주절주절
0730 in
0100 out
-파이썬 크롤링 재미 들렸다. 유튜브 보면서 여러가지 따라해봤다.
-코드에 대한 이해도는 80%정도? 좀 더 해야된다.
-git을 이해하기 위해 생활코딩 git 강의를 수강했는데, 도움이 많이 된다.
-하루가 너무 짧다. 5시간만 더 있었으면.
-크롤링 과제는 어떻게 하는건지 잘 모르겠다.
-내일은 selenium에 대해 집중적으로 공부할 예정.
requests module
-http요청을 보내는 모듈
기본사용예제
import requests
URL = 'http://www.tistory.com'
response = requests.get(URL)
response.status_code
response.text
response.encoding # -> utf-8출처: https://dgkim5360.tistory.com/entry/python-requests [개발새발로그]
statue_code는 http상태코드다.
200이면 정상.
아래 사이트에 잘 정리되어있다.
https://developer.mozilla.org/ko/docs/Web/HTTP/Status
BeautifulSoup
-Requests는 문자열만 반환할 뿐 정보를 잘 추출하기 어렵다.
beautifulsoup이 html코드를 pythondl 이 이해하는 객체 구조로 변환하는 parsing역할을 한다.
사용법
import requests
from bs4 import BeautifulSoup
req = requests.get('https://beomi.github.io/beomi.github.io_old/')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
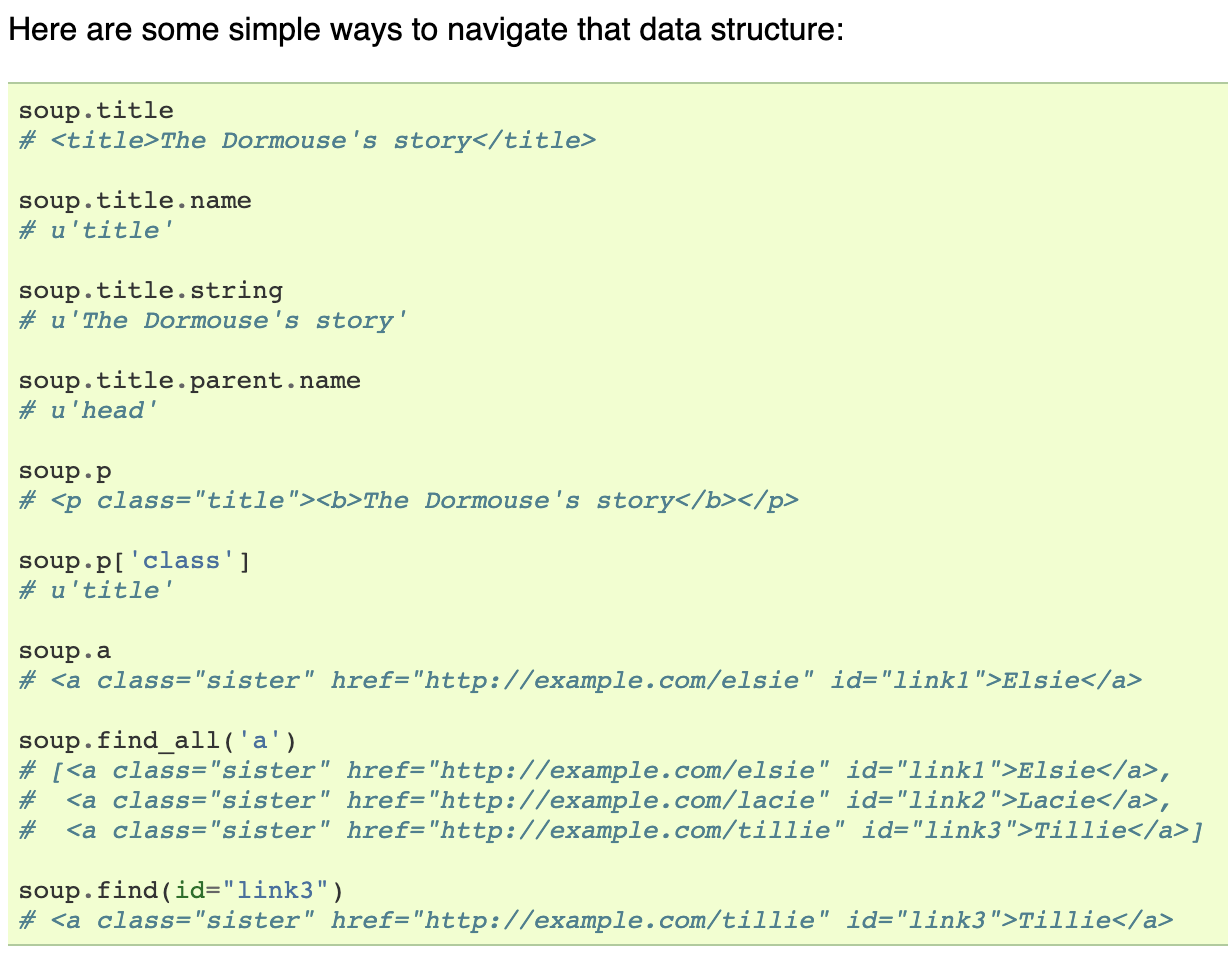
-.find_all로 뽑아낸 정보는 리스트 자료형에 담겨있다.
아래 페이지에 매우 잘 정리되어 있다.
https://twpower.github.io/84-how-to-use-beautiful-soup
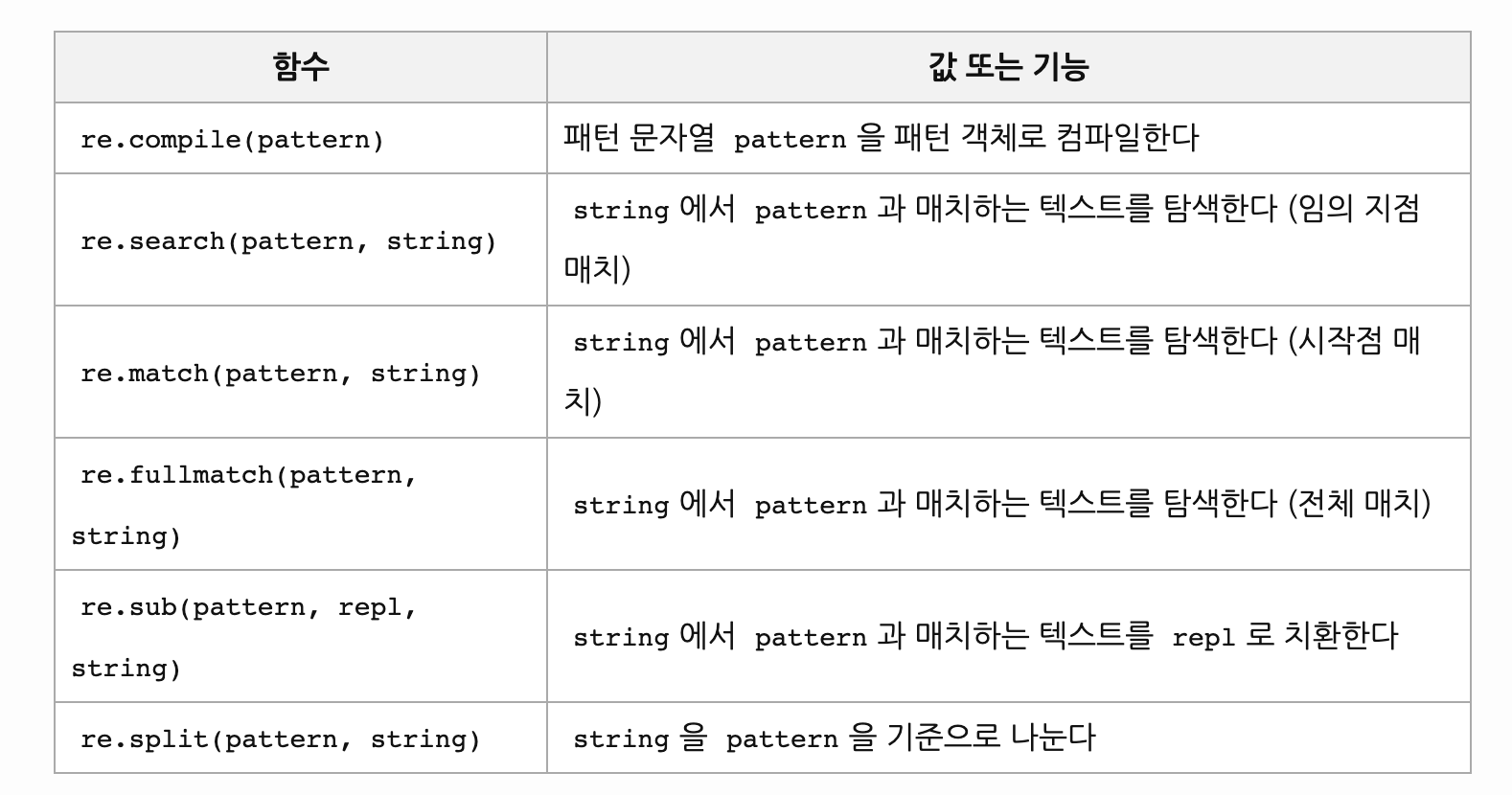
re
아래 페이지 참조.
https://python.bakyeono.net/chapter-11-2.html
python CSV
comma-separated values
예제코드
import csv
f=open('sample.csv','w',encoding='utf-8', newline='')
wr = csv.writer(f)
wr.writerow([1,2,3])
f.close()1.csv는 기본내장모듈이기에 따로 설치 안해도 된다.
jsut import csv
2.먼저 파일을 열어줘야 한다.
f=open('sample.csv','w',encoding='utf-8', newline='')
파일이름-sample.csv(확장자:csv)
기능: 읽기(w)
엑셀에서 열 땐 encoding을 CP949, MS949, EUC-KR중 하나로 해야 안 깨짐.
윈도우즈에서 csv파일 열 때 줄바꿈 문제가 생기는데 newline넣어주면 문제 해결된다함.
3.wr = csv.writer(f)
-csv모듈의 writer기능을 불러와서 f에 사용하겠다.
그걸 wr라는 변수에 할당.
4.wr.writerow([1,2,3])
5.파일을 닫아줘야 한다.
f.close()
6.결과
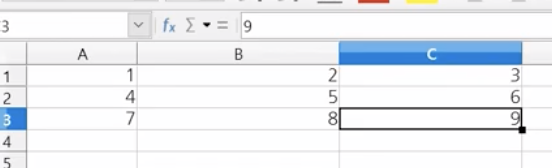
writerow, writerows
- writerow([[1,2,3],[4,5,6],[7,8,9]])

- writerows([[1,2,3],[4,5,6],[7,8,9]])
w, a, r
-w는 새로 write하는 것이다.
-a는 기존 파일에 내용을 add하는 개념.
-r은 파이썬으로 읽어오는 것.
f=open('sample.csv','w',encoding='utf-8', newline='')
rd = csv.reader(f)
for i in rd:
print(i)팁
-메모장에서도 열 수 있다.
빌보트 차트 top100 크롤링
from bs4 import BeautifulSoup
import requests
import re
import csv
bbd = open("bbd.csv","w+",encoding="utf-8")
wr=csv.writer(bbd)
wr.writerow(('num','song','singer'))
url = "https://www.billboard.com/charts/hot-100"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
li = soup.find_all("li", {"class":"chart-list__element display--flex"})
for i in li:
num = i.find_all("span", {"class":"chart-element__rank__number"})
song= i.find_all("span", {"class":"chart-element__information__song text--truncate color--primary"})
singer=i.find_all("span", {"class":"chart-element__information__artist text--truncate color--secondary"})
print(num[0].text,song[0].text,singer[0].text)
wr.writerow((num[0].text,song[0].text,singer[0].text))네이버 블로그 검색 크롤링(검색어 input시 블로그 1페이지 제목 출력)
import urllib.parse
urllib.parse.quote_plus(내용)
urllib.parse.quote_plus(string, safe='', encoding=None, errors=None)
quote()와 유사하지만, URL로 이동하기 위한 쿼리 문자열을 만들 때 HTML 폼값을 인용하는 데 필요한 대로 스페이스를 더하기 부호로 치환하기도 합니다. safe에 포함되지 않으면 원래 문자열의 더하기 부호가 이스케이프 됩니다. 또한 safe의 기본값은 '/'가 아닙니다.
예: quote_plus('/El Niño/')는 '%2FEl+Ni%C3%B1o%2F'를 산출합니다.
from bs4 import BeautifulSoup
import requests
import urllib.parse
Baseurl = "https://search.naver.com/search.naver?where=post&sm=tab_jum&query="
plusurl = input('검색하세요')
url =Baseurl+urllib.parse.quote_plus(plusurl)
html = requests.get(url)
url_text = html.text
soup = BeautifulSoup(url_text, "html.parser")
text = soup.find_all("a", {"class":"sh_blog_title _sp_each_url _sp_each_title"})
for i in text:
print(i.text)
print(i['href'])인스타 검색 시 나오는 사진 크롤링(내컴퓨터에 저장)
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import time
base_url = "https://www.instagram.com/explore/tags/"
plus_url = input()
url = base_url + quote_plus(plus_url)
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(url)
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
insta = soup.select(".v1Nh3.kIKUG._bz0w")
n = 1
for i in insta:
print('https://www.instagram.com'+ i.a['href'])
imgUrl = i.img['src']
with urlopen(imgUrl) as f:
with open('./img/' + plus_url + str(n)+ '.jpg', 'wb')as h:
img = f.read()
h.write(img)
n += 1
driver.close()네이버 사진검색 크롤링
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.parse import quote_plus
import requests
base_url = "https://search.naver.com/search.naver?where=image&sm=tab_jum&query="
plus_url = input()
my_url = (base_url + quote_plus(plus_url))
html = urlopen(my_url).read()
soup = BeautifulSoup(html, "html.parser")
img = soup.find_all("img", {"class":"_img"})
n = 1
for i in img:
img_url=i['data-source']
with urlopen(img_url) as f:
with open(plus_url + str(n) + '.jpg', 'wb') as h:
img = f.read()
h.write(img)
n += 1
print("다운 완료")이해가 안되는 건, with urlopen(img_url) as f:
요문장을 with requests.get(img_url) as f로 하면
Traceback (most recent call last):
File "pohto.py", line 23, in <module>
img = f.read()
AttributeError: 'Response' object has no attribute 'read'이런 오류가 뜬다. 뭘까......
---------바로 해결됐다. 위코드 선배 백엔드 고수분의 도움으로.
바로 포스팅
문제의 해결
일단 해결 코드는 아래처럼 하면 된다.
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.parse import quote_plus
import requests
base_url = "https://search.naver.com/search.naver?where=image&sm=tab_jum&query="
plus_url = input()
my_url = (base_url + quote_plus(plus_url))
html = urlopen(my_url).read()
soup = BeautifulSoup(html, "html.parser")
img = soup.find_all("img", {"class":"_img"})
n = 1
for i in img:
img_url=i['data-source']
with requests.get(img_url) as f:
with open(plus_url + str(n) + '.jpg', 'wb') as h:
img = f.raw.read()
h.write(img)
n += 1
print("다운 완료")requests vs urlopen
문제의 키는 이 둘의 차이에 있다.
먼저, urlopen은 단순히 해당 url의 바이너리 형태를 출력해준다.
urlopen으로 해서 받은 값 자치게 바이너리다.
하지만 requests로 얻은 데이타는 response객체다.
response객체는 많은 속성들을 포함하고 있는 객체다.
때문에 텍스트를 얻기 위해선 .text를 써줘야 한다.
urlopen은 urlopen(my_url).read()로 바로 읽게 할 수 있다.
문제의 코드부분)
with urlopen(img_url) as f:
with open(plus_url + str(n) + '.jpg', 'wb') as h:
img = f.read()위 코드는 작동했지만,
with requests.get(img_url) as f:
with open(plus_url + str(n) + '.jpg', 'wb') as h:
img = f.read()위 코드에서 requests.get은 response객체기 떄문에 f.read()로 못읽는다.
requests에서 바이너리로 읽는 문법에 맞게 f.raw.read() 요렇게 해줘야 한다.
아싸 해결.
네이버 블로그 여러페이지 크롤링(검색하면 블로그 제목과 url 따오기)
from bs4 import BeautifulSoup
import requests
import urllib.parse
plusurl = urllib.parse.quote_plus(input('검색어 입력하세요'))
i = input("몇페이지까지 출력 하실래요?")
num = 1
n = 1
last_page = int(i) * 10 - 9
while num <= last_page:
url = f"https://search.naver.com/search.naver?date_from=&date_option=0&date_to=&dup_remove=1&nso=&post_blogurl=&post_blogurl_without=&query={plusurl}&srchby=all&st=sim&where=post&start={num}"
html = requests.get(url)
url_text = html.text
soup = BeautifulSoup(url_text, "html.parser")
text = soup.find_all("a", {"class":"sh_blog_title _sp_each_url _sp_each_title"})
print(f"{n}페이지 내용입니다---------")
for i in text:
print(i.text)
print(i['href'])
print()
n += 1
num += 11