Elasticsearch 3. Searching
Introduction to Searching
Search Method
- search쿼리에는 두가지 방법있다.
query DSL
- body에 search query를 쓰는 것. 이건 query DSL이라는 걸 통해 이뤄진다.
- 여태 해온 방식이고 제일 많이 쓰인다.

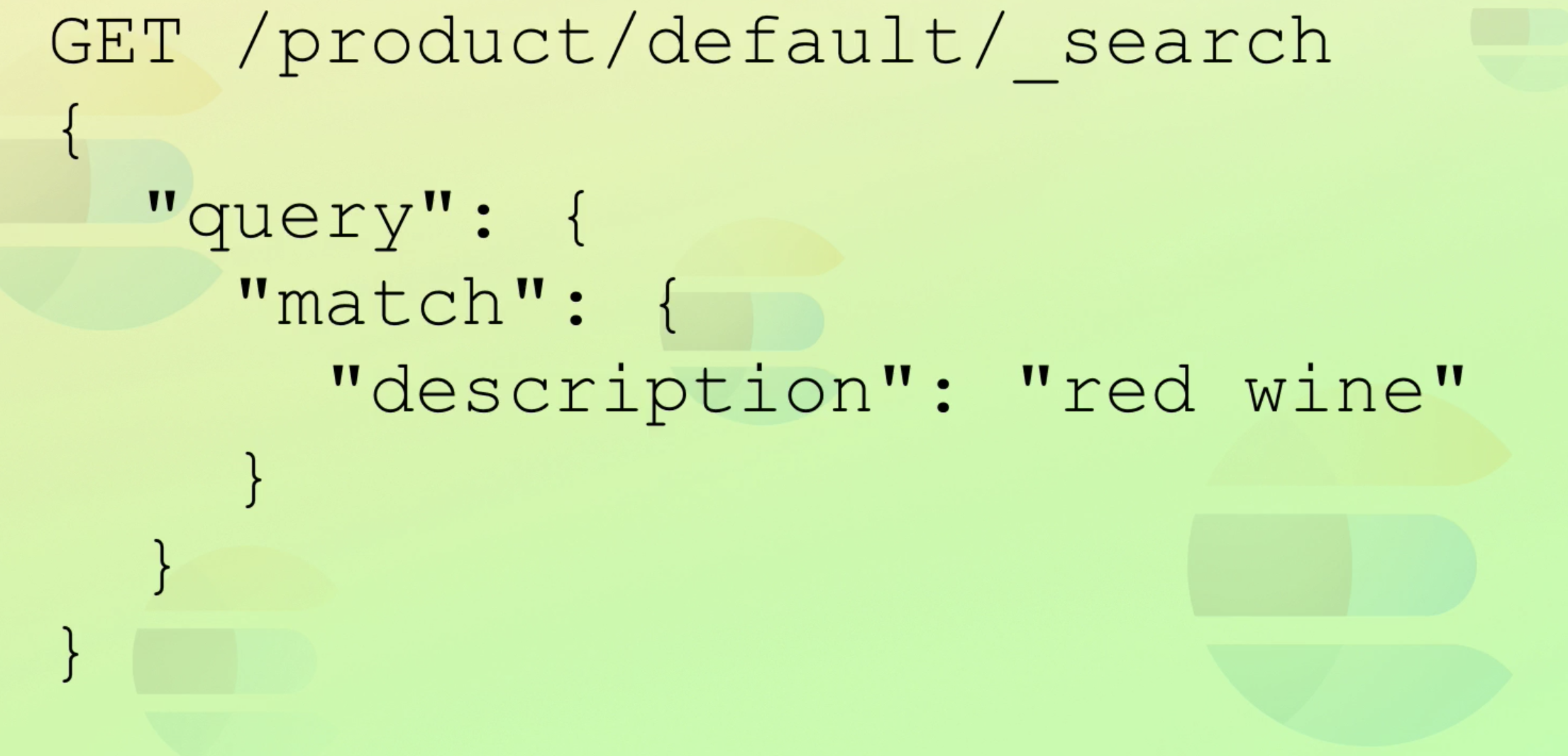
request URI(query string)
GET /product/_search?q=name:past요런 식으로도 search가능하다.- 참고로 query DSL도 query param 사용 가능.
- 간단하게 테스트 하는 용으로 쓰면 좋다. 제대로 할 땐 DSL사용하자.
GET /product/_search
{
"query": {
"query_string": {
"query": "name:pasta"
}
}
}Searching with the request URI
GET /products/_search?q=*- pagenation이 있기 때문에 모든 데이터가 한 번에 리턴되진 않는다.(페이지네이션 나중에 다룸)
name에 Lobster라는 단어가 들어간 doc을 찾기.
GET /products/_search?q=name:Lobster
- response데이터는 revelance score순으로 정렬된다. 맨 위 doc이 제일 연관도 높음.
tags에 Meat이 포함되있고, name에 tuna가 포함되있는 doc 찾기
GET /products/_search?q=tags:Meat AND name:Tuna
- curl에서 request보내려면 뭔가를 %20? encode? 여튼 뭔가를 더 해야한다고 하는데 이해를 잘 못했다.
Introducing the QUERY DSL
-
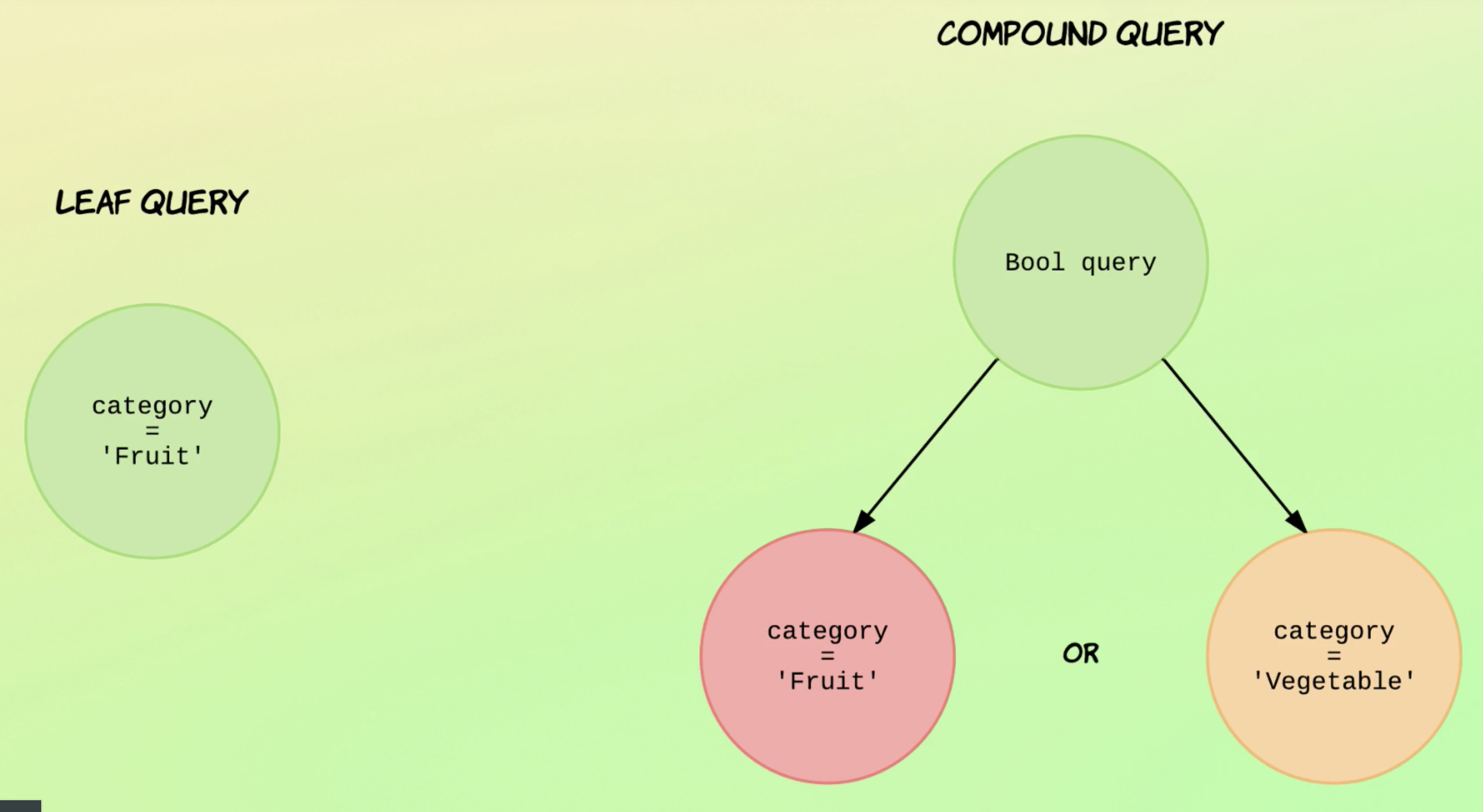
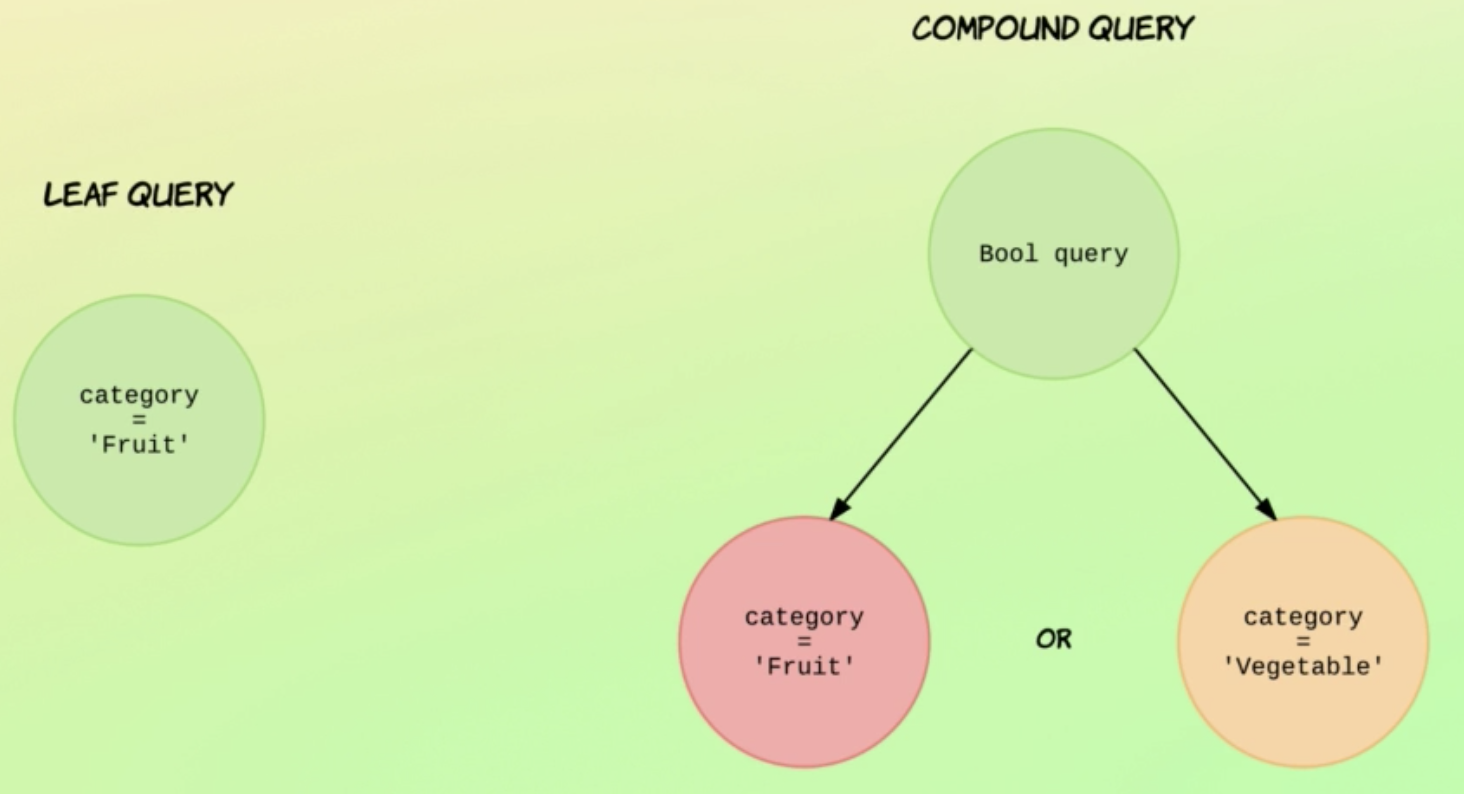
leaf query, compound query 두 종류가 있다.(용어 자체는 중요치 않다)
-
leaf query는 특정 필드의 값을 search한다.
-
compound query는 여러개의 leaf query로 이뤄져있다. (recursive하다는데 아직은 이해 안감)
-
아래 예시를 보면 leaf 쿼리는 category가 Fruit인 doc을 찾는다.
-
compound query는 bool query를 날리고 있는데, category=Fruit이거나 Vegetable인 doc을 찾는다.
-
key로 쿼리의 이름(match_all)을, value로 쿼리문을 날리는게 일반적이다.
GET /reviews/_search
{
"query": {
"match_all": {}
}
}Searching for data
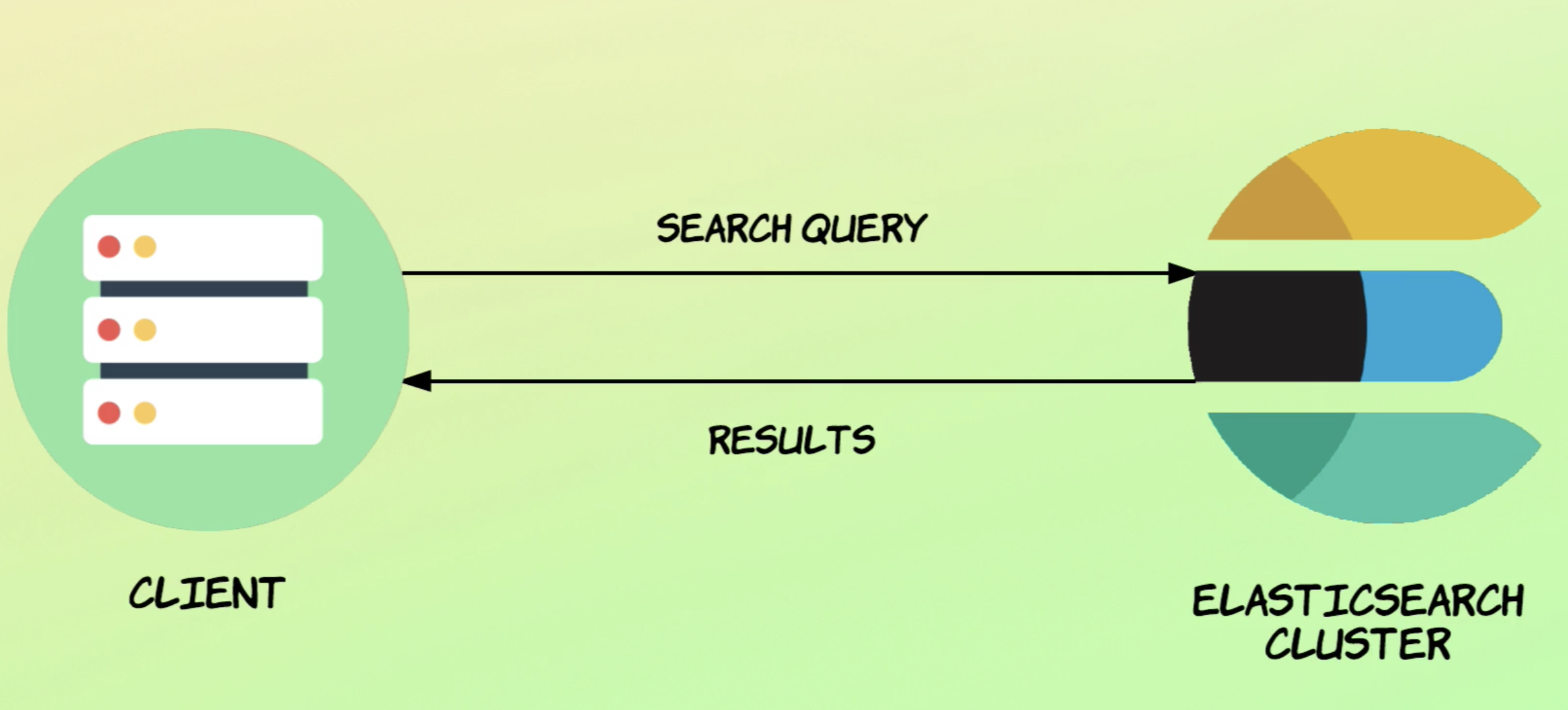
- 좀 더 심화
- 노드 3개. 인덱스 1개. 샤드 3개. replica 2개.
과정
- coordinating node가 request를 받고 다른 노드에 뿌려준다.
- 다른 노드가 보낸 정보를 취합해 result를 만들어 response를 보낸다.

- 만약 id를 통해 request가 왔다면 coordinate 노드가 모든 노드로 broadcast하지 않고, 해당 아이디가 있는 노드로 직행한다.
Understanding query results
took
query 수행 속도. (밀리세컨)
hits.total.value
매칭된 doc 개수
hits.hits._score
- relevance 점수. max_score를 넘을 수 없다.
Understanding relevance scores
- relevance score 계산에 대해 알아보자(알고리즘 커스텀 할 수도 있음)
- 나중에 다시 듣기.
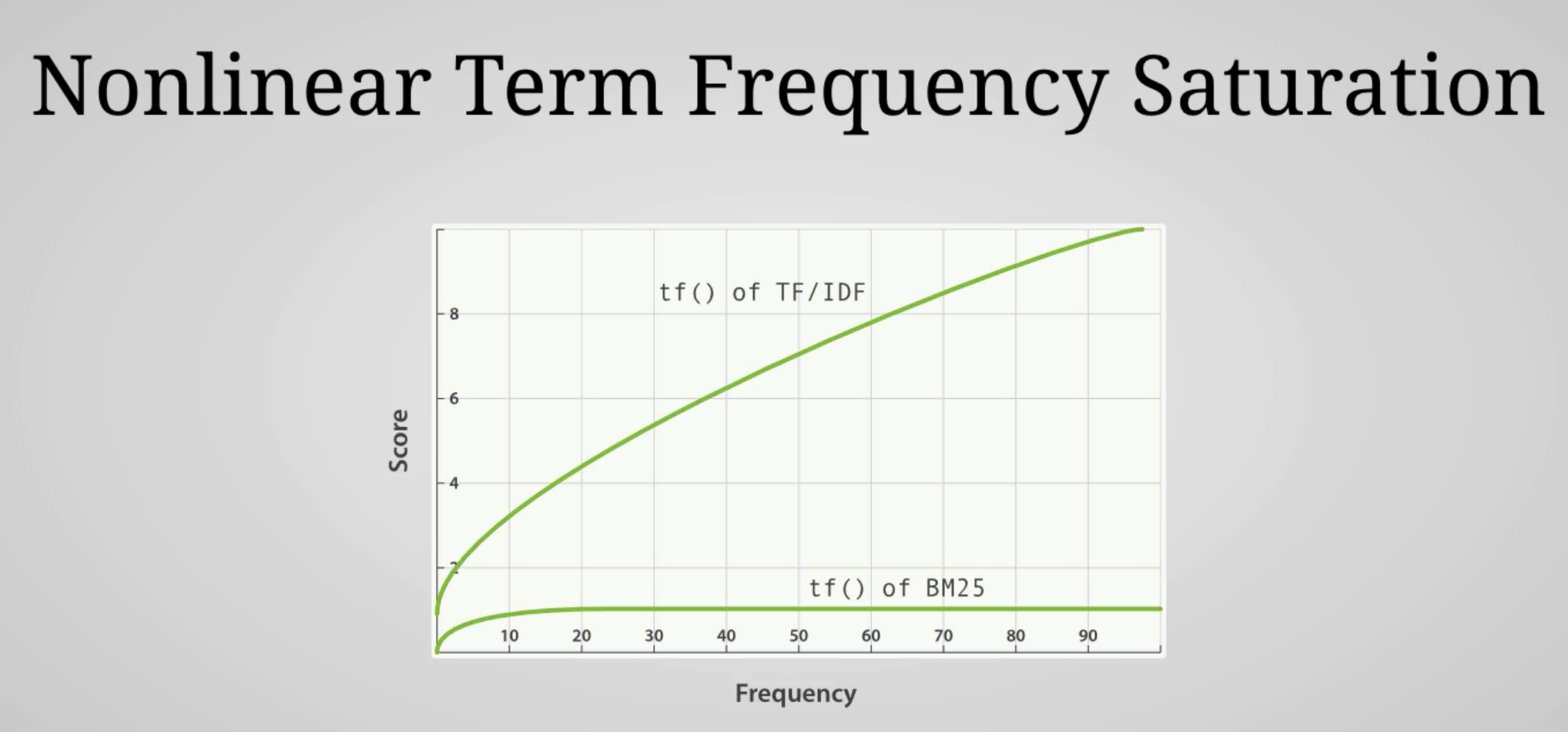
TF/IDF
- Term Frequency / Inverse Document Frequency
- 예전에 쓰이던 알고리즘
- Term Frequency
- How many times does the term appear in the field for a given document?
- Inverse Document Frequency
- How often does the term appear withn the index(i.e. across all documents)?
- 더 많이 있을수록 스코어 낮아짐
- Field-length norm
- How long is the field
- 길이가 1000인 문장에서 일치하는 것보다 길이가 10일 때 일치하는 게 더 고득점
Okapi BM25
- The relevance scoring algorithm currently used by ES
- TF/IDF와 많은 공통점
- Better at handling stop words
- Improves the field-length norm factor
- Can be configured with parameters
Debugging unexpected search results
Query contexts
- query는 두가지 컨텍스트 중 하나 안에서 실행될 수 있다. QUERY CONTEXT vs FILTER CONTEXT
query context
- how well do documents match the query?
- relevance score도 계산됨.
filter context
- Do documents match?
- No relevance socres are calculated.
- commonly used for filtering data such as dates or status or ranges etc.
결론
- relevance score가 필요하면 query context를, 아니면 filter context를 써라.
- relevance score계산하는 것도 연산이기 때문에, 필요 없다면 안쓰는게 좋다.
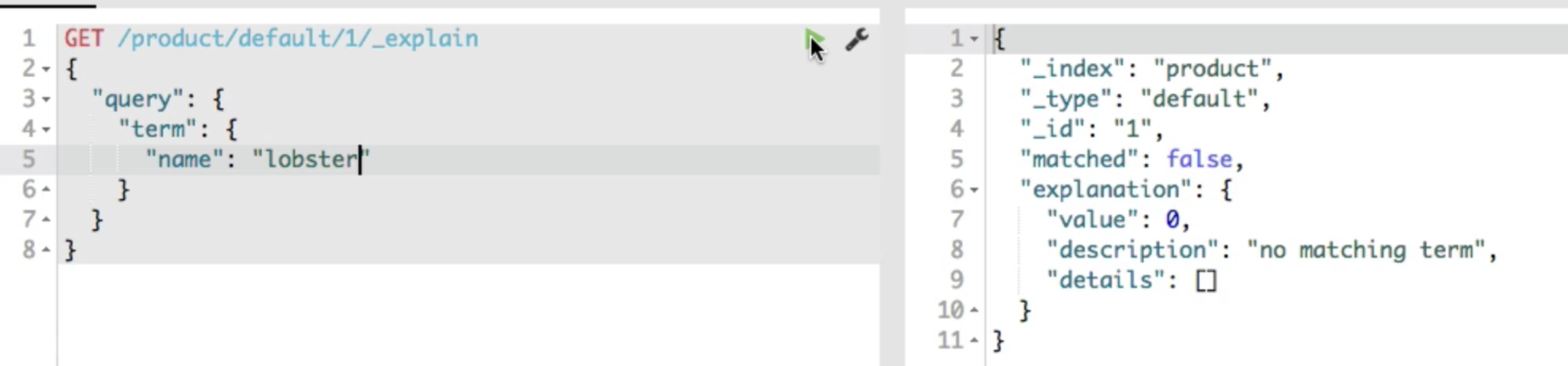
Full text queries vs term level queries
- full text query는 inverted index에 쓰였던 analyzer을 거치지만, term query는 거치지 않는다.
- lobster라는 단어가 들어간 필드를 조회한다 치자. full text query를 사용하면 lobster로 조회하는 것과 Lobster로 조회하는 것 모두 lowercase를 만들어주는 analyzer(디폴트)를 거쳐 같은 결과를 낸다.
하지만 term level query는 analyzer를 거치지 않기 때문에 lobster검색과 Lobster검색이 달라진다. - term level queries search for exact matches.
- full text queries are analyzed with the same analyzer as was used for inverted index
- this is why term level queries are not suited for performing full text search.
- term level queries are better suited for matching enum values, number, dates, etc, not sentences.
Term Level queries
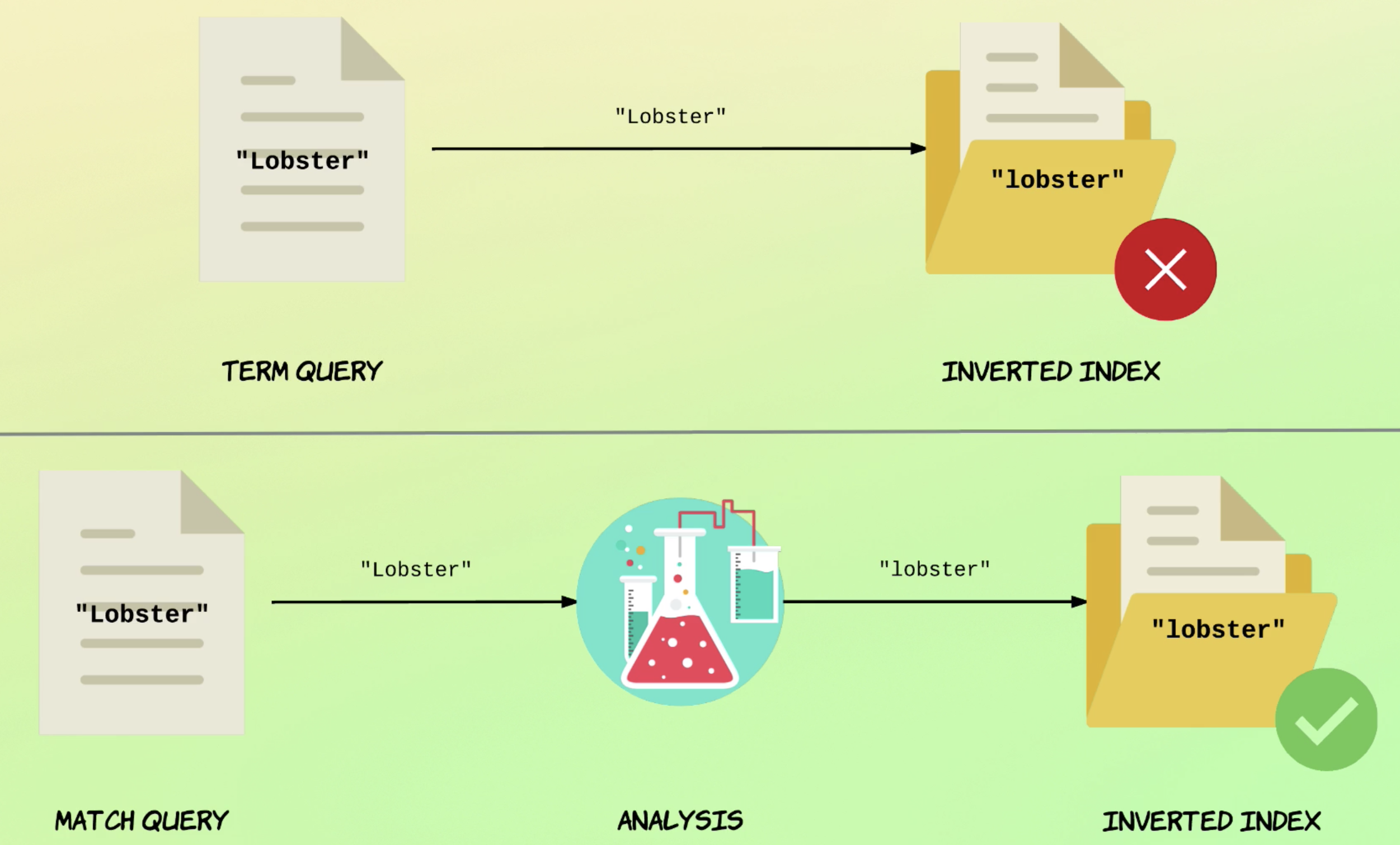
intro
- exact macthing을 할 때 주로 쓰인다.
- analyzer를 거치지 않는다. 때문에 full-text matching에는 부적절하다.
- 사용예시는 is_active값이 true인 doc을 찾는 것이다. true값은 analyzer를 거치지 않아도 되기 때문에 사용이 적절하다.
- 반면 field에 apple이 들어있는 데이터를 찾는건 부적절하다. 대,소문자 여부 등을 따져야 하기 때문.
searching for a term
- term query를 활용해 is_active field가 true인 doc을 찾아보자.
- 방법 1
GET /products/_search
{"query": {
"term": {
"is_active": true
}
}}- 방법 2
GET /products/_search
{"query": {
"term": {
"is_active": {
"value": true
}
}
}}searching for multiple terms
- array형태. 어레이 값 중 하나라도 일치하는 doc이 반환된다.
- term query기 때문에 keyword로 exact matching을 하는 예시를 보자.
GET /products/_search
{
"query": {
"terms": {
"tags.keyword": [ "Soup", "Cake" ]
}
}
}Retrieving documents based on IDs
GET /products/_search
{
"query": {
"ids": {
"values": [ 1, 2, 3 ]
}
}
}Matching documents with range values
Matching documents with an in_stock field of between 1 and 5, both included
GET /products/_search
{
"query": {
"range": {
"in_stock": {
"gte": 1,
"lte": 5
}
}
}
}Matching documents with a date range
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "2010/01/01",
"lte": "2010/12/31"
}
}
}
}Matching documents with a date range and custom date format
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "01-01-2010",
"lte": "31-12-2010",
"format": "dd-MM-yyyy"
}
}
}
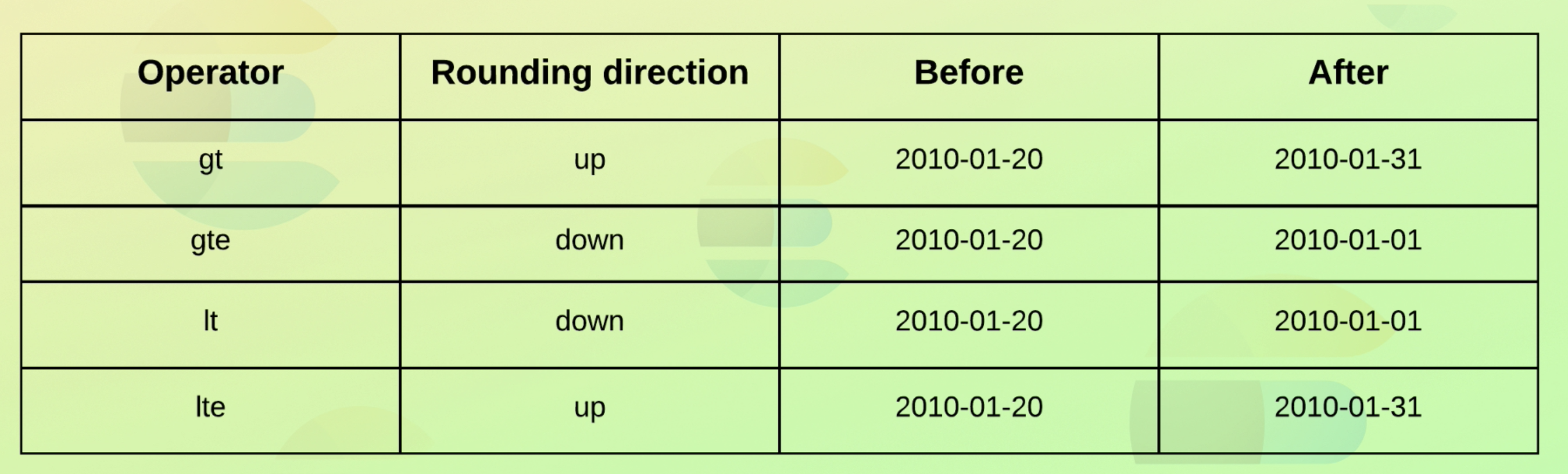
}Working with relative dates(date math)
- 참고자료
- https://www.elastic.co/guide/en/elasticsearch/reference/current/common-options.html#date-math
- m은 minute, M은 month
Subtracting one year from 2010/01/01
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "2010/01/01||-1y"
}
}
}
}
Subtracting one year and one day from 2010/01/01
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "2010/01/01||-1y-1d"
}
}
}
}
Subtracting one year from 2010/01/01 and rounding by month
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "2010/01/01||-1y/M"
}
}
}
}
Rounding by month before subtracting one year from 2010/01/01
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "2010/01/01||/M-1y"
}
}
}
}
Rounding by month before subtracting one year from the current date
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "now/M-1y"
}
}
}
}
Matching documents with a created field containing the current date or later
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "now"
}
}
}
}
matching documents with non-null values
- tags 필드가 null이 아닌 doc을 가져오는 쿼리.
GET /products/_search
{
"query": {
"exists": {
"field": "tags"
}
}
}Matching based on prefixes
GET /products/_search
{
"query": {
"prefix": {
"tags.keyword": "Vege"
}
}Searching with wildcards
Adding an asterisk for any characters (zero or more)
- aesterisk matches in the character sequence, including no characters.
- question mark matches any single character
- wildcard(*, \?) query는 속도가 느리다.
- 특히 맨 앞에 wildcard쓰면 엄청 느리다.
GET /products/_search
{
"query": {
"wildcard": {
"tags.keyword": "Veg*ble"
}
}
}Adding a question mark for any single character
GET /products/_search
{
"query": {
"wildcard": {
"tags.keyword": "Veg?ble"
}
}
}GET /products/_search
{
"query": {
"wildcard": {
"tags.keyword": "Veget?ble"
}
}
}Searching with regular expressions
- 맨 앞에 wildcard쓰면 성능에 치명적이다.
- ES는 lucene의 regular expression을 쓰기 때문에, 일반적인 regex중 안먹히는 것들도 있다.
잘 찾아보고 쓸것.
GET /products/_search
{
"query": {
"regexp": {
"tags.keyword": "Veg[a-zA-Z]+ble"
}
}
}full text queries
- 참고: ES엔 array 데이터 타입이 없다. 왜냐면 field may have more than one value by default.
Flexible matching with the match query
- 구글검색처럼 유저가 입력하는 데이터를 search할 때 적합하다.
Standard match query
GET /recipe/_search
{
"query": {
"match": {
"title": "Recipes with pasta or spaghetti"
}
}
}Specifying a boolean operator
모든 단어가 들어간 결과만 리턴된다.
GET /recipe/_search
{
"query": {
"match": {
"title": {
"query": "Recipes with pasta or spaghetti",
"operator": "and"
}
}
}
}GET /recipe/_search
{
"query": {
"match": {
"title": {
"query": "pasta or spaghetti",
"operator": "and"
}
}
}
}GET /recipe/_search
{
"query": {
"match": {
"title": {
"query": "pasta spaghetti",
"operator": "and"
}
}
}
}Matching phrases
- 단어 순서 그대로 검색할 때 match_phrase를 쓰면 된다.
- 예를 들어 match로 "hi man" 검색하면 단순히 "hi"라는 단어와 "man"이라는 단어가 들어가기만 하면 검색에 걸리지만, match_phrase는 "hi man"이라는 순서가 지켜질 때만 검색에 걸린다. "man hi"는 검색에 안걸림.
The order of terms matters
GET /recipe/_search
{
"query": {
"match_phrase": {
"title": "spaghetti puttanesca"
}
}
}GET /recipe/_search
{
"query": {
"match_phrase": {
"title": "puttanesca spaghetti"
}
}
}Searching multiple fields
- title, description필드 중 pasta단어를 가진 doc 조회 쿼리.
- 참고로 relevance score는 필드들 중 highest score를 가진 필드값으로 계산된다.
- 예를 들어 title필드에는 pasta가 2번 나오고, description에는 1번 나오면 title필드로 relevance score가 계산된다.
GET /recipe/_search
{
"query": {
"multi_match": {
"query": "pasta",
"fields": ["title", "description"]
}Adding boolean logic to queries
intro
- boolean쿼리를 위해 compound쿼리를 사용할 것이다.
querying with boolean logic
- Bool query는 쿼리문에 boolean logic을 추가하기 위해 쓰인다.
- sql의 where clause와 비슷하다.
- 하지만 bool query가 sql where보다 advanced하다. relevance score까지 다루기 때문.
query context, filter context
- bool query를 다루기 전에 이전에 배웠던 context에 대해 복습해보자. 쿼리는 query context 혹은 filter context안에서 이뤄진다.
- 두 context의 차이를 이해하는 것이 Bool query를 이해하는데 중요하다.
- query context
- relevance score가 계산된다.
- result docs는 이 score에 따라 정렬된다.
- filter context
- 단순히 쿼리에 matching되는 docs를 찾는다.
- only determined whether or not a document matches a query and not how well it matches a query
- bool query는 query, filter context 둘 다 가능하다. 우선 query context에서 먼저 해보자.
First query
- must안에 있는 내용은 꼭 일치해야 쿼리결과에 걸린다.
-relevance score도 계산된다.
GET /recipe/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"ingredients.name": "parmesan"
}
},
{
"range": {
"preparation_time_minutes": {
"lte": 15
}
}
}
]
}
}
}second query
- 위 쿼리를 개선해보자.
- range쿼리에서 relevance score를 계산하는게 어색하다. 15분 이하 조건 충족하는지 yes or no만 필요하지, 점수가 있을 수는 없다.
- range부분을 filter context로 옮기다.
- filter object는 relevance score를 계산하지 않기에 성능적으로 우수하다.
- caching is where filter queries have an dege bacause the query clauses can be cached for subsequent queries.
GET /recipe/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"ingredients.name": "parmesan"
}
}
],
"filter": [
{
"range": {
"preparation_time_minutes": {
"lte": 15
}
}
}
]
}
}
}third query
- ingredient에 tuna가 들어간건 제외해보자. (must_not)
- must_not은 filter context에서 실행된다.
- score is ignored, and the score of zero is return for all docs.
- caching 으로 considered 된다.
- ES에서 항상 cache된다는 보장이 없다.
- There's no guarantee that a query will be cached, although chance are that it will
GET /recipe/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"ingredients.name": "parmesan"
}
}
],
"must_not": [
{
"match": {
"ingredients.name": "tuna"
}
}
],
"filter": [
{
"range": {
"preparation_time_minutes": {
"lte": 15
}
}
}
]
}
}
}forth query
- 파슬리가 들어간 recipe의 점수를 높게 줘보자.
- should를 사용한다.
- should는 점수를 높혀준다.
- 하지만 should값이 match되지 않아도 결과에는 걸린다. 단지 일치하는 doc의 score만 높혀줄 뿐.
if the bool query is in a query context and contains must or filter objects, then the should query do not need to match for a doc to measure bool query as a whole. 이경우, should query의 유일한 목적은 relevance score에 영향을 주는 것이다.
On the other hand, if the bool query is in the filter context or if it doesn't have a must or filter object, then at least one of the should queries must match that because the should queries are intended for boosting documents matching a set of queries.
But the documents should still satisfy some constraints.
Otherwise, every single document in an index would be matched.
GET /recipe/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"ingredients.name": "parmesan"
}
}
],
"must_not": [
{
"match": {
"ingredients.name": "tuna"
}
}
],
"should": [
{
"match": {
"ingredients.name": "parsley"
}
}
],
"filter": [
{
"range": {
"preparation_time_minutes": {
"lte": 15
}
}
}
]
}
}
}fifth query
- pasta가 ingredient에 있는게 우선순위고, option으로 parmesasn이 있는걸 찾아보자.
- must query와 should쿼리를 각각 사용.
- pasta가 꼭 들어가야 하고, parmesan이 들어가면 가산점을 준다.
GET /recipe/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"ingredients.name": "pasta"
}
}
],
"should": [
{
"match": {
"ingredients.name": "parmesan"
}
}
]
}
}
}sixth query
- should만 있는 쿼리
- parmesan이 옵션이 아니라 필수값이 된다.
GET /recipe/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"ingredients.name": "parmesan"
}
}
]
}
}
}Debugging bool queries with named queries
- explain api는 디버깅에 좋다. query 성공, 실패 이유를 알려줌.
- 비슷한 작업을 bool query에서도 할 수 있다.
GET /recipe/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"ingredients.name": {
"query": "parmesan",
"_name": "parmesan_must"
}
}
}
],
"must_not": [
{
"match": {
"ingredients.name": {
"query": "tuna",
"_name": "tuna_must_not"
}
}
}
],
"should": [
{
"match": {
"ingredients.name": {
"query": "parsley",
"_name": "parsley_should"
}
}
}
],
"filter": [
{
"range": {
"preparation_time_minutes": {
"lte": 15,
"_name": "prep_time_filter"
}
}
}
]
}
}
}- 결과값의 일부를 가져왔다. 총 2개가 걸렸는데, 결과중 위에 검색된(relevance score가 높은)doc은 보다시피 세개의 조건이 다 일치힌다. 특히 sholud까지 걸렸기 때문에 점수가 높다.
- 반면 아래 결과는 필수조건만 걸렸고, should는 없기에 점수가 낮다.
- 이렇게 디버깅 가능.
"matched_queries" : [
"prep_time_filter",
"parmesan_must",
"parsley_should"
] "matched_queries" : [
"prep_time_filter",
"parmesan_must"
]How the "match" query works
- 나중에 다시 듣기
