이 글은 cs231n(2017)강의를 보며 정리한 글입니다.
https://www.youtube.com/watch?v=OoUX-nOEjG0&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=3
- Image Classification이란?
Computer vision의 가장 중요한 task이며, image에 있는 object를 분류하는 것이다.
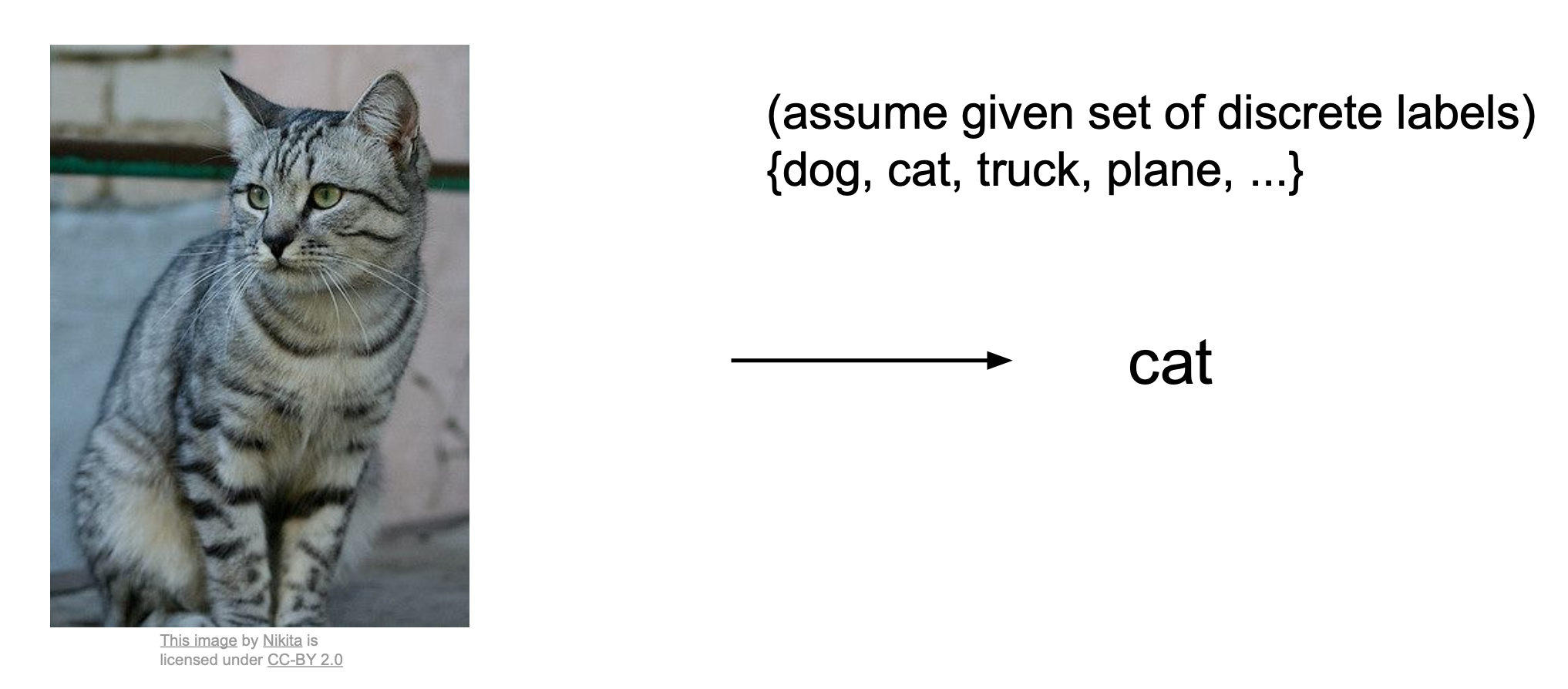
사람은 쉽게 구별이 가능하지만, 컴퓨터는 image를 big grid of numbers로 받아들이기 때문에 이미지의 Object를 쉽게 분류하지 못한다.
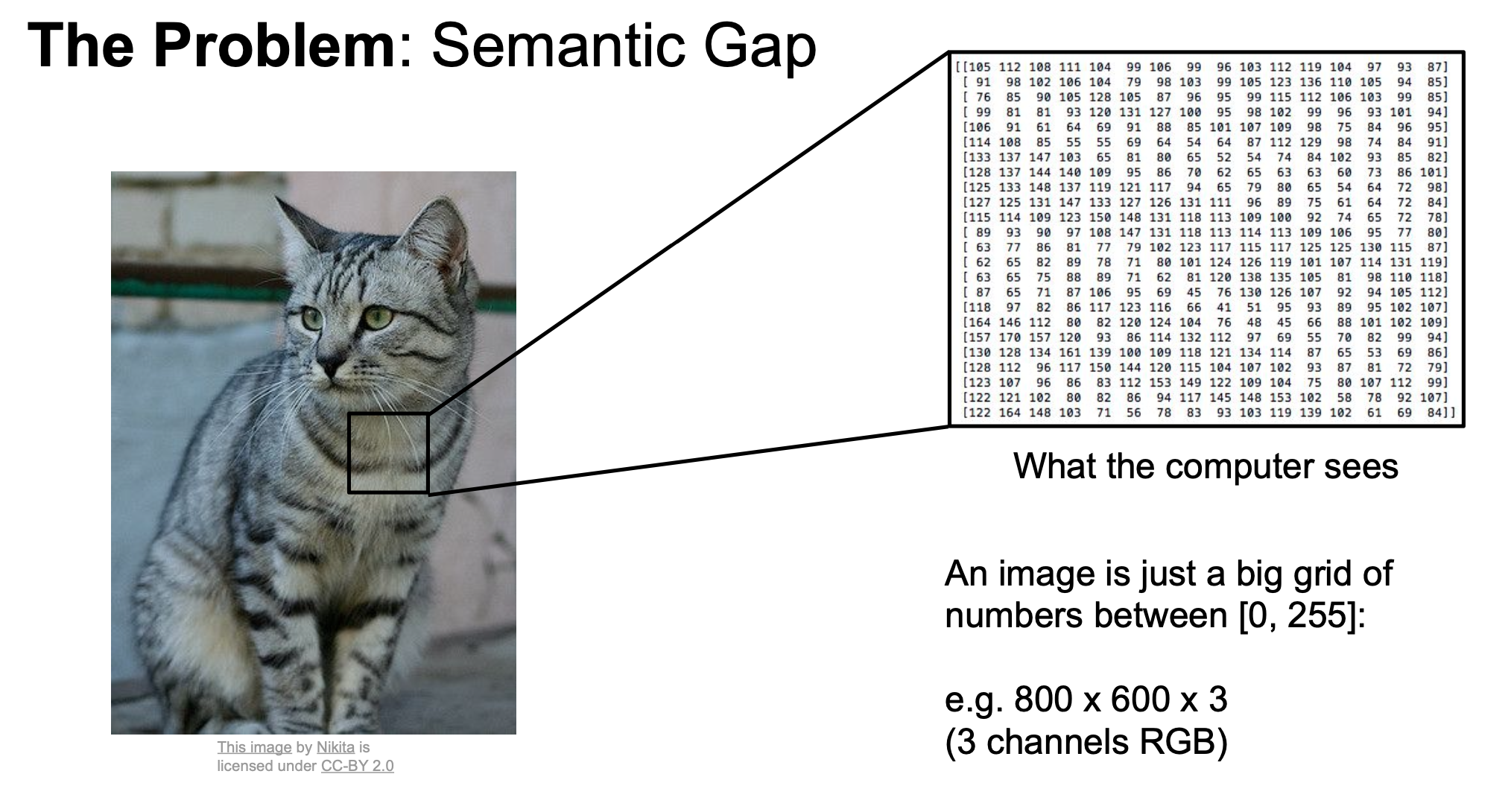
컴퓨터는 image classification에 이러한 어려움들이 있다.
- Viewpoint Variation => 보는 방향이 살짝만 변해도 pixel grid가 확 달라진다.
- Illumination => 빛의 상태에 따라 pixel grid가 달라진다.
- Deformation => object가 어떤 상태에 있느냐에 따라 pixel grid가 달라진다.
- Occlusion => object가 가려져 있어, 일부분만 노출될 경우, pixel grid로 판단을 하기에 어려워진다.
- Background Clutter => Background와 object의 색깔이 비슷한 경우 pixel grid상에서는 경계가 모호하기 때문에, 판단이 힘들다.
- Intraclass variation => 같은 종류의 object라도, 각각 색깔, 형태가 모두 다르기 때문에 판단에 어려움이 있다.
-
Image Classifier
이미지 분류에는 sorting 알고리즘과 같이 명확한 알고리즘이 없다.
그래서 결국 Data Driven Approach 방식으로 image classification 을 수행한다.*Data Driven Approach? => 단순히 데이터를 많이 모아서 머신러닝을 통해 훈련시키고, 새로운 이미지에 대해 평가하는 것
1. Nearest Neighbor
=> 많은 이미지와 그 이미지의 라벨을 학습한 뒤에 새로운 이미지가 들어왔을 때, 가장 비슷한 training image의 라벨이라고 예측하는 것
- Distance Metric
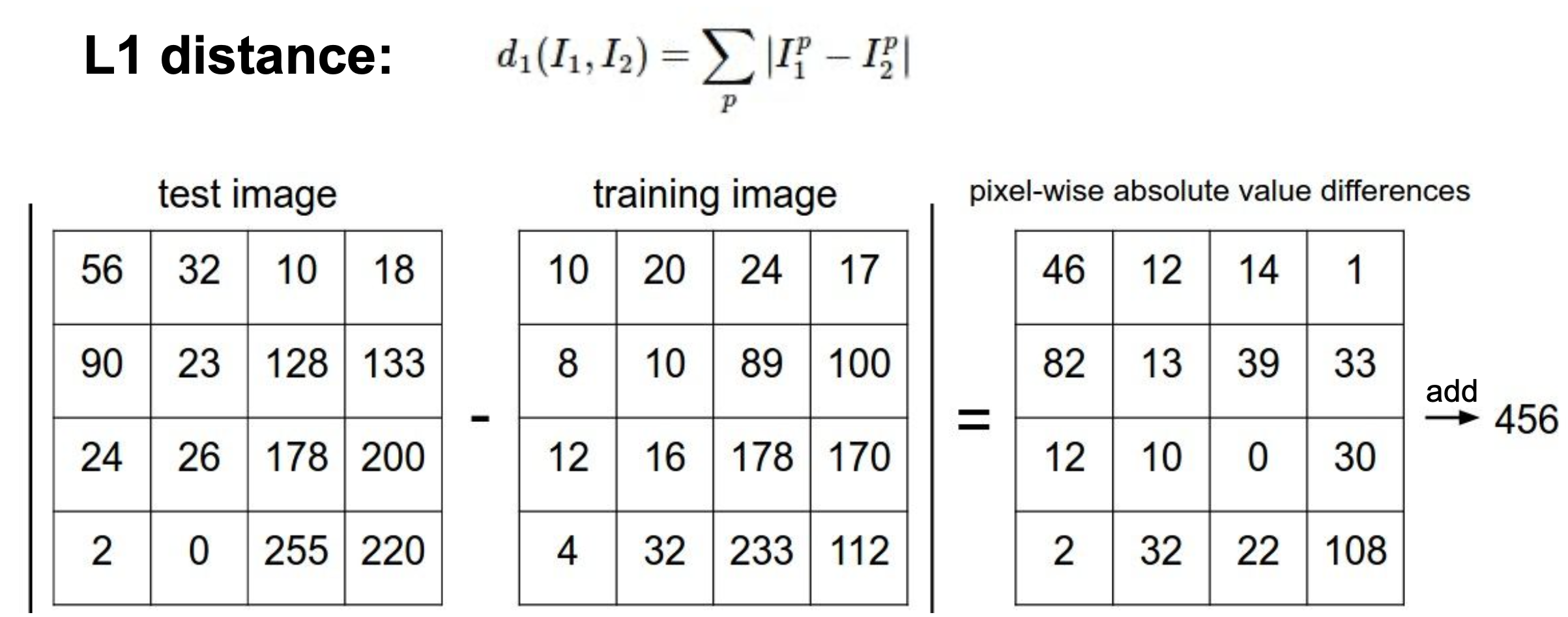
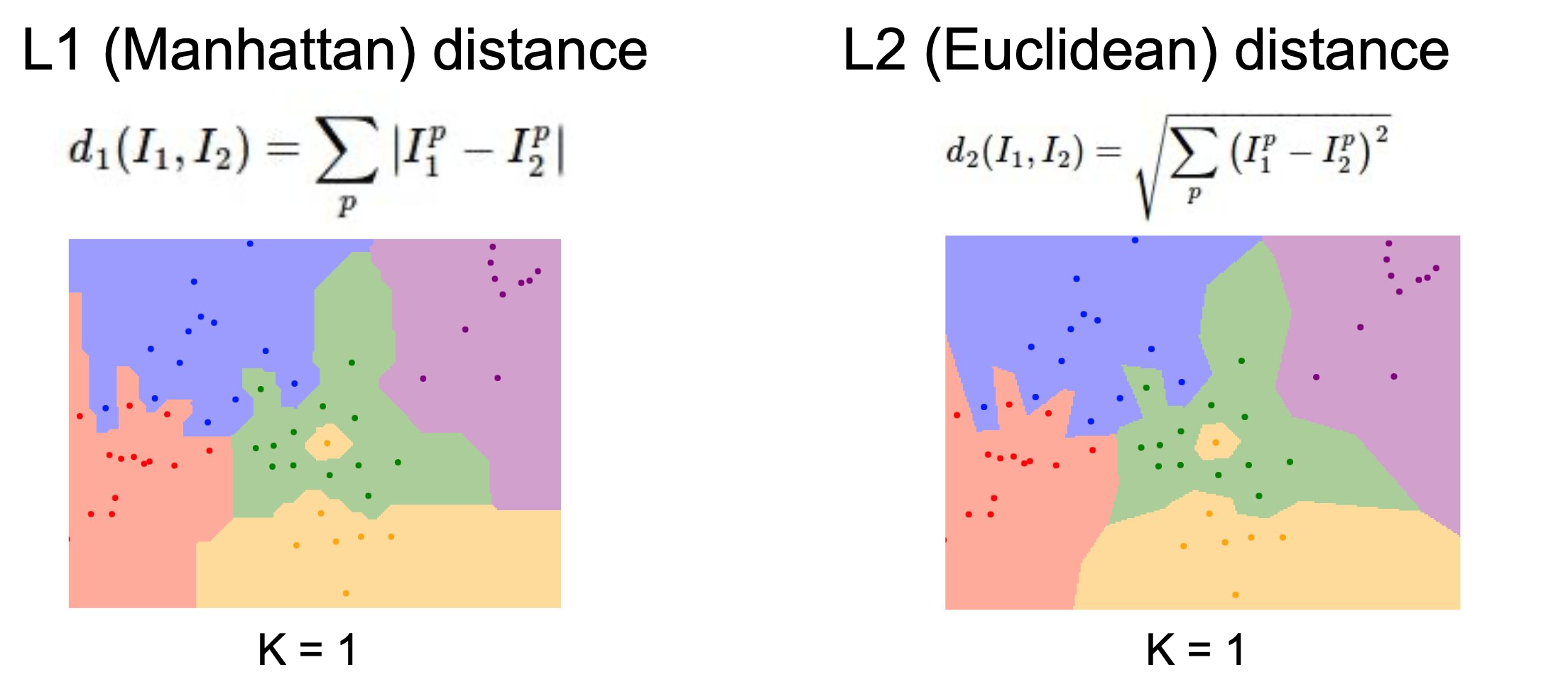
1) L1 distance (Manhattan distance) : 비교하고자 하는 두 이미지의 픽셀 값의 차이의 총합
2) L2 distance (Euclidean distance) : 두 이미지의 픽셀 값의 차이의 제곱의 총합에 루트를 씌운 것
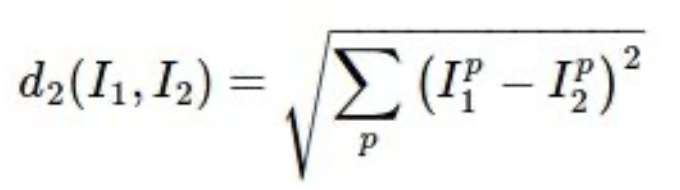
위의 distance metric에 따라, distance가 작으면, 두 이미지가 유사하다고 판단한다.
2. K-Nearest Neighbor
=> 가장 근접해 있는 K개의 데이터의 라벨을 보고 K개중 가장 많은 라벨과 같다고 간주함.
-
Hyperparameter : 학습되어지는 값이 아닌 미리 정해야 하는 parameter
1) K => 아래 그림과 같이 K의 값이 늘어날 수록 경계 선이 모호해지는 경향이 있다.
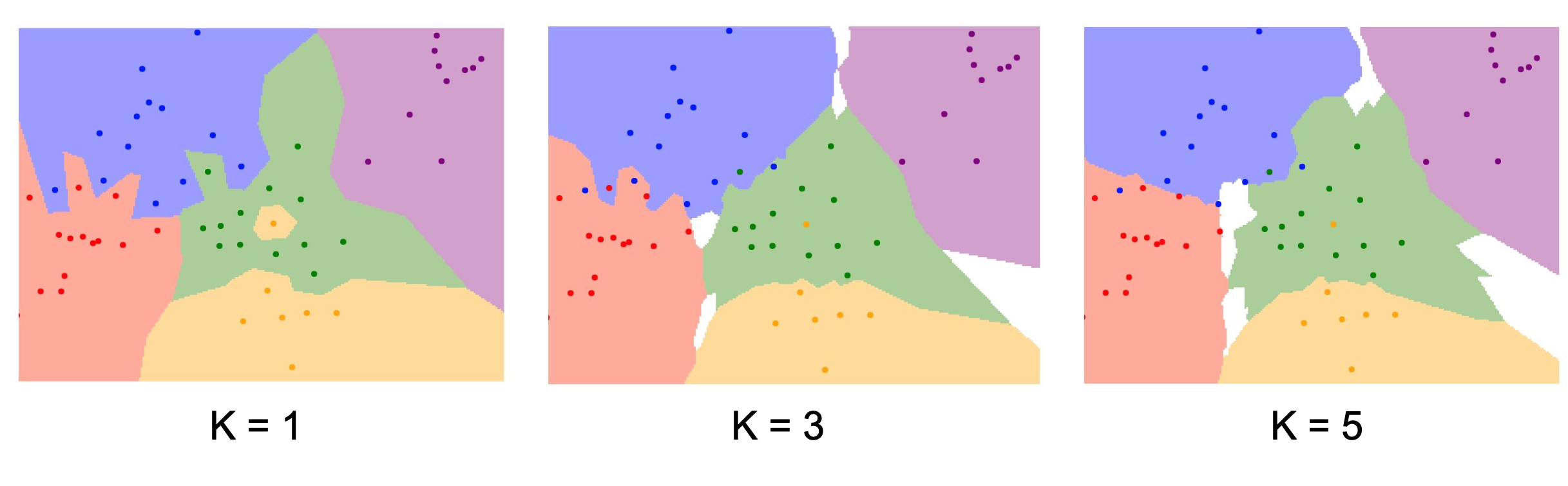
2) Distance metric => L1을 사용하면 경계선이 좌표축에 평행해진다.
-
Setting Parameters
1) Choose Parameters that work best on the data : 단순히 여러번 실험해보고 가장 잘되는 parameter를 찾는다.
 => 하지만, training data로 test를 하기 때문에, K=1일 때, 가장 실험 결과가 잘 나온다.
=> 하지만, training data로 test를 하기 때문에, K=1일 때, 가장 실험 결과가 잘 나온다.
2) Split data into train and test, choose hyperparameters that work best on test data
 => test data에서 실험 결과가 잘 나올만한 알고리즘이 딱히 없다.
=> test data에서 실험 결과가 잘 나올만한 알고리즘이 딱히 없다.
3) Split data into train, val, and test choose hyperparameters on val and evaluate on test
 => Better!
=> Better!
4) Cross-Validation: Split data into folds, try each fold as validation and average the results => training data를 여러개의 fold로 나누어서 그 중 하나를 validation data로 지정해서 수행하는 것
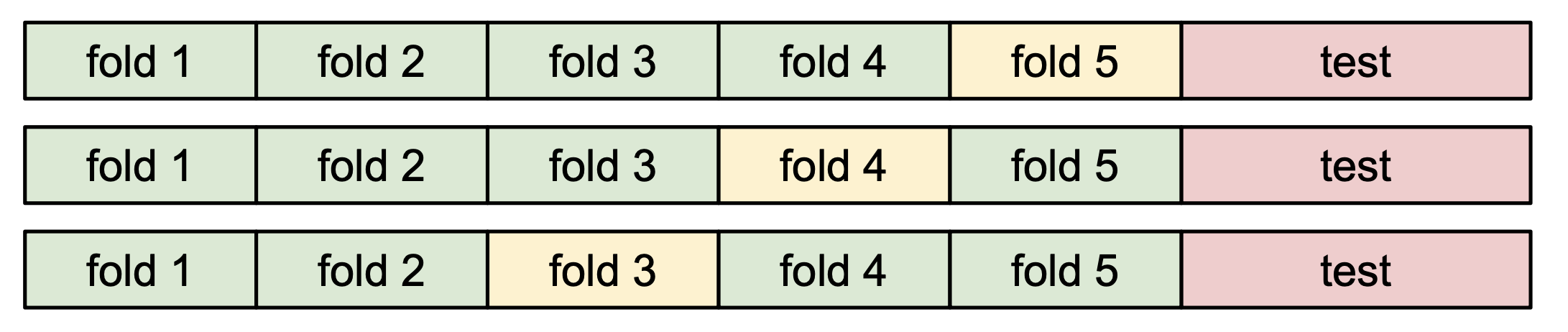 => 데이터의 개수가 적을때 주로 사용함.
=> 데이터의 개수가 적을때 주로 사용함. -
K-Nearest Neighbor가 image classification 에서 사용되지 않는 이유
1) Very slow at test time
2) Distance Metrics on pixels are not informative
3) Curse of Dimensionality
=> 이미지는 고려해야할 요소가 많은데 Distance를 이용해 이미지를 분류하는 것은 적합하지 않다.
3. Linear Classification
- Parametric Approach
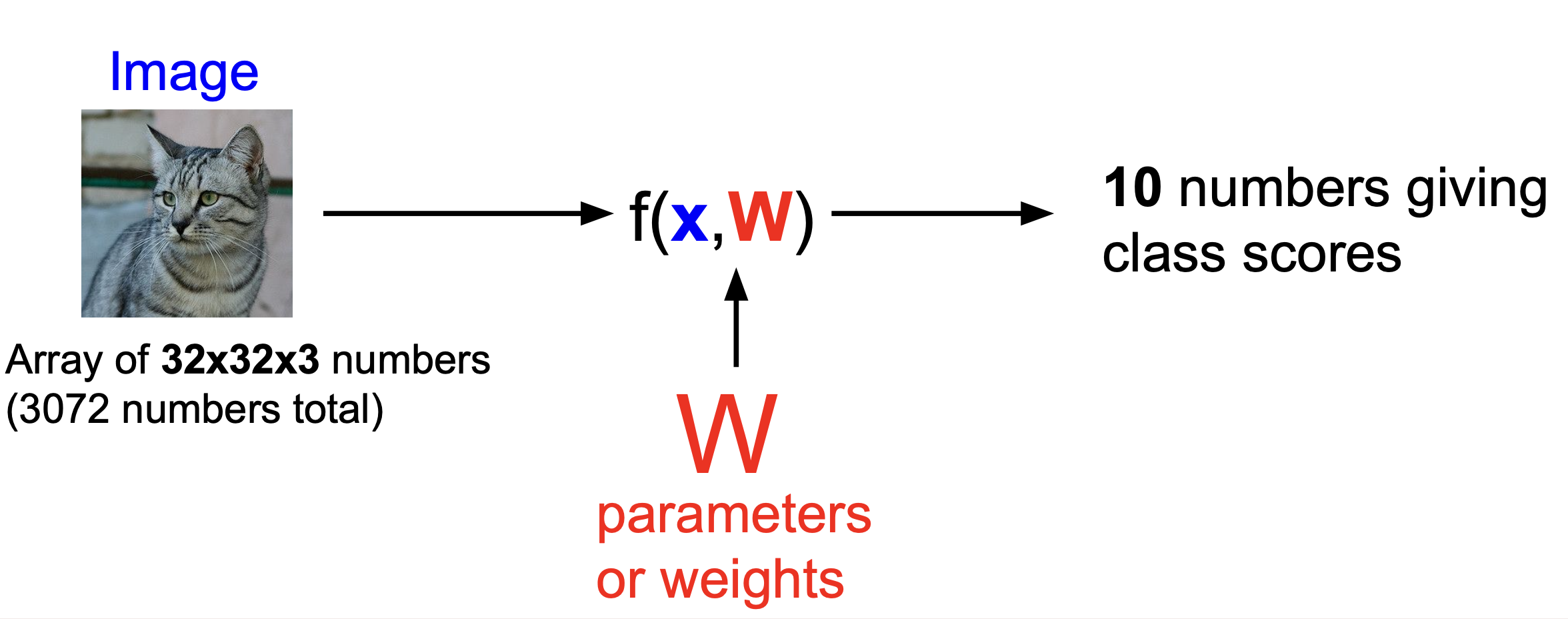
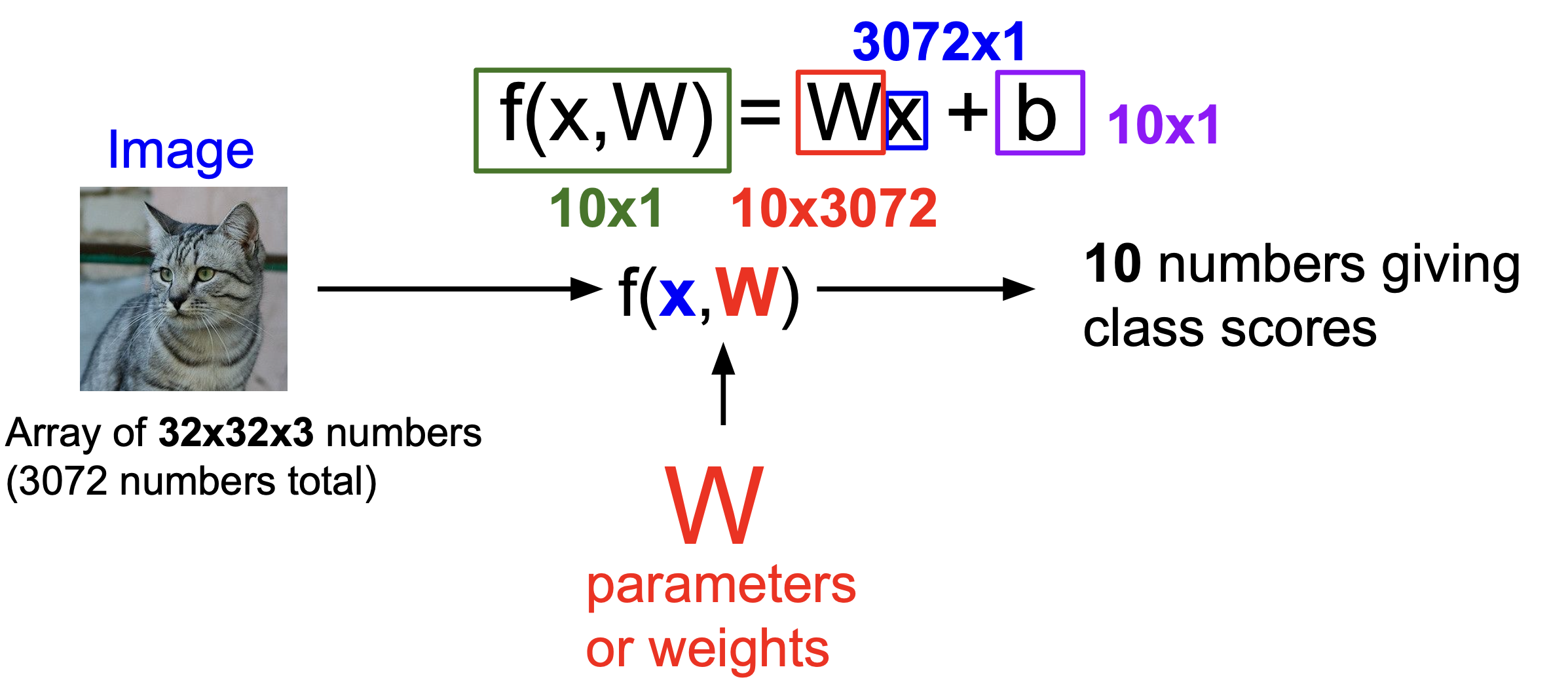
=> 위의 그림에 해당하는 parameter인 weight(가중치)를 학습하는 방법이다.
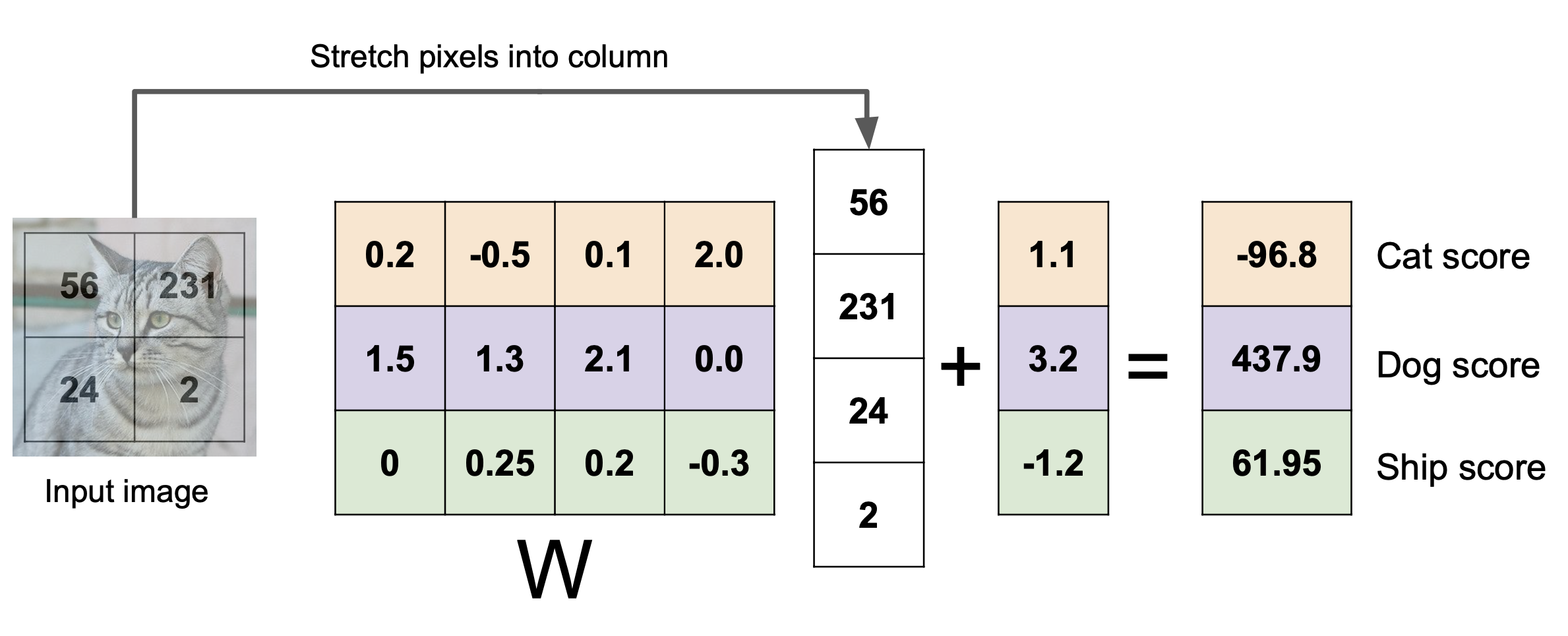 => input image의 pixel 값에 weight를 곱하고 bias를 더해 score vector를 뽑아내 그 중 score가 가장 높은 class로 분류한다.
=> input image의 pixel 값에 weight를 곱하고 bias를 더해 score vector를 뽑아내 그 중 score가 가장 높은 class로 분류한다. - Hard cases for a linear classifier
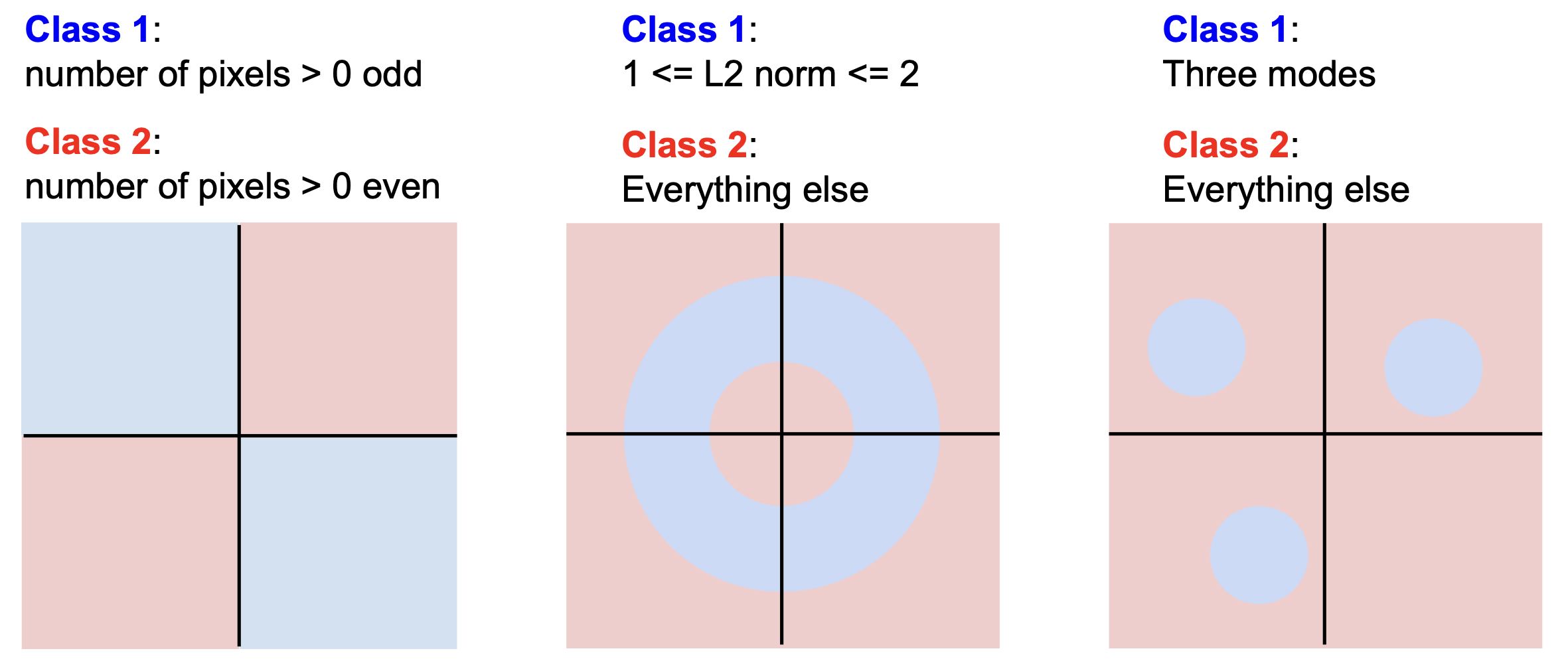 => 이와 같은 경우에는 선 하나로 분류되지 않기 때문에 Linear Classifier를 적용하기 어렵다.
=> 이와 같은 경우에는 선 하나로 분류되지 않기 때문에 Linear Classifier를 적용하기 어렵다.

흥미롭네요..ㄷㄷ