[논문 리뷰] Momentum Contrast for Unsupervised Visual Representation Learning (MoCo)
Introduction
Contrastive learning은 좋은 dictionary를 갖는 것이 중요한데, 논문에서는 중요한 dictionary의 조건으로 다음 두가지를 뽑았다.
-
large
⇒ continuous, high-dimensional visual space에서 sampling을 잘 하기 위해서 dictionary size가 커야한다.
-
consistecy
⇒ dictionary의 key가 일관되어야 query와의 비교 또한 일관되므로 좋은 성능을 낼 수 있다.
이 두가지 조건을 충족하기 위해서 MoCo는 queue를 사용하는 다음과 같은 dynamic dictionary방식을 제안했다.
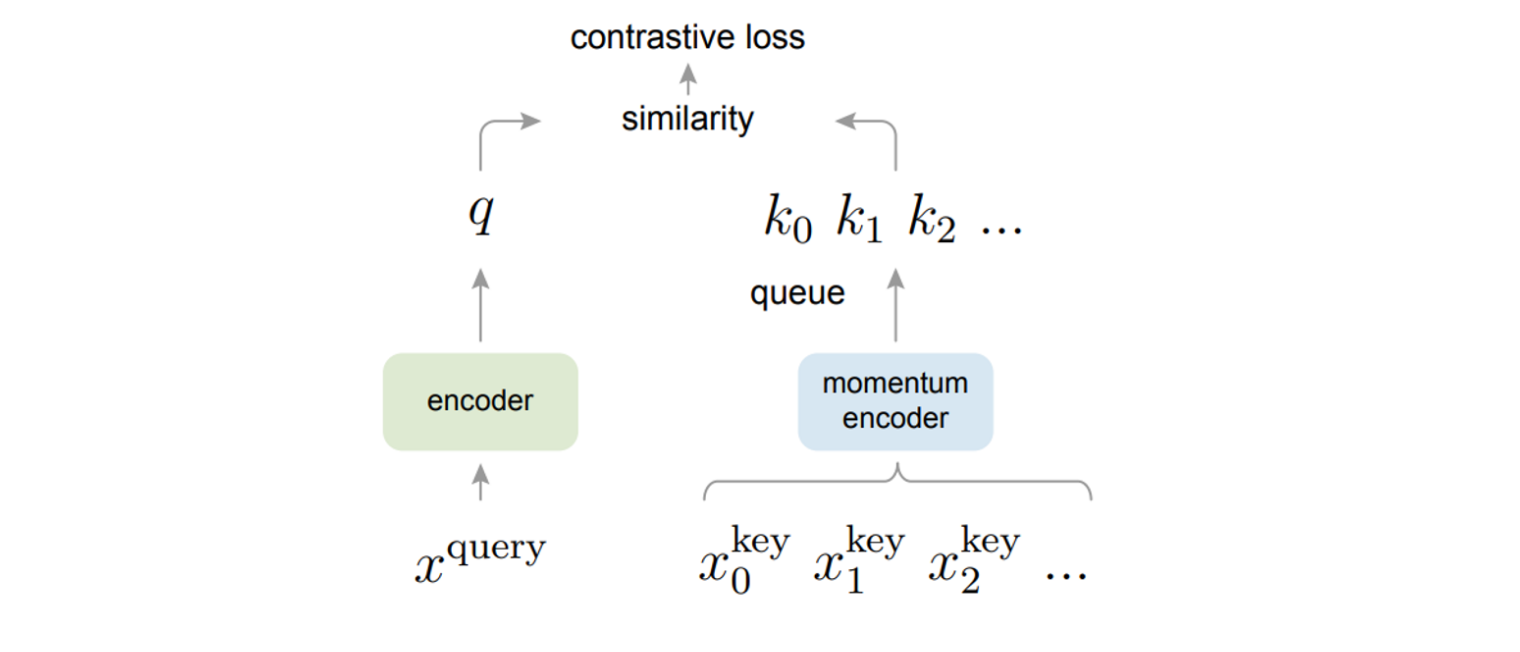
Method
Momentum Contrast
Dictionary as a queue
MoCo는 dynamic dictionary로 queue를 사용했는데, 이 queue의 사이즈는 mini batch size에 독립적이므로, 그래서 위에서 언급한 large한 특성이 충족된다.
또한, sample들이 mini-batch 형태로 queue에 들어오게 되는데, queue의 FIFO특성에 의해서 queue에서 가장 오래된 sample batch가 나가게 된다.
이러한 특성은 queue에 있는 sample들이 가장 최근의 것으로 유지되게 만들어, consistency를 유지하게 해준다.
Momentum update
또한, MoCo는 momentum encoder를 통해 key에 해당하는 encoder는 back propagation 하지 않고, 천천히 업데이트 함으로써 dynamic dictionary(queue)의 consistency를 유지하게 해준다.
momentum update 과정을 식으로 나타내면 다음과 같다.
⇒ 논문에서는 m=0.999와 같이 매우 작은 m을 주어 매우 천천히 업데이트하도록 하는 것이 성능 향상에 도움이 되었다고 실험결과로 보여줬다.
Relative to previous mechanisms
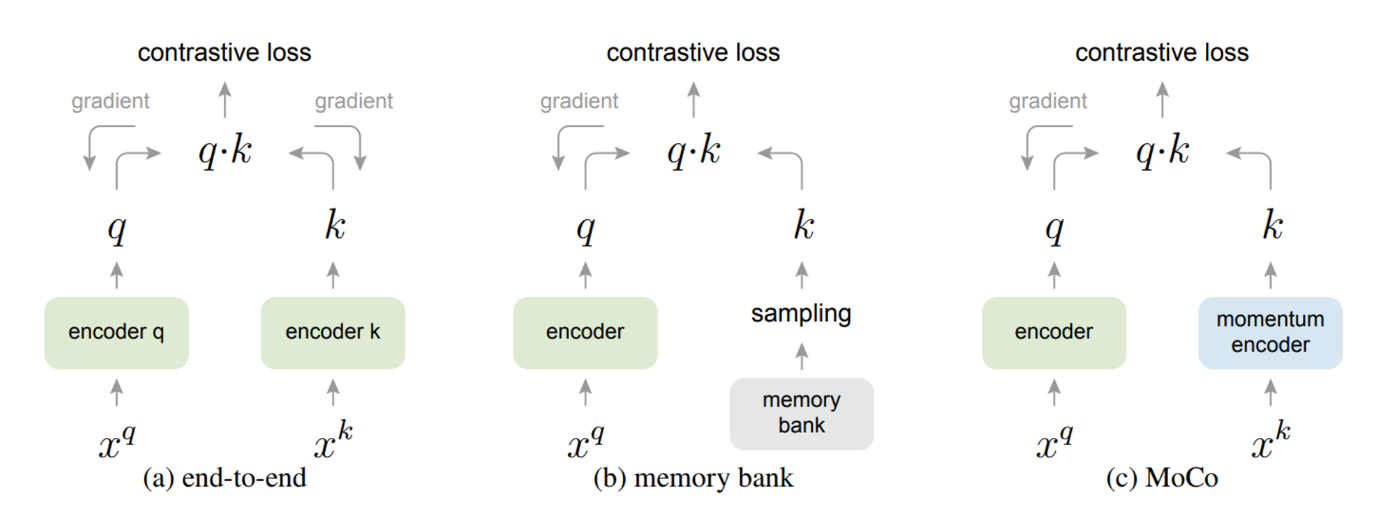
기존의 방식과 비교해보면 기존의 방식을 두가지로 나눌 수 있는데,
첫번째는 end-to-end 방식이다.
이 방식은 mini-batch에서 positive sample과 negative sample을 만들어 각각 encoder를 통과시켜 contrastive loss를 통해 각 encoder를 학습하는 방식이다.
하지만, 이 방식의 가장 큰 문제점은 앞서 말했듯이, contrastive learning에서는 dictionary의 사이즈, 즉, negative sample이 얼마나 많이 있느냐가 중요한데, 이 방식은 mini-batch에서 positive sample, negative sample을 가져오므로, consistency는 충족되지만, Large한 특성은 GPU memory 사이즈에 달려있다.
두번째는 memory bank 방식이다.
이 방식은 memory bank에 dataset의 모든 샘플들의 representation을 넣어두고, memory bank에서 무작위로 샘플링해서 key로 사용하는 방식이다.
그래서, dictionary의 large한 특성은 충족된다.
그러나, memory bank의 representation은 샘플링 될때마다 업데이트를 해주게 되는데, 이는 memory bank에 각자 다른 업데이트 시기의 샘플들을 보관하게 되는 것이므로, 이는 dictionary의 consistency를 충족하지 못한다.
위의 방식들을 통해 구현된 MoCo의 Pseudo-code는 다음과 같다.

