
이 글은 그림으로 배우는 HTTP & Network와 HTTP 완벽 가이드 서적을 참고해 작성하였습니다.
Chrome 브라우저를 이용해 특정 페이지를 검색하는 일반적인 상황을 가정해보자.
우선, 브라우저 검색창에 URL을 입력할 것이고 이에 대한 결과로 원하는 페이지가 노출될 것이다.
좀 더 구체적으로 네트워크 관점에서 살펴보면, 브라우저 주소 입력창에 지정된 URL에 의지해서 웹 서버로부터 리소스라고 불리는 파일 등의 정보를 얻는 것이다.
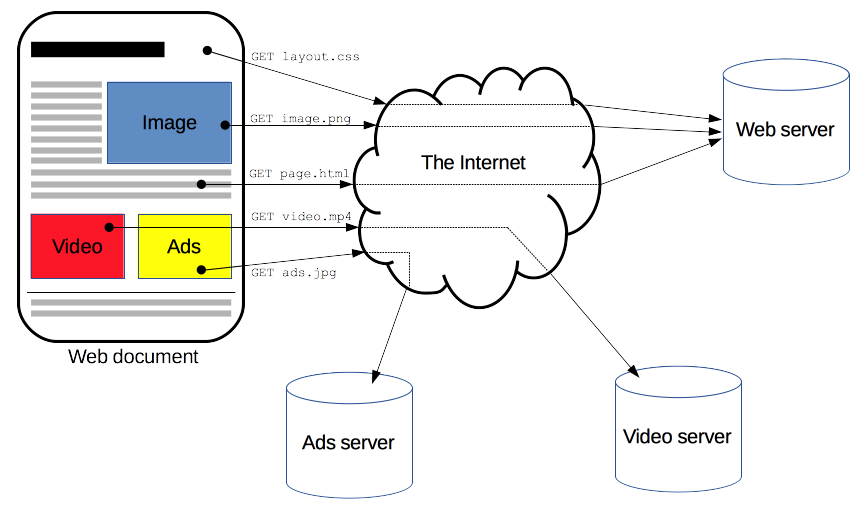
이러한 과정은 HTTP 라는 프로토콜에 기반으로 이루어지는데, 앞으로 HTTP 프로토콜에 대해서 알아볼 것이다.
근데 앞에서 프로토콜이라는 용어를 사용하였는데, 이는 무엇일까?
프로토콜
네트워크를 통해서 컴퓨터 상호간에 통신하기 위해서는 서로 같은 방법으로 통신하지 않으면 안된다. 예를 들어, 어떻게 상대와 통신을 시작하고 어떠한 언어로 이야기하며 어떻게 종료하는 등에 **규칙**을 결정해야만 한다. 즉, 서로 다른 하드웨어와 운영체제을 가진 컴퓨터가 통신하기 위해서는 규칙이 필요하다.
즉, 네트워크에서는 이러한 규칙을 프로토콜이라 부른다.
프로토콜의 종류는 많은데, 그 중에서 HTTP는 HyperText Transfer Protocol 약자로 HTML 문서와 같은 리소스들을 가져올 수 있도록 해주는 프로토콜이다.
뿐만 아니라 HTTP은 TCP/IP 프로토콜을 기반으로 동작하는데, HTTP를 이해하기 위해서는 TCP/IP 대한 이해가 필요하다.(자세한 내용은 다루지 않으므로 다른 전문 서적을 참고 바람)
TCP/IP
TCP/IP는 4계층인 애플리케이션 계층, 전송 계층, 인터넷(네트워크 링크) 계층, 데이터 링크 계층으로 계층화되어 있다.
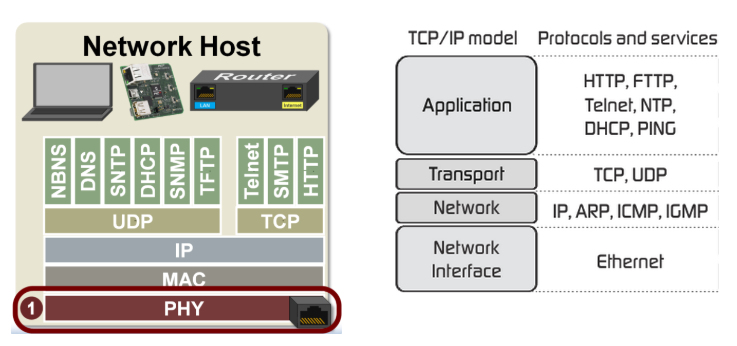
계층화는 왜 필요한가?
계층적으로 나눠놓은 이유는 설계상에 이점이 있기 때문이다.
예를 들어, 중간의 트랜스포트 계층의 사양이 변경되었다고 가정해보자.
만약 하나로 관리할 경우 트랜스포트 계층의 변경으로 인해서 전체를 바꿔야만 한다. 하지만, 계층화가 되어 있다면, 해당 계층만 변경하면 되기 때문에 변경의 유연함이 좋아진다.
뿐만 아니라, 계층 단위로 역할을 명확하게 구분할 수 있다는 장점이 있다.
예를 들어, 애플리케이션 계층은 다른 계층의 역할인 '어떤 경로로 상대방에게 데이터를 전달하는가?'와 같은 고려를 전혀 하지 않아도 된다.
즉, 애플리케이션 계층은 자신이 담당한 역할만 충실히 수행하면 되기 때문에, 각 계층 별로 역할을 명확하게 나눌 수 있다.
그럼 이제 각 계층이 어떤 역할을 하는지 간략하게 살펴보자.
애플리케이션 계층
애플리케이션 계층은 OSI 7계층 중 응용, 표현, 세션 영역에 대응하는 계층으로, 기본적으로 프로그램에 네트워크 서비스를 제공한다.
내부적으로는 프로그램 간에 주고받는 메시지를 압축/암호화할 뿐만 아니라, 상대방과의 주고 받을 데이터 형식을 결정한다.
애플리케이션 계층은 위와 같은 내부적인 작업을 토대로 데이터를 가공해서 전송 계층에 메시지를 전달한다.
가령, HTTP 경우에는 애플리케이션으로 부터 전달받은 URL, Method, Header 정보를 바탕으로 HTTP Request Message를 만들어 전송 계층에 전달한다.
추상적으로 생각해보면, 애플리케이션 계층은 기반이 되는 전송 계층 프로토콜을 사용하여 호스트(프로세스) 간 연결을 확립한다.
애플리케이션 계층에 해당하는 프로토콜은 HTTP, FTP, SMTP 등이 있다.
전송 계층
전송 계층은 주고받는 데이터 흐름을 제어한다.
대표하는 전송 계층 프로토콜은 TCP와 UDP로 나뉘는데, 두 프로토콜의 차이점은 신뢰성 보장 여부이다.
신뢰성을 보장해야 하는 경우에는 TCP 프로토콜을 사용하는데, TCP 프로토콜은 상대방과 데이터를 주고받는 과정에서 세그먼트대한 흐름 제어와 혼잡 제어를 한다.
세그먼트는 애플리케이션 계층로 부터 받은 메시지를 MSS(Max Segment Size)로 나누어 인터넷(네트워크 링크) 계층에 전달하는 단위이다.
또한, 각 세그먼트는 송/수신처 포트 번호, Sequence Number, Acknowledgment Number 등의 TCP 헤더 정보를 포함한다.
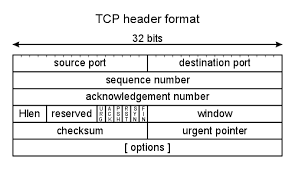
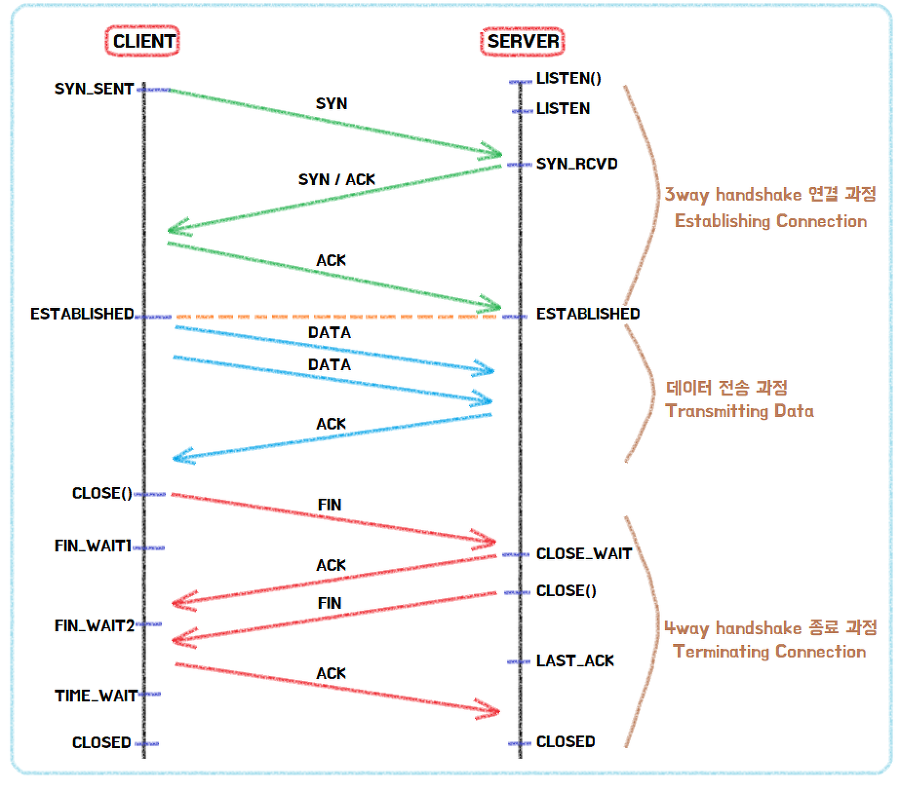
전송 계층에서는 3-way handshake(SYN, SYN/ACK, ACK) 과정을 통해서 상대방과 커넥션을 수립하고, 4-way handshake 과정으로 커넥션을 종료한다. 이러한 안전한 커넥션을 보장하기 위해 수행되는 handshake는 세그먼트의 TCP 헤더 정보를 기반으로 이루어진다.
인터넷 계층(네트워크 계층)
네트워크 계층은 네트워크 상에 패킷의 이동을 다룬다.
패킷은 전송하는 데이터의 최소 단위를 의미하고, 네트워크 계층은 어떠한 경로를 통해서 상대방에게 패킷을 전달할 것인 지를 결정한다. 또한 패킷은 전달받은 세그먼트에 IP 헤더 정보가 추가된 형태인데, IP 헤더는 송/수신처 IP 등의 정보를 가지고 있다. 송/수신처 IP를 기반으로 논리적인 목적지에 도달할 수 있게 된다.
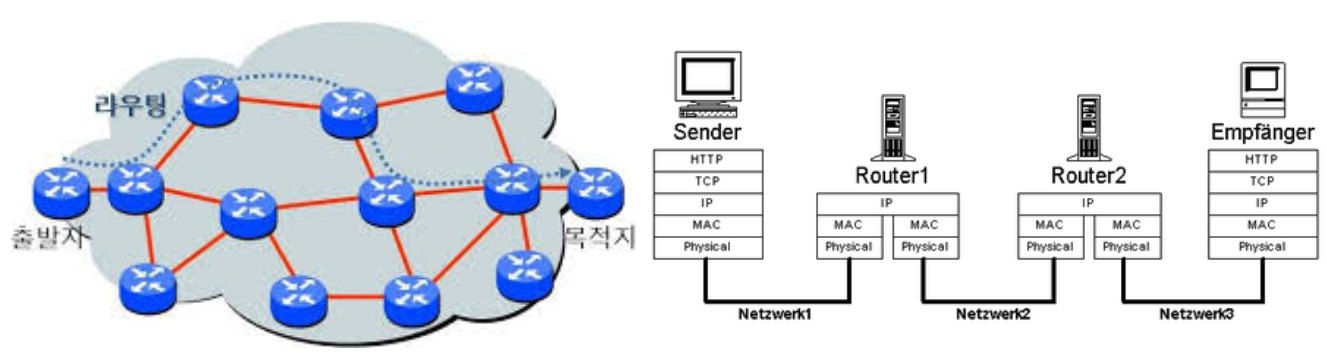
패킷은 여러대의 스위치, 라우터 같은 여러 네트워크 기기를 거쳐 상대방에게 전달되는데, 이동할 수 있는 많은 경로 중에서 하나의 길을 선택하는 것이 네트워크 계층의 역할이다.
네트워크 계층에는 IP, ARP, ICMP 프로토콜이 있다.
데이터 링크 계층
데이터 링크 계층은 네트워크에 접속하는 하드웨어적인 측면을 다룬다.
즉, 데이터 링크 계층은 운영체제를 통해서 어느 네트워크 인터페이스 카드(NIC)로 프레임을 전달할 지를 결정한다.
컴퓨터는 네트워크를 사용하기 위해서는 네트워크 인터페이스 카드(NIC)라는 장치가 필요하다.
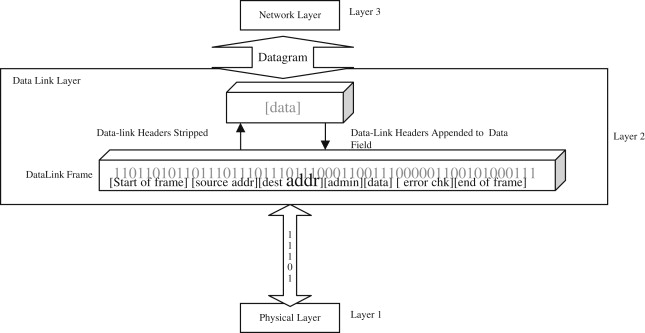
네트워크 인터페이스 카드(NIC)는 고유한 주소값을 갖는데, 프레임은 패킷에 Ethernet 헤더(송/수신처의 MAC 주소 등의 정보로 이루어짐) 추가한 단위이다.
데이터 링크 계층에서는 주로 이더넷(Ethernet) 프로토콜가 사용하는데, 이더넷(Ethernet) 프로토콜은 네트워크 계층에서 ARP 프로토콜으로 얻은 MAC 주소를 이용해서 다음에 이동할 네트워크 기기에게 프레임을 전송한다.
여기서 전달 매체는 주로 케이블을 통한 아날로그 신호로 전달되는데, 네트워크 인터페이스 카드(NIC)가 전달받은 프레임을 아날로그 신호로 변환해서 자신과 연결된 케이블로 전송하는 것이다.
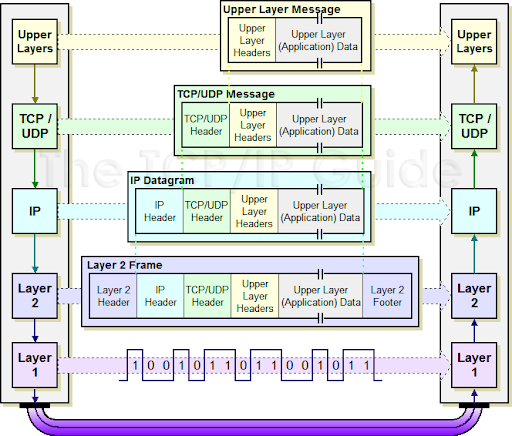
캡슐화
앞에서 살펴본 각 계층에서는 헤더에 필요한 정보를 추가하는 것을 알 수 있다.
애플리케이션 계층으로 부터 전달받은 메시지에는 TCP 헤더가 추가되고, 전송 계층으로 부터 전달받은 세그먼트에는 IP 헤더가 추가된다. 또한 네트워크 계층으로 부터 전달받은 패킷에는 Ethernet 헤더가 추가되는데, 이렇게 상위 계층에서 전달받은 데이터에 헤더를 추가하는 과정을 캡슐화라고 부른다.
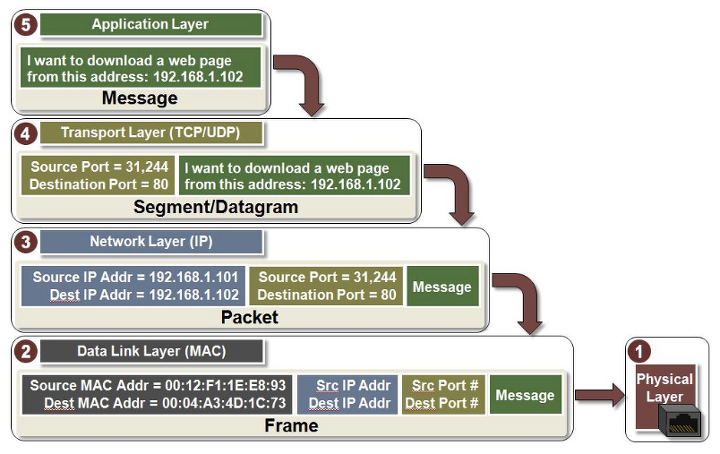
각 계층별로 캡슐화하는 이유는 전송받은 데이터를 상대방 또한 계층적으로 처리할 수 있기 때문이다.
상대방은 전송받은 데이터의 헤더를 각 계층마다 하나씩 잘라서 사용한다. 즉, 상호간의 각 프로토콜에서 필요한 정보를 헤더로 주고받을 수 있는 것이다.
HTTP 특징
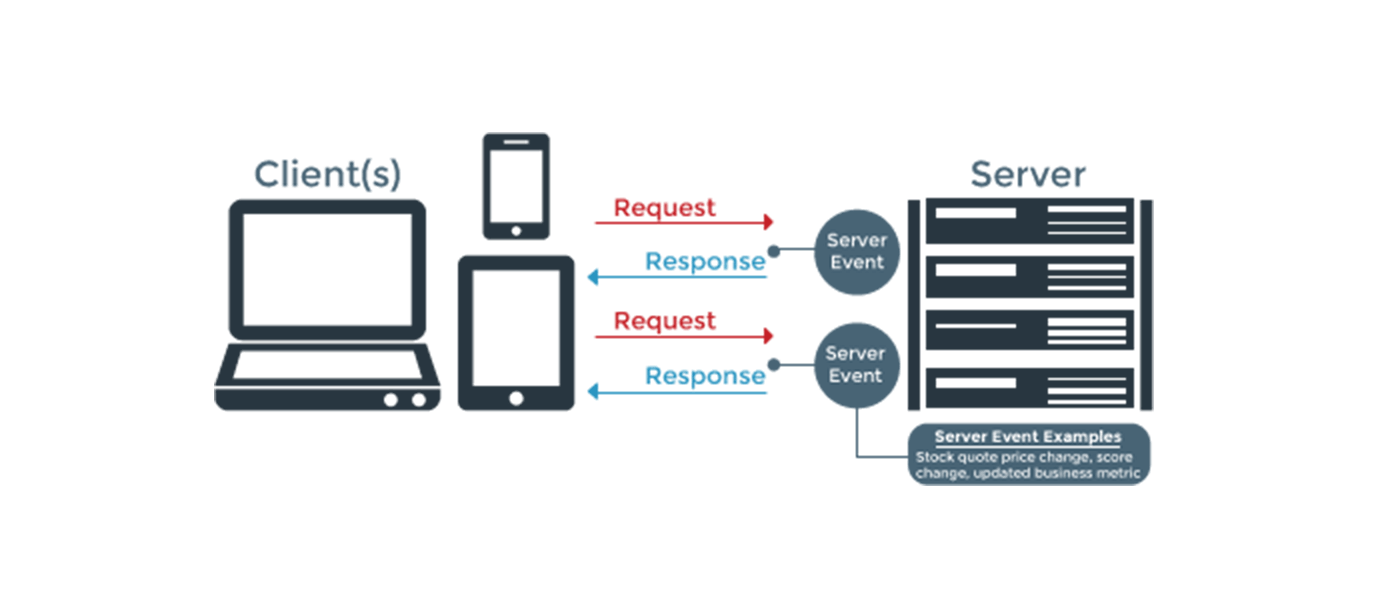
서버-클라이언트
HTTP는 서버와 클라이언트 간에 통신을 한다.
구체적으로, 리소스 요청을 하는 쪽이 클라이언트이고 리소스를 제공하는 쪽이 서버이다.
한번의 HTTP 통신에서 무조건 클라이언트-서버 관계는 형성되고, HTTP는 클라이언트와 서버의 역할을 명확하게 구별한다.
Request-Response
클라이언트는 HTTP 프로토콜로 Request를 송신하고, 그에 대한 결과로 서버는 Response를 응답한다. 즉, HTTP 통신의 시작은 클라이언트로 부터 시작되고 서버는 Request없이 Response 할 수 없다.
Request
Request 내용을 살펴보자.
GET /ko/docs/Web/HTTP/Overview HTTP/1.1
Host: developer.mozilla.org
Accept: text/html우선 GET은 METHOD라고 부르며 수행하고자 하는 동작을 정의하는 것이다.
/ko/docs/Web/HTTP/Overview는 Request URI라 부르며, 리소스의 경로를 나타낸다.
HTTP/1.1 문자열은 해당 Request 메시지에서 사용중인 HTTP Version을 의미한다.
마지막으로, Host: [developer.mozilla.org](http://developer.mozilla.org), accept: text/html는 Request 헤더 필드이다.
즉, Request Message는 METHOD, URI, Version, Headers, Entity 본문으로 구성된다.
구성도를 잡아보면 아래와 같다.
<메서드> <요청 URL> <버전>
<헤더>
<엔티티 본문>Response
서버는 Response를 이용해서 Request 처리 결과를 클라이언트에게 보내준다.
HTTP/1.1 200 OK
Date: Fri, 03 Jul 2020 02:40:54 GMT
Content-Length: 576
Content-type: text/html; charset=utf-8
<!DOCTYPE html>
<html lang="ko">
<head>
...
</head>
<body>
...
...
...
</body>
</html>첫 줄의 HTTP/1.1은 Response Message에서 사용한 HTTP 버전을 의미한다.
200 OK는 Request의 처리 결과를 나타내는 상태 코드와 설명이다.
다음줄부터 빈줄 이전까지는 Response의 헤더 필드를 의미하고, 빈 줄 이후에는 Body라고 부른다.
Body의 시작부는 빈줄(두 번의 \r\n) 이후부터 시작된다는 것을 명심하자.
즉, Response Message는 Version, 상태코드, 사유 구절, Headers, Entity 본문으로 구성된다.
<버전> <상태 코드> <사유 구절>
<헤더>
<엔티티 본문>Stateless
HTTP는 상태를 지속적으로 유지하지 않는 Stateless 프로토콜이다.
즉 HTTP는 Request/Response 교환 과정에서 독자적으로 상태를 관리하지 않기 때문에, Request를 보낼 때마다 새로운 Response가 생성된다.
그러나 점차 Stateless 만으로는 처리하기 힘든 상황이 발생하였다.
예를 들어 쇼핑몰에 로그인한 경우이다. 로그인 상태는 다른 페이지로 이동하더라도 유지되어야 하기 때문에, Response 결과 상태가 어딘가에 유지될 필요가 있다. 만약 로그인 상태를 애플리케이션에서 관리하고 모든 요청에 포함시켜야 한다면 보안상 안정성이 매우 떨어질 것이다.
따라서, HTTP 기반의 통신에서도 브라우저를 이용해 지속적으로 상태를 관리할 수 있도록 쿠키(Cookie)라는 기술이 도입되었다. 브라우저에 쿠키 정보를 저장하기 때문에, HTTP 프로토콜의 stateless 특성은 유지된다.
Method
특정 리소스에 대한 Request를 보내는 경우에 Method를 지정할 수 있다.
그럼, 왜 Method를 이용하는 것일까?
Method는 URI에 해당하는 리소스가 지시한 행동으로 처리되도록 하는 방법이다.
Method 지시자를 이용하면 동일한 URI 대해 다른 행동을 기대할 수 있고, 어떤 목적을 위한 요청인지를 나타낼 수 있다.
따라서 HTTP API를 잘 설계한다면, 특정 리소스에 어떠한 목적으로 요청했는지를 URI와 Method만으로도 유추할 수 있다.
뿐만 아니라, 동일한 리소스에 대한 여러가지의 동작을 URI로만 설계한 것보다 간결하게 구성할 수 있다.
아래의 예시를 보자.
// 잘못된 HTTP API 설계
http://www.something.com/select/user
http://www.something.com/create/user
http://www.something.com/change/user
http://www.something.com/delete/user
// Method 이용
http://www.something.com/users
조회: GET, 생성: POST, 수정: PUT, 삭제: DELETE즉 쓸데없이 길어지는 URI를 제거할 수 있고, 하나의 URI로 다양한 표현을 할 수 있다.

지속 연결
만약 응답받은 HTML가 여러 이미지가 포함하고 있는 경우를 생각해보자.
브라우저는 HTML 문서를 응답받고 나서 순차적으로 이미지를 로드하기 위해 요청을 다시 보낼 것이다.
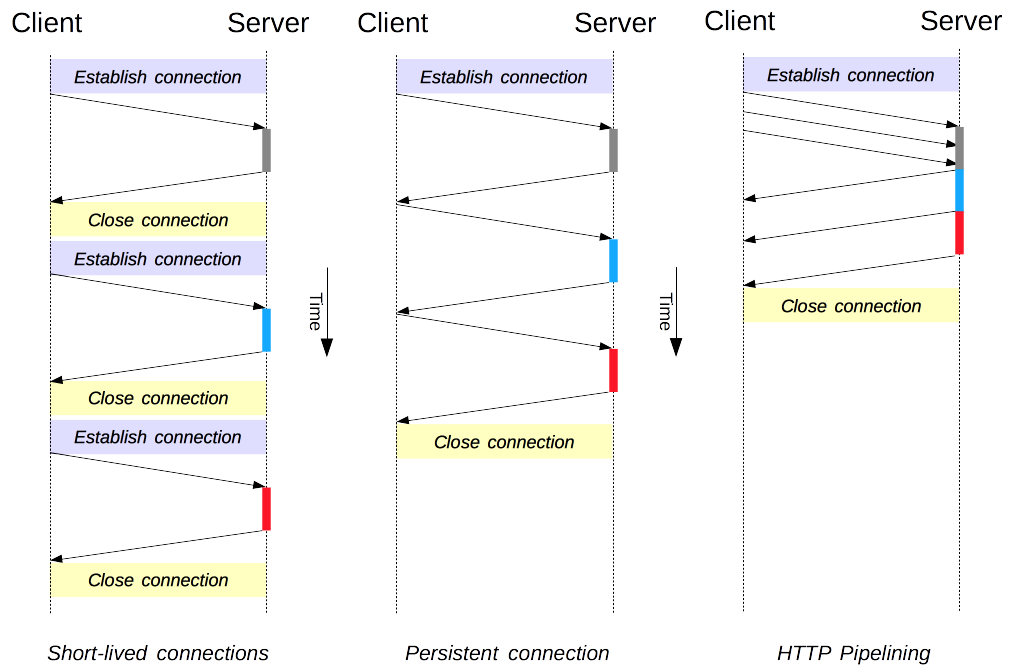
이 과정에서 이미지 요청을 보낼 때마다 TCP 연결/종료함으로써 불필요한 네트워크 리소스를 낭비하게 된다.
Persistent Connections
HTTP는 이와 같이 매번 TCP 연결/종료하는 문제를 해결하고자 지속 연결(Persistent Connections) 방법을 고안하였다.
지속 연결은 두 피어 중에 어느 한 쪽이 명시적으로 연결을 종료하지 않는 이상 TCP 연결을 지속적으로 유지한다는 것이다.
따라서, 지속 연결을 통해서 TCP 커넥션의 연결/종료로 발생하는 오버헤드를 낮출 수 있기 때문에 서버의 부하가 경감된다. 이로 인해, HTTP Request, Response가 빠르게 완료되며 페이지를 빠르게 노출할 수 있다.
HTTP/1.1 부터는 이미 연결된 TCP를 재사용하는 지속 연결 기능을 기본적(Default)으로 제공하지만 표준 명세에서 없어졌다.
이제 지속 연결 을 Express 서버에 적용시킨 예제를 살펴보자.
// keep-alive-test.js
const logger = require('morgan');
const http = require('http');
const path = require('path');
const express = require('express');
const app = express();
const server = http.createServer(app)
// 서버를 3000 포트로 띄우고
// 커넥션 버퍼 큐 사이즈는 0으로 설정
.listen('3000', 0)
// 모든 http 요청마다 이벤트 발생
.on('request', (request) => {
console.log('request', request.socket.remotePort)
})
// 새로운 TCP 연결시 이벤트 발생
.on('connection', (socket) => {
console.log('connection', socket.remotePort);
socket
// 완전히 TCP 종료한 경우 이벤트 발생
.on('close', () => {
console.log('connection', socket.remotePort, 'close')
})
// 상대방이 TCP 커넥션 종료를 위해 FIN 패킷을 보낸 경우 이벤트 발생
.on('end', () => {
console.log('connection', socket.remotePort, 'end')
});
});
// 서버측 Keep Alive 10초 대기시간(ms) 지정
server.keepAliveTimeout = 10000;
app.use(logger('dev'));
app.get('/', function (req, res, next) {
// 클라이인트측 Keep Alive 3초 대기시간(s), 2개의 요청 개수 지정
res.set('Keep-Alive', 'timeout=3, max=2');
res.sendFile(path.join(__dirname, 'index.html'));
});
app.get('/user', function (req, res) {
res.json({name: '철수'});
});<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<title>Keep Alive Test</title>
<link rel="icon" href="data:,">
</head>
<body>
<button onclick='fn()'>요청</button>
<script>
const fn = async function () {
for (let c of [1, 2, 3]) {
await fetch('/user', {method: 'GET'});
}
}
</script>
</body>
</html>지속 연결을 위한 Keep-Alive 설정은 Express 서버에서도 지원한다.
따라서 서버에서도 지정한 대기 시간만큼 연결을 유지할 수 있고, Response 헤더에 Keep-Alive: timeout=3, max=2와 같이 포함해 브라우저에서 지속 연결을 대기 시간만큼 유지시 킬 수 있다.
또한 지속 연결을 사용하고 싶다면, 클라이언트는 Request 헤더에 Connection: keep-alive를 추가해야만 한다. 지속 연결을 지원하는 동일한 헤더를 Response 헤더에 보내고 지원하지 않으면 Connection: keep-alive 헤더없이 응답한다.
그럼 출력 결과를 분석해보자.
connection 64441 // 브라우저 64441 포트와 서버 3000 포트 TCP 커넥션 연결됨
connection 64442 // 브라우저 64442 포트와 서버 3000 포트 TCP 커넥션 연결됨
request 64441
GET / 200 5.307 ms - 398
request 64441
GET /user 200 2.068 ms - 17
request 64441 // 64441 포트에 연결된 TCP 커넥션 재활용
GET /user 200 0.209 ms - 17
request 64441 // 64441 포트에 연결된 TCP 커넥션 재활용
GET /user 200 0.210 ms - 17
request 64441 // 64441 포트에 연결된 TCP 커넥션 재활용
GET /user 200 0.441 ms - 17
request 64441 // 64441 포트에 연결된 TCP 커넥션 재활용
GET /user 200 0.353 ms - 17
request 64441 // 64441 포트에 연결된 TCP 커넥션 재활용
GET /user 200 0.275 ms - 17
connection 64442 end // 브라우저에서 FIN 패킷 전송
request 64441
GET /user 200 0.430 ms - 17
connection 64442 close // 64442 포트에 연결된 커넥션 완전 종료됨
request 64441
GET /user 200 0.331 ms - 17
request 64441
GET /user 200 0.312 ms - 17
connection 64441 close // 64441 포트에 연결된 커넥션 완전 종료됨index.html 요청시 브라우저에서 왜 두 개의 요청을 보내는 이유는 정확히 모르겠으나, 아무튼 요청을 보낸다.
이후, 64441 포트에 연결된 TCP 커넥션을 이용해서 요청과 응답이 전송된다.
다음으로 3초 언저리에서, 브라우저는 64442 포트에 연결된 TCP 커넥션을 종료하기 위해 서버에 FIN 패킷을 전달해 커넥션을 Close 한다. 정확하지는 않지만, Chrome 브라우저는 3초간 어떠한 요청도 없을 경우에는 커넥션을 종료하는 것으로 보이고, 응답 헤더에 전달받은 Keep-Alive: timeout=3, max=2의 max는 무시되는 것으로 보인다.
마지막으로, 서버에서는 10초가 지난 뒤에 64441 포트에 연결된 TCP 커넥션을 종료한다.
지속 연결을 통해서 TCP 연결/종료 비용을 줄일 수 있지만, 그에 대한 Side Effect도 분명히 발생한다.
첫 번째로, 서버가 지속 연결을 지원한다면 모든 요청마다 커넥션을 유지해야 하는 문제가 있다. 이로 인해, 프로세스 수가 증가하여 MaxClient를 초과하게 될 뿐만 아니라, 메모리 사용량이 기하급수적으로 늘어나 과부하 상태가 될 수 있다.
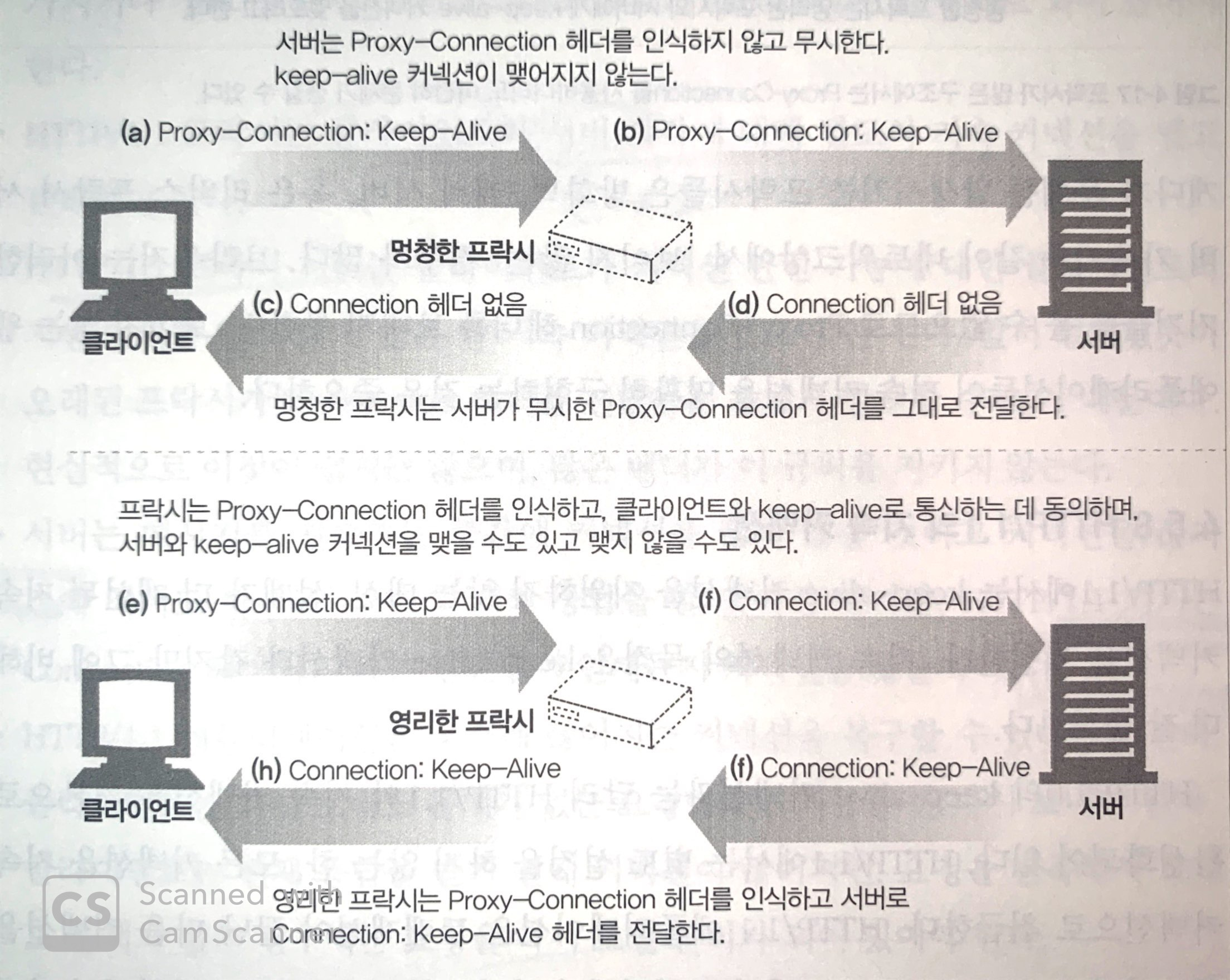
두 번째로, Connection: keep-alive을 해석하지 못하는 프록시 중계 서버를 통해서 목적지 서버에 도달하는 경우, 프록시 중계 서버와 목적지 서버 간에 지속 연결이 계속해서 유지되기 때문에 두 번째 요청은 계속해서 대기하는 문제가 발생한다.
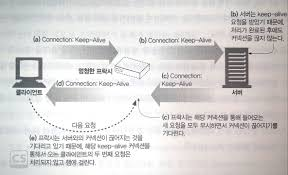
이러한, 멍청한 프록시를 해결하기 위한 차선책으로 Proxy-Connection 헤더가 존재한다.
만약 멍청한 프록시라면 Proxy-Connection를 목적지 서버에 전달하여도 서버가 인식할 수 없기 때문에 위와 같은 문제는 발생하지 않는다.
또한 지속 연결을 인식할 수 있는 프록시 중계 서버라면, Proxy-Connection 헤더를 Connection로 변경해 전달함으로써 커넥션을 유지한다.
Pipelining
지속 연결은 또한 여러 Request를 보낼 수 있도록 Pipelining을 지원한다.
Pipelining 없다면, 요청에 대한 응답을 받고 나서야 다음 요청을 실시할 수 있다. 이로 인해 네트워크 지연과 대역폭 제한이 있을 경우, 다음 요청을 보내는 데까지 상당한 딜레이가 발생하게 된다.
따라서, Pipelining은 응답을 기다리지 않고 요청을 연속적으로 보내도록 하는 기능디ㅏ. 이를 통해, 커넥션의 지연을 회피할 수 있다.
예를 들어, HTML에 10개 이미지를 포함하고 있다면 단일 연결보다 지속 연결이 빠르고, 지속 연결보다는 Pipelining 하는 방법이 더 빠르다.
하지만, Pipelining 기술은 [Head-of-line blocking(HLO)](https://en.wikipedia.org/wiki/Head-of-line_blocking) 문제로 여러 브라우저에서 지원하고 있지 않는다. 결국, HTTP/2 프로토콜에서는 Pipelining을 멀티플렉싱으로 대체해 지원하고 있다.
쿠키
앞서 말했듯이, HTTP는 Stateless 프로토콜이기 때문에 과거 Request, Response의 상태를 관리하지 않는다. 따라서 과거 Response 상태를 다음 Request에 이용하는 것은 불가능하다.
예를 들어 인증이 필요한 애플리케이션을 생각해보자. 이전 상태를 기억하지 못하기 때문에, 새로운 페이지를 이동할 때마다 다시 로그인하거나 애플리케이션에서 별도로 로그인 상태를 관리해 매 요청마다 전달해야 할 것이다.
물론 이러한 HTTP Stateless 특성 덕분에 상태를 유지할 CPU나 메모리 같은 리소스 제거할 수 있지만, 여러 방면에서 사용하기에 불편함이 존재한다.
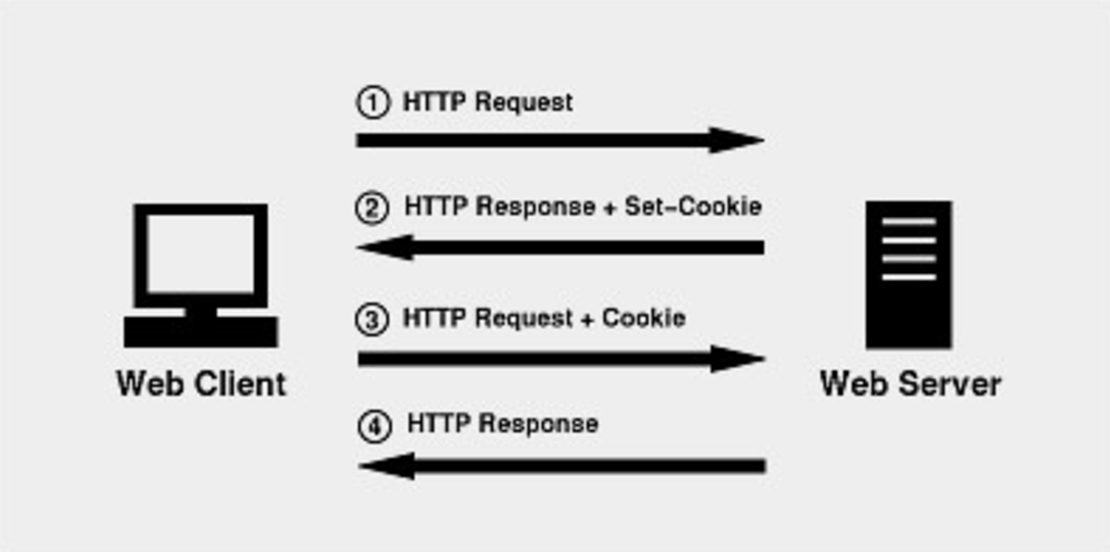
따라서 HTTP Stateless 특성은 유지한 채 상태를 관리하기 위해, Cookie라는 시스템이 도입되었다.
Cookie는 Request, Response에 쿠키 정보를 추가해서 클라이언트의 상태를 파악하기 위한 시스템이다.
즉 클라이언트는 Response의 Set-Cookie 헤더 필드를 브라우저에 저장하고, 다음 Request 송신 과정에서 Cookie 헤더 필드에 저장된 쿠키 정보를 자동으로 추가해 전송한다.
products 쿠키 응답
HTTP/1.1 200 OK
X-Powered-By: Express
Content-Type: text/html; charset=UTF-8
Content-Length: 338
Date: Sat, 04 Jul 2020 21:42:12 GMT
Set-Cookie: products=j%3A%7B%22maxAge%22%3A10000%7D; Path=/다음 요청에서 보관한 products 쿠키 자동 포함
GET /user HTTP/1.1
Host: localhost:3000
Cookie: products=j%3A%7B%22maxAge%22%3A10000%7D참고 자료
