1. 개요
- Task 정의
- 입력 이미지에 포함된 객체가 무엇인지 추론하는 작업
Image classficiation 예시
- 보통은 1장에 1개의 객체만 포함됨
- 해당 이미지가 관심 객체인지 아닌지 판단하는 binary classfication(개-고양이 분류 등), 여러 class 중 입력 데이터가 어디에 속하는 지 판단하는 multi-class classification(ImageNet 등)로 분류 가능
- 입력 이미지가 주어졌을 때, 예측 결과는 입력 데이터가 각 class일 확률이 주어지며, 따라서 class 개수 만큼의 차원을 가짐
- 예시) output=[0.8] (binary), output = [0.1, 0.5, 0.2, 0.2] (multi-class)
- Binary의 경우 class가 2개(positive, negative)뿐이므로 결과 확률 값이 일정 threshold 이상이면 positive라고 판단
- Multi-class의 경우 결과값 중 가장 큰 class를 선택하며, 위의 예시에서 2번째가 가장 크므로 입력 이미지는 2번 class라고 판단
- 컴퓨터비전에서 가장 기본이 되는 task이며, 데이터의 규모도 가장 크고 각 객체간 구별되는 특징을 추출해낼 수 있어야 하기에 많은 backbone network가 image classification task를 대상으로 pretrain 및 평가됨
- 따라서 여러 유명 network architecture가 제시되었으며, 해당 구조를 응용하여 detection 등 다양한 task에 활용함
- 주요 Metrics
Binary
- True positive(TP): 모델이 positive로 예측한 것 중 올바른 것의 개수
- False positive(FP): 모델이 positive로 예측한 것 중 틀린 것의 개수
- True negative(TN): 모델이 Negative로 예측한 것 중 올바른 것의 개수
- False negative(FN): 모델이 Negative로 예측한 것 중 틀린 것의 개수
- Accuracy: 정확도라고 하며, 모델의 모든 예측 중에 올바르게 예측한 것의 비율 (1에 가까울 수록 좋음)
- 여러 classficiation task에서 주로 사용됨
- 하지만 imbalanced dataset에서는 문제가 발생함
- Dataset에 positive가 10개, negative가 90개 포함
- 모델의 예측 결과는 TP=1, FP=0, TN=90, FN=9 으로 총 100번의 예측 중 대부분(TN+FN=99번)을 negative로 예측
- 이 경우 accuracy는 91%로 꽤 높음
- 하지만 거의 모든 입력 데이터에 대해 negative가 나오도록 편향되어 있어 해당 모델은 잘못 학습된 모델임Accuracy=TP+FP+TN+FNTP+TN
- Precision: 정밀도라고 하며, 모델이 positive로 예측한 것 중 올바른 것의 비율 (1에 가까울 수록 좋음)
- 스팸 메일 필터 등에서는 정상 메일을 스팸이라고 걸러내면 사용자의 불편함이 증가하기 때문에 몇 개의 스팸을 걸러내지 못하더라도 정상 메일을 오분류하지 않는 것에 초점을 맞출 수 있음
- 이러한 경우 precision을 주 metric으로 사용
Precision=TP+FPTP
- Recall: 민감도 또는 재현율 등으로 부르며, 데이터에 포함된 positive 중 모델이 positive라고 예측한 것의 비율 (1에 가까울 수록 좋음)
- 의학 분야 등에서 질병의 유무를 판단할 때, 질병에 걸린 사람을 실수로 오진단하여 넘어가면 안되므로 몇 명의 건강한 사람이 오진을 받더라도 질병에 걸린 모든 사람을 찾는 것에 초점을 맞출 수 있음
- 이러한 경우 recall을 주 metric으로 사용
- True Positive Rate(TPR)라고도 함
Recall=TP+FNTP
- F1 score: precision과 recall의 조화평균 (1에 가까울 수록 좋음)
- 위(accuracy에서 가정된 상황)의 case에서 precision은 1, recall은 0.1
- 산술 평균으로 F1 score를 구할 경우, precision의 값이 매우 높기 때문에 0.55 정도의 비교적 높은 수치를 얻음
- 하지만 조화평균을 사용할 경우 0.18가 되어 수치가 작은 recall가 잘 반영됨
- Imbalanced dataset에서도 동작
F1 score=Precision+Recall2∗Precision∗Recall=TP+21(FP+FN)TP
- Specificity: 특이도라고 하며, 데이터에 포함된 negative 중 모델이 negative라고 예측한 것의 비율 (1에 가까울 수록 좋음)
Specificity=TN+FPTN
FPR=TN+FPFP
- Receiver Operating Characteristic(ROC) curve: TPR과 FPR의 관계를 그린 그래프
- 극단적인 예시로 Dataset에 positive가 1개, negative가 99개 포함되어 있고, 모델이 모든 경우 negative라고 예측했을 경우 F1 score는 거의 1로 매우 높음
- 하지만 FPR의 측면에서 FPR이 거의 1이므로 좋지 않은 모델
- ROC curve는 이러한 경우에도 대응 가능
- 일반적인 분류 모델은 "해당 입력 데이터가 positive일 확률" 형태로 결과가 나오므로 일정 threshold 이상의 값이 나올 경우 positive로 판단함
- 따라서 threshold에 따라 TPR과 FPR가 변화 (threshold가 극단적으로 낮으면 모든 입력에 대해 다 positive라고 판단하므로 TPR=FPR=1, threshold가 극단적으로 높으면 모두 negative라고 판단하므로 TPR=FPR=0)
- 잘 학습된 분류기는 모든 positive 샘플에 대해서 결과값으로 1에 가까운 값을, 모든 negative 샘플에 대해서 결과값으로 0에 가까운 값을 출력
- 극단적으로 완벽한 분류기는 threshold=0일 때 TPR=FPR=1, 0<threshold<1 일 때 TPR=1 & FPR=0(완벽히 분류), threshold=1일 때 TPR=FPR=0으로 좌상단에 붙어있는 ROC 커브 형태가 됨
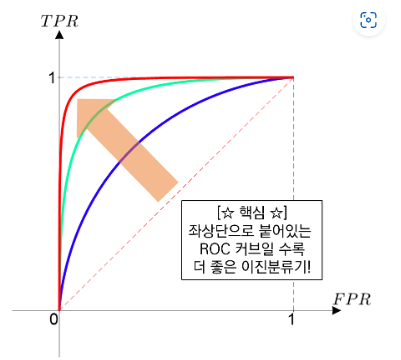
ROC curve 예시 (출처: https://angeloyeo.github.io/2020/08/05/ROC.html)
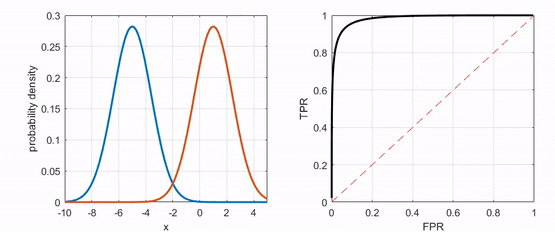
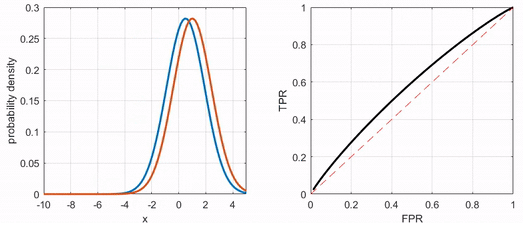
ROC curve 비교 (출처: https://angeloyeo.github.io/2020/08/05/ROC.html)
- Area Under the Curve(AUC) score: 보통 ROC curve와 조합되어 ROC 커브 아래의 면적을 의미 (1에 가까울 수록 좋음)
- 1에 가까울 수록 ROC 커브가 좌상단에 붙어있다는 의미
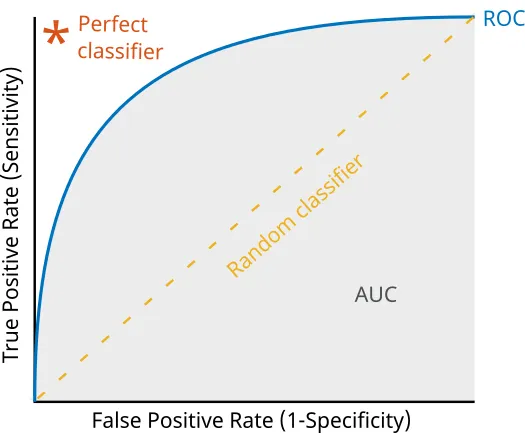
AUC-ROC 예시 (출처: https://docs.clarifai.com/tutorials/how-to-evaluate-an-image-classification-model/)
Multi-Class
- 위 binary classification metric을 각 class 마다 적용 및 평균 계산
- Binary classification과는 달리 분류해야하는 class가 여러 개이므로 위 binary classification metric을 바로 사용하기는 어려움
- 하지만 하나의 class를 positive, 다른 class들을 negative로 생각하면 각 class 별로 binary classification metric을 적용 가능
- 각 class 별로 계산한 binary classification metric(Precision, Recall 등)의 평균을 구하여 multi-class classification metric으로 활용
- Macro 평균화: 각 class별 precision, recall등의 산술 평균 사용(class 별 가중치를 줄 수도 있음)
Precisionmacro=K∑iKPrecisionclass=i Recallmacro=K∑iKRecallclass=i F1macro=K∑iKF1class=i
- Mirco 평균화: 전체 TP, FP, TN, FN의 수치를 사용하여 계산
Precisionmirco=∑iKTPclass=i+∑iKFPclass=i∑iKTPclass=i Recallmirco=∑iKTPclass=i+∑iKFNclass=i∑iKTPclass=i F1mirco=∑iKTPclass=i+21(∑iKFPclass=i+∑iKFNclass=i)∑iKTPclass=i
- Accuracy: 정확도를 의미하며, 가장 많이 사용되는 metric
Accuracy=total predictioncorrect prediction
- Multi-class classiciation에서는 입력데이터가 각 class에 해당할 확률이 출력되며, class 개수만큼의 차원을 갖음
- 따라서 여러 개의 확률값 중 가장 높은 수치를 갖는 class로 입력데이터를 분류
- Top 1 accuracy: 결과값 중 가장 높은 수치를 갖는 class가 실제 label과 같을 때 correct prediciton으로 판단
- Top N accuracy: 결과값 중 가장 높은 수치를 갖는 N 개의 class 중 실제 label이 포합되어 있을 때 correct prediciton으로 판단
- Confusion matrix: 각 class별로 예측한 분포를 matrix로 표현
- 아래 그림에서 분류 모델이 cat 입력데이터를 cat이라고 정확히 예측한 횟수는 826번
- cat 입력데이터를 dog라고 잘못 예측한 횟수는 48번
- dog 입력데이터를 cat이라고 잘못 예측한 횟수는 111번으로 두 경우 모두 수치가 높은 것으로 보아 주어진 모델은 cat-dog간 구분을 타 class 간 구분보다 어려워하는 것으로 보임
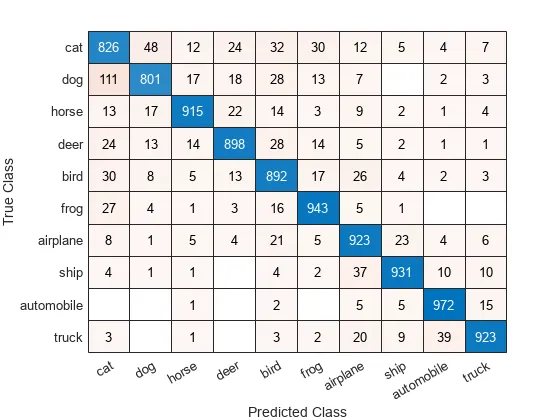
Confusion matrix 예시 (출처: https://docs.clarifai.com/tutorials/how-to-evaluate-an-image-classification-model/)
2. 주요 연구
