Atrous convolution
- DeepLab v1에서 적용한 기법으로 기존의 convolution과 달리 필터 내부에 빈 공간을 둔채로 convolution을 진행하는 방법이다.
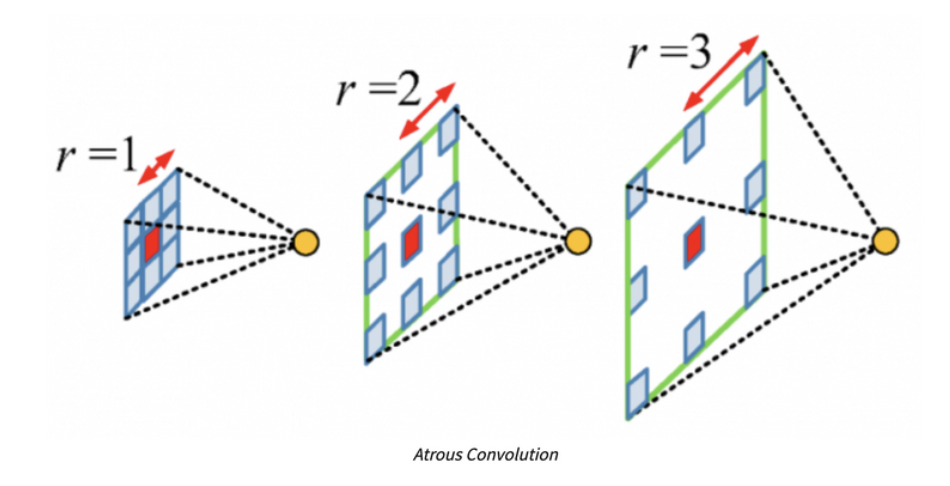
- 이러한 Atrous convolution을 통해 기존 convolution과 동일한 양의 파라미터와 computation cost를 유지하면서 field of view를 크게 가져갈 수 있다.
- Semantic segmentation에서 높은 성능을 내기 위해서는 receptive field의 크기가 중요하게 작용한다.
- 이러한 방법을 통해 convolution과 pooling과정에서 디테일한 정보가 줄어들고 특성이 점점 추상화되는 것을 어느정도 방지할 수 있기 때문에 DeepLab에서는 이를 활용하였다.
Atrous Spatial Pyramid Pooling(ASPP)
- DeepLab v2에서 제안한 방법으로 rate가 다른 Atrous Convolution을 병렬로 적용한 뒤, 이를 다시 합쳐주는 방법이다.
-
PSPNet에서도 이와 비슷한 Pyramid Pooling 기법을 활용하였다.
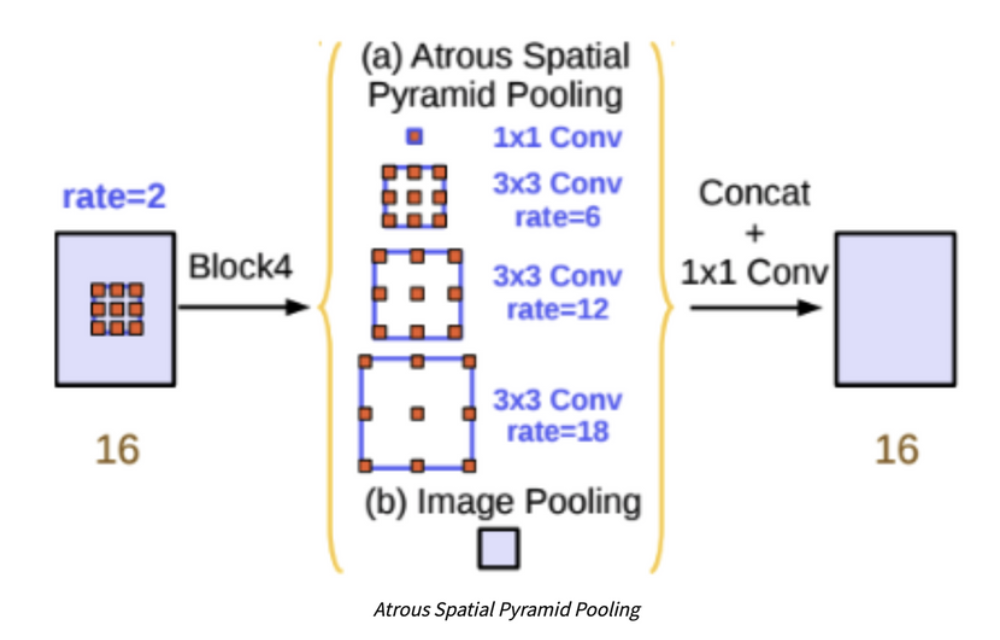
-
- ASPP는 multi-scale context를 모델 구조로 구현하여 보다 정확한 semantic segmentation을 수행할 수 있도록 했다.
Depthwise separable convolution
- Depthwise Convolution
- Channel 축을 한번에 연산하는 기존의 Convolution과 달리, Channel 축을 모두 분리해서 각 Channel별로 서로 다른 Convolution filter로 연산을 하는 방법이다.
- Depthwise Separable Convolution
-
Depthwise convolution에 1x1크기의 Convolution(Separable Convolution)을 적용한 방법이다.
⇒ 이러한 방법은 Convolution과 유사한 성능을 보이면서도 사용하는 파라미터 수와 연산량을 획기적으로 줄일 수 있다.
-
Encoder-Decoder
- DeepLab V3+에서는 위의 모듈들을 Encoder-decoder 구조로 구조화시켰다.

- Encoder
- DCNN에서 Atrous Convolution을 통해 임의의 resolution으로 feature map을 뽑아낼 수 있도록 한다.
- 또한 ASPP를 활용해서 다양한 크기의 물체 정보를 잡아낸다.
- Decoder
- Encoder의 최종 Output에 1x1 convolution을 하여 Channel 수를 줄이고, bilinear upsampling을 해준 후에, concat과정을 거친다.
- 이러한 과정을 하더라도 object의 pixel 단위까지 위치를 정교히 segmentation하는 것이 불가능하므로, CRF를 이용해 post-processing을 하였다.
- Backbone
- DeepLab v3+에서는 Xception을 변형하여 사용하였다.
Fully connected CRF
-
Conditional random field
- 이전 node와의 관계를 기반으로 현재 노드의 값을 추론하는 방법

- 이전 node와의 관계를 기반으로 현재 노드의 값을 추론하는 방법
-
논문에서는 전체 pixel을 모두 연결한 fully connected CRF 방법을 사용해서 detail한 정보들이 살아있는 결과를 얻었다.
-
mean field approximation 방법을 활용하여 효과적으로 빠른 fully connected CRF를 수행 가능하도록 했다.
- : pixel position
- : pixel color intensity
-
