직접 사용해본 새 언어모델 Qwen2.5 후기
Qwen2.5는 알리바바에서 출시한 새로운 언어모델로, 영어, 중국어, 한국어, 일본어 등 주요 언어를 모두 지원하는 Multi-lingual 언어모델입니다. 기존 Qwen2의 높은 성능과 한국어 능력이 인상깊어, 그의 후속모델인 Qwen2에 관심을 가지고 직접 사용해보았습니다.
🔬공식적으로 발표된 성능을 알아보자.
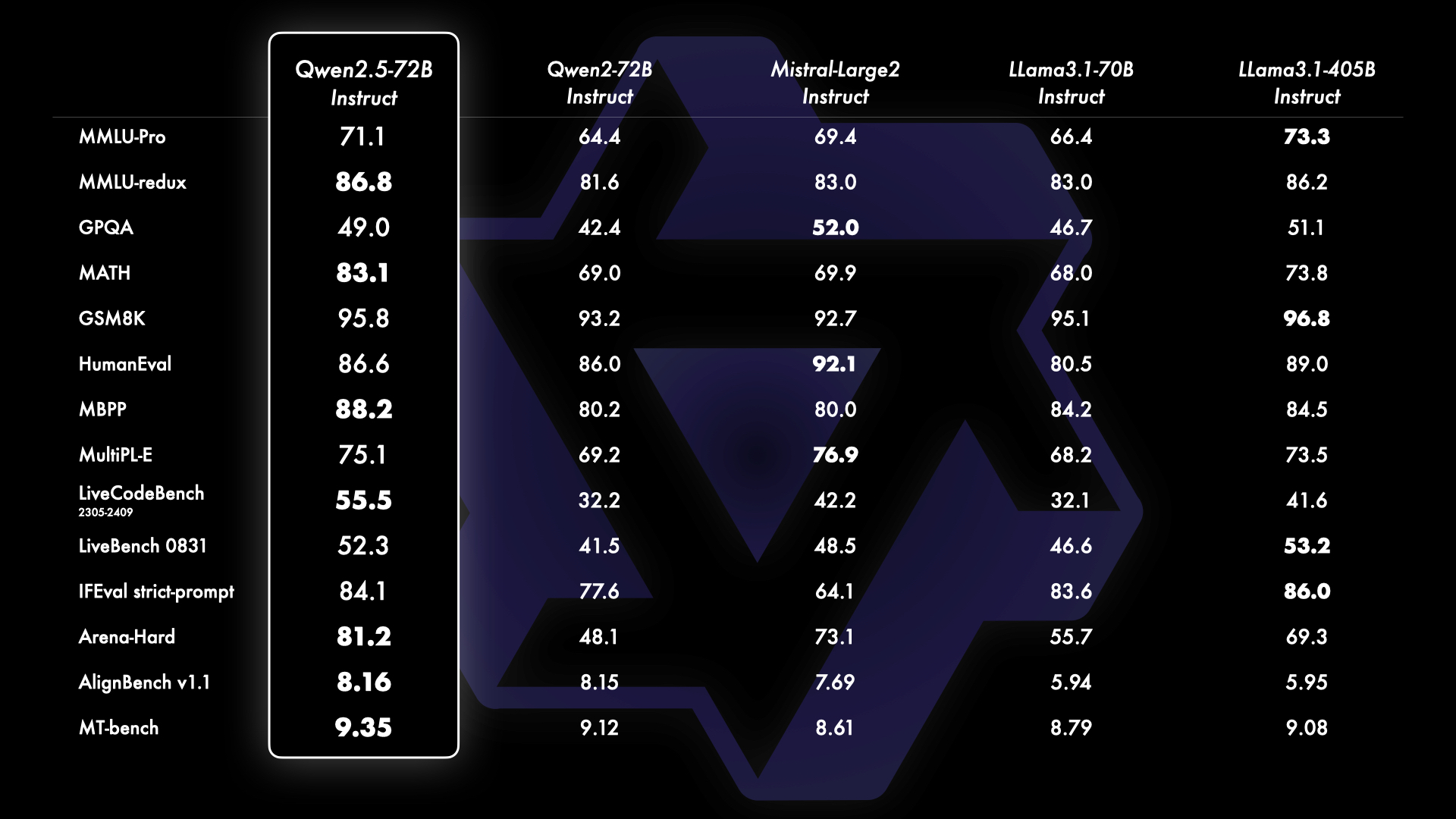
Qwen2.5는 기존 Qwen2대비 높은 성능을 보일 뿐 아니라, Llama3.1-70b, Mistral-Large2 등의 비슷한 급의 모델을 능가하는 성능을 보입니다. 주목할만한 부분은 Llama3.1-405b와 같은 더 큰 급의 언어 모델과 견줄 수 있는 성능을 보인다는 점입니다.
어떤 모델을 사용해보았나요?
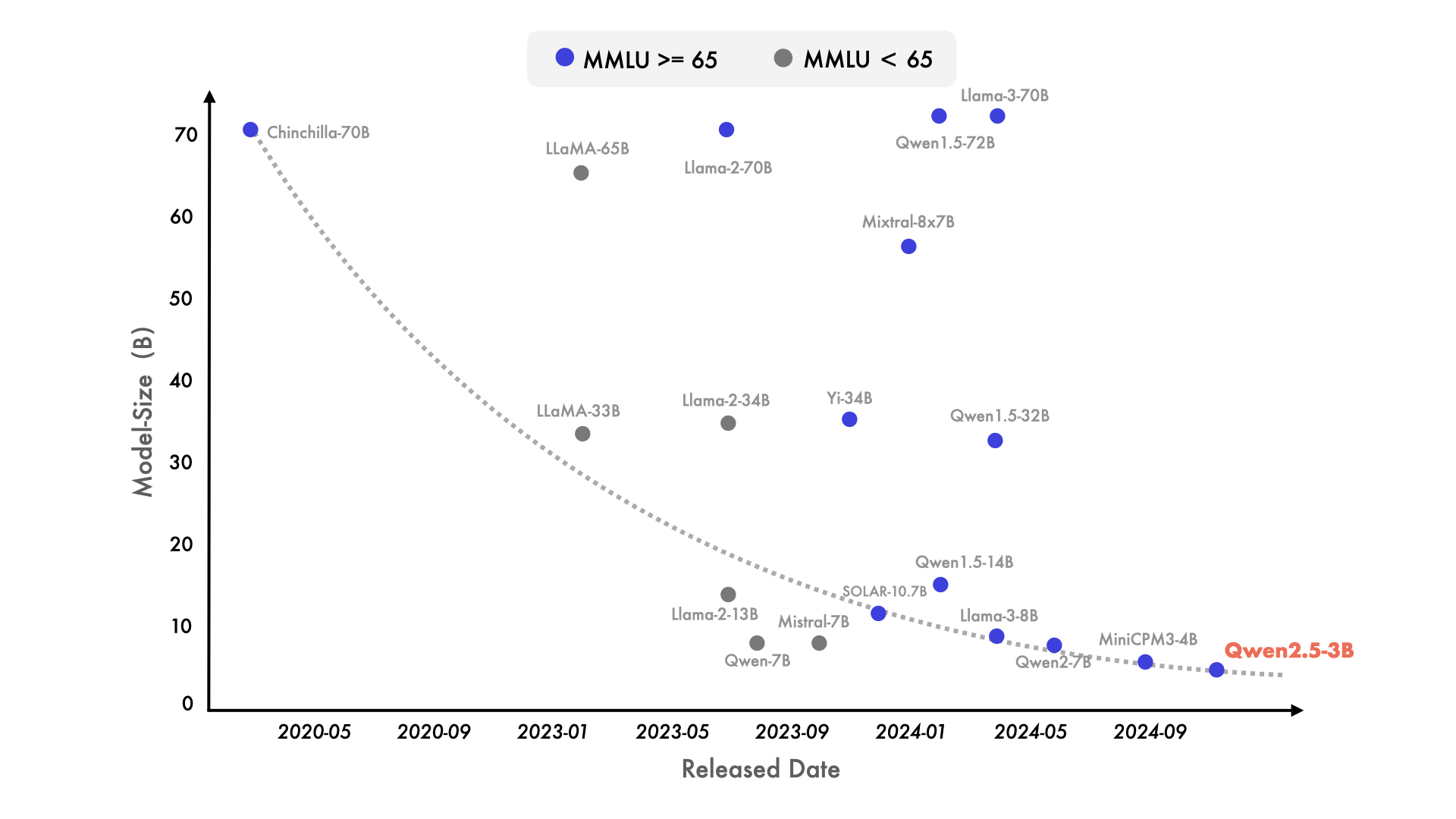
사실 72b는 400b가 넘는 대형 모델에 비해서는 작은 크기의 모델이지만, LLM이 메인이 아닌 기업에서 직접 서비스에 적용하거나, 혹은 개인적으로 사용하기에는 다소 크다고 생각이 드는게 사실입니다. 실제 서비스에 저렴한 비용으로 녹여내거나, 개인적으로 사용하기 좋은 크기는 10b 이하라고 생각하는 편입니다. 그래서, Qwen2.5-7b모델을 직접 사용해보며 다양한 유즈 케이스에 적용해보았습니다.
일반적인 생성은 이제 매우 잘합니다.
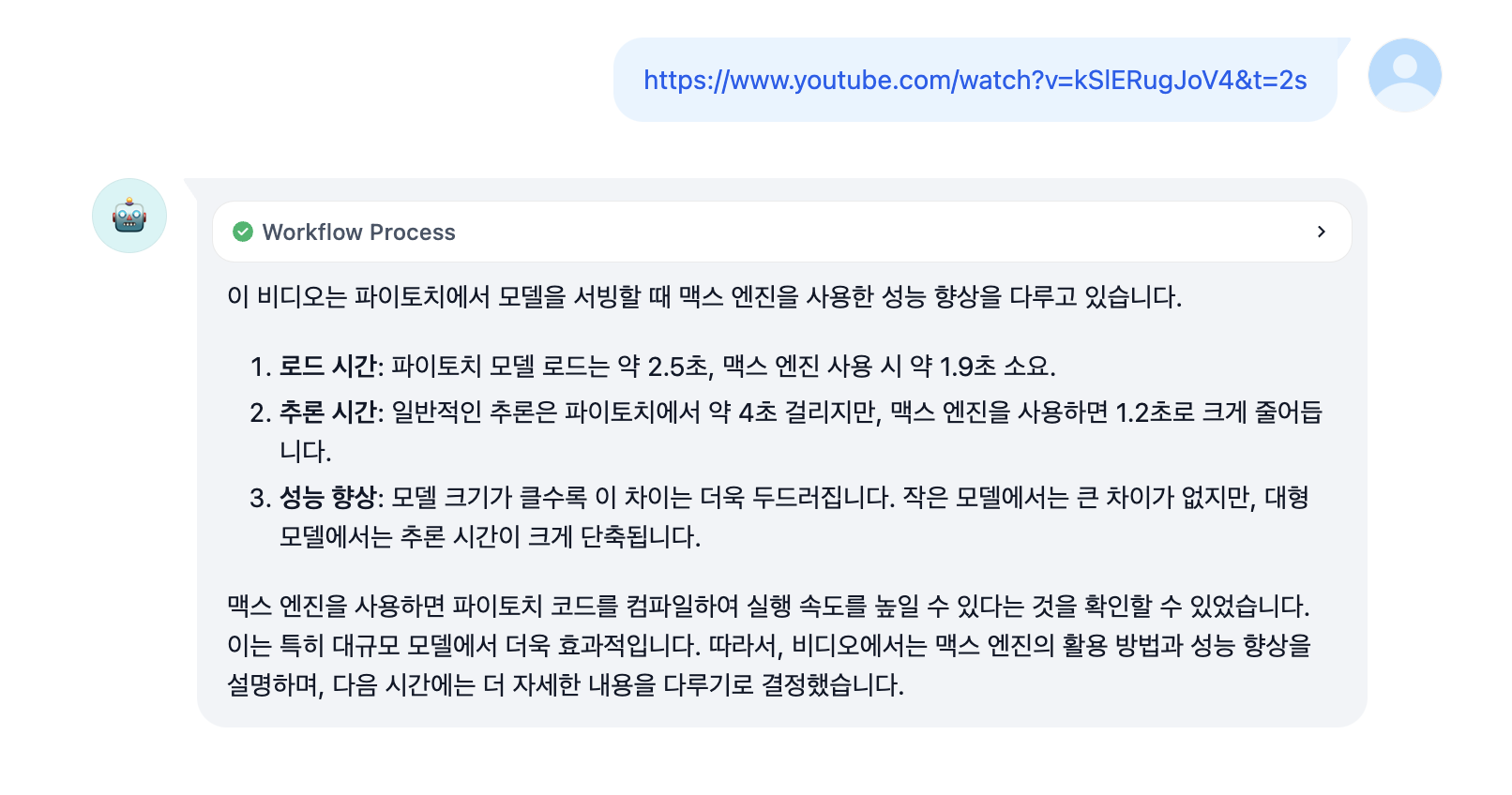
제가 이전에 소개드린 Dify를 통해 유튜브 요약과 관련한 생성을 진행해보았습니다. 그림과 같이 요약 및 생성에 있어서는 매우 자연스러운 성능을 보여줍니다. 전체적인 문맥에 대한 이해도 높은 수준을 보이며, 출력 포멧팅도 요청한 대로 잘 나오는 것을 볼 수 있습니다.
아쉬운 테스크 작업
제가 앞서 개발한 성형시술에 대한 RAG에 접목시켜보았습니다. 이는 LLM을 통해 적절한 문서를 검색(분류)하는 기법과 이를 통해 찾은 문서를 바탕으로 생성하는 기술입니다. 생성은 앞서 확인한대로, 높은 성능을 보임으로 classification모델을 gemma2, qwen2.5, gpt-4o-mini로 바꾸어가며 테스트를 진행해보았습니다.
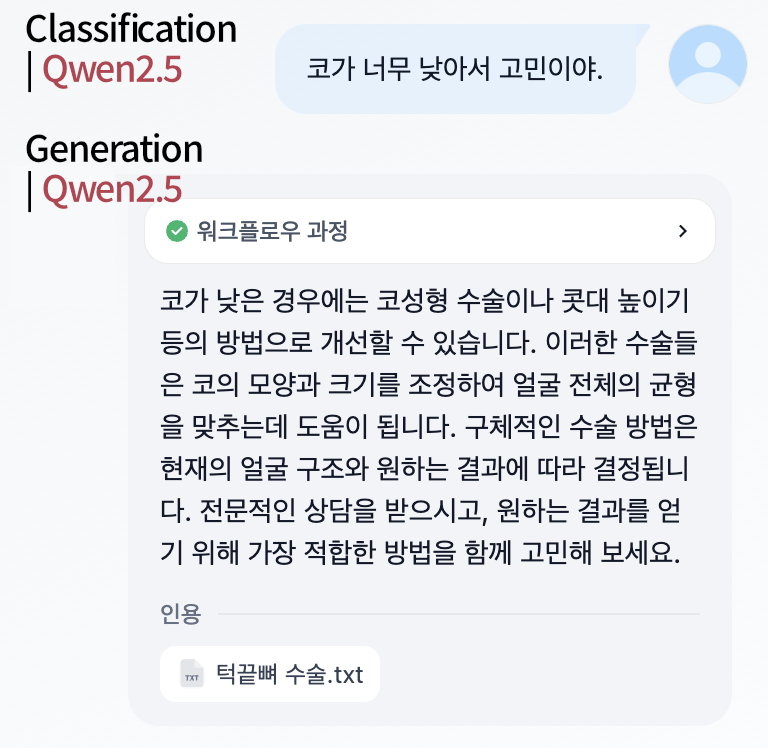
먼저 분류와 생성 모두 Qwen2.5:7b로 진행한 결과입니다. 보시다시피 첫번째 분류에서 정확하지 못한 결과를 주게되고, 이것이 이후 결과에 영향을 미친 것을 볼 수 있습니다. 잘못된 결과가 전달되었음에도 불구하고, 이를 잘 보정하여 결과를 생성한 것을 알 수 있습니다.
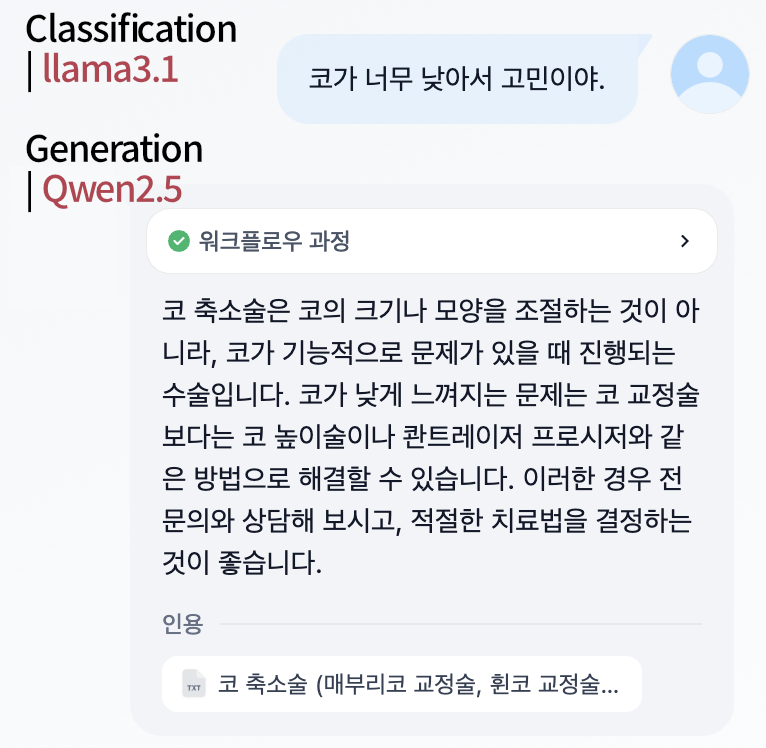
Gemma2:9b을 분류기로 사용한 모델 역시, 정확하지 못한 분류성능을 보여줍니다. "고민"을 이야기 했기 때문에, 코를 확대하는 수술을 주어야하는데, "작아서 고민"이라는 문구로 인해 반대의 문서를 가져온 것을 알 수 있습니다.
또한, 생성에 있어서, 위와 같이 보정을 해주는 것은 좋을 수 있지만, 어찌보면 Hallucination(환각현상)에 재대로 대응하지 못하는 문제를 RAG로 해결하고자하는 방법론에 적합하지 않을 수도 있습니다.
한번 모델 사이즈를 올려보겠습니다. 14b 모델을 사용하여 분류, 생성을 진행해보았습니다.
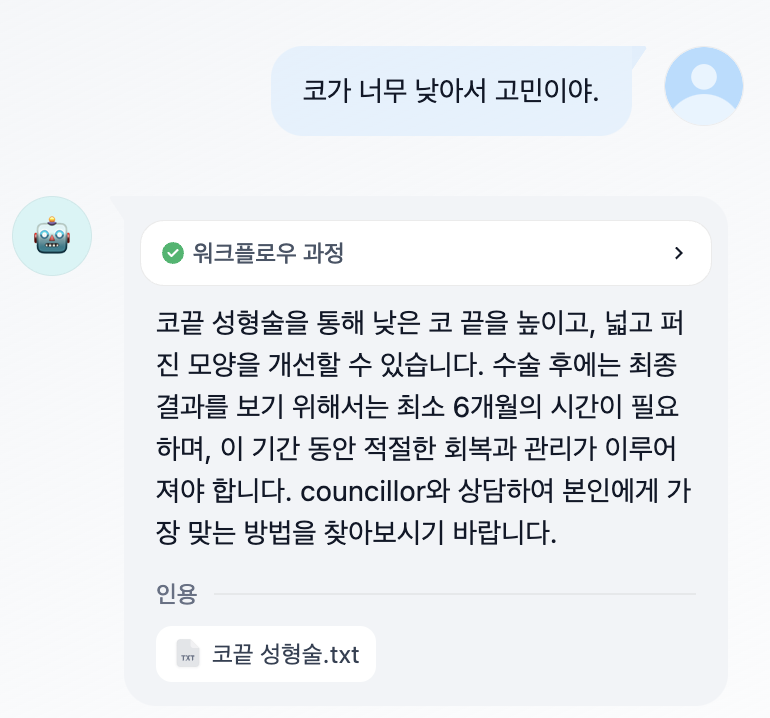
기존 대비 14b 모델이 보다 정확한 분류를 수행하는 것을 알 수 있습니다. 32b, 72b로 갈 수록 더욱 정확한 분류 성능을 보여줄 것을 알 수 있습니다.
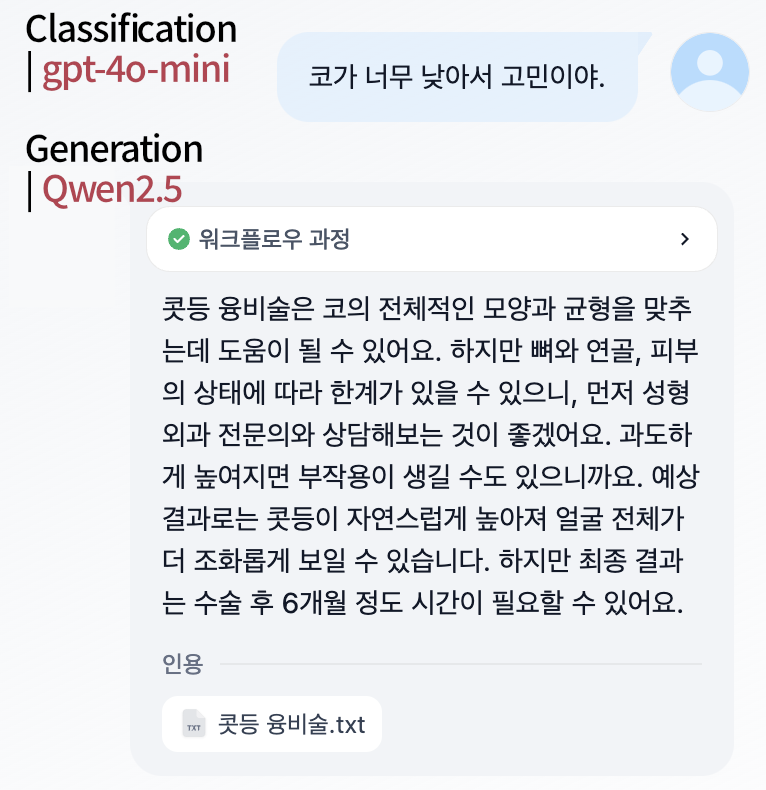
다음은 gpt-4o-mini를 분류기로 사용해준 버전입니다. 보시다시피, 분류 정확도가 매우 뛰어납니다. 아무래도, sLLM 보다는 높은 성능을 보여주는 것을 알 수 있습니다. Qwen2는 더 적은 파라미터에도 불구하고 비슷한 성능을 내주고 있습니다. 그러나, 비용적인 측면에서 gpt-4o-mini는 매우 저렴한 편임으로 각 기업과 상황에 맞는 적절한 모델을 선정해야할 필요가 있습니다.
주목할만한 점
다양한 크기의 모델(3b, 7b, 14b, 32b, 72b 등), 상업적으로 이용가능한 모델, RAG에 사용가능한 높은 포멧팅 정확도 등 오픈소스 언어모델의 발전을 주목해볼만 합니다. 간단한 테스크는 이제 파인튜닝 없이도 가능하고, QLoRA 파인튜닝을 통해 각 기업의 맞는 테스크 개발에 사용할 수 있을 것으로 예상됩니다.
Ollama에서 사용하기: https://ollama.com/library/qwen2.5
Huggingface에서 사용하기: https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e
공식 사이트 살펴보기: https://qwenlm.github.io/blog/qwen2.5/
