ElasticSearch 2
Mapping & Analysis
Introduction to analysis
- text values are analyzed when indexing documents
- The result is stored in data structures that are efficient for searching
- _source데이터는 doc search할 때 내부적으로 사용되지 않는다.
- text는 저장되기 전 가공과정을 거친다.
Analyzer
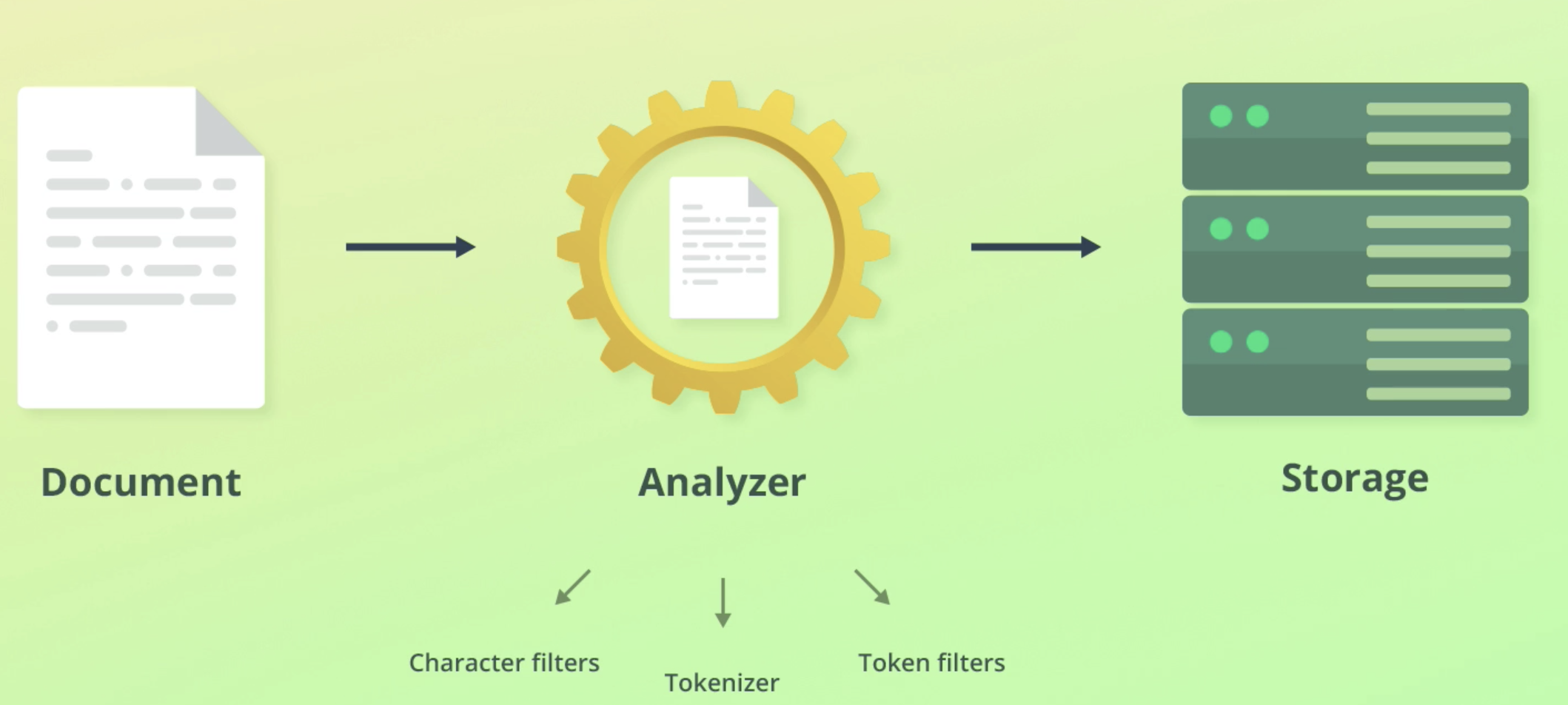
- Analyzer는 3가지 블록으로 구성된다: Character filters, Tokenizer, Token filters
- analyzer를 거친 결과값은 검색 가능한 자료구조 형태로 저장된다.
Character filters
- adds, removes, or changes characters
- Analyzers contain zero or more character filters
- Character filters are applied in the order in which they are specified

Tokenizers

Token filters

Built-in and custom components
- Character filters, Tokenizers, Token filters는 디폴트를 사용하거나, custom할수도 있다.
- Character filters
- 디폴트는 none이다. 아무일도 안일어난다.
- Tokenizer
- 단어 split. punctuation전부 삭제한다. (',' '.' '-', ' '등등)
- Token filters
- 디폴트로 lowercase작업을 한다.

- 디폴트로 lowercase작업을 한다.
Analyze API
- 아래는 analyze api 호출문이다. 아래 case 3개는 모두 동일한 쿼리문이다. (디폴트)
POST /_analyze
{
"text": "2 guys walk into a bar, but the third... DUCKS! :-)",
"analyzer": "standard"
}- case 2
POST /_analyze
{
"text": "2 guys walk into a bar, but the third... DUCKS! :-)"
}- case 3
POST /_analyze
{
"text": "2 guys walk into a bar, but the third... DUCKS! :-)",
"char_filter": [],
"tokenizer": "standard",
"filter": ["lowercase"]
}- response
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.13/security-minimal-setup.html to enable security.
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "guys",
"start_offset" : 2,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "walk",
"start_offset" : 7,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "into",
"start_offset" : 12,
"end_offset" : 16,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "a",
"start_offset" : 19,
"end_offset" : 20,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "bar",
"start_offset" : 21,
"end_offset" : 24,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "but",
"start_offset" : 26,
"end_offset" : 29,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "the",
"start_offset" : 30,
"end_offset" : 33,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "third",
"start_offset" : 34,
"end_offset" : 39,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "ducks",
"start_offset" : 43,
"end_offset" : 48,
"type" : "<ALPHANUM>",
"position" : 9
}
]
}
Inverted indices
- A field's values are stored in one of several data structures
- 필드의 데이터 타입에 따라 달라진다.
- 데이터에 효율적으로 접근하기 위함
- 이 과정은 ES가 아닌 Apache Lucene에 의해 동작된다.
Inverted indices
- Mapping between terms and which documents contain them
- token과 term은 같은 뜻이다. token은 analyzer맥락에서만 쓰이고, 나머지 상황에선 term이라 부른다.
- 아래 예시를 살펴보자.
- 알파뱃순으로 정렬
- ducks라는 단어를 찾으려면 이 인덱스 테이블만 보고 어느 doc에 있는지 쉽게 찾을 수 있다.
- 원래는 doc에서 term을 찾아가는게 맞는 방향인데, term에서 doc을 찾아가므로 inverted index라고 부른다.
- 실제 inverted index는 좀 더 복잡하긴 한데 나중에 배운다고 한다.

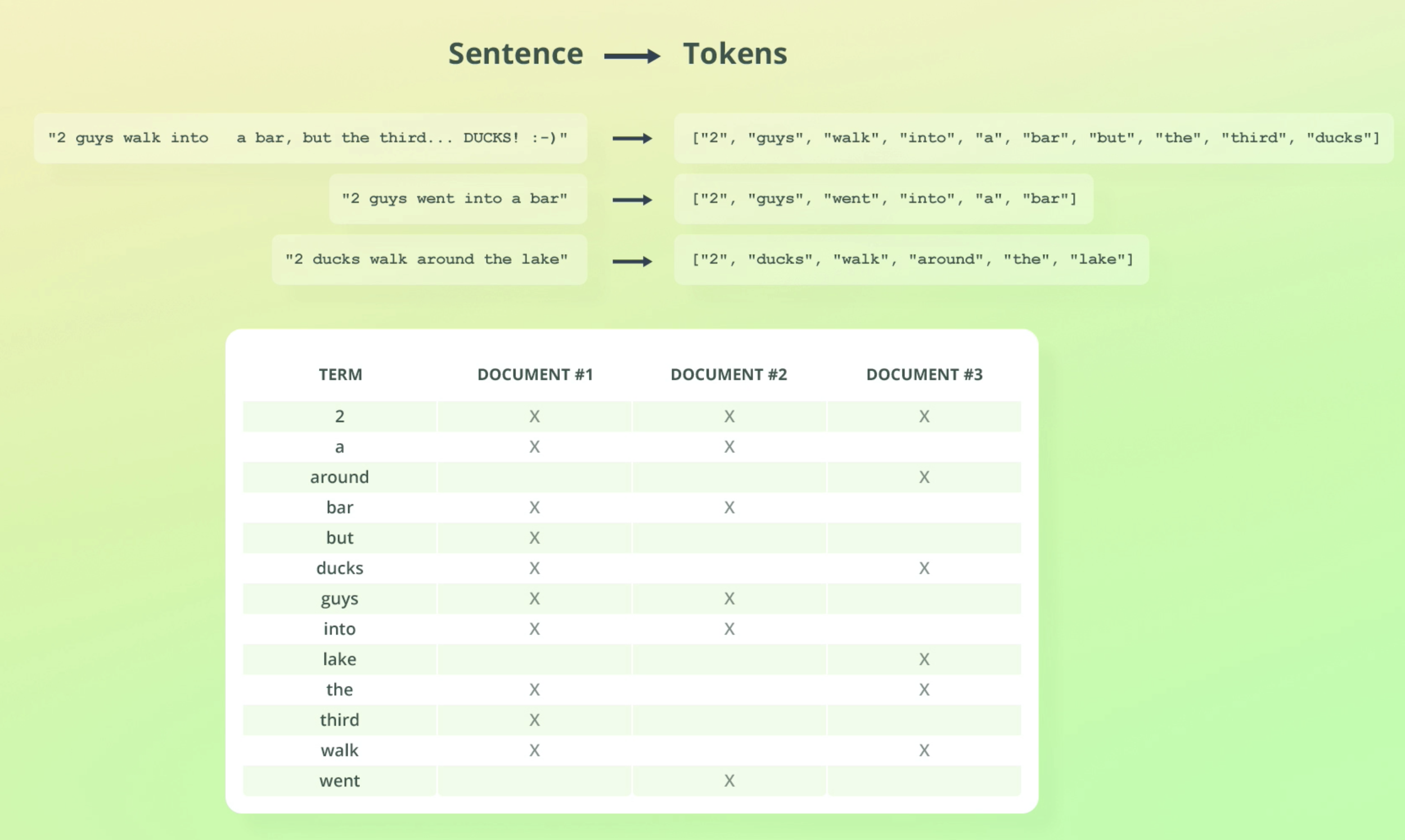
- 아래 예시를 보면 name 필드 인덱스와 description인덱스가 각각 생성됨을 볼 수 있다.
- so the key thing here is to understand that an inverted index exists within the scope of a field.


summary
- text field의 값은 analyzer를 거치고 결과값은 inverted index에 저장된다.
- 각 필드별로 dedicated invert index를 갖는다.
- An inverted index is a mapping between terms and which documents contain them.
- Terms are sorted alphabetically for performance reasons.
- Created and maintained by Apache Lucene, not ES
- Invereted indices enable fast searches
- Inverted indices contain other data as well
- E.g. things used for relevance scoring(covered later)
- ES(technically, Apache Lucene) uses other data structres as well
- E.g. BKD trees for numeric values, dates, and geospatial data.
Introduction to mapping
What is mapping?
- Defines the structure of documents(e.g. fields and their data types)
- Also used to configure how values are indexed
- Similar to a table's schema in a relational DB

- mapping에는 두 종류가 있다. (Explicit mapping, Dynamic mapping)
- 두 매핑 혼용 가능
Explicit mapping
- 내가 직접 정의
Dynamic mapping
- 필드값에 맞춰 ES가 직접 정의함. (Text값이 들어오면 text필드로 정의해줌)
Overview of data types
- object, text, float, date, boolean, long, short, integer, double 등이 있다.
object
- used for any JSON object
- each doc that we index into ES is a JSON object
- Objects may be nested
- Mapped using the properties parameter
- Objects are not stored as objects in Apache Lucene
- Objects are transformed to ensure that we can index any valid JSON
- 내부적으로 objects는 flattened된다.


nested data type
-
Similar to the 'object' data type, but maintains object relationships
- Useful when indexing arrays of objects
-
Enables us to query objects independently
- Must use the nested query

- Must use the nested query
-
object가 없는 apache lucene엔 어떻게 object가 저장될까?
- nested objects are stored as hidden documents
-
1000개의 review가 nested형태로 있는데 product 1개를 indexing한다고 해보자.
- Apache Lucene은 11개의 doc을 인덱싱 하게된다.
keyword data type
- Used for exact matching of values. 값이 정확하게 일치하는 걸 찾을때 쓰인다.
- 주로 filtering, aggregations, sorting에 쓰인다.
- 예. status가 PUBLISHED인 article찾기.
- full-text search는 text data type을 쓰는게 유리하다.
- 예. 특정 단어가 들어간 Article 찾기.
how the keyword data type works
How keyword fields are analyzed
- keyword 필드는 keyword analyzer 가 분석한다.
- 이 analyzer는 no-op analyzer다. 아무 일도 안함. 가공하면 exact mathing이 불가능하기 때문.
- It outputs the unmodified string as a single token
- text is left completely untouched
- example of using keyword analyzer
- 이메일 검색 등에 쓰일 수 있다.
POST /_analyze
{
"text": "2 guys walk into a bar, but the third... DUCKS! :-)",
"analyzer": "keyword"
}{
"tokens" : [
{
"token" : "2 guys walk into a bar, but the third... DUCKS! :-)",
"start_offset" : 0,
"end_offset" : 53,
"type" : "word",
"position" : 0
}
]
}type coercion
- 데이터 삽입시 데이터 타입은 validation과정을 거친다.
- 이때, 잘못된 데이터 타입이라 할지라도 경우에 따라 거절되는 경우도 있고 승인될 떄도 있다.
- 예를 들어 숫자 필드에 "8" 값을 넣으면 이건 알아서 숫자로 바껴서 저장된다. 하지만 숫자 필드에 "asdf"를 넣으면 에러가 난다.
- 아래 예시에서 1번째는 성공(처음이니까), 2번째도 성공(string -> float 자동변환), 3번째 실패다
PUT /coercion_test/_doc/1
{
"price": 7.4
}
PUT /coercion_test/_doc/2
{
"price": "7.4"
}
PUT /coercion_test/_doc/1
{
"price": "7.4m"
}
GET /coercion_test/_doc/1
GET /coercion_test/_doc/2- GET에 대한 response를 보면 id 1은 float으로, 2는 string으로 출력된다. 분명 float으로 바뀐다 했는데..?
"_source" : {
"price" : 7.4
}"_source" : {
"price" : "7.4"
}
}- 내부적으론 float으로 저장되지만, 출력형태는 입력형태와 똑같이 된다.
- 따라서 _source를 쓸땐 이점을 유의해야 한다.
- 이런 상황을 방지하려면 1)애초에 제대로 된 데이터를 넣거나, 2) coercion기능을 해제해야 한다. (디폴트로 켜져있음)

understanding arrays
- array data type은 ES에 없다.
- any field may contain zero or more values
- No configuration or mapping needed
- Simply supply an array when indexing a document
- 아래 결과를 보면 두 텍스트가 한 문장처럼 연결된 것을 볼 수 있다.
- 두 string은 a space in-between으로 연결된다. (한 문장이 되지 않기 위해)
POST /_analyze
{
"text": ["sting number one", "string number two"],
"analyzer": "standard"
}- response
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.13/security-minimal-setup.html to enable security.
{
"tokens" : [
{
"token" : "sting",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "number",
"start_offset" : 6,
"end_offset" : 12,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "one",
"start_offset" : 13,
"end_offset" : 16,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "string",
"start_offset" : 17,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "number",
"start_offset" : 24,
"end_offset" : 30,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "two",
"start_offset" : 31,
"end_offset" : 34,
"type" : "<ALPHANUM>",
"position" : 5
}
]
}- text가 아닌 데이터는 analyzed되지 않고 적절한 데이터 타입에 저장된다.
constraints
- array안의 데이터 타입은 전부 같아야한다. (아래의 초록색 예시)
- 혹은 coercion으로 같아질 수 있어야 한다. (아래의 노란색 예시들)

- 참고로 coercion은 필드가 매핑이 된 상태에서만 작동한다.
- 첫 필드 생성시(아직 매핑 안된 상태) 필드타입을 명시 하지 않는 다이나믹 매핑을 한다면, 이때는 반드시 array데이터 타입이 같아야 한다.
- 강사는 개인적으로 coercion을 비추한다고 한다.
nested arrays
- 가능함
- flattened during indexing
- [1, [2,3]] becomes [1,2,3]
Remember to use the nested data type for arrays of objects if you need to query the objects independently.
Adding explicit mappings
- 실제 매핑을 만들어 index를 create해보자.
PUT /reviews
{
"mappings": {
"properties": {
"rating": {"type": "float"},
"content": {"type": "text"},
"prouct_id": {"type": "integer"},
"author": {
"properties": {
"first_name": {"type": "text"},
"last_name": {"type": "text"},
"email": {"type": "keyword"}
}
}
}
}-
크게 rating, content, product_id, author필드가 있고 author필드는 object이기 때문에 다시 데이터 타입을 정의한다.
-
text vs keword 어떤 필드를 쓸지 신중하게 고르는 게 좋다.
-
keyword 필드는 filtering, aggregation, and for exact mathces에 쓰인다.
-
보통 정확한 이메일을 찾고, 그 메일을 pk로 쓸수도 있고 하니 이메일에 keyword필드를 쓰는게 적절하다.
-
response
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "reviews"
}- 이제 위에서 정의한 타입에 맞게 document를 indexing하면 된다.
Retrieving mappings
GET /reviews/_mapping : retrieve mappings for the entire index
GET /reivews/_mapping/field/content : retrieve mapping for a field
GET /reivews/_mapping/field/author.email : retrieve mapping for a field(object)
Using dot notaion in field names
- object 매핑할 때 author.first_name 같이 dot notation 쓰면 좀 더 편하다.
PUT /reviews_dot_notation
{
"mappings": {
"properties": {
"rating": {"type": "float"},
"content": {"type": "text"},
"product_id": {"type": "integer"},
"author.first_name": {"type": "text"},
"author.last_name": {"type": "text"},
"author.email": {"type": "keyword"}
}
}
}
}Adding mappings to existing indices
- 위에서 만든 reviews인덱스에 created_at 필드를 추가해보자.
PUT /reviews/_mapping
{
"properties": {
"created_at": {
"type": "date"
}
}
}How dates work in ES
- Specified in one of three ways
- Specially formatted strings
- Milliseconds since the epoch(long)
- Seconds since the epoch (integer)
- Epoch refers to the 1st of January 1970 (Unix Timestamp)
- Custom formats are supported
Defualt behavior of date fields
- Three supported foramts
- A date without time
- A date with time
- Milliseconds since the epoch (long)
- UTC timezone assumed if none is specified
- Dates must be formatted according to the SIO 8601 specification
How date fields are stored
- 내부적으로 milliseconds since the epoch로 저장됨.
- date값이 들어오면 내부적으로 UTC timezone으로 변환된다.
- 저장할 때, Search할 때 둘 다 date field가 epoch형태로 변환됨
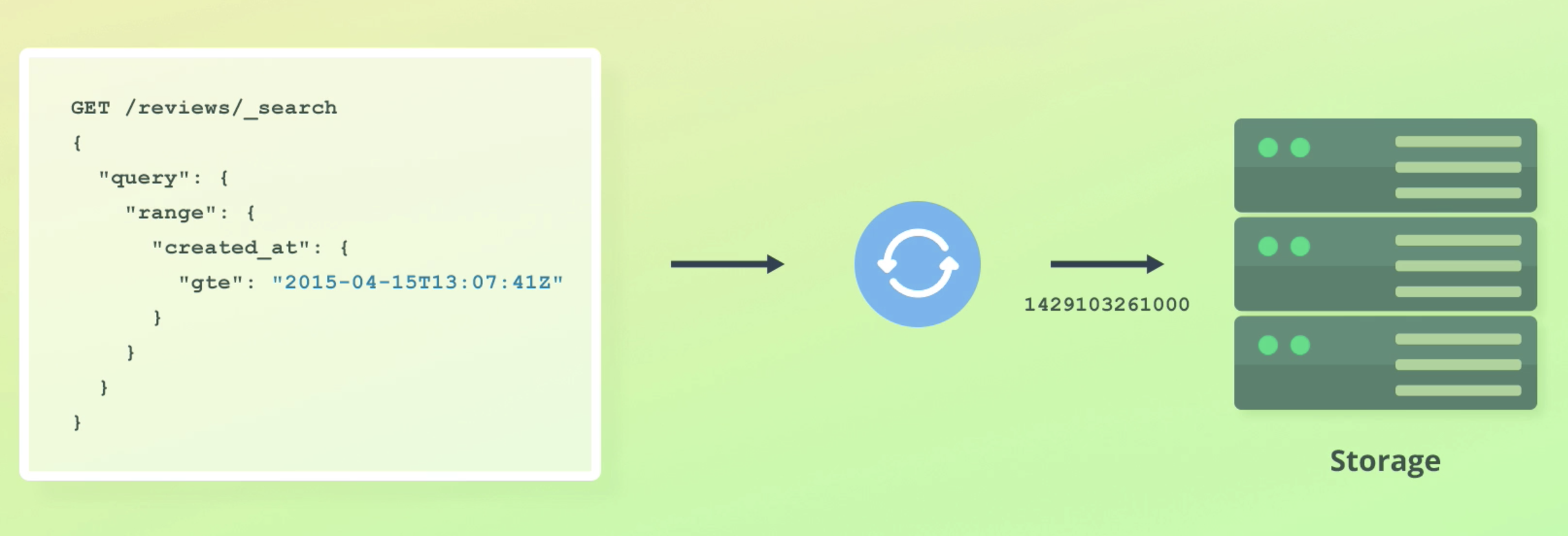
SIO 8601
- time이 안주어지면 UTC면서 midnight으로 가정하고 데이터가 저장된다.
- T는 Date와 time을 구분하기 위함이고, Z는 UTC timezone을 나타낸다.
- UTC가 아닐 때는 +01:00 형태로 UTC와 얼마나 차이나는지를 명시해준다.
- the number of milliseconds since the epoch.
it's really important that you don't specify a UNIX timestamp here, i.e. the number of seconds since epoch. If you do that, ES won't give you and error because it will just treat the number as the number of milliseconds since the epoch.
You might then think that everyting is okay.
However, when you search for documents within a given date ragne, you won't get any matches becuase the dates are actually way in the past.
If you do have a UNIX timestamp, then be sure to multiply that number by 1,000
실습
PUT /reviews/_doc/2
{
"rating": 4.5,
"content": "Not bad",
"product_id": 123,
"created_at": "2015-03-27",
"author": {
"first_name": "A",
"last_name": "Joe",
"email": "Joe@example.com"
}
}
PUT /reviews/_doc/3
{
"rating": 4.5,
"content": "Not bad",
"product_id": 123,
"created_at": "2015-03-27T13:07:41Z",
"author": {
"first_name": "B",
"last_name": "Boe",
"email": "Boe@example.com"
}
}
PUT /reviews/_doc/4
{
"rating": 4.5,
"content": "Not bad",
"product_id": 123,
"created_at": "2015-03-27T13:07:41+01:00",
"author": {
"first_name": "B",
"last_name": "Boe",
"email": "Boe@example.com"
}
}
PUT /reviews/_doc/5
{
"rating": 4.5,
"content": "Not bad",
"product_id": 123,
"created_at": 1436011284000,
"author": {
"first_name": "B",
"last_name": "Boe",
"email": "Boe@example.com"
}
}
GET /reviews/_search
{
"query": {
"match_all": {}
}
}How missing fields are handled
- All fields in ES are optional
- can leave out a field when indexing documents
- integrity check: You should handle this at the application level
- Adding a field mapping does not make a field required
- Searchs automatically handle missing fields
Overview of mapping parameters
- mapping에는 필드명, 데이터 타입 외에도 parameter를 넘길 수 있다.
- 이번에 다루는 param외에도 많이 있는데, 거의다 잘 안쓰이거나 아주 특별한 상황에서만 쓰이는 거라 패스. 때가 되면 배울거다.
format parameter
-
date 필드 포맷을 커스텀하는데 사용된다.
-
웬만하면 디폴트 포맷 쓰는걸 추천한다.
-
default는 ISO 8601.
-
legacy 때문에 혹시 저 포맷이 안되면 format param으로 커스텀 하면 된다.
- Java의 DateFormatter문법대로 하면 된다.

properties parameter

coerce parameter
- used to enable or disable coercion of values(enabled by default)
- 왼쪽 예시는 특정 필드단에 coerce설절 준 것.
- 오른쪽 예시처럼 index레벨에서 설정도 가능하다. 그리고 바로 아래에서 필드 단위로 또 다시 설정해줬다.

Introduction to doc_values
- ES는 많은 자료구조를 사용한다.
- inverted indices는 searching text에 최적화 되어있다.
- They don't perform well for many other data access patterns
- "Doc values" is another data structure used by Apache Lucene
- Optimized for a different data access pattern(document -> terms)
- Essentially an "uninverted" inverted index
- Used for sorting, aggregations, and scripting
- An additional data structure, not a replacement
- ES automatically queries the appropriate data structure.
Disabling doc_values
- Set the doc_values parameter to false to save disk space
- also slightly increases the indexing throughput
- only diable doc values if you won't use aggregations, sorting, or scripting.
- particularly useful for large indices; typically not worth it for small ones.
- Cannot be changed without reindexing documents into new index.
- Use with caution, and try to anticipate how fields will be queried.
if set false, this data structrue would then not be built and stored on disk.
Storing data in multiple data structures effectively duplicates data with the purpose of fast retrieval, so disk space is traded for speed.
A side benefit of that would be increased indexing speed, because there is naturally
a small overhead of building this data structure when indexing documents.
So when would you want to disable doc values?
If you know that you won’t need to use a field for sorting, aggregations, and scripting,
you can disable doc values and save the disk space required to store this data structure.
For small indices, it might not matter much, but if you are storing hundreds of millions
- doc values 해제하는 법.
PUT /sales { "mappings": { "properties": { "buyer_email": { "type": "keyword", "doc_values": false } } } }
norms parameter
-
Normalization factors used for relevance scoring
-
relevance scoring은 연관도다. 구글 검색했을 때 5페이지보다 1페이지에 내가 원하는 내용이 많은데 이게 연관도 순으로 정렬하기 때문이다.
-
Often we don't just want to filter results, but also rank them.
-
Norms can be siabled to save disk space
- Useful for fields that won't be used for relevance scoring
- The fields can still be used for filtering and aggregations
-
필드를 filtering과 aggregation만 할거라면 norms를 disabled해서 디스크 공간을 아낄 수 있다.
PUT /products
{
"mappings": {
"properties": {
"tags": {
"type": "text",
"norms": false
}
}
}
}index parameter
- Disables indexing for a field
- Values are still sotred within _source
- Useful if you won't use a field for search queries
- Saves disk space and slightly improves indexing throughput
- Often used for time series data
- Fields with indexing disabled can still be used for aggregations.
PUT /server-metrics
{
"mappings": {
"properties": {
"tags": {
"type": "integer",
"index": false
}
}
}
}null_values parameter

PUT /sales
{
"mappings": {
"properties": {
"partner_id": {
"type": "keyword",
"null_value": "NULL"
}
}
}
}copy_to parameter
- Used to copy multiple field values into a "group field"
- Simply specify the name of the target field as the value
- E.g first_name and last_name -> full_name
- values are copied, not terms/tokens
- The analyzer of the target field is used for the values
- The target field is not part of _source
PUT /sales
{
"mappings": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name"
},
"last_name": {
"type": "text",
"copy_to": "full_name"
},
"full_name": {
"type": "text"
}
}
}
}Updating existing mappings
- 원래 int였던 product_id가 letter까지 포함하게 됐다 치자.
- product_id를 text 혹은 Keyword로 바꿔야 하는데, full-text search보단 filtering을 주로 하므로 keyword로 바꿔야 한다.
- 아래 처럼 하면 될까? 싶지만 에러가 난다.
PUT /reivews/_mapping
{
"properties": {
"product_id": {
"type": "keyword"
}
}
}- 일반적으로 ES 필드 매핑은 바꿀 수 없다.
- 다만 몇몇 mapping parameter를 업데이트 하는 것만 가능하다.
- 아래는 256크기 이상이 들어오면 저장하지 말라는 param이다. 이런것만 업데이트 가능함.
PUT /reivews/_mapping
{
"properties": {
"author": {
"properties": {
"email": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}- 매핑 업데이트는 problematic하다.
- text -> keyword로 바꾸는건 불가능하다. 이미 value들이 analyzed됐기 때문.
- Changing between some data types would require rebuilding the whole data structure.
- Even for an empty index, we cannot update a mapping.
- Field mappings also cannot be removed
- Just leave out the field when indexing documents
- The Update By Query API can be used to reclaim disk space
- creaet a new index with the updated mapping and reindex any existing documents into it. 이게 방법이다.
Reindixing documents with the Reindex API
- 기존 int필드였던 product_id를 keywword필드로 만들기 위해 리인덱싱을 하자.
- 새로운 인덱스를 만들고 mapping을 지정해준다.
PUT /reviews_new
"mappings" : {
"properties" : {
"author" : {
"properties" : {
"email" : {
"type" : "keyword"
},
"first_name" : {
"type" : "text"
},
"last_name" : {
"type" : "text"
}
}
},
"content" : {
"type" : "text"
},
"created_at" : {
"type" : "date"
},
"product_id" : {
"type" : "keyword"
},
"prouct_id" : {
"type" : "integer"
},
"rating" : {
"type" : "float"
}
}
}- 새 인덱스를 만들고 매핑을 했으니 이제 기존 데이터를 여기로 옮겨주자.
- but how do we do that?
- 기존 인덱스에서 데이터를 전부 retrieve한 다음 새로운 인덱스에 넣어준다.
- 데이터가 많으면 시간도 꽤 걸린다.
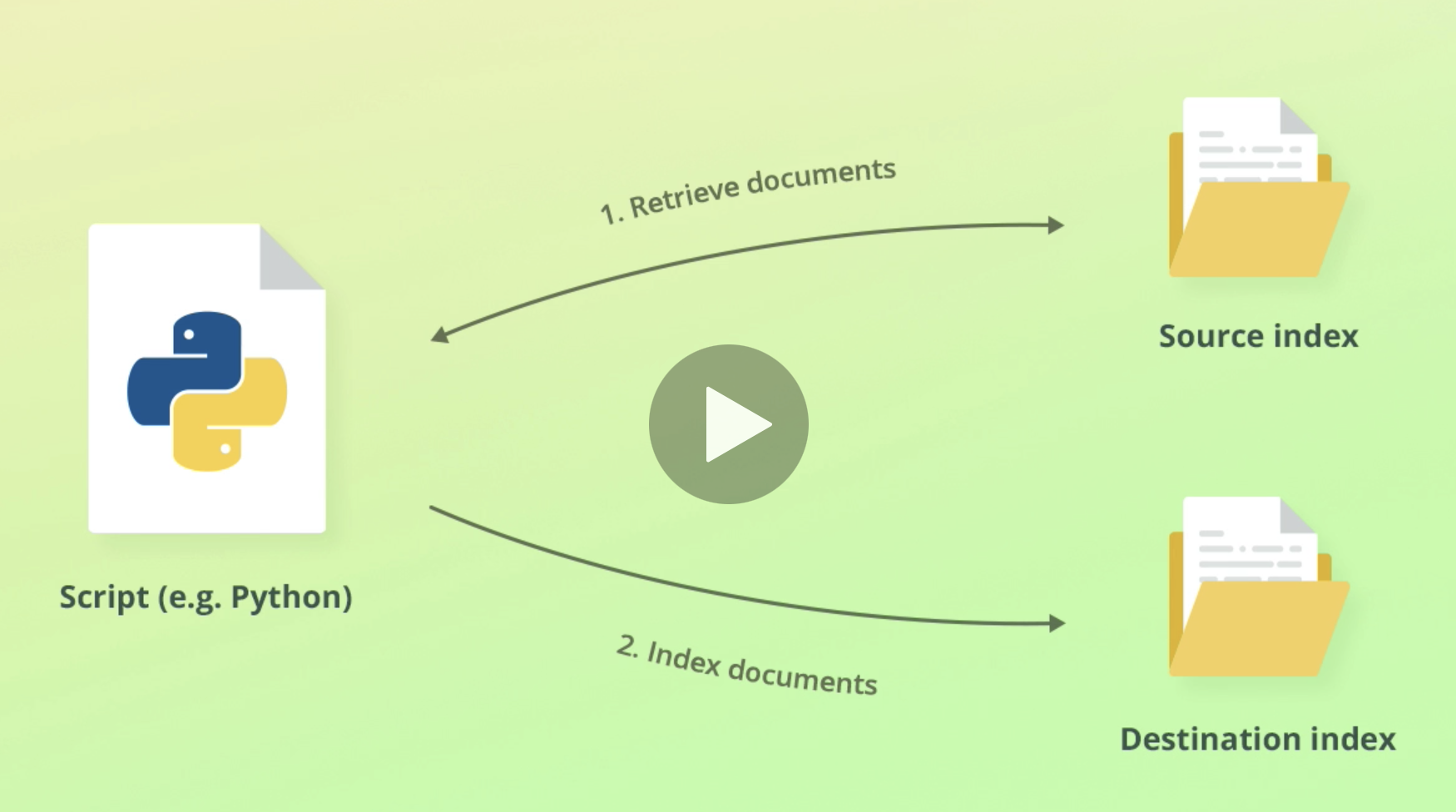
- 근데 이게 너무 복잡하잖아요? 그래서 이걸 직접 해주는 Reindex API라는게 있다!
Reindex API

- 아래는 reivews인덱스에서 reviews_new인덱스로 reindex하는 코드
POST /_reindex
{
"source": {
"index": "reviews"
},
"dest": {
"index": "reviews_new"
}
}_source data types
- The data type doesn't reflect how the values are indexed
- _source contains the field values supplied at index time
- It's common to use _source values from search results
- You would probably expect a string for a keyword field
- We can modify the _source values while reindexing
- Alternatively this can be handled at the application level
- int필드를 keyword필드에 리인덱스 해서 옮겨와도 기존에 int였던 데이터타입이 변하지 않는다.
- 바꿔주려면 따로 script를 작성해야 한다.
- 방금 reindex로 가져온 데이터를 지우고 다시 int->string으로 변환해서 가져와보자.
POST /reviews_new/_delete_by_query
{
"query": {
"match_all": {}
}
}
POST /_reindex
{
"source": {
"index": "reviews"
},
"dest": {
"index": "reviews_new"
},
"script": {
"source": """
if (ctx._source.product_id != null) {
ctx._source.product_id = ctx._source.product_id.toString();
}
"""
}
}GET 쿼리해보면 데이터 타입이 int가 아닌 string임을 볼 수 있다.
Reindex documents matching a query
- 전체 인덱스 말고, 특정 데이터만 reindex해서 가져오고 싶을 때 query를 사용하면 된다.
- 아래 예시는 reviews -> reviews_new로 reindex하는 예시인데, review데이터 중 rating이 4.0보다 큰 것만 가져온다.
POST /_reindex
{
"source": {
"index": "reviews",
"query": {
"range": {
"rating": {
"gte": 4.0
}
}
}
},
"dest": {
"index": "reviews_new"
}
}Removing fields
- _source를 사용해 들고올 필드만 명시해줌으로 remove함.
POST /_reindex
{
"source": {
"index": "reviews",
"_source": ["content", "created_at", "rating"]
},
"dest": {
"index": "reviews_new"
}
}rename fields
- content필드를 comment필드로 rename하는 쿼리
- remove함수는 지워진 값을 return하기 때문에 좌변에 우변이 할당된다
POST /_reindex
{
"source": {
"index": "reviews"
},
"dest": {
"index": "reviews_new"
},
"script": {
"source": """
# Rename "content" field to "comment"
ctx._source.comment = ctx._source.remove("content");
"""
}
}ingnore reviews tih ratings below 4.0
POST /_reindex
{
"source": {
"index": "reviews"
},
"dest": {
"index": "reviews_new"
},
"script": {
"source": """
if (ctx._source.rating < 4.0) {
ctx.op = "noop"; # Can also be set to "delete"
}
"""
}
}Using ctx.op within scripts
- Usually, using the query parameter is possible
- for more advanced use cases, ctx.op can be used
- Using the query parameter is better performance wise and is preferred
- Specifying "delete" deletes the document within the destination index
- The destination index might not be empty as in our example
- The same can often be done with the Delete by Query API
Defining field aliases
- alias를 사용해 content필드명을 comment로 바꿔보자. (정확히 말하면 바뀌는 건 아니고 별명지정)
PUT reviews/_mapping
{
"properties": {
"comment": {
"type": "alias",
"path": "content"
}
}
}- content, comment 둘 중 뭐로 해도 같은 결과가 검색된다.
GET /reviews/_search
{"query": {
"match": {
"content": "Not bad"
}
}}
GET /reviews/_search
{"query": {
"match": {
"comment": "Not bad"
}
}}Updating field aliases
- Field aliases can actually be updated
- Only its target field, though
- Simply perform a mapping update with a new path value
- Possible becuase aliasees don't affect indexing
- It's a query-level construct
Multi-field mappings
- 필요하다면 text필드면서 동시에 keyword필드로 설정할 수 있다.
- 특정 필드가 full-text search에도 쓰이고(text), aggregation, sorting에도 쓰인다면 둘 다 지정해줘야한다.
- ingredients 필드가 text, keword 둘 다를 가지게 해보자.
- 아래에 키값 keyword는 다른 걸로 해도 되지만 해당 타입과 똑같이 해주는게 convention이다.
PUT /multi_field_test
{
"mappings": {
"properties": {
"description": {
"type": "text"
},
"ingredients": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}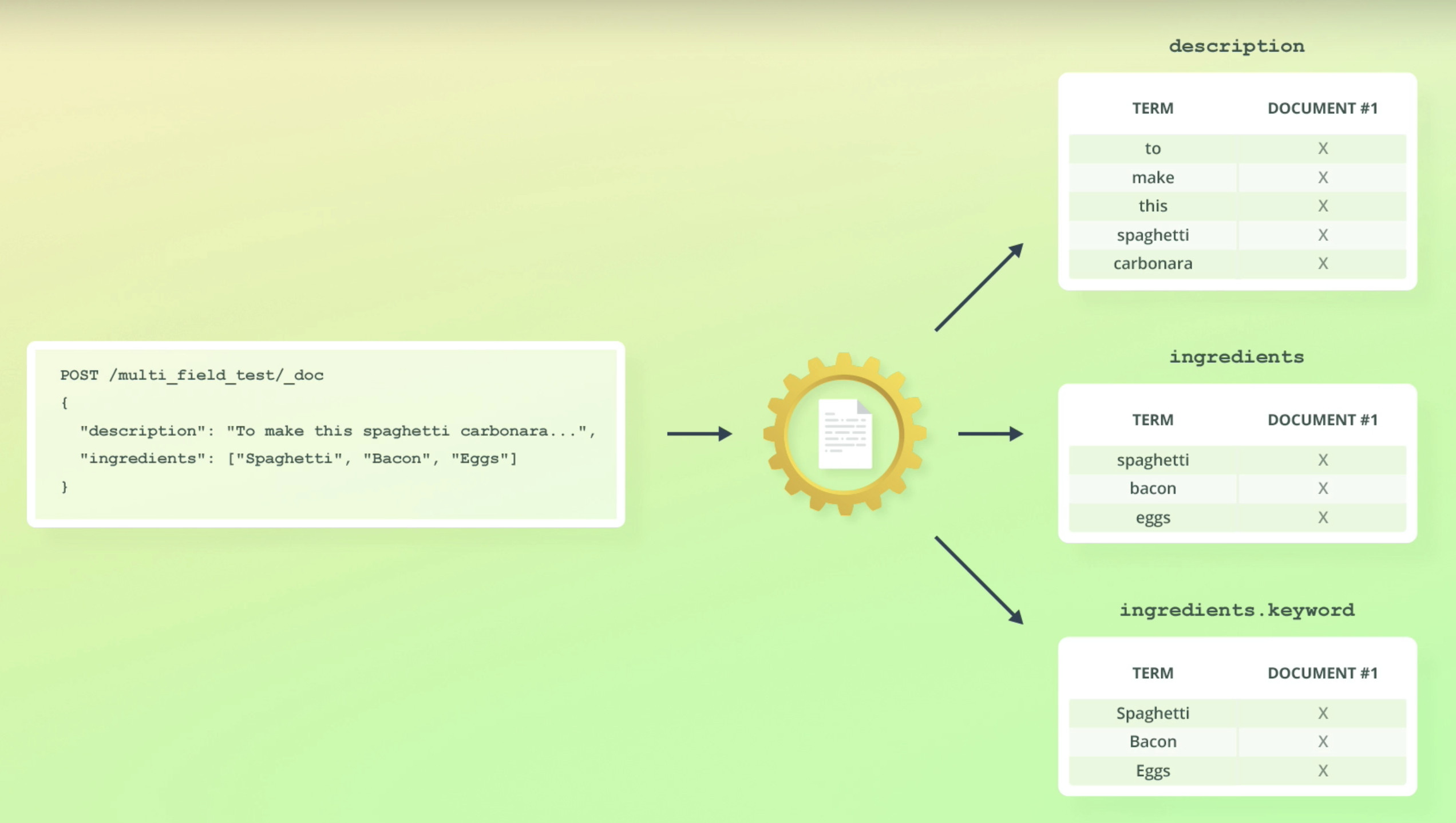
POST /multi_field_test/_doc
{
"description": "To make this spaghetti carbonara, you first need to...",
"ingredients": ["Spaghetti", "Bacon", "Eggs"]
}- 아래 첫 케이스는 text필드 retrieve, 두 번째는 keyword retrieve다.
GET /multi_field_test/_search
{
"query": {
"match": {
"ingredients": "Spaghetti"
}
}
}GET /multi_field_test/_search
{
"query": {
"term": {
"ingredients.keyword": "Spaghetti"
}
}
}Index templates
- 잘 이해 안됨. 다시 듣기
ECS(Elastic Common Schema)
- 잘 이해 안됨. 다시 듣기
Dynamic mapping(intro)
- 미리 필드매핑을 안해놓은 경우, ES가 첫 doc의 indexing을 할 때 필드매핑을 자동으로 해준다.

- created_at이 str으로 들어왔지만, datetime 검증을 거쳐 str이 datetime format일 경우 자동으로 매칭해준다.
- in_stock에 숫자 4가 들어왔으니 int로 해도 되지만, 얼마나 더 큰 수가 들어올지 모르므로 ES는 long으로 매핑한다.
- tags는 text와 keyword 두개로 매핑됐다. full text search(text)로 쓰일지, aggregation, sorting(keyword)로 쓰일지 모르기 때문에 대비해 놓는 것이다.
- 256 이상의 키워드로 exact match, aggregation을 하는게 사실상 말이 안되니 256이상은 무시하도록 설정한다.

- string은 text, date, float or long으로 매칭된다.
- 나머지도 위에 표와 같다.
- object는 똑같이 세부적으로 매핑된다. 아래 참고.

- 256 이상의 키워드로 exact match, aggregation을 하는게 사실상 말이 안되니 256이상은 무시하도록 설정한다.
Combining explicit and dynamic mapping
- explicit, dynamic꼭 택 1을 해야하는 건 아니다. 두개를 섞어 쓸 수 있다.
- 어떤 필드는 미리 매핑 해놓고, 다른 필드를 나중에 매핑 없이 추가하면 자동으로 매핑된다.
Configuring dynamic mapping
1. dynamic 매핑 false로 설정.
PUT /people
{
"mappings": {
"dynamic": false,
"properties": {
"first_name": {
"type": "text"
}
}
}
}-GET /people/_mapping으로 매핑 확인하면 아래와 같다.(first_name만 존재)
{
"people" : {
"mappings" : {
"dynamic" : "false",
"properties" : {
"first_name" : {
"type" : "text"
}
}
}
}
}- 매핑에 없는 last_name까지 더해 doc post
POST /people/_doc
{
"first_name": "Bo",
"last_name": "Andersen"
}- first_name : "Bo"로 search날려보니 매핑에 없던 last_name까지 _source에 들어있다?!
GET people/_search
{"query": {
"match": {
"first_name": "Bo"
}
}} "_source" : {
"first_name" : "Bo",
"last_name" : "Andersen"
}- 그럼 last_name으로도 search가 가능할까?
GET people/_search
{"query": {
"match": {
"last_name": "Andersen"
}
}}- 정답은 no.
{
"took" : 688,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}- 위 내용으로 알 수 있는 점
Setting dynamic to false
- 매핑이 안된 필드는 indexing되진 않지만 _source에는 포함된다.
- 해당 필드(last_name)을 위한 inverted index가 만들어지지 앟는다.
- 쿼리할 수 없다.
- Fields cannot be index without a mapping
- When enabled, dynamic mapping creates one before indexing values
"dynamic": "strict" -> Better way
-
제일 좋은건(강사 기준) "dynamic": "strict"으로 설정하는 것이다.
-
이렇게 하면 ES는 unmapped fields를 reject한다.
- RDS랑 비슷
-
DELETE /people로 위인덱스를 지운 후 아래 put으로 다시 만들자.
PUT /people
{
"mappings": {
"dynamic": "strict",
"properties": {
"first_name": {
"type": "text"
}
}
}
}이제 아까처럼 Post해보면 400에러가 난다!
POST /people/_doc
{
"first_name": "Bo",
"last_name": "Andersen"
}numeric detection
- dynamic설정과 같이 Root level에서 설정해준다.
- value가 오직 숫자로만 이뤄져있는지 검사한 후 참이라면 이게 작동한다.

date detection
- dynamic설정과 같이 Root level에서 설정해준다.
- 디폴트 format이 있고, 커스텀도 가능하다(위 오른쪽 그림)

Dynamic templates
생략
Mapping recommendations
- mapping에 관한 강사의 개인적 추천들
use explicit mappings
- dynamic mapping이 편하긴 하지만, production에서는 비추다.
- save disk space with optimized mappings when storing many documents
- Set dynamic to "strict", not false
- Avoids surprises and unexpected results
Mapping of text fields
- Don't always map strings as both text and keyword
- Typically only one is needed
- Each mapping requires disk space
- Do you need to perform full-text searches?
- Add a text mapping
- Do you need to do aggregations, sorting, or filtering on exact values?
- Add a keyword mapping
Disable coercion
- Coercion forgives you for not doing the right thing
- Try to do the right thing instead
- always use the correct data types whenever possible
Use appropriate numeric data types
- integer might be enough
- long can store larger numbers, but also uses more disk space
- for decimal, float might be enough
- double stores numbers with a higher precision but uses 2x disk space
- Usually, float provides enough precision
Mapping parameters
- Set doc_values to false if you don't need sorting, aggregations, and scripting
- Set norms to false if you don't need relevance scoring
- Set index to false if you don't need to filter on values
- You can still do aggregations, e.g. for time series data
- Probably only worth the effort when storing lots of docs
- Otherwise it's probably an over complication
- Worst case scenario, you will need to reindex dos
Stemming & stop words
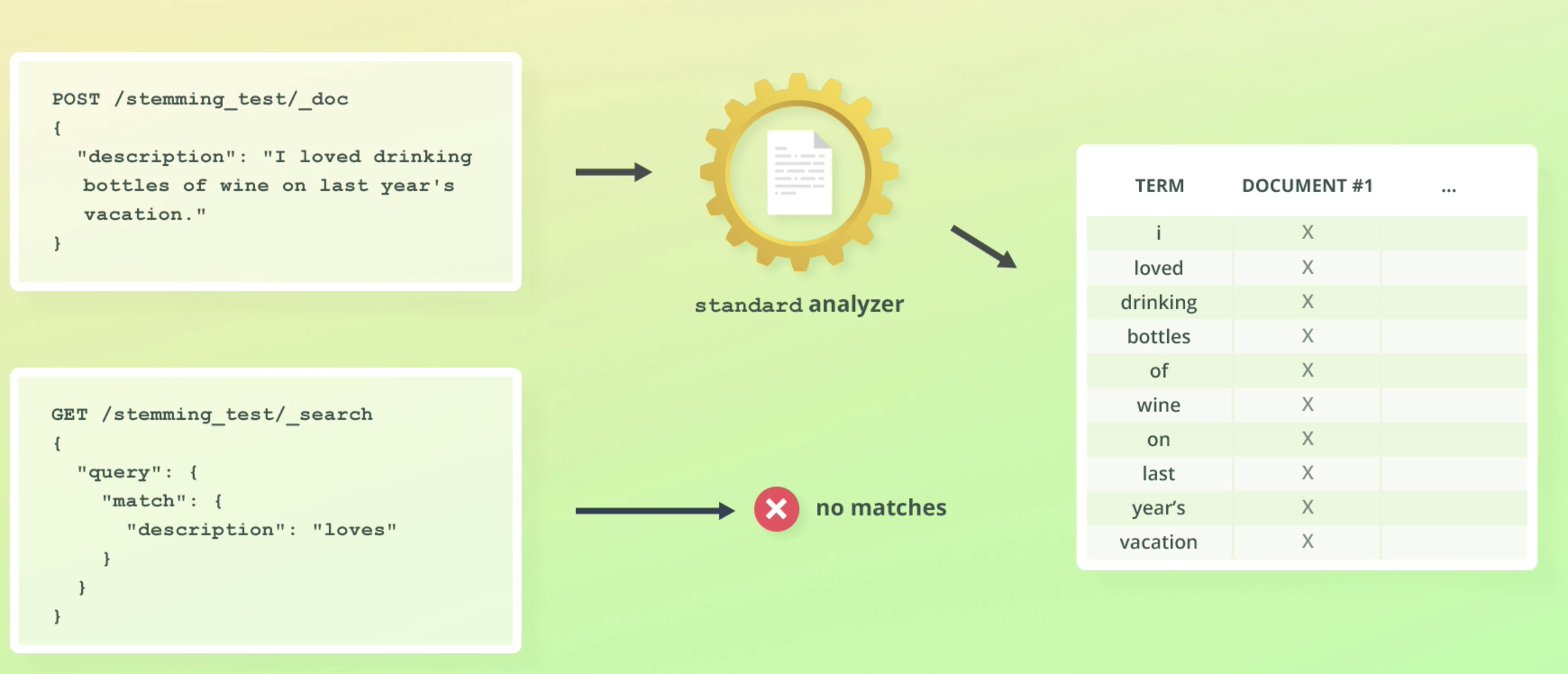
stemming
- reduces words to their root form
- loved -> love. drinking -> drink
- ES 내부적으로 사용되는 용어.
stop words
- text alanysis할 때 filtered out되는 단어들
- "a", "the", "at", "of", "on" 등등
- relevance scoring에 별 영향 안주는 단어들이다.
- 저런 단어 지우는건 꽤 흔한 일이다(구글 검색에서도 저 단어 없다고 결과 달라지지 않음)
- 하지만 Less common in ES today than in the past
- 왜냐면 relevance algorithm이 엄청 개선되었기 때문
- 하지만 Less common in ES today than in the past
- Not removed by default, 그리고 강사도 이거 사용 비추함.
Analyzers and search queries
- (전에 배웠듯이) analyzer는 텍스트 필드 indexing하는데 쓰이고, search query에도 쓰인다.
- index할 때 쓰였던 analyzer가 search쿼리 할때도 똑같이 쓰인다.
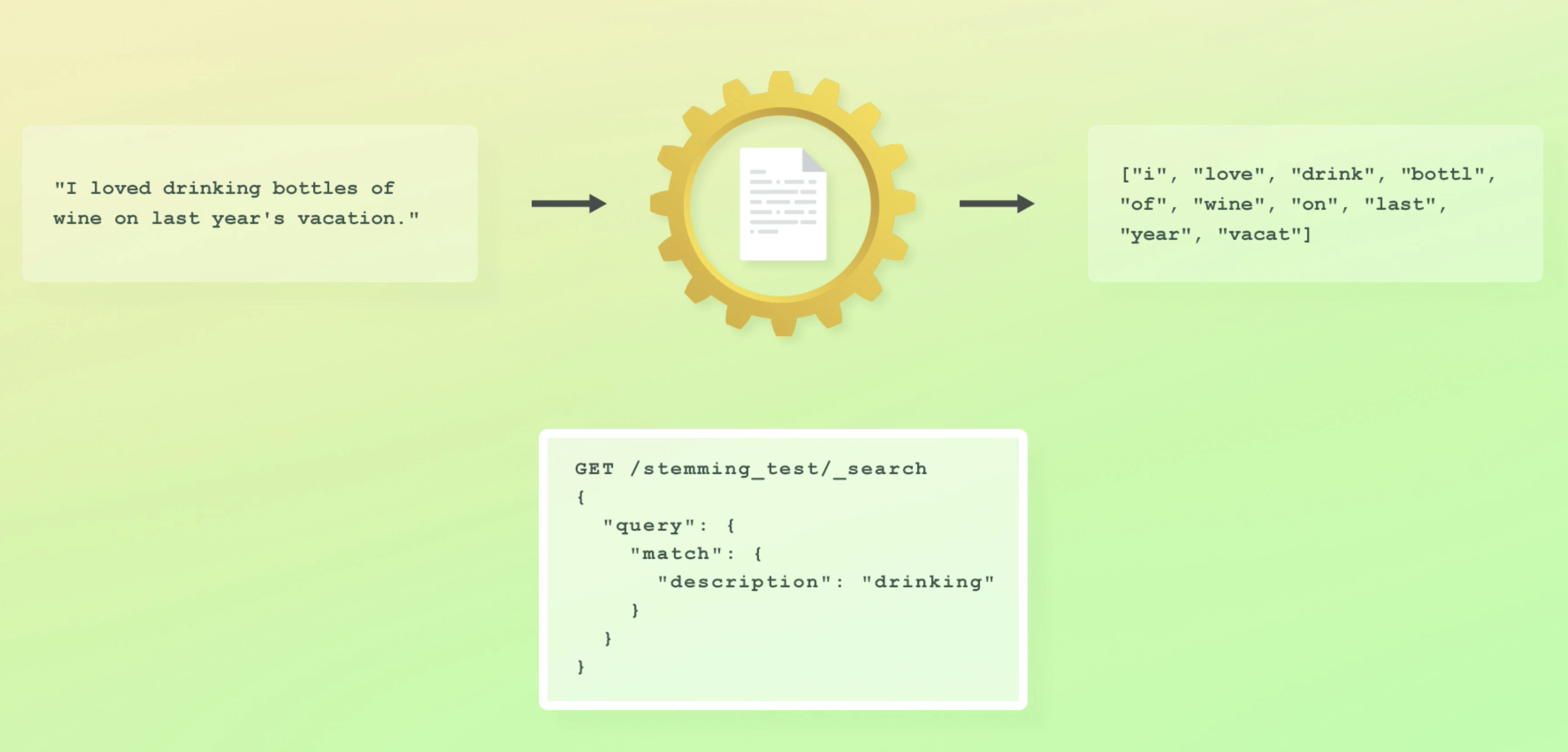
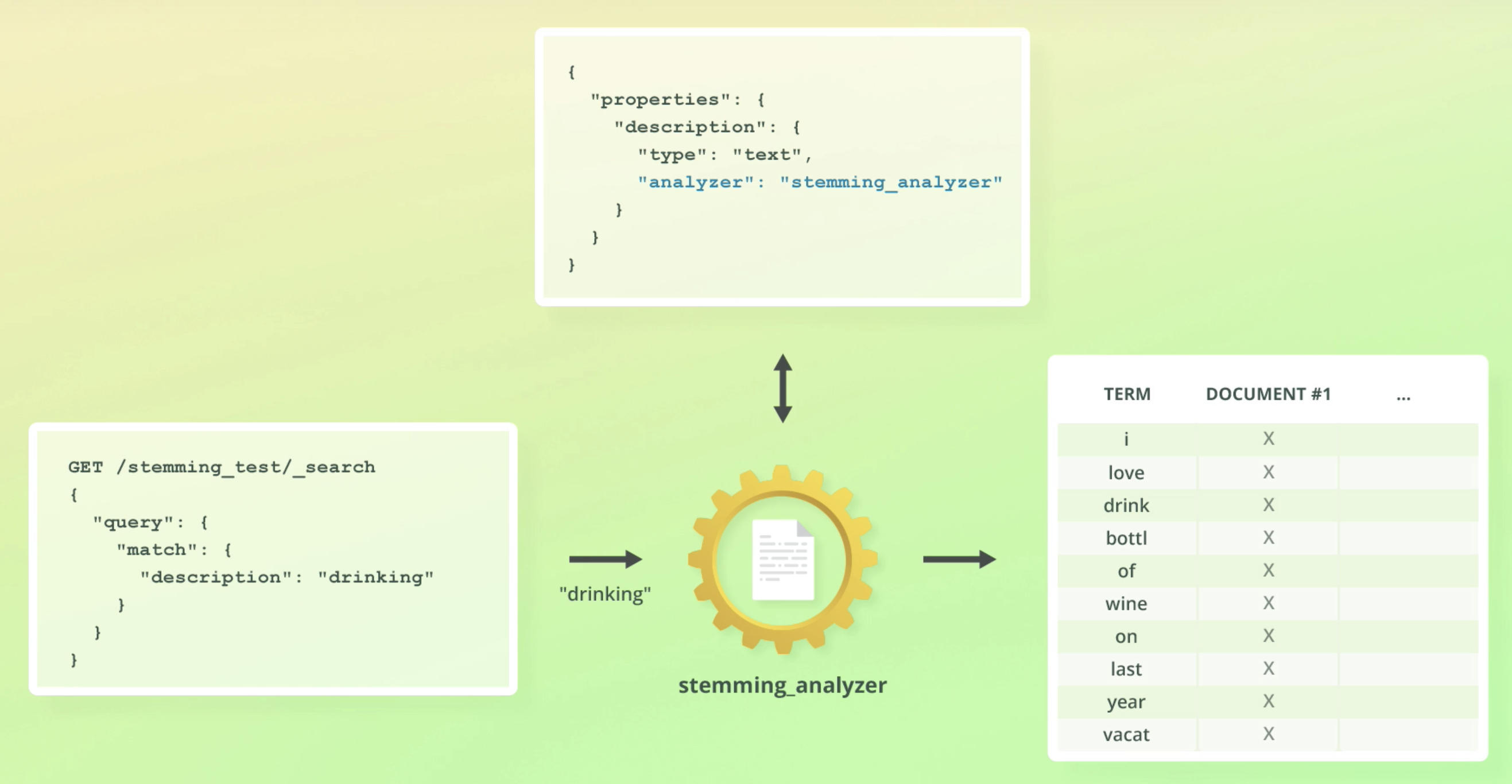
- 예를 들어 stemming이 들어간 analyzer를 사용해서 인덱싱 했으면, search 쿼리때도 똑같은 analyzer가 사용된다. "I loved drinking"이 stemming되어 drink라 저장됐으니, drinking으로 검색하면 안걸릴 것 같지만, 쿼리또한 stemming되어 내부적으로는 drink로 검색된다.
Built-in analyzers
standard analyzer
- Splits text at word boundaries and removes punctuation
- Done by the standard tokenizer
- Lowercases letters with the lowercase token filter
- Contains the stop token filter(disabled by default)

simple analyzer
- similar to the standard analyzer
- splits into toknes when encountering anything else then letters
- lowercases letters with the lowercase tokenizer
- Unusual and a performance hack
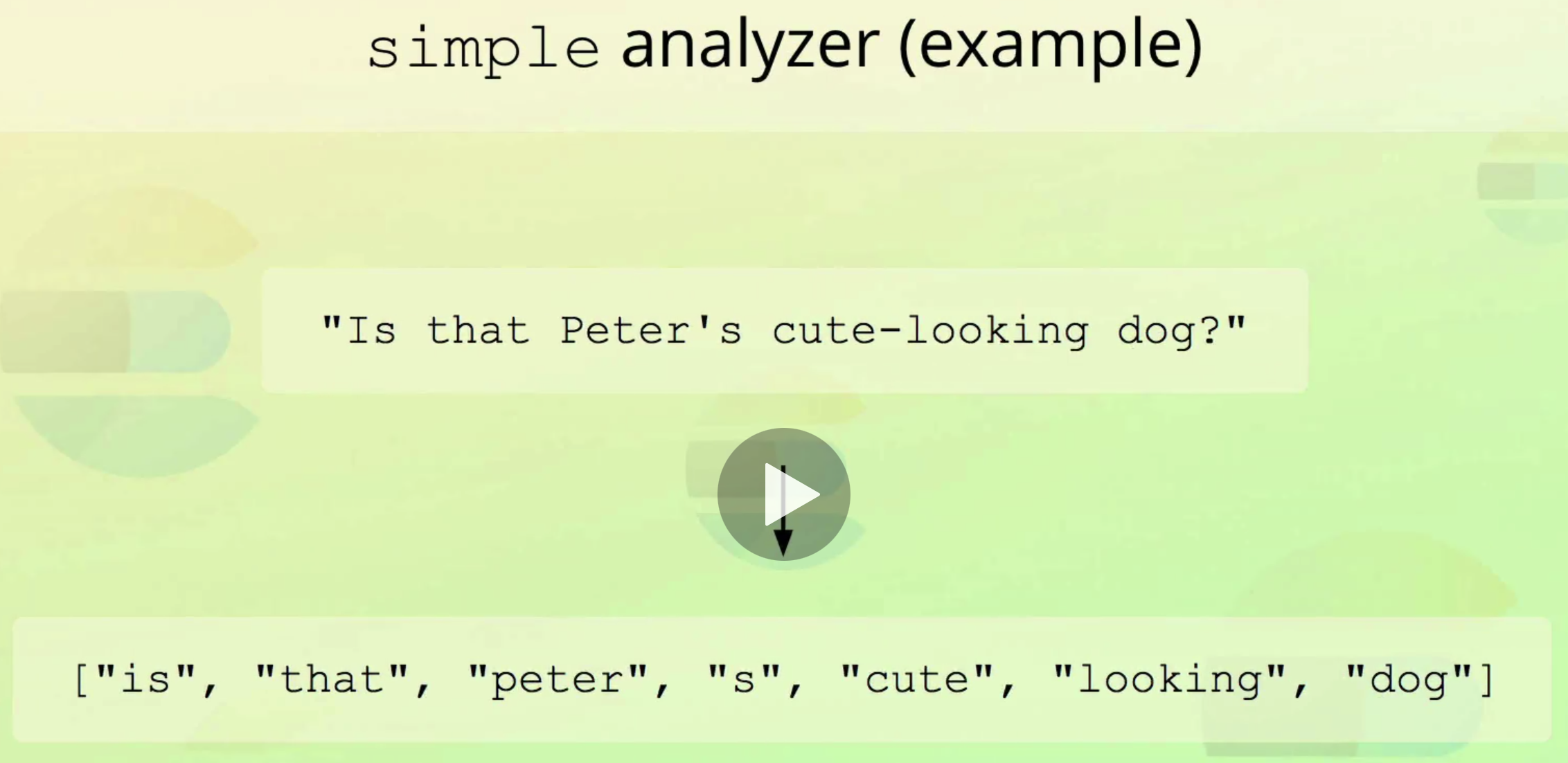
- Unusual and a performance hack
whitespace analyzer

keyword analyzer
- No-op analyzer that leaves the input text intact(아무것도 안해줌)
- It simply outputs it as a single token
- Used for keyword fields by default
- Used for exact matching
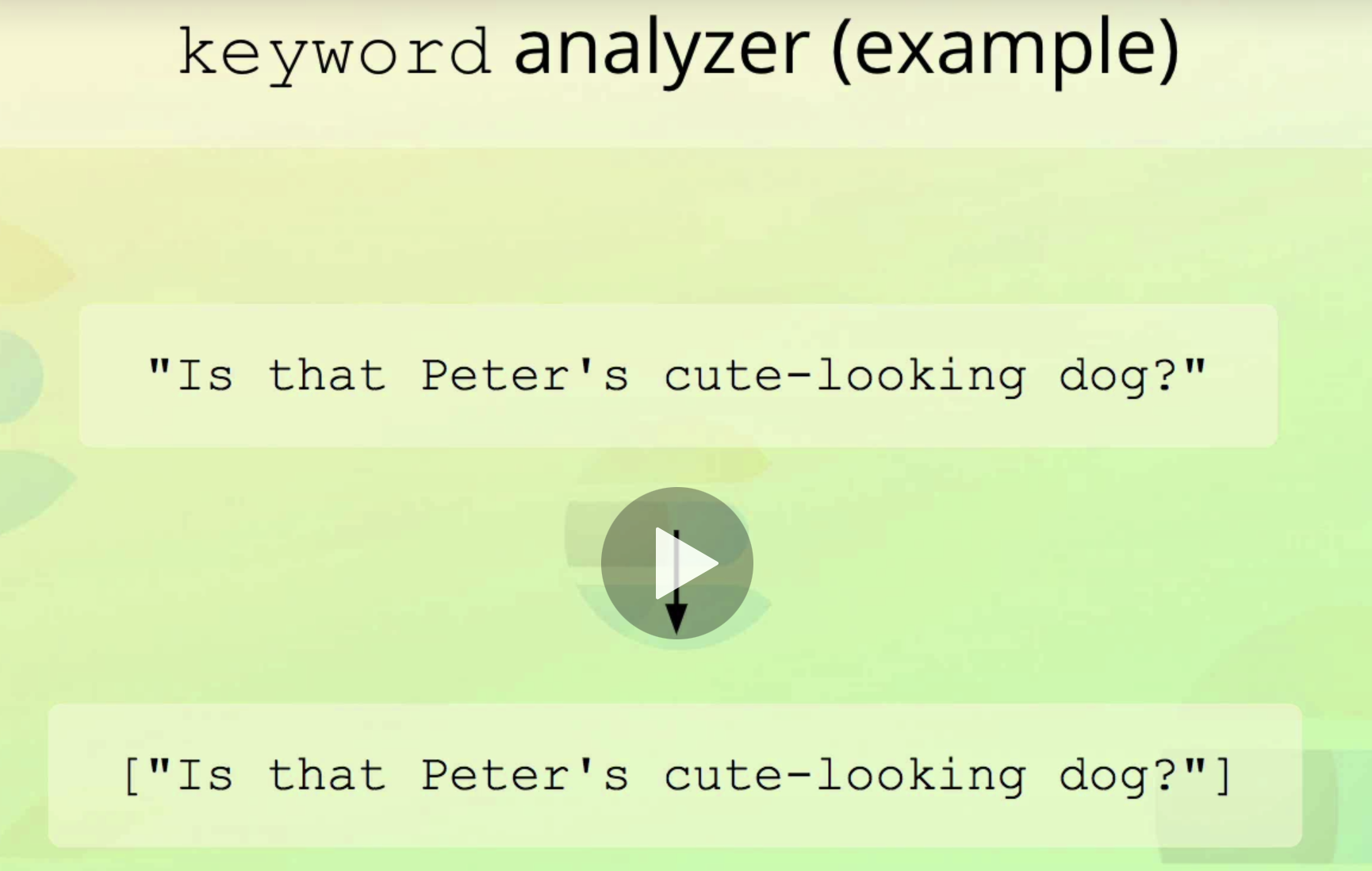
- Used for exact matching
pattern analyzer

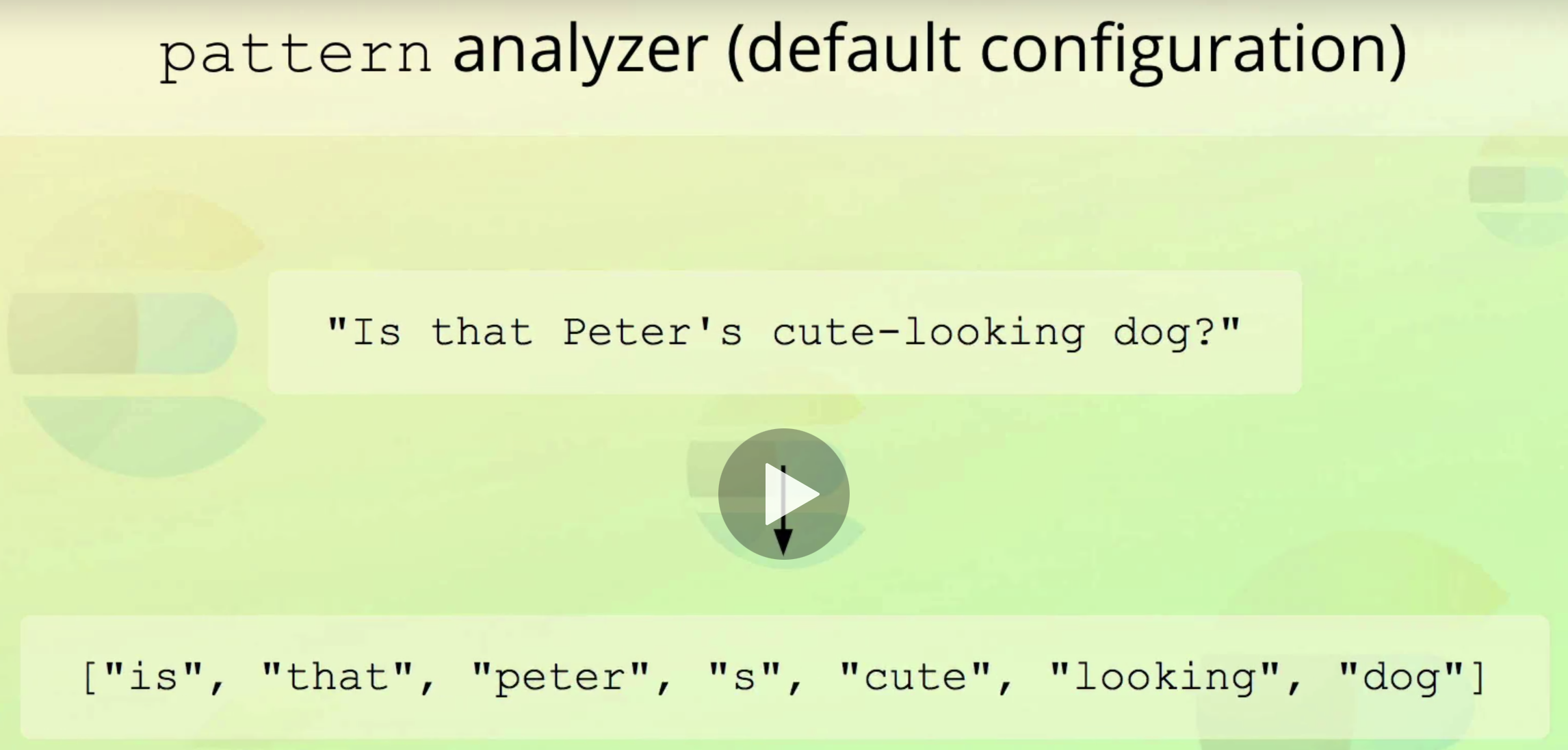
etc
- 이외에도 여러 analyzer들이 있고, param도 넘길 수 있다. 필요할 때 공식문서 확인.
Creating custom analyzers
Adding analyzers to existing indices
pass. 나중에 다시 듣기.
Updating analyzers
pass. 나중에 다시 듣기.
출처
출처: udemy Bo Andersen의 Complete Guide to Elasticsearch 강의.
https://www.udemy.com/course/elasticsearch-complete-guide/learn/lecture/7585356#overview
