0745 in
2215 out
페이스북 로그인
페이스북 로그인
from selenium import webdriver
driver = webdriver.Chrome(executable_path="")
driver.get(url)
driver.find_element_by_id("email").send_keys("아이디")
driver.find_element_by_id((pass)).send_keys("비번")
driver.find_element_by_id(("u_0_b").click())
#driver.find_element_by_xpath()
selenium
1.
https://l0o02.github.io/2018/06/13/selenium-with-beautifulsoup-1/
https://www.fun-coding.org/crawl_advance3.html

Web Driver 가 현재 실행중인 웹 사이트의 소스를 가져오려면 아래 소스를 입력해야 한다. req = driver.page_source
그다음 html긁으려면 이렇게. soup=BeautifulSoup(req, 'html.parser')
Copy -> Copy Selector로 div의 id딴다.
information_list = soup.select("#intro_container_id")
for information in information_list:
print(information.text)selenium 문법들
from selenium import webdriver
driver = webdriver.Chrome(executable_path="") 크롬드라이버 위치지정
driver.get(url) 크롤링할 사이트 호출
req = driver.page_source 페이지 소스 가져오기
find_element_by_class_name() : class name이 입력한 값과 일치하는 것 중에서 가장 먼저 발견된 한 개만 가져옴
find_elements_by_class_name() : class name이 입력한 값과 동일한 모든 것을 리스트로 가져옴
page_height = int(driver.execute_script("return document.body.scrollHeight")) 스크롤 해야되는 페이지의 총길이 구하는 코드
driver.execute_script("window.scrollTo(0, " + str(scrollPosition) + ");") 스크롤 내리기 코드
window_page_height = int(driver.execute_script("return window.innerHeight")) 윈도우 페이지 높이 구하는 코드
스크롤 내리기(for문으로 반복횟수 정하면 얼만큼 내릴지 조절가능)
body = driver.find_element_by_css_selector("body")
keys = body.send_keys(Keys.PAGE_DOWN)driver.back() 페이지 뒤로가기
-코드해설: search가 찾은 곳(검색창)에, 그곳에 가서 test라고 쓴 뒤, return(enter)버튼을 눌러라.
search = driver.find_element_by_name("s")
search.send_keys("test")
search.send_keys(Keys.RETURN)-print(driver.page_source)
해설: driver가 찾은 페이지의 모든 html을 프린트
-print(driver.title) 해당 사이트 이름 가져오기 기능.
-from selenium.webdriver.common.keys import Keys 브라우저상에서 키보드 동작을 할수 있게 해주는 기능..
mydata = driver.find_element_by_class_name('list_title') # 클래스 명이 list_title인 모든 것을 리스트로 가져와서 mydata에 할당

출처: https://cceeddcc.tistory.com/98
기본셋팅
from selenium import webdriver
PATH = "크롬드라이버주소"
driver = webdriver.Chrome(PATH)
driver.get("url")
driver.quit()driver.get('http://tieba.baidu.com/p/5513911529')
SCROLL_PAUSE_TIME = 0.5
SCROLL_LENGTH = 200
page_height = int(driver.execute_script("return document.body.scrollHeight"))
scrollPosition = 0
while scrollPosition < page_height:
scrollPosition = scrollPosition + SCROLL_LENGTH
driver.execute_script("window.scrollTo(0, " + str(scrollPosition) + ");")
time.sleep(SCROLL_PAUSE_TIME)csv 강의 정리
CSV: comma separated value
open은 파일을 열어주는 기능, 파일이 없다면 새로 생성해준다.
names.csv파일이 이미 존재한다 치자. 아래와 같이.
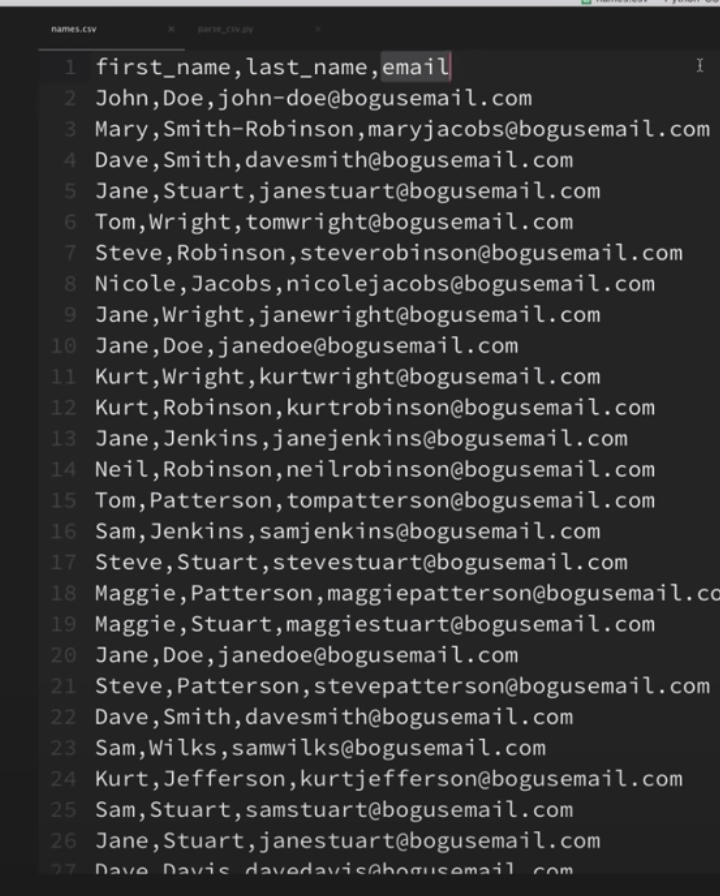
이것을 읽어들이기 위해 아래처럼 해야된다.
import csv
with open('names.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
print(csv_reader)요게 기본이다.
-with open안에 이름, 확장자, 기능(r=read)를 적어준다.
-as csv_file에서 as뒤에 파일 이름을 적어준다.
-csv.reader(파일이름)은 csv함수다. 말 그대로 csv파일 읽어준다. 파일 이름엔 방금 만든 파일 썻다.
-위 상태로 print(csv_reader)하면, <_csv.reader object at 0x1023e5eb8>같은게 출력된다. 지금 상태론 단지 메모리 속 object일 뿐이다.
-내용을 출력하고 싶다면 for loop에 돌려야한다.
import csv
with open('names.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
for line in csv_reader:
print(line)
결과는 아래와 같다.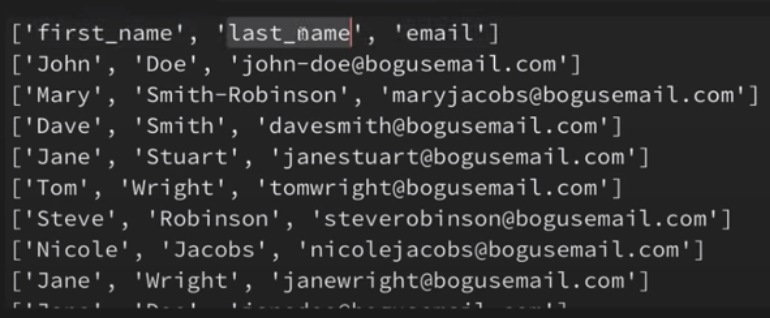
names.csv에서 인덱스는 다음과 같다. 0:firstname, 1:lastname, 2:email
이메일만 출력하고 싶다면 아래처럼 해주면 된다.
import csv
with open('names.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
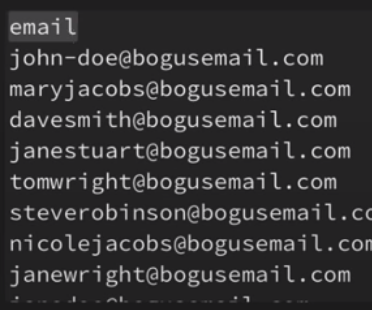
for line in csv_reader:
print(line[2])
결과
만약 맨 처음 email이라는 타이틀 뺴고 바로 메일주소부터 출력하고 싶다면?
generator처럼 next를 써주면 된다.
import csv
with open('names.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
next(csv_reader)
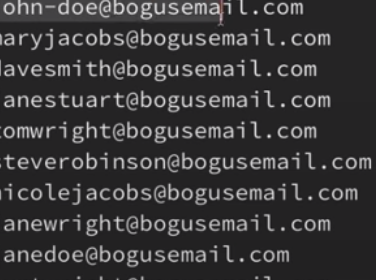
for line in csv_reader:
print(line[2])
결과
-이제 새로운 파일을 하나 만들고, 기존의 names.csv파일을 거기에 옮겨써주는 것을 해보자.
import csv
with open('names.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
with open('new_names.csv', 'w') as new_file:
csv_writer = csv.writer(new_file, delimiter='-')
for line in csv_reader:
csv_writer.writerow(line)
delimiter는 일부러 '-'를 써서 표현했다. 컴마가 더 좋은데, 일부러 불편함 느껴보라고.
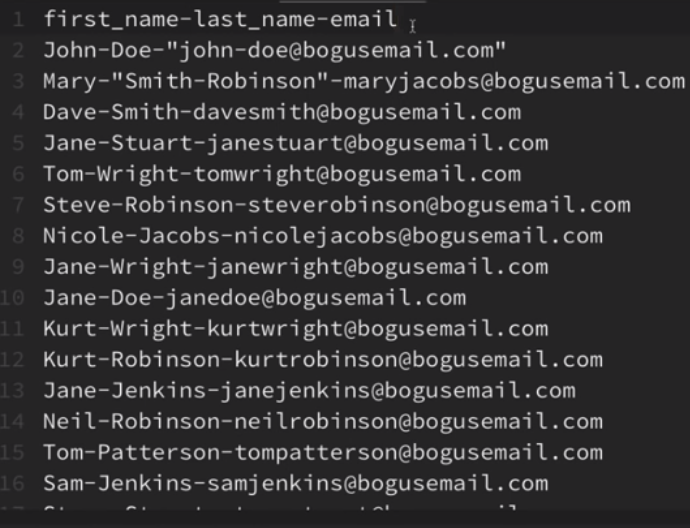
-delimiter를 탭으로 바꿔보자.
import csv
with open('names.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
with open('new_names.csv', 'w') as new_file:
csv_writer = csv.writer(new_file, delimiter='\t')
for line in csv_reader:
csv_writer.writerow(line)
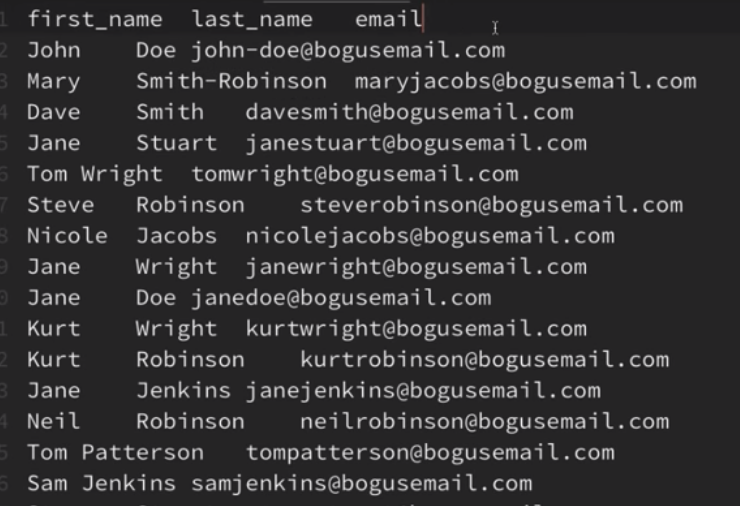
zip
[1,2,3,4,5], [a,b,c,d,e], [가,나,다,라,마]
이런 식으로 생긴 리스트를
1,a,가
2,b,나
...의 꼴로 만드려면 zip을 사용하면된다.
zip([1,2,3,4,5], [a,b,c,d,e], [가,나,다,라,마])
csv에 넣는 꿀팁.
웹은 어떻게 작동하는가 session
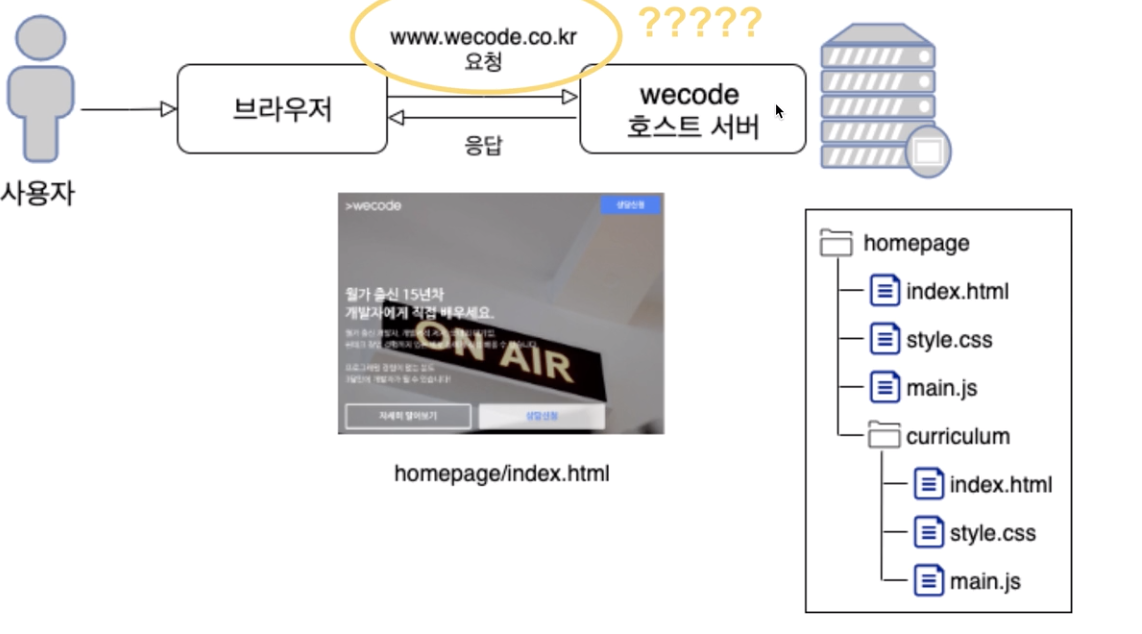
사용자의 요청에 서버가 응하려면, 요청받는 그 때에 서버상태가 on이어야만 한다.
24시간 중 사용자의 요청이 언제 올지는 아무도 모른다.
그러므로 호스트 서버는 항상 켜져있어야 한다.
이는 개인컴퓨터로 하기엔 한계가 있으므로, 전문 호스팅 업체가 필요하다.
Hosting(web hosting service)
인터넷에 띄운다는 것은 홈페이지의 구성파일들이(html,css,js)인터넷에 '항상'연결되고, '절대' 꺼지지 않는 호스트컴퓨터(웹서버)에 저장되어 있다가 사용자의 요청이 오면 언제든지 응답.
서비스예) 카페24, aws
IP
-internet protocol
-internet으로 통신하는 각 device(컴퓨터,통신장비)에 부여된 고유한 값.
-스마트폰, 노트북, 대규모 소매 웹 사이트의 컨텐츠를 서비스하는 서버에 이르기까지 인터넷상의 모든 컴퓨터는 숫자를 사용하여 서로 찾고 통신하며, 이러한 숫자를 ip주소라 한다.

Domain(Domain name)
-수많은 ip주소를 사람이 외워서 접속할 수는 없다. 그래서 생긴게 도메인.
-도메인은 string으로 된 고유 주소.
ex)www.wecode.com
-도메인은 돈 주고 사야된다. 일 년에 2만원 정도.

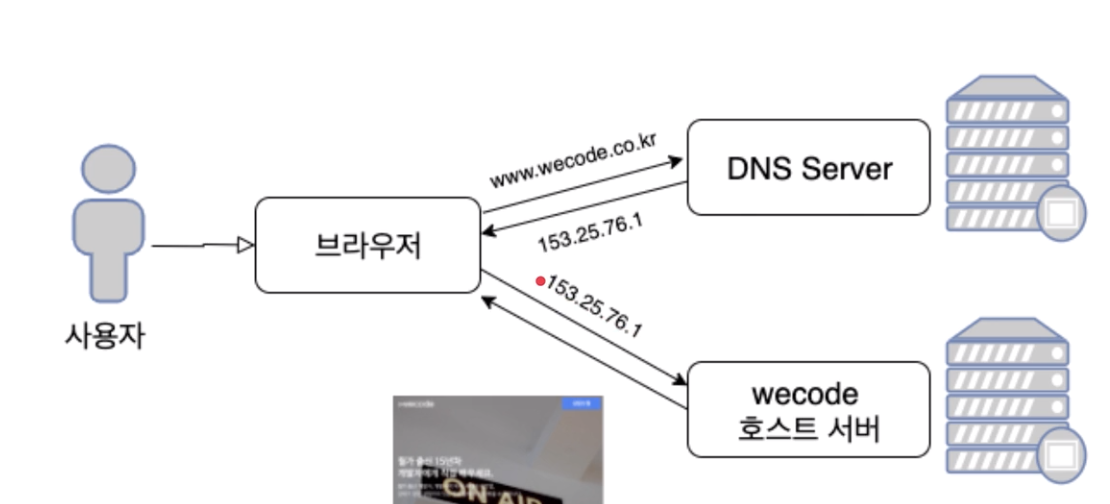
DNS(Domain Name System)
-DNS는 사람이 읽을 수 있는 도메인(www.wecode.com) 이름을 머신이 읽을 수 있는 ip주소(예:192.0.2.44)로 변환.
-DNS는 이름과 숫자 간의 매핑을 관리, 전화번호부 같은 역할.
DNS서버는 이름에 대한 요청을 IP주소로 변환, 최종 사용자가 도메인 이름을 웹 브라우저에 입력할 떄 해당 사용자를 어떤 서버에 연결할 것인지 제어한다. 이 요청을 쿼리라 한다.
예) Amazon Route 53, Cafe24 도메인관리, 가비아 네임서버 관리
*DNS서버는 도메인-서버를 연결해주는 중간서버. 도메인 이름을 인터넷상의 주소(ip주소)로 변환시켜 원하는 컴퓨터를 찾아갈 수 있도록 한다.
배포(번외)
배포(deply) 혹은 deploy한다 라는 말 자주 쓰인다.
배포란, 그동안 개발하던 것을 인터넷상에 공개하고 모든 사람이 접근할 수 있도록 하는 것.
네트워크 7계층 공부하기.
