이 글은 그림으로 배우는 HTTP & Network와 HTTP 완벽 가이드 서적을 참고해 작성하였습니다.
HTTP Message는 Request, Response에 포함해 교환하는 정보를 의미한다.
Message 구조
HTTP Message 구조는 Header, CRLF, Body 순으로 구성되는데, 모두 문자열 형태로 이루어져 있고 CRLF는 개행 문자로 Header와 Body를 구분한다.

구체적으로, 위 그림과 같이 Request, Response 에 따라 Message Header 구조가 조금 다르다.
Request Line: 요청에 사용하는Method,URI,HTTP Version정보 포함Status Line:HTTP Version,상태 코드,사유 구절정보 포함Header Field- 요청/응답에 대한 여러 조건과 속성 등을 나타내는 정보
General Header,Request Header,Response Header,Entity Header로 구분된다.
- 그 외로 RFC에는 정의되지 않은
쿠키와 같은Header Field가 존재할 수 있다.
Encoding
HTTP 기반으로 데이터를 전송하는 경우, 인코딩을 통해 전송 효율을 향상시킬 수 있다.
Message Body VS Entity Body
기본적으로 Message Body와 Entity Body는 동일하지만, 전송 코딩이 적용된 경우에는 Entity Body의 내용이 변하기 때문에 Message Body와 달라진다.
즉, HTTP Message를 인터넷 운송 시스템의 컨테이너라고 생각한다면 HTTP Entity는 메시지의 실질적인 화물이다.

Entity Body는 전혀 가공되지 않은 데이터만을 담고 있고, 해당 raw data의 의미를 나타내는 정보는 Entity Header에 담겨 있다. 예를 들어, Content-Type 엔터티 헤더는 Entity Body를 어떻게 해석해야 하는 지를 알려주는 정보이고 Content-Encoding 엔터티 헤더는 Entity Body가 압축되었거나 추가적인 인코인 처리가 되었는지를 알려준다.
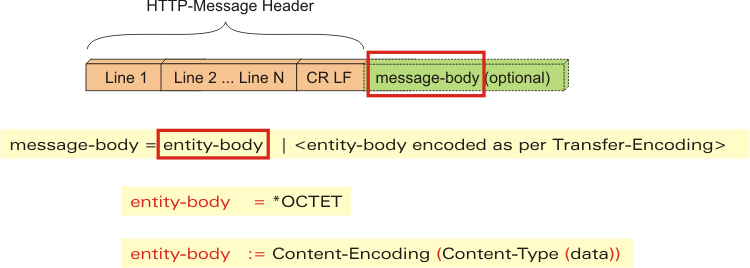
따라서, Message와 Entity에 대해 정의해보면 아래와 같다.
- Message : Octet Squence(octet = 8bit)로 이루어진 HTTP 전달 기본 단위
- Entity :
Request,ResponsePayload를 구성하는 Raw Data(인코딩, 압축 처리된 결과물)
콘텐츠 코딩을 통한 압축
콘텐츠 코딩(Content Coding)은 Entity에 적용하는 인코딩을 의미하는데, Entity 정보는 유지한 채로 압축한다. 콘텐츠 코딩 적용된 Entity는 클라이언트에서 디코딩을 시행한다.
따라서 콘텐츠 코딩을 통해서 Entity 용량(대역폭)과 전송 시간을 줄일 수 있다. 뿐만 아니라, 제 3자가 콘텐츠를 볼 수 없도록 콘텐츠를 암호해서 전송할 수도 있다.
콘텐츠 코딩에 대한 헤더 필드는 Content-Encoding이고, 적용할 수 있는 압축 목록은 아래와 같다.
- gzip(GNU zip)
- compress(UNIX의 표준 압축)
- deflate(zlib)
- identity(인코딩 없음)
여기서 주목할 점은 콘텐츠 코딩이 적용된 Entity Body의 원래 포맷을 알기 위해서는 반드시 Content-Type 헤더 필드가 존재해야만 한다.
또한, 콘텐츠 코딩이 적용되면, Entity Body의 크기가 작아지기 때문에, Content-Length 헤더 필드값은 Content-Encoding이 적용된 본문의 길이를 나타내야만 한다.
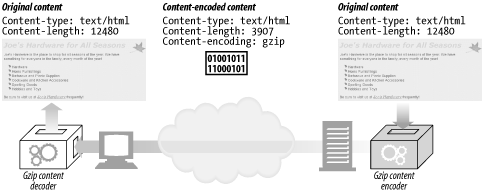
콘텐츠 코딩은 서버에서 압축하는 방법이고, 클라이언트에서 디코딩을 수행하게 된다.
여기서 서버에서 인코딩한 본문을 클라이언트가 해석하지 못할 경우를 대비해서, 클라이언트 요청시 Accept-Encoding 헤더 필드에 자신이 해석 가능한 인코딩 목록을 전달할 수 있다. 이를 통해서 서버는 클라이언트 상황에 적합한 인코딩을 수행하고, 만약 Accept-Encoding 없이 요청을 보내면 클라이언트가 모든 인코딩을 해석할 수 있다고 간주한다.
Chunked Transfer Coding
전송 코딩은 Message가 네트워크를 통해 전송되는 방법을 바꾸는 기능이다.
구체적으로, 전송 코딩 방식 중에는 Message를 Chunk로 분해해 전송하는 청크 전송 코딩이 있다.
또한, 전송 코딩은 Entity Body를 대상으로 하는 콘텐츠 코딩과 다르게 Message를 대상으로 적용한다.
청크 전송 코딩(Chunked Transfer Coding)은 Entity Body를 분할하는 기능으로, 사이즈가 큰 데이터를 분할해서 전송할 수 있다.
즉 청크 전송 코딩은 Message를 Chunk로 분해하고 순찬적으로 전송하는데, 메시지를 보내기 전에 전체 크기(Content-Length)를 알 필요가 없어진다. 본문이 동적으로 생성됨에 따라, 서버는 그중 일부를 버퍼에 담아서 Chunk와 Chunk 크기를 합쳐 하나씩 전송할 수 있다.
왜 모든 Chunk에 Chunk 크기를 함께 전송해야만 하는 것일까?
그 이유는 콘텐츠가 서버에서 동적으로 생성되어 전송 이전에 본문의 길이(Content-Length)를 알 수 없기 때문이다.
따라서 동적으로 본문이 생성됨에 따라, 서버는 그중 일부를 버퍼에 담은 뒤 한 덩어리를 그의 크기와 함께 전송해야만 한다. 본문을 모두 보낼 때까지 이 단계는 반복되고, 서버는 크기가 0인 Chunk로 본문이 끝났다는 것을 알린다.
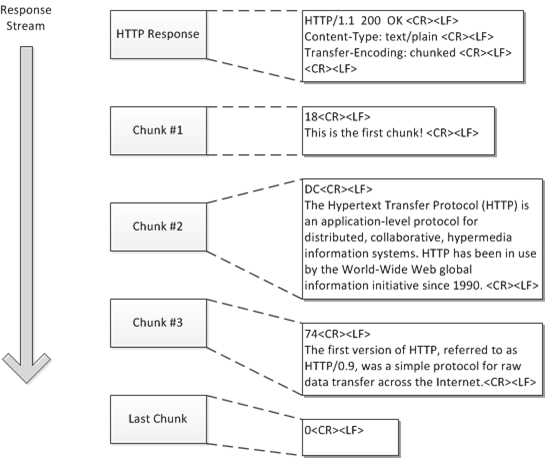
위 그림을 보면, Chunk 구조를 알 수 있다.
Chunk는 CRLF로 구분된 16진수 형식으로 이루어진 Chunk 크기와 Chunk 데이터로 이루어져 있다.
Chunk 크기는 바이트 단위로 오직 Chunk 데이터의 길이만을 의미한다.(CRLF, Chunk 크기는 미포함)
또한, 본문의 마지막을 의미하는 Chunk는 Chunk 크기가 '0'이다.
Multipart
MIME은 이미지 등의 바이너리 데이터를 아스키(ASCII) 문자열로 인코딩하는 방법과 데이터 타입을 나타내는 방법을 규정하고 있다.
Multipart는 MIME의 확장 사양으로 여러 다른 종류의 데이터를 전송하는 방법이고, HTTP도 Multipart를 지원하여 Message Body 내부에 여러 Entity를 포함해 전송할 수 있습니다.
multipart/form-data
HTTP Form 을 채워서 제출하면, 가변 길이의 텍스트 필드와 업로드할 객체는 각각 멀티파트 본문을 구성하는 하나의 파트가 되어 보내진다.
multipart/form-data 시작은 아래와 같이 이루어진다.
Content-Type: multipart/form-data; boundary=DfE22jmultipart는 각 파트를 구분하기 위해 boundary 구분자를 사용하고, 각 Entity 앞에는 -- 문자열을 추가한 boundary로 시작하고 마지막에는 -- 문자열로 감싼 boundary로 끝난다.
Content-Type: multipart/form-data; boundary=DfE22j
--DfE22j
Content-Disposition: form-data; name="helloworld"
Hello World
--DfE22j
Content-Disposition: form-data; name="file.txt"
Content-Type: text/plain
... file.txt 데이터 ...
--DfE22j--위와 같이, multipart는 각각의 헤더 필드가 포함한다.
또한, 파트 내부에 중첩으로 multipart를 포함할 수도 있다.(ex, 여러 파일 업로드)
Content-Type: multipart/form-data; boundary=DfE22j
--DfE22j
Content-Disposition: form-data; name="helloworld"
Hello World
--DfE22j
Content-Disposition: form-data; name="files"
Content-Type: multipart/form-data; boundary=BkV91u
--BkV91u
Content-Disposition: form-data; name="file.txt"
Content-Type: text/plain
... file.txt 데이터 ...
--BkV91u
Content-Disposition: form-data; name="image.png"
Content-Type: image/png
... image.png 데이터 ...
--BkV91u--
--DfE22j--
Content-Disposition헤더는 컨텐츠가 브라우저에inline으로 표현되어야 하거나,attachment(or, attachment; filename="cool.html")로 다운로드 여부에 대한 정보이다.
또한,multipart/form-data에서Content-Disposition헤더는 각 파트의 필드에 대한 정보를 제공한다.
multipart/byteranges
범위 요청(206(Partial Content))에 대한 HTTP 응답 역시 multipart로 전송될 수 있는데, 각 파트가 다른 범위를 담고 있는 본문으로 응답한다.
HTTP/1.1. 206 Partial Content
Date: Sun 13 Aug 2011 11:23:33 GMT
Content-Type: multipart/s-byterange; boundary=Cd21Ddk
--[Cd21Ddk]
Content-Type: text/plain
Content-Range: bytes 0-204/800
... 800bytes 크기의 문서중에서 0~204사이의 bytes 데이터 ...
--[Cd21Ddk]
Content-Type: text/plain
Content-Range: bytes 300-500/800
... 800bytes 크기의 문서중에서 300~500사이의 bytes 데이터 ...
--[Cd21Ddk]
Content-Type: text/plain
Content-Range: bytes 750-799/800
... 800bytes 크기의 문서중에서 750~799사이의 bytes 데이터 ...
--[Cd21Ddk]--참고 자료
Range Request
HTTP는 클라이언트가 문서의 일부분이나 특정 범위만 요청할 수 있도록 지원한다.
만약 용량이 큰 데이터를 다운로드 받고 있는 과정에서 네트워크 문제로 커넥션이 끊기면 처음부터 다시 다운받아야 한다.
범위 요청(Range Request)을 이용하면, 클라이언트가 중단된 지점부터 엔터티의 범위를 지정해 요청할 수 있다.
Range Request은 Request 헤더에 Range 필드를 사용해서 리소스의 bytes 범위를 지정할 수 있다.
// 100 ~ 200 byte 범위 요청
Range: bytes = 100-200
// 100 byte 이후 부분 요청
Range: bytes = 100-
// 처음부터 200 byte 까지 요청
Range: bytes = -200또한, Range 헤더 필드는 복수의 범위 설정도 가능하다.
// 복수 범위 요청
// 100 ~ 200 byte 범위와 300 byte 이후 부분 요청
Range: bytes = 100-200, 300-Range Request에 대한 응답은 상태 코드가 206 Partial Content 메시지를 전송하고, 복수 범위를 요청한 경우에는 multipart/byteranges 응답 메시지를 받게 된다.
만약 서버가 Range Request를 지원하지 않는 경우에는 200 OK 상태 코드의 응답을 받게 되고, 지원하는 경우에는 자신이 측정 가능한 단위를 나타내는 Accept-Ranges: bytes 헤더를 응답 메시지에 포함한다.
참고 자료
Content Negotiation
Content Negotiation은 클라이언트와 서버가 제공하는 리소스의 내용에 대해서 협상하는 것이다.
즉, 하나의 URL에 대해 클라이언트와 서버가 가장 적합한 리소스를 제공하기 위한 구조이다.
예를 들어, [www.something.com](http://www.something.com) URL에 대해 영어권에 사용자는 영어로 이루어진 리소스를 받길 원할 것이고, 스페인권 사용자는 스페인어로 구성된 리소스를 원할 것이다.
이를 위해, Content Negotiation은 제공하는 리소스를 언어(Language), 문자 세트(Charset), 인코딩 방식(Encoding) 등의 Request Header 기준으로 협상한다.
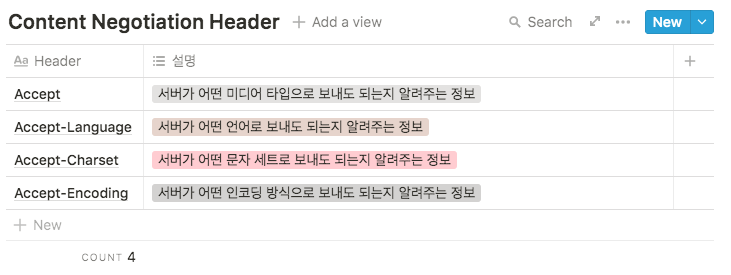
콘텐츠 협상 방식은 크게 세 가지로 구분하는데 하나씩 살펴보자.
클라이언트 주도 협상
클라이언트 주도 협상 방식은 서버가 요청을 받았을 때 가능한 페이지 목록을 응답으로 전달하고 클라이언트가 원하는 것을 선택하도록 하는 방법이다.
리소스의 내용을 선택하는 방법은 서버가 가능한 선택지를 HTML로 표현해 응답하거나, 300 Multiple Choices 상태 코드로 응답을 할 수도 있다.
300 Multiple Choices 상태 코드의 응답에서는 선택지를 제고하기 위해 Link와 Location 헤더를 사용할 수 있다.
Link 헤더는 의미적으로 HTML <link>와 동일하며 이동할 수 있는 Link 정보를 제공한다. Location 헤더를 통해서는 이동할 수 있는 Link 중에 디폴트(Default)를 제안한다.
HTTP/1.1 300 Multiple Choices
Link: </boards/eng> rel="alternate"
Link: </boards/es> rel="alternate"
Content-Type: text/html
Location: /boards/ko하지만, 클라이언트 주도 협상에는 몇 가지 단점이 있다.
사용자가 원하는 내용을 얻기까지 최소 두 번의 요청이 필요하고, 이로인해 대기시간이 증가한다는 것이다.
뿐만 아니라, 각 페이지에 대한 여러 개의 URL이 필요하게 되는 단점이 있다.
참고 자료
서버 주도 협상
클라이언트 주도 협상의 단점은 서버-클라이언트 간에 통신이 많다는 것인데, 서버 주도 협상으로 이러한 문제를 해결할 수 있다.
서버 주도 협상에서 서버가 어떤 페이지를 응답할 지 결정하기 위해, 클라이언트는 리소스에 대한 자신의 선호 정보를 요청 헤더로 전달한다.
서버는 요청 헤더 정보를 기반으로 협상을 하는데 Accept 관련 헤더, User-Agent 헤더를 기반으로 내용을 선정해 응답한다.
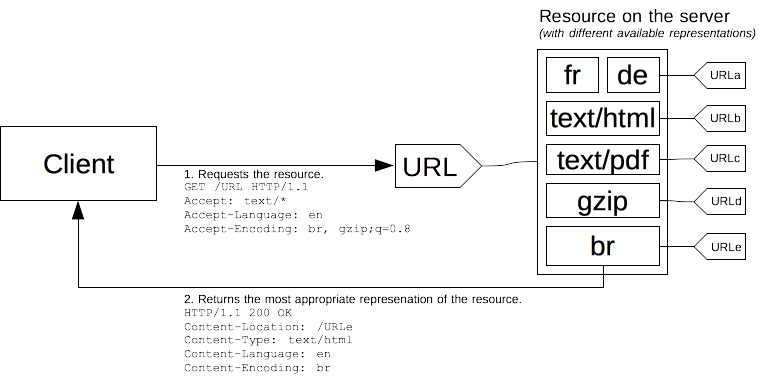
또한, Accept 관련 헤더는 클라이언트가 원하는 정보가 여러 개 전달될 수 있는데, 선호도(quality value)를 통해서 서버는 우선순위로 선택할 수 있다.
Accept-Language: en;q=0.1, es;q=1.0, ko;q=0.5위와 같이 사용자가 원하는 언어 목록에 0.0 ~ 1.0 선호도를 설정하면, 서버는 자신이 지원하는 문서에 따라 우선적으로 응답한다.
서버 주도 협상 또한 단점이 존재하는데, 여러 버전의 문서를 서버에 가지고 있어야 하고 요청 헤더에 따라 적합한 리소스를 선택에 응답해주어야 한다는 것이다. 이러한 과정은 서버에 부하를 일으킨다.;
참고 자료
투명 협상
투명 협상은 중개자 프락시를 사용해서, 클라이언트와의 메시지 교환을 최소화하는 동시에 서버 주도 협상으로 인한 부하를 서버에서 제거하는 방법이다.
중개자 프락시는 단일한 URL을 통해 접근할 수 있는 문서의 여러 다른 사본을 저장하고 있고, 서버가 의사결정 프로세스를 중개자에게 알려주었다면 클라이언트와 협상이 가능해진다.
투명한 내용 협상을 지원하기 위해, 서버는 클라이언트의 요청에 가장 적합한 것이 무엇인지 판별하려면 어떤 요청 헤더를 검사해야 하는지 프락시에게 반드시 알려주어야 한다.
이는 서버가 프락시에게 Vary 응답 헤더를 전달하여, 중계자에게 내용 협상을 위해 어떤 헤더를 사용하고 있는지 알려줄 수 있다.
HTTP Vary 응답 헤더는 서버가 문서를 선택하거나 콘텐츠를 생성할 때 고려한 클라이언트 요청 헤더를 모두 나열한 정보이다.

새로운 요청이 도착했을 때 다음과 같은 과정을 거친다.
- 중계자 프락시는 내용 협상 헤더를 보고 가장 적합한 캐시된 응답을 찾는다.
- 캐시된 응답안에
Vary응답 헤더가 존재한다면, Vary응답 헤더가 가리키는 헤더들의 값이 새로운 요청과 캐시된 요청에서 동일하면 캐시된 응답을 전달한다.Vary응답 헤더가 가리키는 헤더들의 값이 새로운 요청과 캐시된 요청에서 동일하지 않으면, 서버에 요청을 다시 전달하고, 그에 대한 응답을 캐시한다.
참고 자료
