1. 개요
- Task 정의
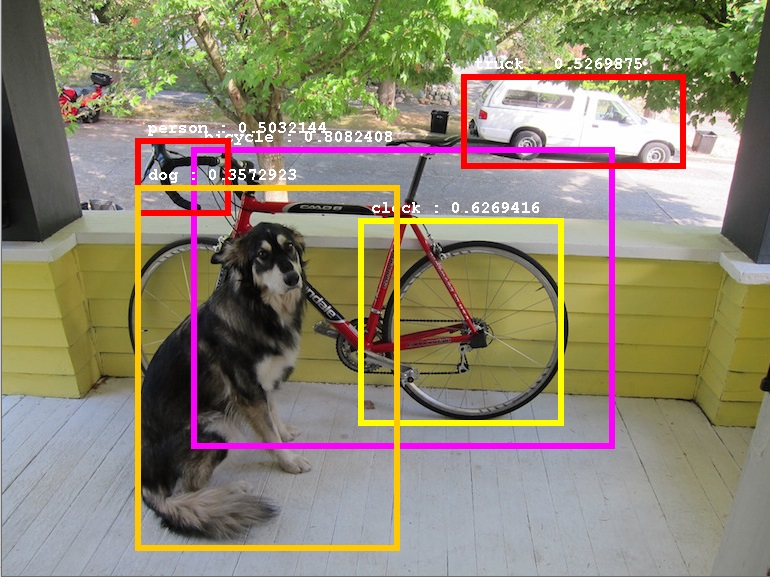
Object detection 예시
-
입력 이미지에 포함된 객체의 위치 및 크기와 종류를 추론하는 작업
-
하나의 입력 이미지에 여러 개의 객체가 포함될 수 있음
-
모델의 output은 보통 3가지
- Bounding box
- 해당 bounding box에 객체가 존재할 확률 (confidence)
- 해당 bounding box에 존재하는 객체의 class별 확률
-
Bounding box는 객체의 위치와 크기를 의미
- Bounding box의 표현 방법에는 여러가지가 있dma
- 사각형의 왼쪽 위 꼭지점의 좌표 , 오른쪽 아래 꼭지점의 좌표 로 표현
- 객체의 중심 좌표 와 bounding box의 높이 및 너비 로 표현
- Network를 사용하여 bounding box을 추론하는 방법은 각 논문마다 다를 수 있음
- 특수한 경우 object의 위치(center point)만 추론하거나, bounding box가 회전되어 있는 경우도 있음
- Bounding box의 표현 방법에는 여러가지가 있dma
-
객체의 존재 유무는 binary classification과 비슷
-
객체의 종류에 대한 output은 multi-class classification과 비슷
- Softmax를 적용하여 각 class 별 확률을 구함
- 주요 Metrics
-
Mean Average Precision(mAP) : 각 class 별 Average Precision(AP)를 구하고, 평균을 구함
-
mAP를 구하는 과정
-
1. Detection model output 취득
- Detection model output = (bounding boxes, confidence scores, class scores)
-
2. Non-Maximum Suppression (NMS) 적용
-
Detection model은 구조상 하나의 객체에 대해서 여러 개의 bounding box를 예측할 수도 있음 (아래 "주요 연구" 파트 참조)
-
따라서 bounding box들의 IoU를 계산하여 과도하게 겹쳐있는 bounding box들은 하나의 객체에 대한 예측이라고 생각하고, 가장 높은 confidence score를 가진 bounding box만 남기고 나머지는 제거
-
IoU: 두 bounding box가 겹친 영역과 두 bounding box의 전체 영역 사이의 비율
-
Sample code: bounding box는 (cx, cy, w, h)로 표현
def batch_iou(boxes, box): # 겹치는 부분의 너비 계산 lr = np.maximum( np.minimum(boxes[:,0]+0.5*boxes[:,2], box[0]+0.5*box[2]) - \ np.maximum(boxes[:,0]-0.5*boxes[:,2], box[0]-0.5*box[2]), 0 ) # 겹치는 부분의 높이 계산 tb = np.maximum( np.minimum(boxes[:,1]+0.5*boxes[:,3], box[1]+0.5*box[3]) - \ np.maximum(boxes[:,1]-0.5*boxes[:,3], box[1]-0.5*box[3]), 0 ) inter = lr*tb union = boxes[:,2]*boxes[:,3] + box[2]*box[3] - inter return inter/union def nms(boxes, confidence, threshold): # 내림차순으로 정렬 order = confidence.argsort()[::-1] # 개수 대로 true 리스트 생성 keep = [True]*len(order) for i in range(len(order)-1): # IOU 계산 (특정 bounding box와 그 이하의 confidence를 가진 bounding box들) ovps = batch_iou(boxes[order[i+1:]], boxes[order[i]]) for j, ov in enumerate(ovps): if ov > threshold: # IOU가 특정 threshold 이상인 box를 False로 세팅 keep[order[j+i+1]] = False return boxes[keep]
-
-
3. Class 별 AP 계산
-
AP를 계산할 class를 선택하고 해당하는 class에 대한 bounding box와 confidence 값을 추출 (각 bounding box의 class 예측 결과 중 해당 선택 class의 수치가 가장 높은 경우)
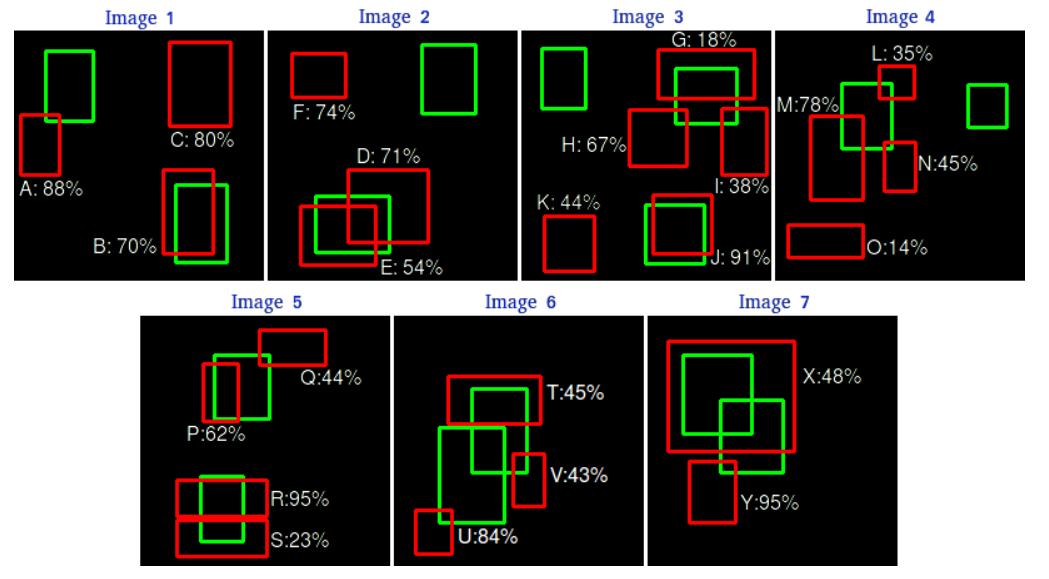
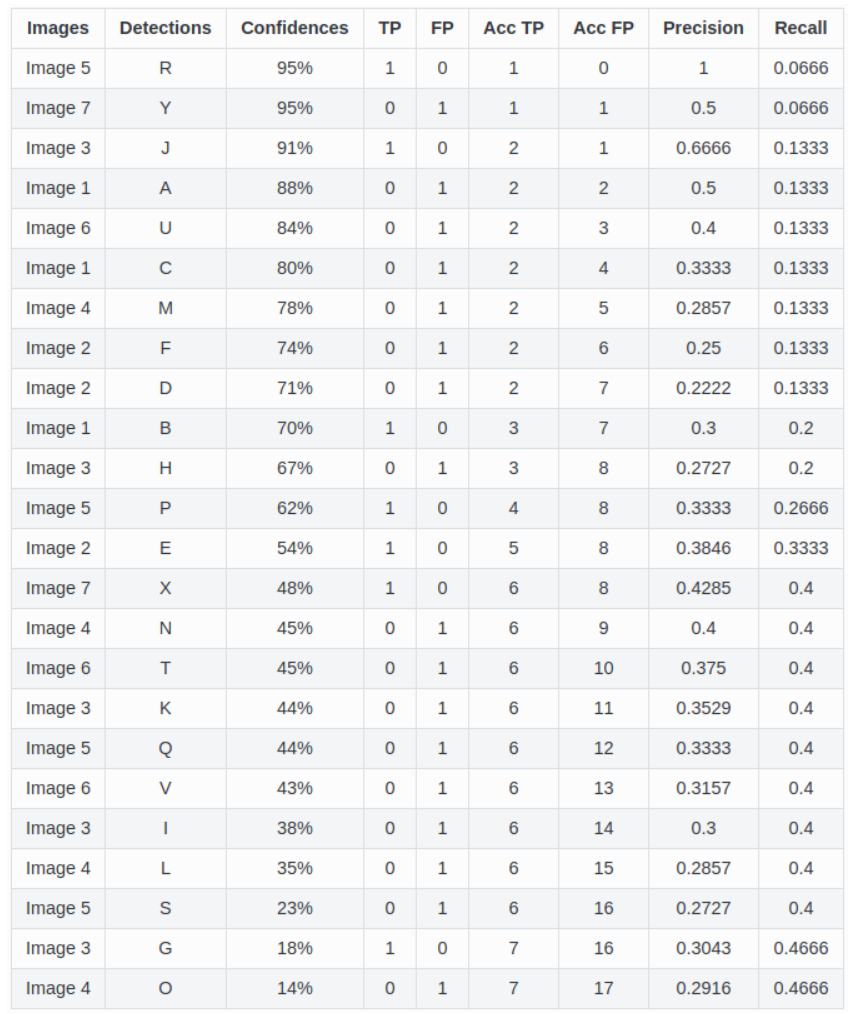
예측된 bounding box들과 precision, recall 계산 결과 -
Bounding box를 confidence score에 따라 정렬
-
각 confidence를 confidence threshold로 설정하여 각 threshold 마다의 precision, recall을 계산 : 위 표에 따라 처음에는 threshold를 95% 두고 계산, 그 다음은 91%, 그 다음은 88%, ...
-
TP: confidence threshold 이상의 확률을 갖는 예측 bounding box들 중 일정 수치(IoU threshold) 이상의 IoU를 갖는 ground-truth bounding box가 존재하는 것의 개수
-
FP: confidence threshold 이상의 확률을 갖는 예측 bounding box들 중 일정 수치(IoU threshold) 이상의 IoU를 갖는 ground-truth bounding box가 없는 것의 개수
-
FN: ground-truth bounding box 중 일정 수치(IoU threshold) 이상의 예측 bounding box가 없는 것의 개수
-
Precision = TP/(TP+FP), Recall = TP/(TP+FN)
-
모든 confidence threshold에 대해 반복하고, 이를 이용하여 다음과 같은 그래프 작성
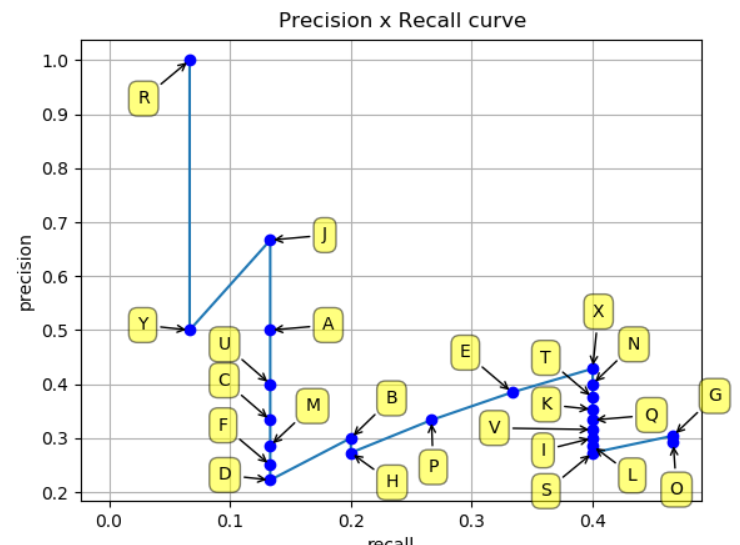
Precision-Recall(PR) curve -
해당 그래프의 아래 면적(AUC)이 AP
-
다만 그래프의 모양이 부드러운 곡선이 아닌 지그재그 모양이기 때문에 계산의 용의성을 위해 N-point interpolation, All-point interpolation 등을 사용(dataset마다 공식적으로 사용하는 방법이 다름)
-
11-point interpolation: recall을 11개의 간격(0, 0.1, 0.2, ..., 1)으로 나누고, 각 위치마다 현재 Recall보다 큰 Recall의 precision 중 가장 큰 값(max)을 취하여 얻은 모든 precision을 평균내어 AP를 구함
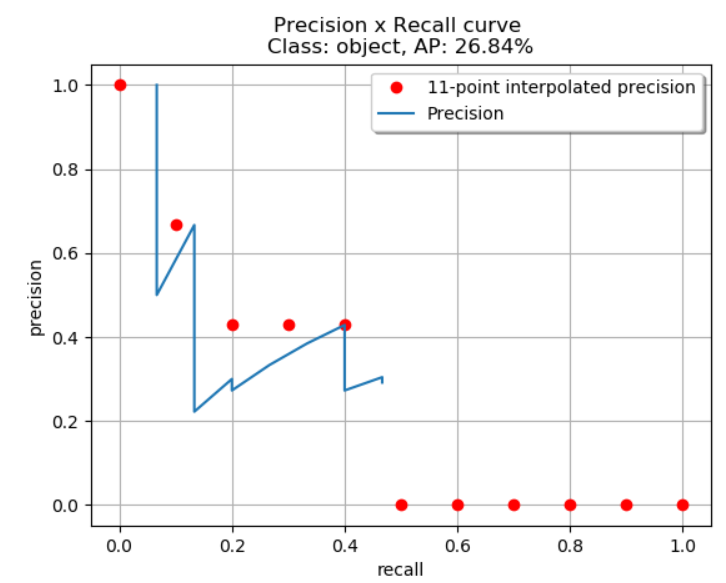
11-point interpolation 예시 -
All-point interpolation: 위와 원리는 같으나 일정 간격마다 interpolation 하는 것이 아니라 그래프의 각 점에서 interpolation하여 아래 그림과 같이 그래프를 단순화하고, 아래 면적을 구함
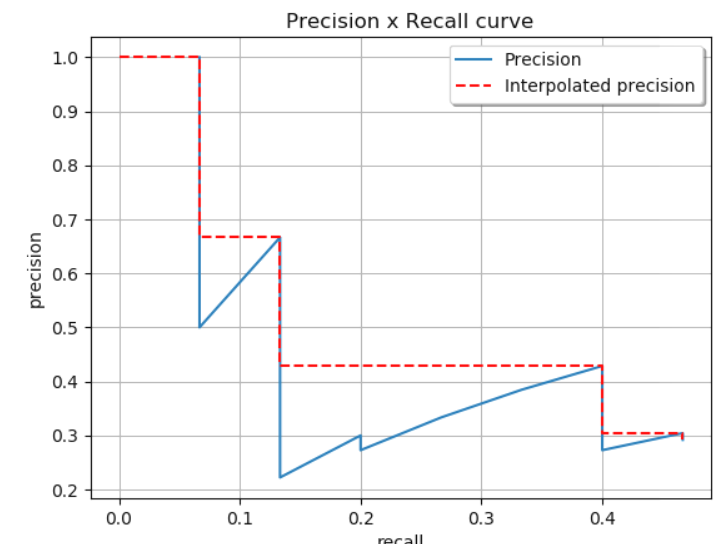
All-point interpolation 예시
-
-
4. mAP 계산
- 모든 class의 AP에 대한 산술평균
- 다만, dataset에 따라 공식적으로 사용하는 mAP 계산 방법이 조금씩 다름
- Pasval VOC dataset의 경우 IoU threshold를 0.5로 두고, 혹시 하나의 객체에 대해 여러 bounding box가 예측되었을 경우 하나만 positive, 나머지는 negative로 취급(NMS를 거치더라도 상황에 따라 중복탐지가 존재할 수도 있음) (, (IoU threshold=0.75인 경우)등으로 표현)
- COCO dataset의 경우 IoU>0.5, IoU>0.55, IoU>0.6, …, IoU>0.95 각각을 기준으로 mAP를 계산한 후 평균
-
2. 주요 연구
R-CNN
(R-CNN)1. R-CNN구조
(R-CNN)2. Selective Search
목표
- Classfication task에서 고성능을 달성한 deep learning 방법을 detection task에도 적용(최초)
Method
-
Selective search는 <(R-CNN)2>와 같이 입력 영상의 색상, 명암 등의 정보를 기반으로 픽셀을 군집화하여 각 객체의 위치를 찾음. 이러한 방법을 사용하여 입력 영상 내 관심 객체가 존재할 것 같은 위치(초록색 box)를 다수 추출하고, 일정한 크기로 resizing 한 후, 다음의 CNN 모듈로 전달함. Region proposal 단계라고도 함.
- 해당 단계에서 추출된 region proposal과 ground-truth 사이의 IoU를 기반으로 positive sample(관심 객체가 포함된 영역)과 negative sample(관심 객체가 포함되지 않고 배경만 포함된 영역)을 분류함.
- AlexNet의 fine tuning, classifier 등의 학습에는 positive sample과 negative sample가 모두 필요하기 때문(positive sample만 있으면 학습이 되지 않음)
-
Feature extraction을 위한 CNN 모듈을 각 region proposal에 적용하며, R-CNN 논문에서는 pretrain된 AlexNet을 detection 데이터셋에서 fine tune하여 사용
-
추출된 Feature에 SVM에 적용하여 입력된 영역에 포함된 관심 객체의 종류를 구분하는 classifier 학습
- 이 논문이 나올 당시 실험 결과로 CNN+FC+Softmax 조합보다 SVM을 썼을 때 성능이 더 좋았다고 함
- 요즘에는 보통 Softmax 사용하여 classification 파트까지 end-to-end로 학습
-
추출된 Feature에 Bounding box regressor를 적용하여 selective search의 결과를 보정하고, 더욱 정확한 bounding box를 추출함
- selective search로 추론한 bounding box를 ground-truth와 비슷하게 변환해주는 transformation 매개변수를 찾는 과정
- Bounding box regressor는 신경망을 통해 구현되어 positive sample을 이용하여 학습
-
NMS를 적용하여 대표 bounding box만 남김
특징
- (단점) Selective search는 CPU기반으로 동작하여 매우 느림
- (단점) Selective search의 결과물이 2000개 가량 나오는데, 이렇게 추출된 이미지 패치를 CNN에 순차적으로 입력하다보니 연산 시간이 매우 오래 걸림
- (단점) 학습해야하는 모듈이 AlexNet(CNN, feature extraction 파트), SVM(classification 파트), bounding box regressor 3개인데 end-to-end로 한번에 학습하지 못하고 세 개의 모듈을 각각 학습하여 비효율적임
Fast R-CNN
목표
- R-CNN의 단점 중 일부를 개선
- Selective search의 결과(약 2000개의 region proposal)을 순차적으로 CNN에 입력하여 feature를 추출하는 대신, 원본 이미지 전체를 CNN에 입력하여 feature를 한번에 추출
Method
(Fast R-CNN)1. Fast R-CNN구조
(Fast R-CNN)2. RoI Pooling 방법
-
Selective search를 사용하여 region proposal 추출
-
VGG16 등의 모델에 전체 이미지를 입력하여 feature map 추출
- CNN 모델에 포함된 convolution, pooling 연산 등으로 인해 원본 이미지 크기에 비해 작은 크기를 갖는 feature map이 추출됨
- 따라서 다음 단계에서 소개하는 RoI project을 적용하여 위치 후보를 추출
-
원본 이미지 크기와 feature map의 크기 간 비율을 이용하여, 1단계에서 추출된 region proposal을 feature map에 projection. 이를 통해 feature map 상에서의 region proposal을 추출함
- 각 region proposal은 크기가 다르기 때문에 CNN에 바로 입력하지 못함(CNN은 고정된 형태의 모델이기 때문에 입력 크기가 달라지면 출력 크기도 달라짐. 따라서 정의된 loss funcion 및 prediction 방법을 적용하지 못함)
- 이를 해결하기 위해 다음 단계의 RoI Pooling을 적용하여 모두 같은 크기로 맞춰줌
-
Feature map 상에서 추출된 region proposal에 RoI Pooling을 적용하여 모두 같은 크기의 feature가 되도록 함.
- 만약 우리가 2x2 크기의 feature로 통일시키고자 한다면, <(Fast R-CNN)2>에서 볼 수 있듯이 region proposal을 적당히 2x2의 블록으로 쪼개고, 각 블록에서 max pooling등을 적용하여 하나의 값만 남도록 함
-
추출된 각 RoI에 대해서 FC layer 등을 적용하여 classfication 및 bounding box regression을 수행
- 각 RoI에 대해 순차적으로 수행
- RoI pooling을 통해 나온 feature(7x7x512=25088)을 FC layer를 통해 (4096)크기의 vector를 계산하는 과정에서 연산량이 매우 많이 요구되므로, inference 시에는 Truncated SVD를 통해 FC layer 가중치 matrix를 근사하는 저용량의 matrix를 계산하여 연산량을 절약
- R-CNN과 달리 classification을 위해 Softmax를 사용하며, classfication 및 bounding box regression을 하나의 multi-task loss로 동시에 학습
-
NMS를 적용하여 대표 bounding box만 남김
특징
- R-CNN의 단점 중 일부를 개선하여 속도를 더욱 빠르게 함
- (단점) 아직 selective search를 사용하여 bottleneck이 존재
Faster R-CNN
목표
- RPN(Region Proposal Network)를 제안하여 selective search 등으로 수행하던 region proposal 또한 신경망으로 대체
- 속도를 더욱 빠르게 개선
Method
(Faster R-CNN)1. Faster R-CNN구조
(Faster R-CNN)2. Anchor Box 예시
(Faster R-CNN)3. RPN(Region Proposal Network)
-
전체 이미지를 CNN 네트워크에 입력하여 feature를 추출
-
1번 단계에서 추출한 feature map을 RPN에 입력하여 region proposal 추출
- 추출된 feature map은 CNN에 의해 원본 이미지에 비해 축소된 크기를 가지므로, <(Faster R-CNN)2>의 우측 그림처럼 원본 이미지를 몇 개의 grid로 나눈 것에 대응됨(feature map의 크기가 8x8이라면, feature map의 각 원소는 원본 이미지를 8x8 grid로 나눈 영역 중 하나에 대응됨)
- RPN의 기본 아이디어는 각 grid cell에 객체가 존재하는 지의 여부, 존재한다면 그 크기는 어떤지(bounding box)를 예측하여 region proposal을 추출(detection task와 비슷하지만, 객체의 존재 여부만 예측하고, 그 종류는 classify하지 않음)
- 다만, 등장하는 객체의 크기, 모양이 모두 다르므로, <(Faster R-CNN)2>의 좌측 그림처럼 몇 개(논문에서는 9개)의 anchor box를 정의하여 각 anchor box와 ground-truth 사이의 IoU를 측정해 positive/negative sample를 분류함 (RPN 학습용)
- Anchor 박스는 가로, 세로의 비율(aspect ratio)과 scale를 조합하여 생성
- 따라서, RPN의 output은 각 anchor box에 대한 존재여부/bbox regression parameter를 포함하며, anchor box가 9종류라면, "존재여부 = 2x9=18", "bbox regression parameter = 4x9=36"의 결과값을 출력함
-
추출된 region proposal를 사용하여 1번 단계에서 추출한 feature map에 대해 RoI projection, RoI pooling을 적용
- Region proposal과 GT간 IoU를 측정해 positive/negative sample를 분류함 (faster R-CNN 학습용)
-
각 RoI에 대해서 classfication 및 bounding box regression을 수행
-
NMS를 적용하여 대표 bounding box만 남김
특징
- RPN의 제시로 속도 및 성능을 고도화
- Region proposal - prediction으로 이루어지는 2-stage detector의 기본 형태를 제시
- (단점) Region proposal이 bottlenect이 되어 속도가 그리 빠르지 않음 -> 1-stage detector의 개발 원인
Yolo
목표
Method
특징
YoloX
목표
Method
특징
