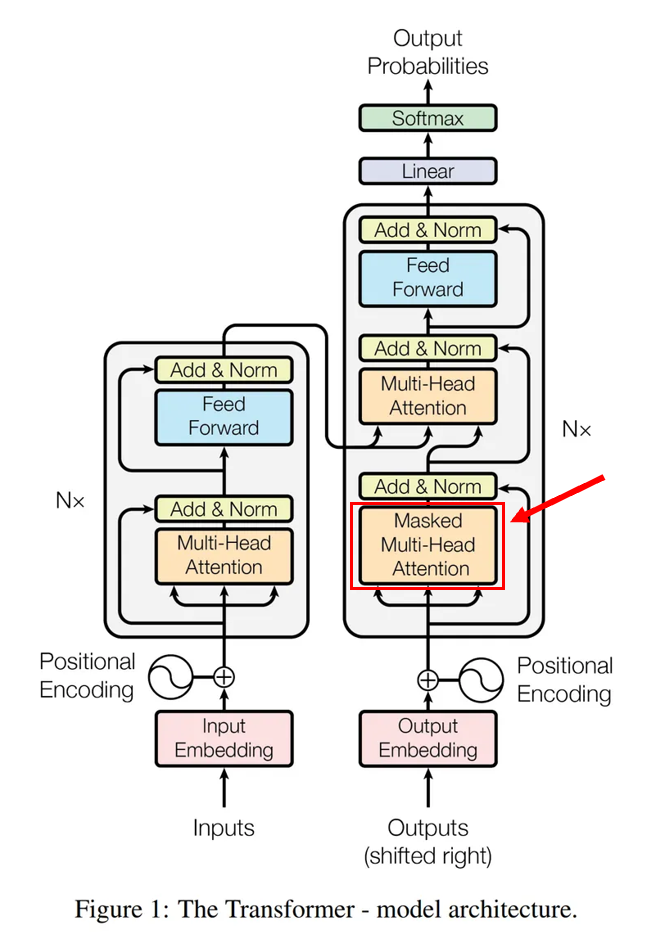
1. 트랜스포머의 학습 방법
트랜스포머의 기본 개념: 번역 모델
트랜스포머는 기본적으로 번역 모델로 설계되었다.
즉, A 언어 문장을 B 언어 문장으로 변환하는 역할을 수행한다.
번역 과정의 직관적 접근
- 첫 번째 단어부터 번역하는 것이 직관적으로 이해하기 쉽다.
- 트랜스포머는 번역할 문장의 첫 단어부터 순차적으로 예측한다.
- 번역 과정에서 입력 문장(예: 한국어)을 Encoder에 넣어 전부 활용한다.
트랜스포머의 번역 작동 방식
- Encoder에서 한국어 문장을 입력받아 전체 문장 정보를 학습한다.
- Decoder에서 번역할 문장(영어)에서 n번째 단어를 예측할 때, n-1번째 단어까지의 정보를 활용한다.
번역을 위한 특수 토큰 사용
- 첫 번째 단어를 예측할 때:
- 특별한 시작 토큰 SOS(Start of Sentence) 를 0번째 단어로 삽입.
- 번역 결과에서는 제거된다.
- 번역이 완료되면:
- 문장 끝을 나타내는 EOS(End of Sentence) 토큰을 마지막 단어에 추가하여 번역 종료를 유도.
병렬 학습을 위한 입력-정답 구조
- 번역을 효율적으로 학습하기 위해 SOS와 EOS 토큰을 활용하여 입력을 한 칸씩 밀어 넣는 방식을 사용한다.
- 이를 통해 병렬 학습이 가능해지고, 모델의 훈련 속도가 향상된다.
2. 미래 정보를 사용하면 안 되는 문제
위와 같은 학습 방식은 입력과 정답을 함께 제공하는 방식이다.
하지만 트랜스포머의 Self-Attention 특성상 문제가 발생한다.
Self-Attention에서 발생하는 문제
- Self-Attention은 한 단어를 예측할 때, 해당 문장 내 모든 단어를 활용한다.
- 즉, 미래 정보(아직 예측되지 않은 단어)까지 학습에 사용되는 문제가 발생한다.
- 예를 들어, 문장의 마지막 단어까지도 학습에 포함되면, 올바른 번역이 불가능해진다.
예측해야 할 단어까지 학습에 사용되면, 모델이 단순히 정답을 복사하는 형태가 되어 의미 있는 번역을 하지 못하게 된다.
해결 방법: 예측할 단어 이후의 정보를 차단해야 한다.
- 올바른 학습을 위해서는 번역할 단어(n번째)와 이전 단어(n-1번째)까지만 학습에 사용해야 한다.
- 이를 위해 Masking 기법을 적용한다.
3. Masking (미래 정보 차단)
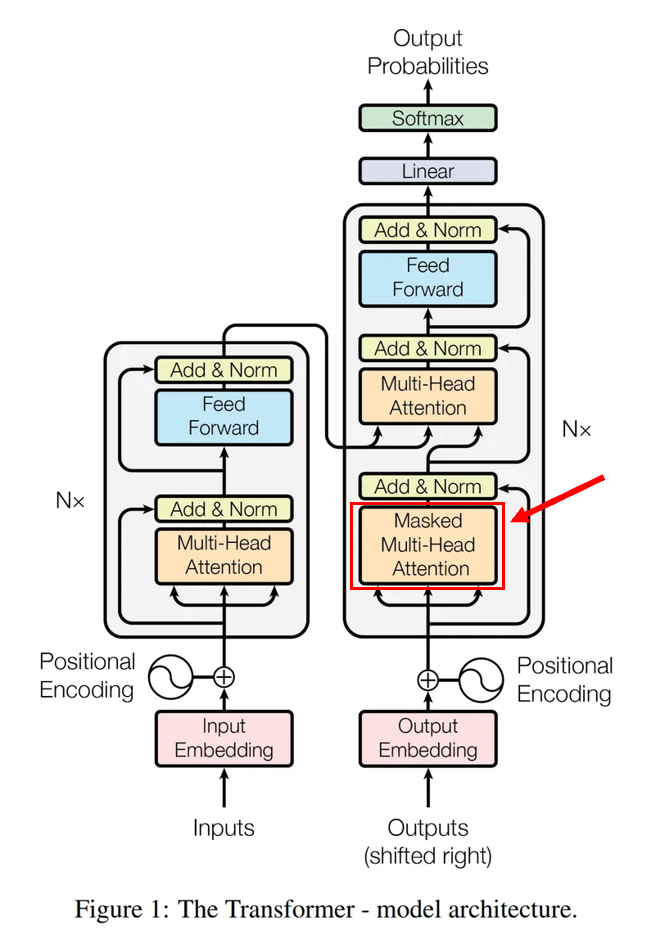
Masking은 미래 단어를 가려주는 "가림막" 역할을 한다.
즉, 아직 번역되지 않은 단어가 학습 과정에서 사용되지 않도록 차단하는 방법이다.
Masking의 동작 방식
- 내적(dot product) 연산을 수행하여 Query와 Key 간의 유사도를 계산한다.
- 해당 단어 이후의 단어들(미래 단어)의 내적 결과를 극단적인 음수 값으로 변환한다.
- 이는 exp() 연산을 적용했을 때 결과가 0이 되도록 유도한다.
- 즉, 미래 단어의 정보가 완전히 사라지게 된다.
Masking을 적용하면, 번역할 단어 이전의 정보만을 사용하여 학습할 수 있다.
4. 트랜스포머 번역 구조 정리
트랜스포머의 번역 과정은 다음과 같은 구조를 따른다.
| 구성 요소 | 설명 |
|---|---|
| Encoder | 번역할 원문(한국어) 문장을 입력하여 처리 |
| Decoder | 번역할 목표 언어(영어) 문장을 예측 |
| Self-Attention | 각 단어가 문장 내 다른 단어들과 관계를 형성 |
| Masking | 미래 정보를 차단하여 예측 과정과 학습 환경을 동일하게 유지 |
Masking이 필요한 이유
- Masking을 적용하지 않으면 학습 시 모델이 미래 정보를 참조하여 정답을 그대로 예측할 수 있다.
- 하지만 실제 번역 과정에서는 미래 정보를 알 수 없으므로 학습과 실제 사용 환경이 다르게 된다.
- 따라서 Masking을 통해 학습 환경과 실사용 환경을 동일하게 맞춰준다.
5. 최종 요약
- 트랜스포머는 번역 모델로 설계되었으며, 문장 전체를 활용하여 번역을 수행한다.
- Decoder는 번역할 단어(n번째)를 예측할 때, n-1번째 단어까지만 입력으로 사용한다.
- 하지만 Self-Attention의 특성상 모든 단어를 참조하게 되어, 미래 정보까지 학습하는 문제가 발생한다.
- 이를 방지하기 위해 Masking을 적용하여 미래 단어를 차단한다.
- Masking을 적용하면 학습과 실제 번역 환경을 동일하게 유지할 수 있다.
Masking을 적용하면 학습할 때 정보와 실사용 시 정보를 동일하게 유지할 수 있다.

hello world!