해당 포스트는 "단단한 강화학습", "단단한 심층강화학습"의 내용을 기반으로 작성됨.
1. 강화학습 개요
우선 강화학습(reinforcement learning)은 지도학습(supervised learning)과 비지도학습(unsupervised learning)과 함께 기계학습을 구성하는 방법이며, 따라서 강화학습을 학습하기 전 해당 방법과 타 방법(지도학습, 비지도학습) 간의 차이점을 인식하는 것이 중요하다.

그림 1. Yann LeCun의 케이크
먼저 지도학습는 가장 흔하게 접할 수 있는 학습 방법으로 외부 전문가가 개입하여 데이터에 대한 참값(label)을 제공하고, 기계는 data-label 쌍을 통해 그 관계를 학습한다. 하지만 뒤에서 학습하겠지만 강화학습의 경우 주어진 환경에서 최적의 행동을 찾는 문제에 많이 사용되고, 이를 위해 최적 행동에 대한 label을 사용하는 대신 환경에서 획득하는 보상을 통해 학습을 진행한다는 것이 지도학습과 구분된다.
Label을 사용한다는 점에서 비지도학습의 한 종류로 보일 수도 있지만 이 또한 구분되어야 하는 개념이다. 비지도학습의 경우 clustering 등의 문제를 포함하는데, 스스로 주어진 데이터 집합의 구조를 찾는 등의 작업을 수행한다. 하지만 강화학습에서 사용되는 상태, 행동 등과 같은 데이터의 구조를 분석한다고 해서 보상을 최적화하는 최적 행동을 찾는 것은 불가능하며, 강화학습에서는 지속적으로 여러 시행을 통해 행동 정책을 업데이트해 나간다.
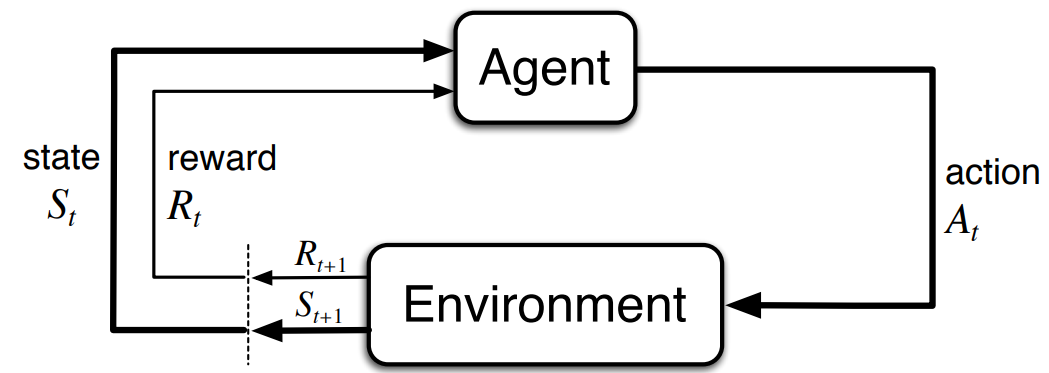
그림 2. 강화학습의 구조

그림 3. OpenAI Gym의 Atari 게임 중 Breakout
강화학습은 그림2과 같이 이루어지며, 주어진 환경(environment)에서 agent가 어떠한 행동(action)을 하면, 그에 알맞는 보상을 얻게 된다. 예를 들면, 강화학습은 게임 인공지능을 만들 때도 많이 사용되는데, 그림3에서 볼 수 있는 벽돌부수기 게임(Breakout)을 보면, environment은 게임 시스템, agent는 사람이 조작하게 되는 하단의 판자가 되며, action은 판자를 움직이는 방향, 보상은 게밍 점수가 된다. 추가적으로 state는 현재의 environment와 agent의 상태를 의미하는데 그림3에서는 남아있는 벽돌의 개수와 위치, 현재 판자의 위치, 공의 위치와 속도 등이 포함된다. 강화학습의 목표는 agent를 이리저리 움직여보며(exploration) reward를 얻고, 그에 대한 데이터를 축적하여, 최종적으로는 최적 reward를 얻을 수 있는 행동을 찾는 것이다.
이러한 강화학습에는 우리가 수식으로 표현하여 풀어야하는 몇 가지의 주요한 구성 요소가 있다.
- 정책(policy): 주어진 state에 대해서 어떤 행동을 취할 지 정함.
- 보상(reward): 주어진 state에서 어떤 행동을 했을 때 environment에서 취득되는 보상이며, 이를 최적화 해야 함
- 가치함수(value function): 주어진 state에서부터 일정 시간 동안 기대할 수 있는 보상의 총량
- 모델(model): environment를 모사하며, 주로 주어진 state에서 어떤 행동을 취했을 때 state가 어떻게 변화할 지를 모델링 함
2. 기초 용어 DP 풀이
우선 agent와 environment간의 상호작용이 어떻게 일어나는지 보면, 그림 2에서 agent는 초기 state S0를 보고, 자신이 취해야하는 action A0를 결정한다. 해당 action을 취하면, environment는 agent에게 특정한 reward R1를 주고, action의 결과로 전체적인 state가 변화하여 S1이 된다. 강화학습의 학습 과정 및 데이터 수집은 보통 이와 같은 과정의 반복이다.
S0,A0,R1,S1,A1,R2,S2,⋯
강화학습에서는 보통 MDP(Markov Decision Process)를 가정하며, 이는 다음과 같이 강화학습의 dynamics(또는 model)를 정의할 수 있도록 한다.
p(s′,r∣s,a)=Pr{St=s′,Rt=r∣St−1=s,At−1=a}
이는 St,Rt 각각 이 어떤 특정 값을 가질 확률은 바로 이전 time step의 St−1,At−1에만 영향을 받으며, 그 이전 값들에 대해서는 영향을 받지 않음을 의미한다. 또한 여기서는 구분하지 않았지만, 때때로 agent가 관측한 state와 실제 environment의 state는 다를 수 있다(센서의 노이즈 등의 문제). 이러한 문제는 POMDP(Partially Observable MDP)라고 구분짓기도 한다.
이렇게 dynamics를 정의하면 다음과 같이 상태 전이 확률이나 보상의 기대값 등을 계산할 수 있다(아래 식의 가장 마지막 부분에서는 조건부확률 식, p(A∣B)=p(A∩B)/p(B)에서 구할 수 있다).
상태전이확률:p(s′∣s,a)=Pr{St=s′∣St−1=s,At−1=a}=r∈R∑p(s′,r∣s,a)
보상의기대값:r(s,a)=E[Rt∣St−1=s,At−1=a]=r∈R∑rs′∈S∑p(s′,r∣s,a)
보상의기대값:r(s,a,s′)=E[Rt∣St−1=s,At−1=a,St=s′]=r∈R∑rp(s′∣s,a)p(s′,r∣s,a)
이제 학습의 목표가 되는 이득(return)을 정의해보자. 가장 간단한 예시로 이득을 앞으로 얻을 것으로 예상되는 reward의 총합으로 다음과 같이 정의할 수 있다.
Gt=Rt+1+Rt+2+Rt+3+⋯+RT
여기서 T는 종단 상태(terminal state)라고 분리는 상태에 도달한 것으로 게임이 끝나는 등의 상황이라고 생각하면 된다. 이렇게 종단 상태가 존재하는 작업으로 episodic task라고 하며, 때때로 종단 상태 없이 계속 끝없이 이어지는 작업도 있는데 이를 continuing task라고 하고, T=∞가 된다. 다만 T=∞라면 보상의 합 또한 끝없이 발산한 것이므로, 할인율(discount rate), 0≤γ≤1을 곱하게 되며 이러한 이득을 정리하여 작성하면 다음과 같다.
Gt=k=t+1∑Tγk−t−1Rk
여기서 할인율은 이득 값의 발산을 막는 역할 외에도 그 수치에 따라 short-term reward를 중요시하느냐, long-term reward를 중요시 하느냐를 결정하게 되는데, 예를 들어 할인율이 매우 작다면(≈0), 이득은 거의 현재 step에서 취득되는 reward로 결정이 될 것이고, 충분히 크다면 먼 미래의 reward 또한 전체 이득에 큰 영향을 줄 것이다.
이러한 이득을 통해 우리는 강화학습이 최적화 하고자 하는 목표식인 가치함수를 정의할 수 있다. 가치함수는 현재 state에서 앞으로 어떠한 정책, π을 따랐을 때 기대되는 이득으로 다음과 같이 정의할 수 있다.
vπ(s)=Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1∣∣∣∣∣∣St=s]
이와 비슷하게 현재 state에서 정책 π을 따라 action a를 취했을 때의 가치 qπ(s,a)는 다음과 같이 정의할 수 있다(행동 가치 함수).
qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[k=0∑∞γkRt+k+1∣∣∣∣∣∣St=s,At=a]
어떠한 state에서의 가치함수는 주어진 정책을 따랐을 때 기대되는 이득으로 다음의 벨만 방정식(Bellan equation)처럼 이후 state에서의 가치함수와 재귀적인 특성을 보이며, 올바른 가치함수는 이와 같은 일관성을 유지하여야 한다.
vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+1+γGt+1∣St=s]=a∑π(a∣s)s′∑r∑p(s′,r∣s,a)[r+γE[Gt+1∣St+1=s′]]=a∑π(a∣s)s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
강화학습의 목표는 장기적으로 많은 보상을 얻는 정책을 찾는 것으로 어떤 정책 π가 다른 모든 정책 π′ 및 모든 state s에 대해서 vπ(s)≥vπ′(s)를 만족하면 π를 최적의 정책이라고 할 수 있다. 이러한 최적 정책은 보통 π∗와 같이 표현하며, 최적 정책을 따를 때의 가치함수는 다음과 같이 쓸 수 있다.
v∗(s)=πmaxvπ(s)
q∗(s,a)=πmaxqπ(s,a)=E[Rt+1+γv∗(St+1)∣St=s,At=a]
여기서 행동 가치 함수는 주어진 state에서 a라는 행동을 한 뒤 최적 정책 π∗를 따르면 얻을 수 있는 이득의 기댓값을 의미한다.
이렇게 나타난 최적 정책의 가치함수도 결국에는 어떠한 정책을 따르는 가치함수이기 때문에 벨만 방정식을 따라야 하며, 다음과 같이 최적 벨만 방정식(Bellan Optimality Equation)의 형태로 나타난다.
v∗(s)=a∈A(s)maxqπ∗(s,a)=amaxEπ∗[Gt∣St=s,At=a]=amaxEπ∗[Rt+1+γGt+1∣St=s,At=a]=amaxE[Rt+1+γv∗(St+1)∣St=s,At=a]=amaxs′,r∑p(s′,r∣s,a)[r+γv∗(s′)]
q∗(s,a)=E[Rt+1+γa′maxq∗(St+1,a′)∣St=s,At=a]=amaxs′,r∑p(s′,r∣s,a)[r+γa′maxq∗(s′,a′)]
이제까지 가치함수의 성질(일관성)과 최적 정책의 정의, 최적 정책을 따를 때의 가치함수의 성질(최적 벨만 방정식) 등을 학습하였다. 이제는 실제로 가치함수를 구하고, 그로 부터 최적 정책을 찾는 방법을 살펴보자.
우선 주어진 정책에 대해서 정확한 가치함수를 구하는 방법은 벨만 방정식 vπ(s)=∑aπ(a∣s)∑s′,rp(s′,r∣s,a)[r+γvπ(s′)]로 주어진다. 즉, 이러한 일관성을 바탕으로 모든 state에 대해서 연립 방정식을 세우고 미지수 vπ(s)를 구하는 것이다. State의 크기가 매우 클 경우 이렇게 세워진 연립 방정식을 바로 풀어내는 것은 어렵지만 다음과 같이 간단한 반복적인 계산을 통해 수치적으로 접근해 나갈 수 있다.
vk+1(s)=Eπ∗[Rt+1+γvk(St+1)∣St=s]=a∑π(a∣s)s′,r∑p(s′,r∣s,a)[r+γvk(s′)]
즉, (v0,v1,⋯,vk,⋯)과 같이 가치 함수를 벨만 방정식에 따라 계속 업데이트 해나가는 것으로 벨만 방정식을 잘 만족하지 않는 초기의 가치함수 제안 부터 이전 step의 가치 함수 결과를 토대로 벨만 방정식을 통해 다음 step의 가치함수를 업데이트해 나가는 작업을 반복하다보면, 결국 벨만 방정식을 정확히 만족하는 실제 가치함수에 근접하게 된다. 이러한 작업을 정책 평가(policy evalutation)이라고 하며, 주어진 정책에 대해서 정확한 가치 함수를 찾는 작업이다.
이렇게 어떤 정책에 대해서 정확한 가치 함수를 찾았으면, 이제 이를 이용하여 최적의 정책을 찾아야 한다. 이때 생각할 수 있는 방법은 정책 또한 점진적으로 발전시켜 나가는 것으로 어떤 state s에서 action a를 취하고, 이후로는 주어진 정책 π를 따를 때의 가치는 다음과 같이 계산할 수 있다.
qπ(s,a)=E[Rt+1+γvπ(St+1)∣St=s,At+1=a]=s′,r∑p(s′,r∣s,a)[r+γvk(s′)]
이때, 만약 state s에서 action a를 취하고, 이후로는 주어진 정책 π를 따르는 새로운 정책을 π′라고 했을 때, 위의 행동 가치 함수는 qπ(s,π′(s))와 같이 쓸 수 있다. 그런데 다음과 같이 새로운 정책에 대한 가치가 현재 정책을 따랐을 때의 가치보다 높다면, 새로운 정책이 더 좋은 정책이라고 할 수 있고, 이렇게 점진적으로 정책을 발전 시켜나가는 것으로 정책 향상(policy improvement)라고 한다.
qπ(s,π′(s))≥vπ(s)
정책 향상(policy improvement) 식은 다음과 같고, 즉 한 step 식 주어진 가치 함수에 대해서 가장 좋은 행동을 찾아 취하는 탐욕적인 정책 발전을 수행하는 것이다.
π′(s)=aargmaxqπ(s,a)=aargmaxE[Rt+1+γvπ(St+1)∣St=s,At+1=a]=aargmaxs′,r∑p(s′,r∣s,a)[r+γvk(s′)]
초기 정책(무작위 정책 등) π0가 주어졌을 때, 정책 평가을 통해 π0에 대한 가치함수 vπ0를 찾고, 이를 이용하여 정책 향상을 통해 약간 발전된 정책 π1를 찾는 일련의 과정을 π0,vπ0,π1,vπ1,π2,⋯와 같이 반복하면, 결국에는 더이상 정책 향상을 통해 정책이 변화하지 않는 상태에 도달할 것이고, 이를 최적 정책이라고 할 수 있다. 이러한 반복 작업을 정책 반복(policy iteration)이라고 한다.
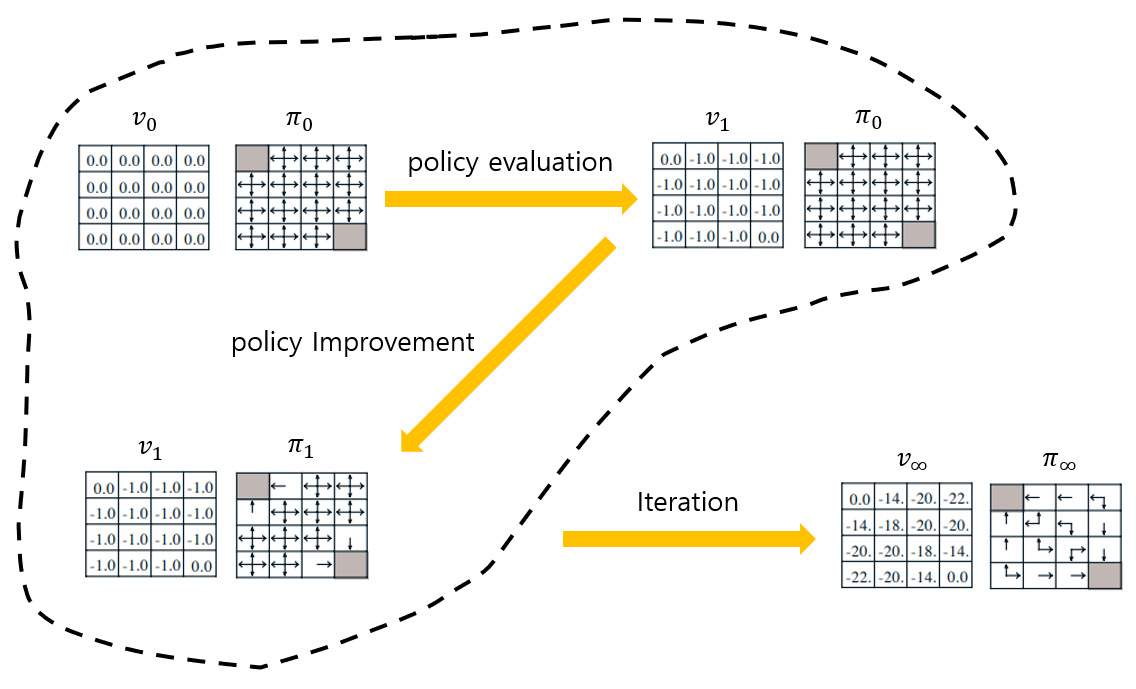
그림 4. 정책 반복 예시
다만 이러한 정책 반복 작업의 단점은 매 step마다 모든 state에 대해서 계산을 수행해야하는 정책 평가를 수행한다는 것이다. 정책 평가는 많은 계산량을 요구하며, 실제 구동 시에 문제가 될 수 있다. 하지만 이러한 정책 평가를 굳이 실제 가치 함수에 근접하도록 끝까지 수행할 필요는 없다. 왜냐하면 어느 정도 수렴이 된 상태라면 그로 부터 추출된 정책이 완전히 계산된 가치 함수에서 추출된 정책과 크게 다르지 않기 때문인데(가치함수의 값이 틀리더라도 상대적인 고저만 맞으면), 가치 반복(value iteration)은 이러한 아이디어에서 도출된다.
vk+1(s)=amaxE[Rt+1+γvπ(St+1)∣St=s,At+1=a]=amaxs′,r∑p(s′,r∣s,a)[r+γvk(s′)]
즉, 가치 반복에서는 다음 가치 함수의 업데이트를 현재의 가치 함수에서 탐욕적으로 선택된 action을 따라 진행하며, 이렇게 업데이트를 할 경우 추가적인 정책 향상 과정 없이 가치 함수에서 π(s)=argmaxa∑s′,rp(s′,r∣s,a)[r+γvk(s′)]처럼 정책을 추출 할 수 있다.
3. 몬테카를로 방법
앞에서는 DP를 이용한 점근적인 방법으로 정책반복 및 가치반복 문제를 해결하였다. 하지만 이렇게 DP를 사용할 경우 환경에서 주어지는 전이 확률 등의 모델을 모두 알고 있어야하는 단점이 있다. 이러한 문제를 해결하기 위하여 몬테카를로(Monte Carlo, MC)방법에서는 agent의 경험만을 이용하여 여러 표본을 모아 이러한 문제를 해결한다.
몬테카를로 방법은 정책(가치)반복 과정 중 위에서 DP를 사용해서 해결했던 정책 평가 과정을 대체할 수 있다. 기본적인 알고리즘은 현재의 정책 π를 따라서 여러 번의 에피소드를 진행하고 각 이득을 계산하여 에피소드 별 이득의 평균을 구한다. 이러한 과정은 에피소드의 횟수가 증가할수록 점점 더 정확한 가치를 추정하게 된다. 이때 몬테카를로 방법은 환경의 모델 등을 모른다는 가정이 들어가기 때문에 상태가치함수, vπ(s)보다는 행동가치함수, qπ(s,a)를 구하는 것이 유용하다. 왜냐하면 이후 가치함수를 이용하여 정책 선택할 때 유용하기 때문인데, 모델을 모를 경우 상태가치함수만을 가지고 어떤 action을 취했을 때 가장 높은 가치를 찾아갈 수 있는 지 알아내기가 모호하다. 이렇게 주어진 정책에 대한 가치를 추정하면 DP 방법에서와 비슷하게 탐욕적인 정책 선택을 통해 정책을 향상시킨다.
이때 크게 2가지의 문제가 존재한다. 먼저 몬테카를로 방법은 수많은 데이터를 취득하고 샘플링하여 참값을 근사하는 방법으로 어느정도 많은 횟수의 에피소드를 요구한다. 이는 DP 방법에서도 나타나는 문제인데 즉 가치함수의 수렴까지 꽤 많은 연산을 수행해야한다는 점이다. 이러한 문제의 간단한 해결방법은 어느 정도 수준으로만 수렴하면 정책 평가를 끝내버리는 것으로 이것의 극단적인 예시가 위의 가치반복 방법이다.
또다른 문제는 몬테카를로 방법에서 데이터를 수집할 때, 많은 상태-행동 쌍에 대한 접촉이 발생하지 않을 수 있다는 것이다. 예를 들어 grid world에서 초기 정책이 무조건 오른쪽만 가는 정책이라고 할 때, 우리가 수집할 수 있는 데이터는 (s, 오른쪽)이라는 데이터 뿐이다. 하지만 정확한 가치함수 계산을 위해서는 상하좌우 모두 움직여 보아서 데이터를 수집해야하고, 이를 통해 정책 발전이 이루어질 수 있다.
이러한 문제를 해결하는 가장 간단한 방법은 시작 탐험 방법이다. 시작 탐험 방법은 모든 상태-행동 쌍이 에피소드 시작시에 선택될 확률로 0 이상을 갖는 방법이며, 이를 통해 에피소드 수가 늘어날수록 결국 모든 상태-행동 쌍에 접촉하게 된다. 하지만 이렇게 시작 상태가 무작위한 환경은 많지 않으며, 실제 환경에서는 더더욱 적용되기 힘든 방법이다.
또다른 방법으로는 입실론 탐욕적 정책을 활용하는 것이다. 해당 방법은 agent가 정책 π를 따라 움직일 때, 대부분의 시간 동안 주어진 정책에 대해 최대의 행동 가치 추정값을 갖는 행동을 취하지만, 아주 작은 확률 입실론(ϵ)의 확률로 무작위 행동을 하는 것이다. 일반적으로 입실론 소프트 정책은 모든 s∈S와 모든 a∈A(s)에 대해서 π(a∣s)를 만족하는 것으로 입실론 탐욕적 정책은 입실론 소프르 정책의 일부로써 모든 비탐욕적 행동은 작은 확률 ∣A(s)∣ϵ를 갖고, 나머지 대부분의 확률 1−ϵ+∣A(s)∣ϵ만큼이 탐욕적 행동에 부여된다.
이러한 입실론 탐욕적 정책 π′이 모든 입실론 소프트 정책 π보다 향상된 것임은 다음과 같은 정책 향상 정리로 보장된다.
qπ(s,π′(s))=a∑π′(a∣s)qπ(s,a)=∣A(s)∣ϵa∑qπ(s,a)+(1−ϵ)amaxqπ(s,a)⋯(1)≥∣A(s)∣ϵa∑qπ(s,a)+(1−ϵ)a∑1−ϵπ(a∣s)−∣A(s)∣ϵqπ(s,a)⋯(2)=∣A(s)∣ϵa∑qπ(s,a)−∣A(s)∣ϵa∑qπ(s,a)+a∑π(a∣s)qπ(s,a)=vπ(s)
이때, equation 2의 마지막 항에서는 가중치 합이 1이되는 가중합을 취한 것으로 최대 가치를 내는 행동을 찾아간 것보다는 무조건 작거나 같다. 따라서 정책 향상 정리에 따라 π′≥π이며, 이제 π′,π가 둘 다 입실론 소프트 정책 줓 최적일 때만 등호가 성립함을 보일 것이다. v~∗,q~∗가 새로운 환경에 대한 최적 가치 함수를 나타낸다고 하자. 그 정의에서 다음과 같다.
v~∗(s)=(1−ϵ)amaxq~∗(s,a)+∣A(s)∣ϵa∑q~∗(s,a)=(1−ϵ)amaxs′,r∑p(s′,r∣s,a)[r+γv~∗(s′)]+∣A(s)∣ϵa∑s′,r∑p(s′,r∣s,a)[r+γv~∗(s′)]
그리고 등식이 성립하여 입실론 소프트 정책 π가 향상되지 않을 경우 equation 1에서 다음과 같다.
vπ(s)=(1−ϵ)amaxqπ(s,a)+∣A(s)∣ϵa∑qπ(s,a)=(1−ϵ)amaxs′,r∑p(s′,r∣s,a)[r+γvπ(s′)]+∣A(s)∣ϵa∑s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
이 방정식은 v~∗ 대신 vπ(s)을 제외하면 똑같으며, 해당 방정식에서 v~∗가 유일한 해이므로, v~∗=vπ(s)가 되어야 한다.
강화학습에서는 최적 행동을 찾기 위해서 해당 정책에 대한 가치를 구해야 하지만 정확한 가치를 구하기 위해서는 최적 행동이 아닌 여러 가지 행동을 해보며 데이터를 수집해야 한다. 약간 모순처럼 들릴 수 있는 이러한 문제를 앞에서는 입실론 정책 등의 탐험 방법을 적용하고, 점진적으로 정책을 발전시켜 나가는 것으로 해결하였다. 이렇게 하나의 정책을 사용하여 데이터를 수집하고, 이로부터 해당 정책을 점차 발전시켜 나가는 방식을 활성 정책 학습(on-policy learning)이라고 한다.
하지만 탐험을 위한 행동 정책, 최적 행동을 찾기위해 점점 학습시켜 나가는 목표 정책, 2가지로 구분하여 사용하는 방법 또한 생각해 볼 수 있다. 이러한 학습 방식을 비활성 정책 학습(off-policy learning)이라고 하며, 비활성 정책 학습은 일반적으로 분산이 더 크고 수렴 속도가 느리지만 더 다양한 환경에 적용할 수 있고, 전문가 데이터 활용 등 활용도에 있어 자유도가 높은 장점이 있다.
여기서는 목표 정책을 π, 행동 정책을 b라고 표기하며, 목표는 정책 b를 통해 생성된 데이터들을 사용하여 정책 π의 가치를 추론하는 것이다. 이를 위해서는 정책 π하에서 취해지는 모든 행동이 b를 통해서 적어도 출현은 해야하며, 결정론적인 π를 사용하더라도 분리된 행동 정책 b는 확률적으로 설정할 수 있어 이러한 문제가 해결된다. 행동 정책 b 를 통해 얻은 이득의 기댓값 Eb[Gt∣St=s]=vb(s)는 분명 vπ(s)와는 다르다. 따라서 중요도추출비율(ρ)을 도입하여 기대값을 구할 때 적절한 가중합을 사용하게 된다. 중요도추출비율은 다음과 같이 상태-행동 궤적의 상대적인 확률로 정의할 수 있다.
Pr{At,St+1,At+1,⋯,ST∣St,At:T−1∼π}=π(At∣St)p(St+1∣St,At)π(At+1∣St+1)⋯p(ST∣ST−1,AT−1)=k=t∏T−1π(Ak∣Sk)p(Sk−1∣Sk,Ak)
ρt:T−1=∏k=tT−1b(Ak∣Sk)p(Sk−1∣Sk,Ak)∏k=tT−1π(Ak∣Sk)p(Sk−1∣Sk,Ak)=k=t∏T−1b(Ak∣Sk)π(Ak∣Sk)
즉 중요도추출비율(ρ)은 두 정책에서 행동이 선택될 확률의 비율로 결정된다. 이러한 중요도추출비율을 적용하면 다음과 같이 π에 대한 가치를 구할 수 있다.
E[ρt:T−1Gt∣St=s]=vπ(s)
이를 이용하면 다음과 같이 여러 에피소드에 대한 평균을 내는 몬테카를로 알고리즘을 통해 정확한 가치함수를 근사할 수 있다. 크게 2가지 방법이 있는데 하나는 단순히 에피소드에 대한 평균을 내는 기본 중요도추출법이고, 나머지 하나는 가중치를 두어 평균을 내는 가중치 중요도추출법이다(이때 J(s),는 s와 마주치는 모든 시간 단계를 의미).
V(s)=∣J(s)∣∑t∈J(s)ρt:T(t)−1Gt
V(s)=∑t∈J(s)ρt:T(t)−1∑t∈J(s)ρt:T(t)−1Gt

그림 5. 비활성 정책, 가중치 중요도추출법일때 정책 평가 구현

그림 6. 비활성 정책, 가중치 중요도추출법일때 MC 제어
