[논문 리뷰] Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation
Motivation
기존 Image-to-video (I2V) diffusion model을 활용해서 key frame interpolation task에 적용
- Key frame interpolation
- 두 Key frame 사이의 frame들을 예측하는 task (멀리 떨어진 프레임 사이를 예측)
Contribution
- 기존 I2V diffusion model을 key frame interpolation task에 맞게 fine-tuning 할 수 있는 lightweight fine-tuning strategy 제안
- forward motion과 backward motion이 일치할 수 있도록 dual-directional diffusion sampling process 제안
Method
Reverse motion-time association by self-attention map rotation
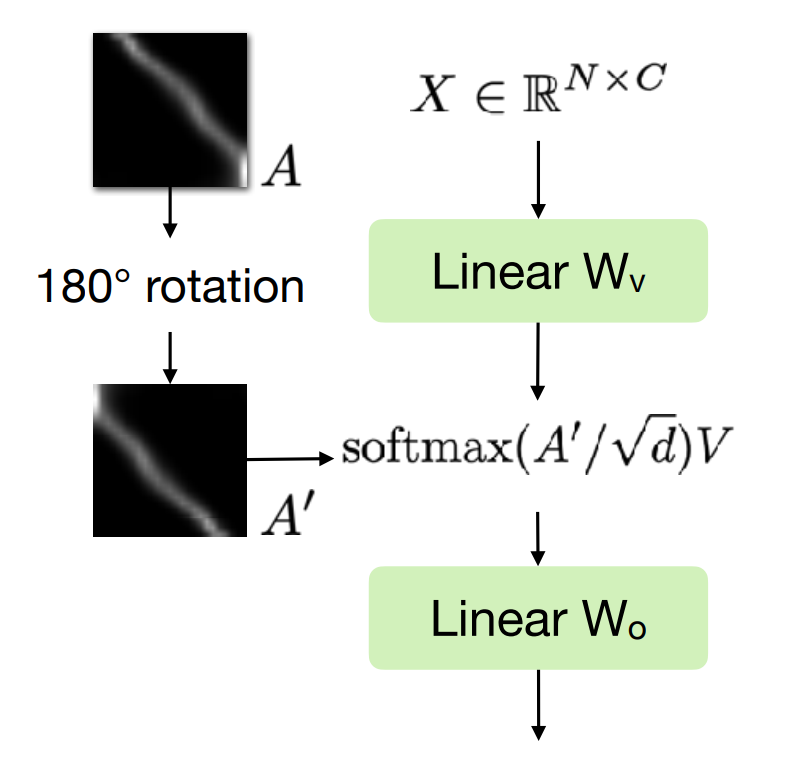
기존 I2V network에서 video의 forward motion에 대한 feature는 temporal self-attention map이다.
논문에서는, 이를 단순히 180 degree rotation 하면 backward motion에 대한 feature가 될 수 있다고 말한다.
- 는 j와 k frame 사이의 attention score
Lightweight backward motion fine-tuning
기존 I2V task와 크게 다르지 않으므로, backward motion에 대한 부분만 fine-tuning 하면 된다.
이를 위해, 위에서 제시한 rotation 방법을 이용해서 temporal attention weight 만 fine-tuning 한다.
⇒ less data and fewer paramters
이에 대한 pseudo code는 아래와 같다.

Dual-directional sampling with forward-backward consistency
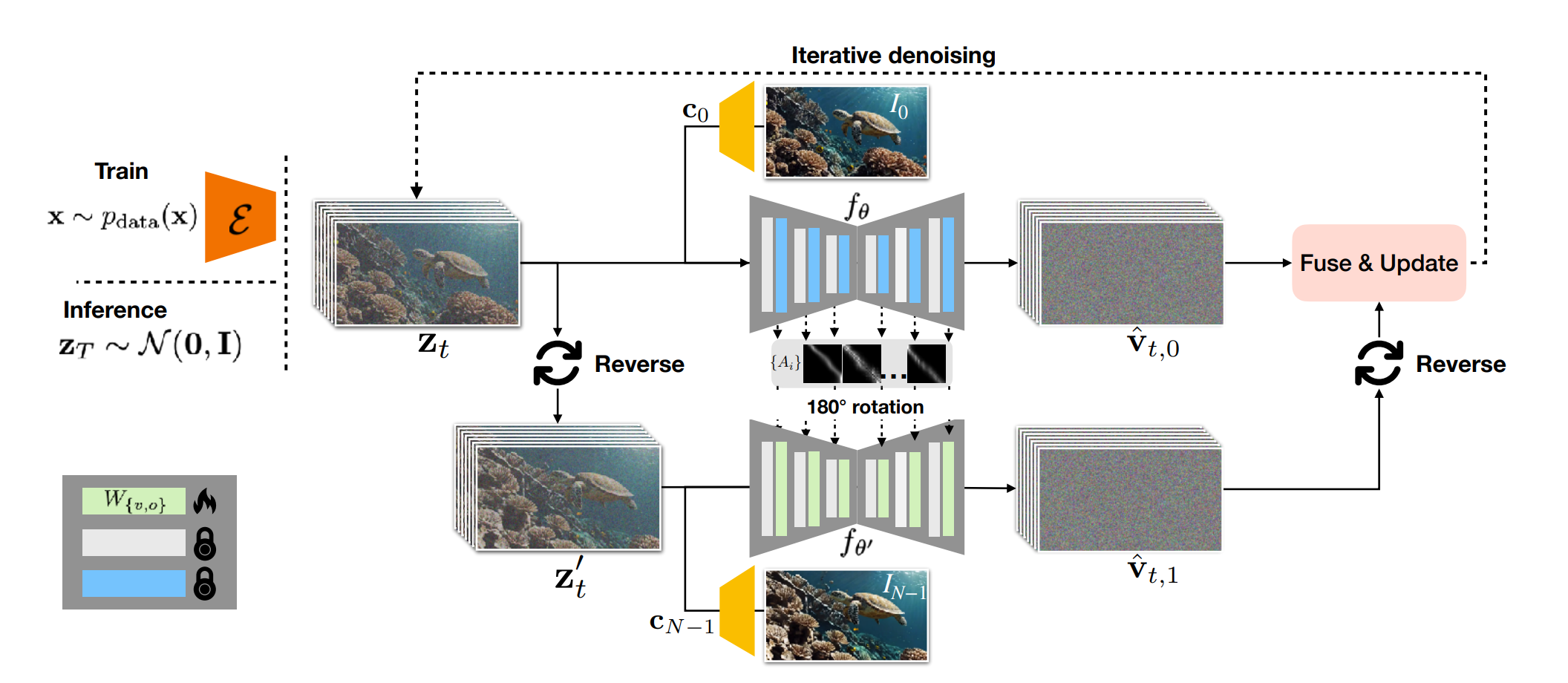
논문에서는 forward motion과 backward motion이 asymmetric하기 때문에, forward-backward consistency를 위한 sampling 기법을 제안했다.
전체적인 프로세스는 아래와 같다.
- Forward motion denoising
- 기존 I2V diffusion model과 같이, 첫 프레임을 condition으로 pre-trained diffusion model로 denoising 한다.
- 여기서, noise 뿐만아니라, temporal attention map 또한 Output으로 얻는다. ⇒ rotation 위함
- 여기서, noise 뿐만아니라, temporal attention map 또한 Output으로 얻는다. ⇒ rotation 위함
- 기존 I2V diffusion model과 같이, 첫 프레임을 condition으로 pre-trained diffusion model로 denoising 한다.
- Backward motion denoising
- I2V diffusion model에 마지막 프레임을 condition으로 하여 backward motion을 denoising 한다.
- 1에서 얻은 temporal attention map을 rotation하여, backward diffusion model에 넣는다.
- I2V diffusion model에 마지막 프레임을 condition으로 하여 backward motion을 denoising 한다.
- Fusing two denoised output
- forward motion denoising, backward motion denoising을 통해 얻은 output을 단순히 average하여 최종적인 output을 얻는다. 이를 매 diffusion timestep마다 반복하여, 최종적으로 in-betweening frames를 생성할 수 있다.
- forward motion denoising, backward motion denoising을 통해 얻은 output을 단순히 average하여 최종적인 output을 얻는다. 이를 매 diffusion timestep마다 반복하여, 최종적으로 in-betweening frames를 생성할 수 있다.
이에 대한 Pseudo-code는 아래와 같다.
 ### Evaluation
### Evaluation
- Dataset
- training
- lightweight fine-tuning이 가능하기 때문에, 100개의 high quality video만을 활용하여, 학습함.
- evaluation
- DAVIS, PEXEL
- 25 frame이상 떨어져있는 Pair를 Input으로 지정
- training
