[논문 리뷰] Weakly Supervised Learning of Instance Segmentation with Inter-pixel Relations(IRNet)
Abstract
- 본 논문은 image-level class label에 대한 instance segmentation task에 대한 새로운 approach를 제시한다.
- 이 모델은 pseudo intsance segmentation label을 생성하고, 이 label로 Fully supervised segmentation을 진행하는 구조로 이루어져 있다.
- Generating pseudo label
- object의 confident seed area를 image classification model의 attention map을 뽑아낸 후에 object의 entire area를 찾아낼 때까지 propagate한다.
- IRNet은 각 instance에 대한 rough area를 찾아내고, 서로 다른 class 사이의 boundary를 찾아낸다.
- 또한, IRNet은 attention map에서 주변 pixel과의 관계에 대한 부분도 함께 학습시킨다.
- Generating pseudo label
Introduction
Instance Segmentation
- class label과 각 object들의 segmenation mask를 함께 예측하는 task이다.
- 하지만 instance-wise segmentation mask annotation을 만드는 것은 너무 시간이 많이 들기 때문에, 다양한 object들이 존재하는 real-world에서는 한계점이 많다.
Weakly Supervised Segmentation
- segmentation mask annotation을 하는 작업에 대한 한계점을 보완하기 위해서 제안된 방법으로, pixel-wise annotation에 비해 상대적으로 간단한 annotation을 통해 segmentation을 수행한다.
- i.e. bounding box, image-level class label
- 하지만 bounding box annotation 또한, ImageNet과 같이 large size dataset에 대해서는 annotation cost가 적지 않았다. 그래서 대부분의 Weakly Supervised Segmentation에서는 image-level class label을 이용해서 segmentation을 수행한다.
CAM
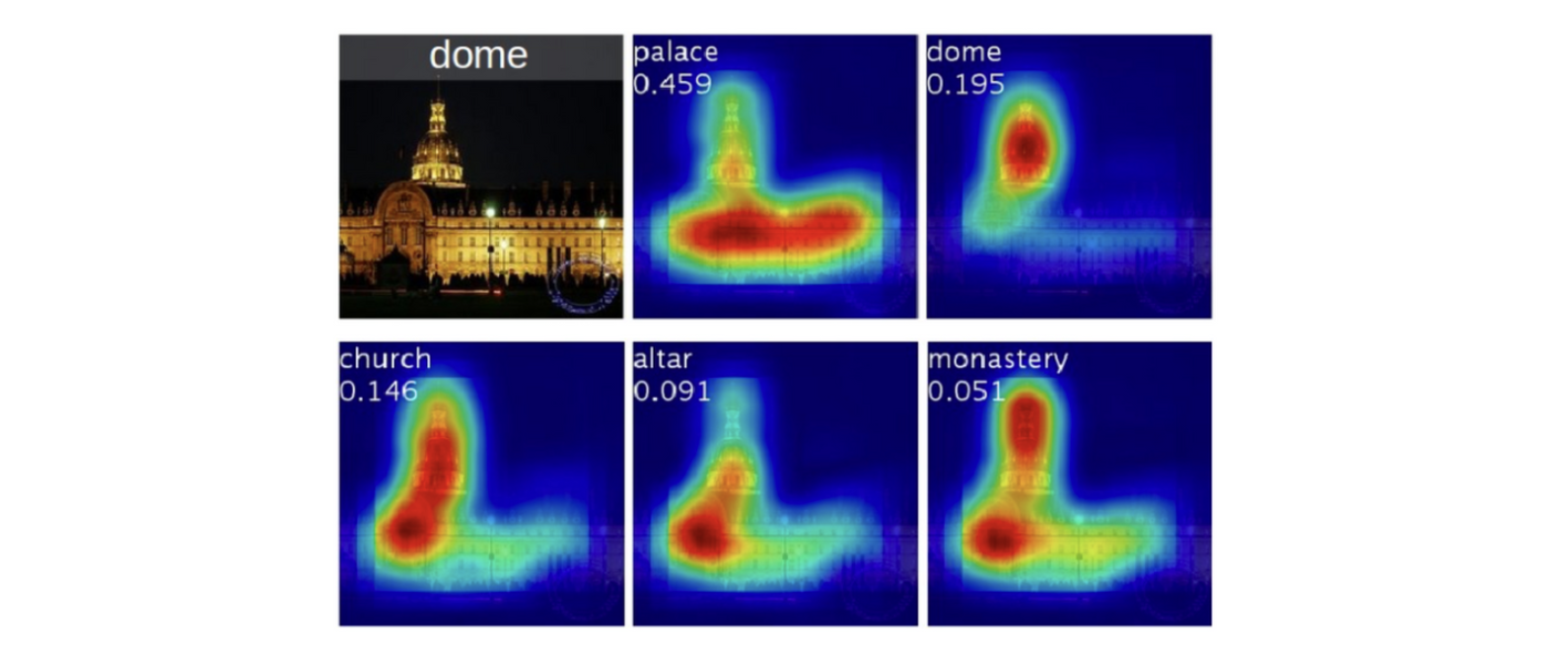
- Image-level class label의 경우, image안에서 object의 class와 존재 유무만 labelling되어 있기 때문에, object의 위치에 대한 정보가 필요하다. CAM은 이러한 대략적인 위치 정보를 classification network를 통해 얻을 수 있게 해준다. 하지만 CAM의 output을 곧바로 supervision하는데 활용하는 것은 무리가 있는데, 그 이유는 다음과 같다.
- Limited Resolution
- Highlight only partial areas of objects
- Cannot distinguish different instances of the same class
- 이러한 문제를 해결하기 위해서, CAM과 off-the-shelf segmentation technique을 활용하기도 한다.
- 하지만, 이러한 technique은 다른 dataset으로부터 supervision하게 학습된 technique이다.
IRNet
- IRNet은 이전의 approach들과 달리, additional supervision, proposal들을 필요로 하지 않는다.
- IRNet 또한 CAM을 활용하여 pseudo label을 생성하고, pseudo label을 통해서 training을 수행하는데,위에서 언급한 CAM의 단점들을 보완하기 위해서 두가지 additional information을 활용한다.
- Class-agnostic Instance map
- class label, accurate boundary 없이 rough하게 instance segmentation mask를 생성한 것
- Pairwise Semantic Affinity
- pair pixel 간의 class equivalence에 대한 confidence score에 대한 정보
- Class-agnostic Instance map
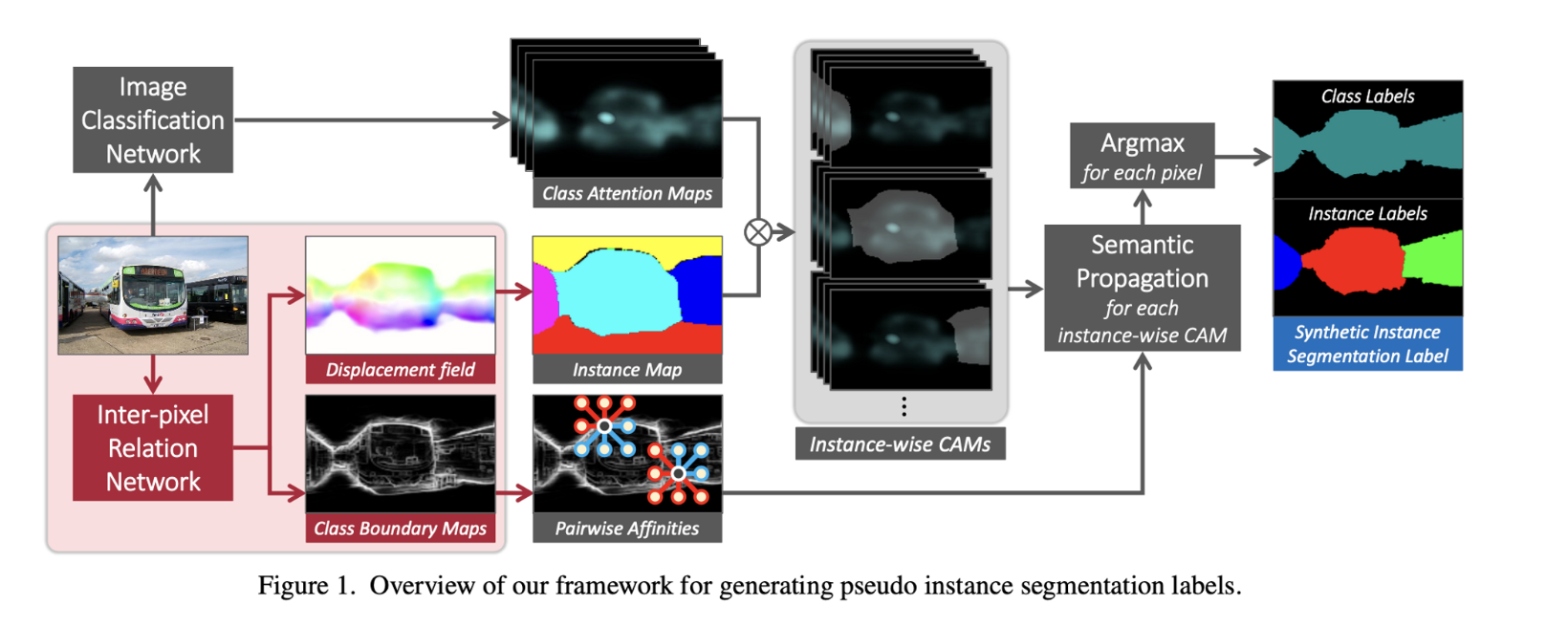
- IRNet은 다음 그림과 같이 instance map을 생성하는 branch와 semantic affinity를 생성하는 두가지 branch로 이루어져 있다.
- Instance map branch
- Displacement field를 예측하는 branch
- 각 픽셀마다 그 픽셀이 존재하는 instance의 centroid에 대한 정보를 담고 있다.
- 같은 centroid를 가지는 픽셀들끼리 같은 instance label을 줘서 instance map을 생성한다.
- Displacement field를 예측하는 branch
- Semantic affinity branch
- different object class 사이의 boundary를 찾아낸다.
- Instance map branch
Contribution
- class-agnostic instance map을 활용한 Image-level supervision 방법을 제안한다.
- semantic affinity를 예측해서 class boundary를 찾아내는 이전 연구보다 더 효율적인 방법을 제안한다.
- PASCAL VOC 2012 dataset에서 image-level label에 대해 SOTA를 달성했으며, Full-supervision 초기 모델을 넘어섰다.
Class Attention Maps
- CAM은 framework에서 두가지 역할을 수행한다.
- Define seed areas of instances
- Extract reliable inter-pixel relations using CAMs
- CAM은 image classification에 GAP를 수행하는 구조로 이루어져 있고, 다음과 같이 나타낼 수 있다.
- f : feature map
- : classification weights on class c
Inter-pixel Relation Network
- IRNet은 두가지 information을 도출한다.
-
Displacement vector field
-
Class boundary map
⇒ 이러한 information을 통해 최종적으로 pseudo mask를 생성한다.
-
IRNet Architecture
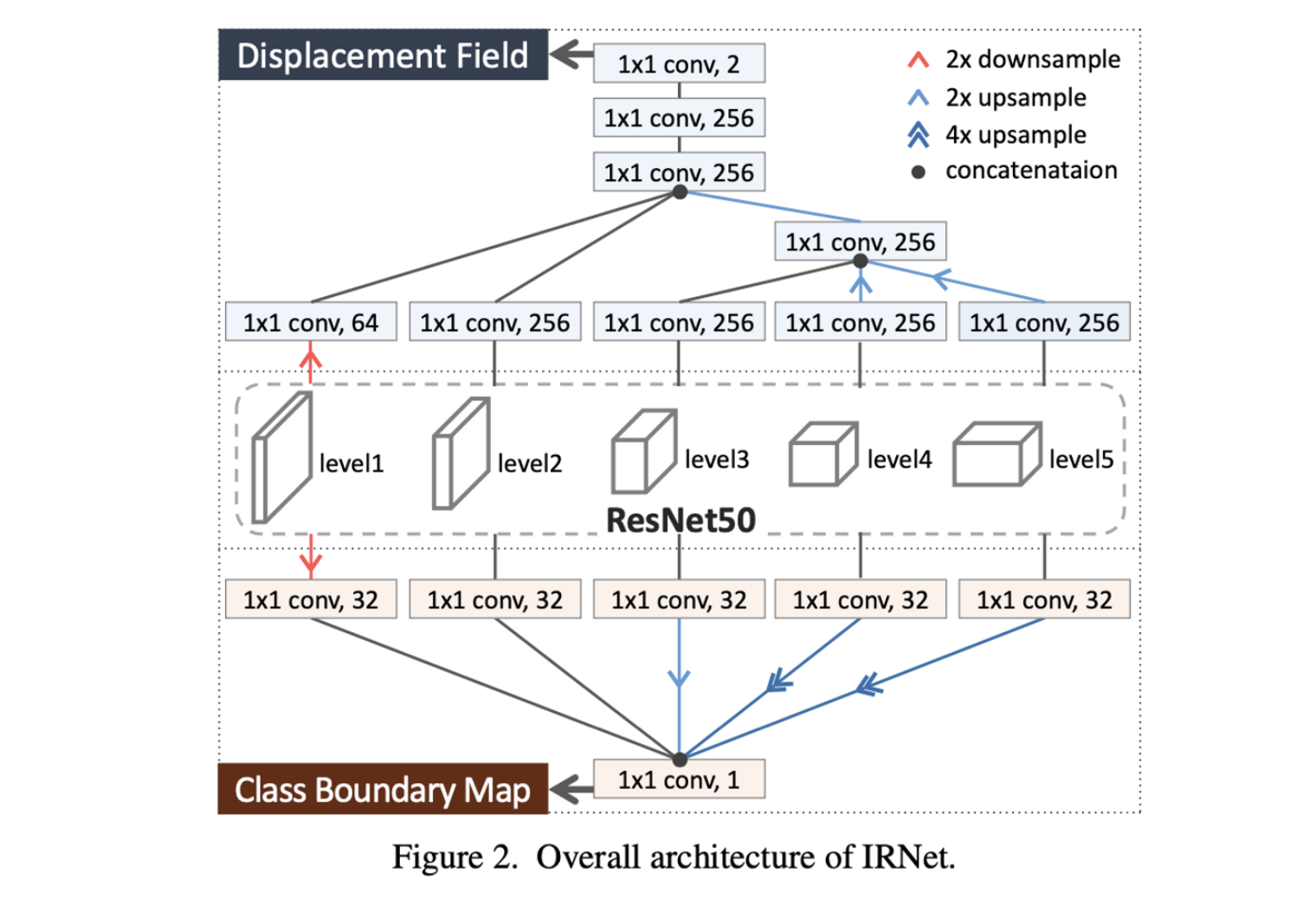
- Displacement Field Prediction Branch
- 위 그림과 같이 ResNet50 backbone의 각 level에서 1x1 convolution을 통해 channel이 256보다 큰 경우, 256으로 맞춰준다.
- 그 후, low-resolution featuer map은 upsampling을 해주고, 같은 resolution을 가진 feature map끼리 concat해서 하나의 feature map으로 만든 후에 1x1 convolution을 통해 displacement field를 생성한다.
- Boundary Detection Branch
- 1x1 convolution을 통해 각 level의 feature map을 dimensionality reduction 해준 후에 size를 맞추어 concat을 해서 class boundary map을 생성한다.
Inter-pixel Relation Mining from CAMs
- Inter-pixel Relation은 두가지로 구성되어 있다.
- displacement between their coordinates
- 단순히 subtraction을 통해서 거리 계산을 한다.
- class equivalence
- pixel-wise class label이 없기 때문에 CAM을 이용한다.
- 하지만, CAM은 blurry하고, 부정확하기 때문에 CAM에서 confident foreground/background attention score를 추출해 일정 threshold 이상일 경우, foreground로 분류하고, 일정 threshold 이하일 경우, background로 분류하고, 여기서 분류되지 않은 pixel은 무시한다.
- 그 후, confident area를 dense CRF를 통해서 pseudo class map을 생성해서 픽셀마다 best score를 가진 class로 분류한다.
- displacement between their coordinates
- 인접한 픽셀들 간의 class equivalence를 고려해서 다음과 같이 로 분류한다.
⇒ Diveide into ,
Loss for Displacement Field Prediction

-
IRNet의 첫번째 branch에서는 displacement vector field 를 예측한다.
- 는 픽셀마다 해당하는 instance의 centroid를 2D vector로 가리킨다.
-
가 displacement field가 되기 위해 두가지 조건을 만족해야 한다.
- ⇒ 일 때 →
-
첫번째 조건을 만족하도록 L1 loss 식을 구해보면 다음과 같이 나타낼 수 있다.
- 두번째 조건의 경우, 첫번째 조건을 만족하도록 학습하는 과정에서 두번째 조건 또한 만족하도록 학습된다.
- background 픽셀의 경우, centroid가 정의되기 어렵기 때문에, loss 식을 다음과 같이 세워서 학습시킨다.
Loss for Class Boundary Detection
- IRNet의 두번째 branch에서는 different class 사이의 boundary를 detect한다. Boundary에 해당하는 output은 로 출력된다.
- class boundary에 해당하는 ground truth label은 없지만, 픽셀 사이의 class equivalence relation을 MIL(Multiple Instance Learning)을 통해 학습시킨다.
- 이 MIL은 class boundary가 different pseudo class label을 가지는 픽셀들 사이에 존재한다고 가정한다.
- MIL?
- 여러개의 input들을 묶어서 학습하는 방식
- 예를 들어, 묶음 Input들 중에 positive한 input이 하나라도 있다면 묶음을 positive input으로 정의하고, 그렇지 않으면 negative input으로 정의한다.
- MIL?
- 이 MIL은 class boundary가 different pseudo class label을 가지는 픽셀들 사이에 존재한다고 가정한다.
- 이러한 idea를 적용하기 위해서 픽셀 사이의 semantic affinity를 정의한다.
- : 와 를 연결하는 직선 위의 픽셀들
- pseudo class label이 동일한 픽셀일 경우 1, 아닐 경우 0으로 나타난다.
- 위와 같이 class equivalence relation을 이용해서 affinity를 학습시킨다.
- 따라서, 다음과 같은 cross-entropy loss 식으로 정의할 수 있다.
Joint Learning of the Two Branches
- 위에서 설명한 두가지 branch에서 도출된 loss를 모두 최소화시키는 방향으로 학습된다.
- 위 Loss는 와 모두 class equivalence만 고려하고, 각 픽셀의 class label은 고려하지 않으므로, class-agnostic하다.
Label Synthesis Using IRNet
- pseudo instance label들을 합성하기 위해서 와 를 각각 class-agnostic instance map과 pairwise affinity로 변환시켜야 한다. semantic affinity의 경우, 로 부터 식에 따라 바로 도출이 가능한데, 의 경우, instance map을 바로 도출하는 것이 불가능하다.
- 이 section에서는 먼저 어떻게 가 instance map으로 변환되는지와 어떻게 pseudo instance segmentation label을 instance map과 affinity map으로 생성하는지에 대해 설명하고 있다.
Generating Class-agnostic Instance map
- class agnostic map 는 로 이루어져 있으며, 각 픽셀이 instance label 정보를 담고 있다.
- 만약, 가 perfect accuracy를 가진다면, 같은 centroid를 갖는 픽셀끼리 묶는 것만으로 바로 얻어질 수 있다.
- 하지만 IRNet은 CAM으로 부터 나온 incomplete supervision으로 부터 학습되기 때문에 정확한 centroid를 예측할 수 없다.
-
따라서, 이러한 문제를 해결하기 위해 iterative한 방법으로 를 계속해서 refine한다.
-
: iteration index
-
Synthesizing Instance Segmentation Labels
-
pseudo mask를 생성하기 위해 일단 첫번째로 CAM을 class-agnostic instance map과 합성하는데 다음과 같은 방법으로 합성한다.
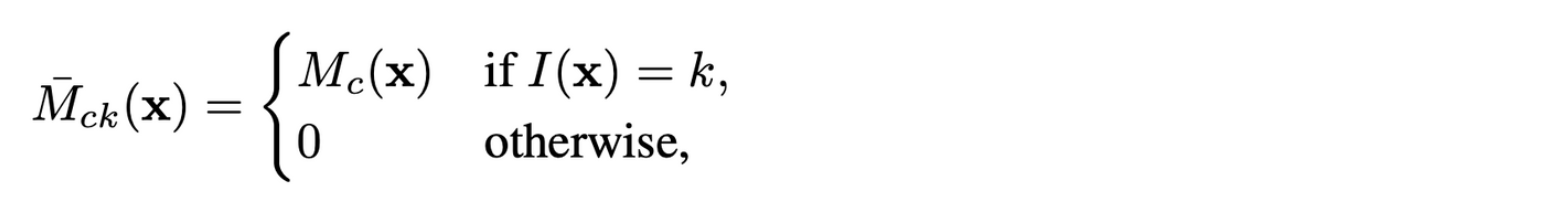
- : instance-wise CAM of class c and instance k
-
각각의 instance-wise CAM은 attention score에 따라서 확장되는데, semantic affinity matrix(Transition matrix)에 따라서 random walk 방법으로 확장된다.
-
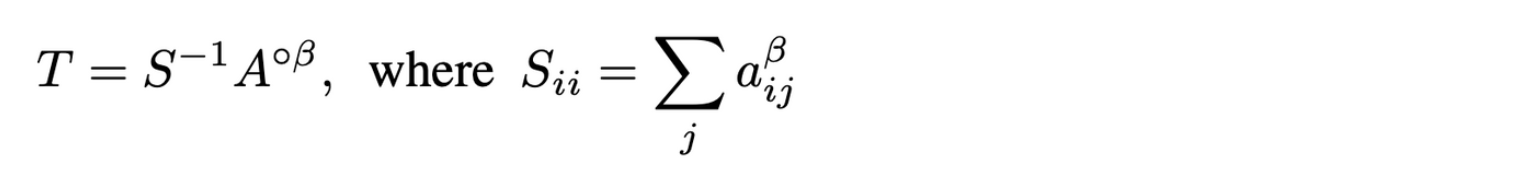
-
: A to the Hadamard power of
-
: diagonal matrix for row-normalization of
-
: transition matrix
-
-
Random walk propagation with T
- : number of iteration
- : hadamard product
- 를 Hadamard 곱해서 같은 class label일 경우, score를 주변 neighbor pixel들에게 propagate하고, 아닐 경우, 하지 않는다.
- 따라서, isolated pixel은 propagate하지 않으므로, 상대적으로 high score를 가진다.
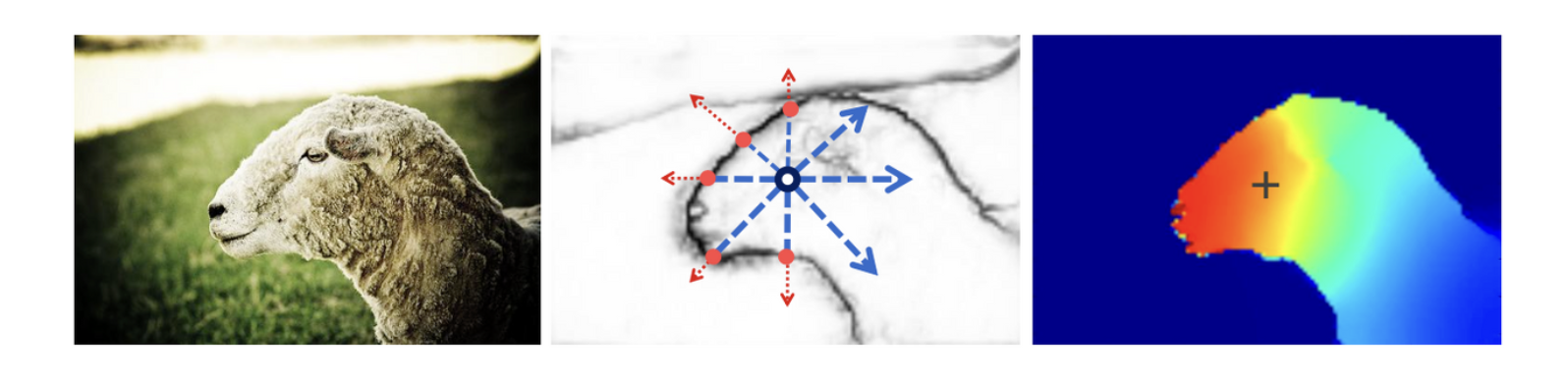
- 이를 통해 maximum score가 25%보다 낮을 경우, background로 간주한다.
-
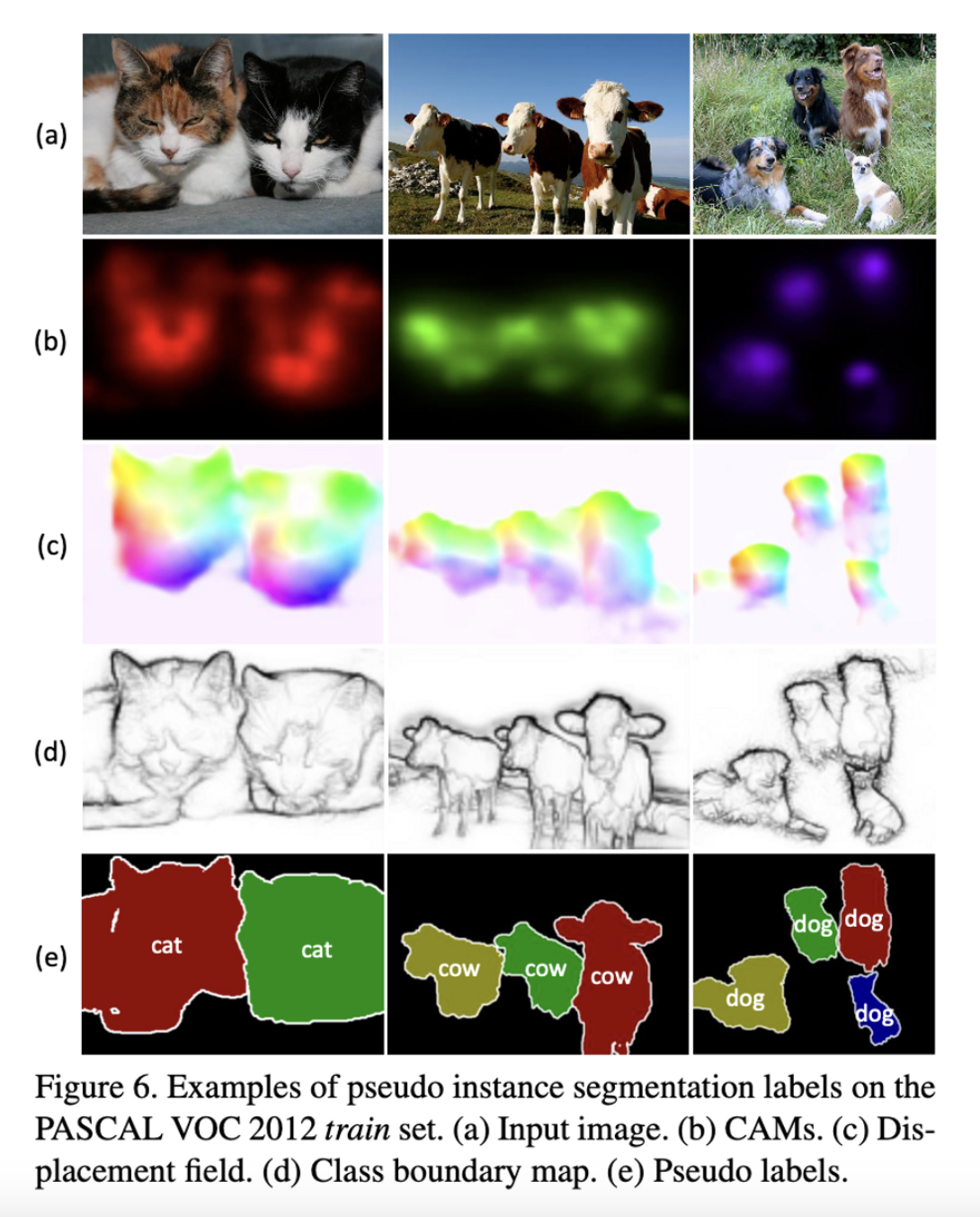
최종적으로, CAM, Displacement field, Class boundary map, Pseudo label에 대한 결과는 다음과 같다.