[논문 리뷰] Railroad is not a Train: Saliency as Pseudo-pixel Supervision for Weakly Supervised Semantic Segmentation(EPS)
Abstract
- Image-level weak supervision을 사용하는 WSSS는 몇가지 한계점이 존재한다.
-
sparse object coverage
-
inaccurate object boundary
-
co-occuring pixels from non-target objects
⇒ 이러한 문제점들을 해결하기 위해 EPS를 제안한다.
-
- EPS는 two weak supervision을 합쳐서 pixel-level feedback을 얻는다.
- localization map
- saliency map
- Joint training strategy로 localization map과 saliency map으로부터 오는 정보들의 complementary relationship을 이용한다.
Introduction
-
WSSS는 weak supervision을 이용해서 fully-supervised model과 비슷한 성능을 내는 것을 목표로 한다.
-
대부분의 WSSS모델은 weak supervision으로 image-level label을 택한다.
-
WSSS의 전체적인 파이프라인은 two stage로 구성되어 있다.
1) pseudo-mask 생성 (image classifier 이용)
2) pseudo-mask로 segmentation model 학습
-
주로 CAM(Class Activation Map)을 통해서 localization map(Pseudo mask)를 생성한다.
-
하지만 WSSS에는 문제점들이 존재한다.
- localization map이 targete object의 일부분만 cover하는 문제
- boundary mismatch
- co-occuring pixel과 target object를 구분하기 어려운 것
-
이러한 문제들을 해결하기 위해 기존의 연구에서는 다음과 같은 방법들을 제시했다.
- First approach
-
픽셀들을 지워나가며, object의 full extent를 cover
-
Ensembling score maps
-
Using self-supervised signal
⇒ 하지만, object의 shape에 대한 단서가 부족해서 accurate boundary를 뽑아내는데는 실패했다.
-
- Second approach
-
Expand pseudo-masks until boundaries
⇒ target object와 non-target object가 공존하는 pixel을 구분하는 것에 실패했다.
-
- Third approach
-
extra GT masks, saliency map을 이용해서 co-occurence problem을 이용해서 완화
⇒ pixel-level annotation을 필요로 하므로, WSSS paradigm에 맞지 않다.
-
- First approach
-
본 논문에서는 localization map(CAM from image-level labels)과 saliency map을 통해서 위에서 제시한 세가지 문제점들을 해결한다.
- localization map ⇒ distingusih different objects
- saliency map ⇒ rich boundary information
Proposed Method
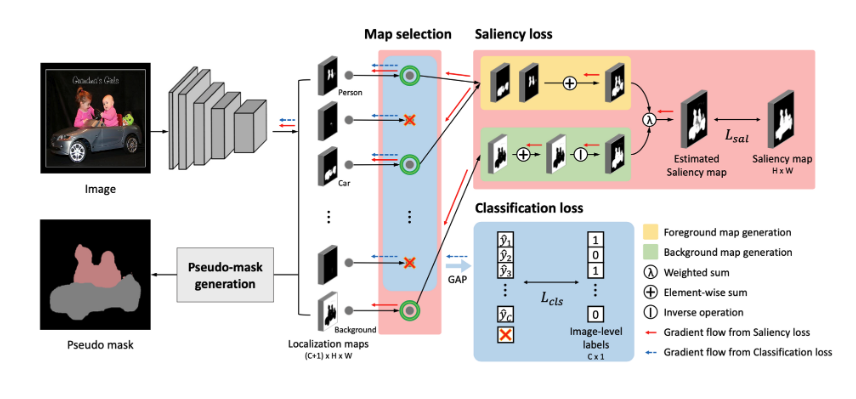
Motivation
- EPS의 key insight는 두가지 정보, 즉, localization map과 saliency map을 상호보완적으로 사용하는 것이다.
- Background를 포함해서 C+1개의 class로 분류하는 classifier로 C+1개의 localization map을 생성해서 saliency map과 비교한다.
- Foreground
- C개의 localization map을 합쳐서 foreground map을 생성하고, 이를 saliency map과 매칭시킨다. ⇒ improving boundaries of objects
- C개의 localization map을 합쳐서 foreground map을 생성하고, 이를 saliency map과 매칭시킨다. ⇒ improving boundaries of objects
- Background
- background localization map과 saliency map의 바깥부분(을 매칭시킨다. ⇒ mitigate the co-occuring pixels of non-target objects
- background localization map과 saliency map의 바깥부분(을 매칭시킨다. ⇒ mitigate the co-occuring pixels of non-target objects
Objective function
- saliency loss와 multi-label classification loss를 jointly training함으로써, 두 가지 정보를 상호보완적으로 받아올 수 있다.
- noisy, missing information에 대한 부분을 joint training을 이용해 향상시킨다.
- 예를 들어, original saliency map은 작은 물체들을 놓치거나, noisy한 경향이 있는 반면에 localization map을 같이 이용하면 noisy함을 잡아주고, 작은 물체들도 놓치지 않는다.
- 따라서, object boundary를 더 정확하게 포착할 수 있고, target object와 co-occuring pixel을 분리할 수 있다.

Explicit Pseudo-pixel Supervision
- Saliency map은 물체의 실루엣을 잘 찾아낸다는 장점이 있고, 이는 object boundary를 잘 찾아낸다. 이를 활용하기 위해 두가지 case를 saliency map과 매칭시킨다.
- Foreground
- localization map의 foreground 부분을 모두 합쳐서 foreground map 를 만들어 낸다.
- Background
- localization map의 background 부분으로 를 만들어 낸다.
- Foreground와 Background의 weighted sum을 이용해서 estimated saliency map을 도출한다.
- 위의 estimated saliency map과 original saliency map 사이의 sum of pixel-wise difference를 saliency loss 로 설정한다.
- Foreground
- 하지만, 본 논문에서는 saliency map으로 fully-supervised model을 사용한다면 WSSS의 방향성에서 벗어난다는 점을 지적하였다.
- saliency detection method에는 unsupervised, fully-supervised 방법이 있는데, 두 method 모두 다른 full-supervised saliency model을 사용한 방법들을 뛰어넘었다.
Map selection for handling saliency bias
- 이 파트에서는 localization map에서 foreground 부분을 선택할 때, naive하게 background부분을 제외하고 모두 선택한다면 작은 물체들을 salient object라고 생각해 무시하는 경향이 있다.
- 이러한 error는 saliency model이 다른 dataset으로 학습되었기 때문에 불가피한데, 본 논문에서는 overlapping ratio를 이용해서 error를 해결하였다.
- 와 가 % 이상 overlap된다면 foreground로 채택하고, 아니면 background로 채택
- : binary image-level label
Joint Training Procedure
-
Saliency loss
- is obtained form off-the-shelf saliency detection model (PFAN)
-
multi-label classification loss
- : sigmoid function
- : prediction, result of the global average pooling on the localization map
-
Total
