Transformer mechanism 2
Attention의 순서 및 맥락 정보
1. Attention의 기본 개념
어텐션은 쿼리를 입력하면, 관련 있는 키들의 가중치 합을 계산하는 과정이다.
즉, Attention의 결과는 Query와 연관된 Key 정보들의 가중 합이다.
이때, 가중치 합을 계산할 때 Query와 Key를 각각 하나씩 내적하여 계산한다.
하지만 이 과정에서는 단어의 "순서" 정보가 고려되지 않는다.
2. 어텐션에서 순서 정보가 반영되지 않는 이유
어텐션 연산은 Query와 Key 간의 내적(dot product) 연산을 기반으로 한다.
즉, 단어들의 내적 값이 동일하면 그 단어가 문장에서 처음 등장했든, 마지막에 등장했든 내적 결과는 동일하다.
예제
"인도 음식점을 가던 중 주행 금지 표지판을 보았다."
위 문장에서 "인도"라는 단어가 첫 번째 위치에 등장한다.
하지만 "인도"라는 단어가 문장 끝에 있더라도 내적 계산 결과는 동일하다.
즉, 어텐션은 단어의 위치 정보를 고려하지 않는다.
어텐션의 결과(가중치 합)는 Query 값이 동일하면 단어의 순서가 바뀌어도 동일한 결과를 출력한다.
3. 순서 정보 포함: Positional Encoding
트랜스포머 모델에서는 순서 정보를 보완하기 위해 Positional Encoding을 사용한다.
Positional Encoding은 단어의 위치를 표현하는 벡터를 추가하는 방법이다.
Positional Encoding의 원리
- 각 단어의 임베딩 벡터에 특정 위치마다 고유한 벡터 값을 더해준다.
- 예를 들어, "1번 벡터"가 추가된 단어는 "첫 번째 단어"로 인식된다.
- 이 방식으로 위치 정보를 명시적으로 추가할 수 있다.
구조도
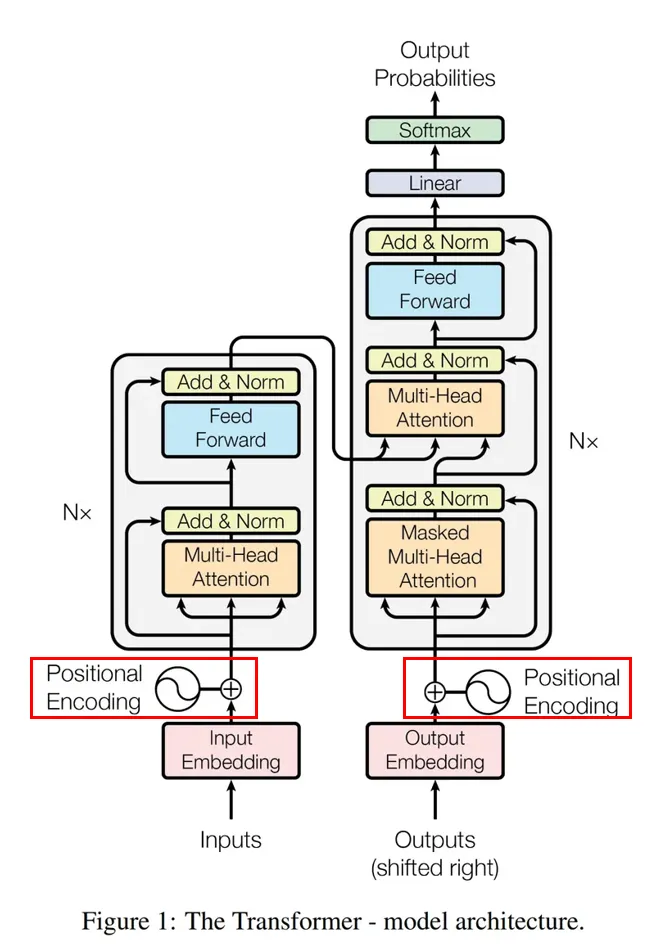
Positional Encoding을 통해 단어의 위치 정보를 모델에 주입한다.
4. Self-Attention의 역할 (맥락 정보 반영)
어텐션 네트워크에서 Query와 Key로 동일한 정보를 사용하는 경우, 이를 Self-Attention이라고 한다.
Self-Attention의 과정
-
한 문장을 분석할 때, 모든 단어를 Query로도 사용하고 Key로도 사용한다.
- 즉, 각 단어는 다른 단어들과 내적 연산을 수행하여 가중치 합을 구한다.
-
계산된 가중치 합을 다음 레이어의 입력으로 사용한다.
- 첫 번째 레이어를 통과한 후, 각 단어는 단순한 개별 정보가 아닌, 다른 단어들과의 관계를 반영한 정보를 갖게 된다.
-
인코더-디코더를 거치면서 문맥 정보가 더욱 풍부해진다.
- 예를 들어, 디코더가 영어로 번역할 때, 단순히 첫 번째 단어만 보는 것이 아니라, 맥락이 반영된 정보를 활용하여 번역을 수행한다.
Self-Attention을 여러 레이어 반복하면, 단어 간의 상관관계를 더 깊이 반영할 수 있다.
5. 어텐션에서 순서 & 맥락 정보 반영 정리
| 문제점 | 해결 방법 |
|---|---|
| Attention만 사용하면 단어들을 개별적으로 내적 계산하기 때문에, 위치 정보와 맥락 정보가 반영되지 않는다. | Positional Encoding을 활용하여 위치 정보를 포함한다. |
| 단순 Attention만으로는 문맥을 이해하는 데 한계가 있다. | Self-Attention을 사용하여 문맥 정보를 반영한다. |
6. 최종 요약
- Attention은 Query와 Key 간의 내적을 통해 유사도를 구하지만, 단어의 순서는 고려되지 않는다.
- Positional Encoding을 사용하여 단어의 위치 정보를 추가한다.
- Self-Attention을 사용하여 단어 간의 관계(맥락 정보)를 반영한다.
- 인코더-디코더 레이어를 거치면서 더욱 깊은 문맥을 학습하여 번역 및 자연어 처리 성능을 향상시킨다.
