에 되지 않았다.
개발 초기에는 미리 저장함으로서 로직을 편하게 짤 수 있어 2900만개를 전부 넣었지만 이제는 뺄 시간이 되었다고 생각이 들었다.
로직 변경
크기를 줄이기 위해 사용자들이 한번이라도 방문한 땅만 DB에 저장하는 방법으로 바꾸려한다. 새로운 땅을 방문하면 그때 그때 계산해서 DB 에 넣는 방식으로 새로운 땅을 채웠다.
테이블 이전
CREATE TABLE pixel_non_null_user LIKE pixel;
INSERT INTO pixel_non_null_user
SELECT *
FROM pixel
WHERE user_id IS NOT NULL;사용자가 한번이라도 방문한면 pixel 테이블의 user_id 컬럼이 방문한 사람의 id 로 채워진다. 따라서 user_id 가 null 이 아닌 데이터 들만 모아서 새로 테이블을 만들어 기존 테이블과 바꾼다.
새로운 땅 삽입
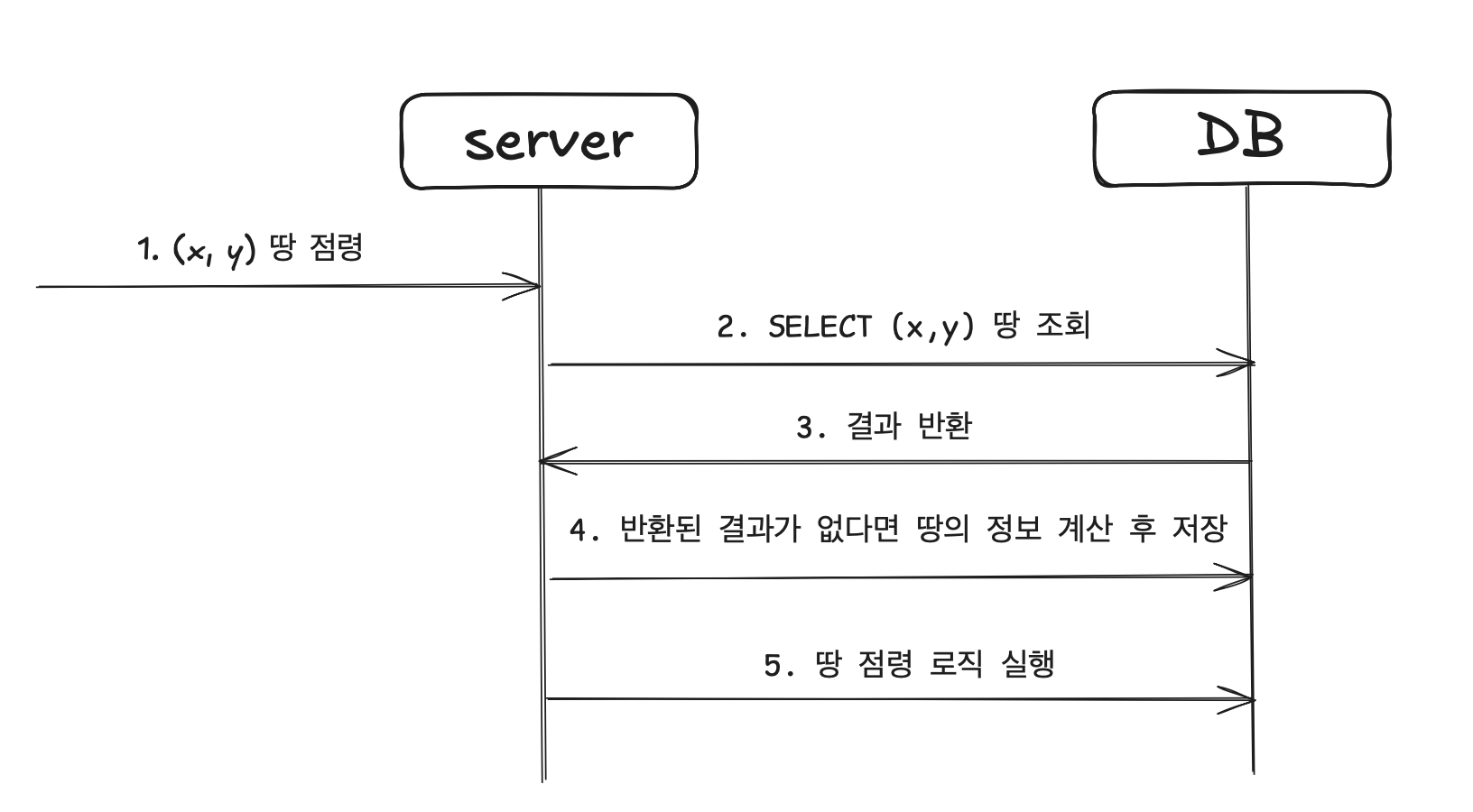
위와 같은 로직으로 구현했다. 로직이 살짝 많아져 처리 속도가 느려질 우려가 있긴 하지만 조회에 비해 삽입 요청은 압도적으로 적기 때문에 괜찮다고 판단했다.
추후 사용량이 더 많아져서 버티지 못한다면 메시지 큐 같은 것을 써서 처리 해봐야겠다는 생각을 했다.
최종 데이터 개수
이렇게 줄인 데이터는 현재 운영용 DB 기준 약 3만개 정도 밖에 되지 않는다! 이전 2900만개에 비하면 약 967배나 데이터가 줄었다!
결과
테스트 용 RDS
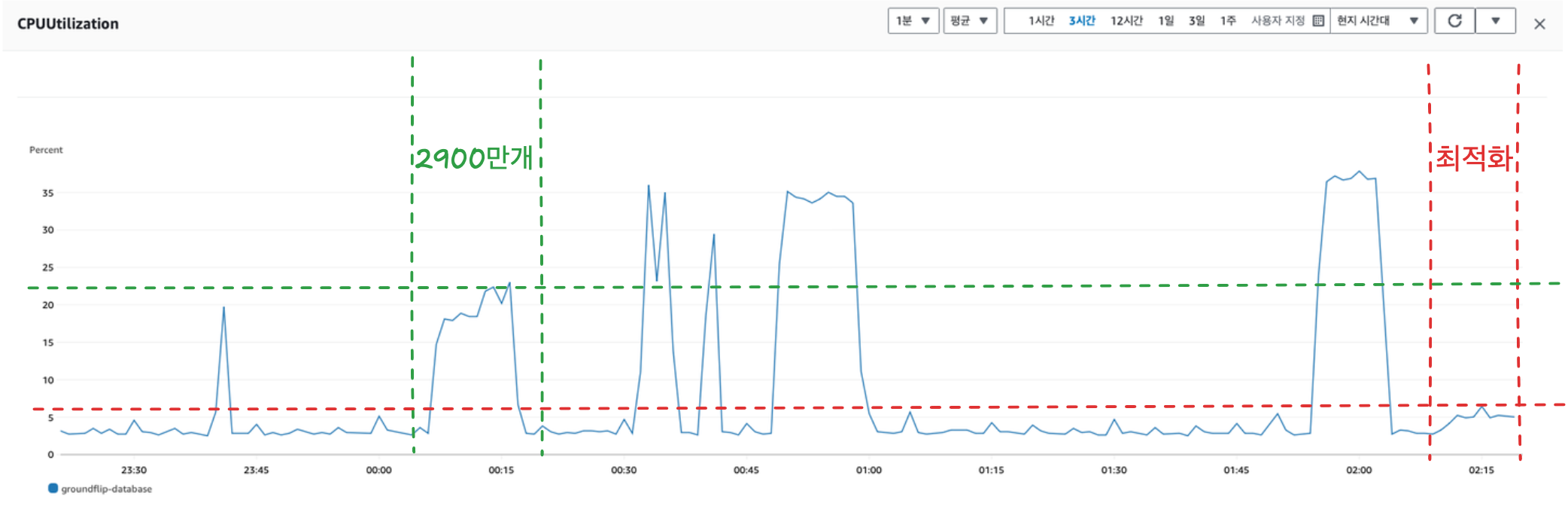
결과는 성공적이다! 기존에 비해 부하가 절반도 되지 않는다!
결과적으로 데이터량이 많은 것이 문제가 확실 했던 것 같다.
실제 운영 RDS
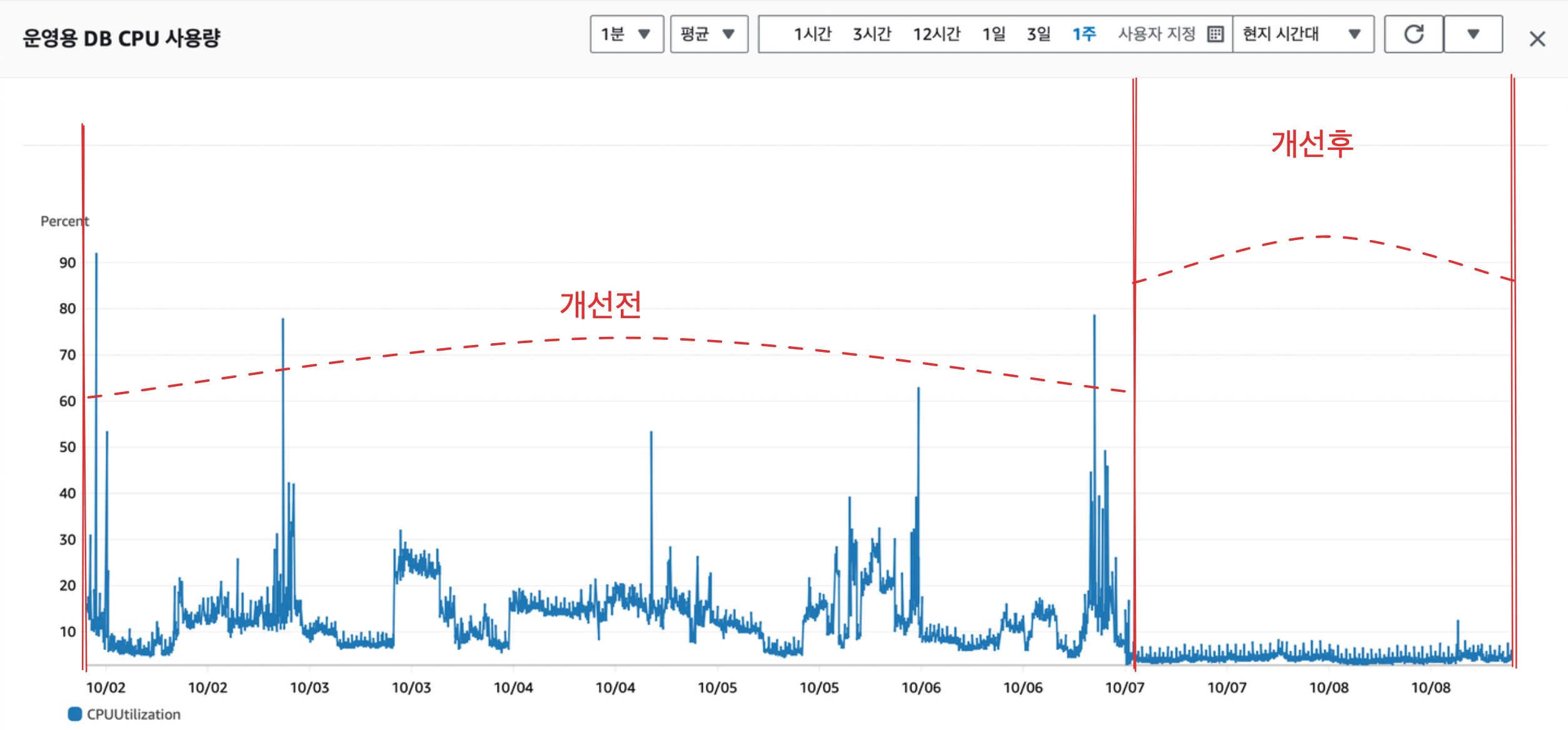
운영용 RDS의 1주일간 CPU 사용률 수치를 봐도 눈에 띄게 CPU 사용률이 감소한 것을 확인 할 수 있다. 최대 90% 까지 오르던 사용률이 개선 후에는 아무리 많이 나와도 10% 언저리인 것을 확인 할 수 있다!
마무리
이번 경험은 굉장히 의미있는 경험이라고 생각한다. 트래픽이 몰릴 때 문제를 해결해보기는 쉽지 않았는데 사용자가 많아진 덕분에 값진 경험을 했다. 이번 일을 토대로 좀 더 서버를 최적화 해야겠다고 강하게 느꼈다. 자원은 한정적이니 저비용 환경에서 최대의 효율을 발휘하도록 수정 해봐야겠다! t2.small 에서는 데이터의 개수가 몇개 정도 일때 안정적으로 작동할지도 궁금해서 다음번에 테스트해 볼 예정이니 많은 관심부탁드린다.

26개의 댓글


땅 정보 저장에서 validation을 진행하는 과정이 있을지 조심스럽게 여쭤봅니다.. 당연하게도 포켓몬고 처럼 사용자가 위치만 바꿔서 요청을 보낼 수도 있으니, 저장 요청에 보안 요소를 가미하거나 서비스하는 지역 내인지 확인하는 로직이 있으면 좋을 것 같습니다 : )
Velog에서 오랜만에 양질의 글을 읽은 것 같습니다. 감사합니다!!


너무 재미있게 읽었습니다~ 이미 충분히 대응과 분석, 고민까지 잘하고 계시지만 자그마한 추천 드리고 싶어서 남겨봅니다 🙏
table vertical partitioning 을 (결론적으로 적용을 하신건데) 지역구나 도단위로 해도 괜찮을 것 같고, 이후에 multi-indexing 을 사용하시면 더 좋을 것 같습니다!
아주 옛날글인데 제가 자주 찾아 봤던 글도 같이 남겨봅니다~ https://blog.lael.be/post/370



아하 그럼 로직만 개선만 하면 rds의 스케일업은 굳이 필요없다라는 말씀이신거같네요 근데 .. 제생각은 이거 데이터베이스 쿼리를 만지신건가요? 아님 백엔드 로직을 고쳐서 sql 접근 할때 고치신건지 궁금합니다


좋은 글 잘 읽었습니다. 글을 읽다가 궁금한 점이 생겨서 질문드립니다. 시스템에서 이미 redis 를 사용중이신 것 같은데 혹시 문제 해결을 단순히 redis 로 쿼리 결과를 캐싱하는 방법을 사용하지 않으신 이유가 따로 있으실까요??
땅 정보 저장에서 validation을 진행하는 과정이 있을지 조심스럽게 여쭤봅니다.. 당연하게도 포켓몬고 처럼 사용자가 위치만 바꿔서 요청을 보낼 수도 있으니, 저장 요청에 보안 요소를 가미하거나 서비스하는 지역 내인지 확인하는 로직이 있으면 좋을 것 같습니다 https://www.hpinstantink-hp.com
좋은 글 감사합니다