그래프 신경망(Graph Neural Network, GNN)은 그래프 구조로 표현된 데이터를 분석하고 처리하기 위한 신경망의 한 종류이다.
1. 학습 과정 비교
| General Articial Neural Network | Graph Neural Network |
|---|---|
| 신경망 구조 정의 및 input 준비 | Aggregate, Concatenate 함수 정의 및 graph input 준비 |
| Loss function 정의 및 optimizer 결정 | Loss function 정의 및 optimizer 결정 |
| Loss가 0에 가까워지도록 신경망이 param 학습 | Loss가 0에 가까워지도록 신경망의 Aggregate, Concatenate param 학습 |
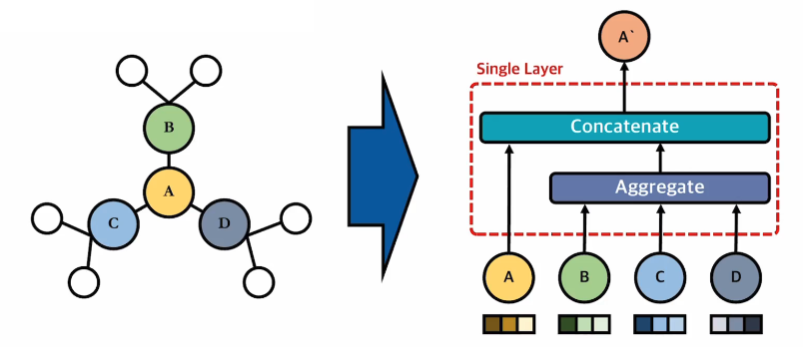
- Aggregate function: 주변 정점(=node)들이 정보를 집계해서 가져오는 함수
- Concatenate function: 자기자신의 정점 정보와 aggregate function을 통해 가져온 주변 노드의 정점 정보를 합치는 함수
2. Aggregate function, Concatenate function
대표적인 GNN중 하나인 GCN(Graph Convolutional Network)를 예로 설명하겠다.
- Neighborhoods Aggregation
target node(A)와 인접한 node를 이용해서 target node를 쇄신 하는 것. (
(Transformer의 self-attention과 비슷한 컨셉)
Single Layer에서 한 칸(1 step)의 주변 노드만 본다고 했을 때, aggregate function을 이용해 주변 노드 임베딩을 종합하고, target node와 임베딩과 합친다. (concatenate)
그렇다면 2겹의 GCN layer가 쌓이면 어떻게 될까?
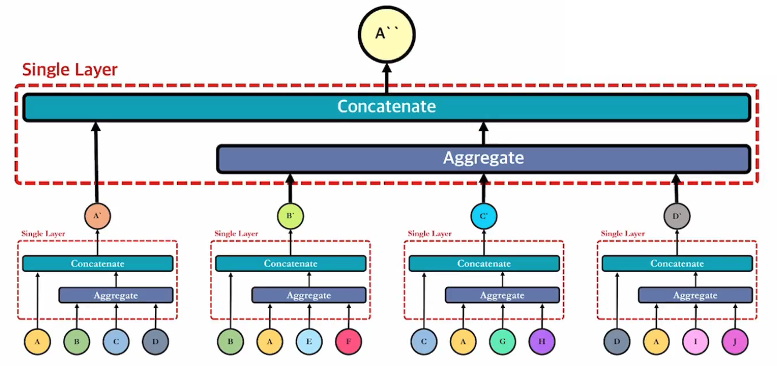 어? 그림이 이상한 것 같아. layer가 위에 1개, 아래에 총 4개가 있으니 총 5개의 layer가 아니냐고?
어? 그림이 이상한 것 같아. layer가 위에 1개, 아래에 총 4개가 있으니 총 5개의 layer가 아니냐고?
GCN(Graph Convolutional Network)의 경우 CNN과 같이 weight를 공유한다.
즉, single layer는 같은 weight로 모든 target node를 주변 노드 임베딩에 대한 aggregation과 concatenate에 대해 쇄신한다.
그렇다면, 첫 번째 layer를 통해 A, B, C, D는 A', B', C', D'로 쇄신 될 것 이다.
두 번째 layer도 target node를 A로 두었을 때 쇄신된 첫 번째 layer로 부터 얻은 B', C', D'의 임베딩을 aggregation하여 정보를 종합하고, A'와 concatenate를 하여 A''를 얻는다.
이제 어떻게 동작하는지는 알았다. 그렇다면 GCN layer를 여러 개 쌓는 것은 무슨 의미가 있는 걸까?
이것도 CNN layer에 빗대어 이해하면 쉽다. 작은 커널을 갖는 CNN layer를 생각해보자. 이 layer를 하나만 쌓을 때와 여러 개 쌓았을 때의 가장 큰 차이점이 뭘까? 바로 receptive field의 크기이다. 깊은 CNN layer 일수록 receptive field가 넓을 것이다.
GNN도 마찬가지다. layer가 깊어질수록 target node를 쇄신함에 있어 멀리 있는 정점정보 까지 활용할 수 있다. 그림을 보면 알겠지만 첫 번째 GCN으로 부터 얻은 A'는 A와 A의 주변 노드인 B, C, D의 정보를 활용하였다. 그리고 두 번째 GCN으로 부터 얻은 A''는 A'와 B', C', D'의 정보를 활용하였고, B', C', D'는 B, C, D 각각의 주변 노드 정보를 활용 하였으므로, A''는 B, C, D 뿐 아니라 B, C, D 각각의 주변 노드 (E, F, G, H, I, J)의 정보까지 활용한 것이다.
3. GCN(Graph Convolutional Network)
GCN연산은 아래 식으로 표현된다.
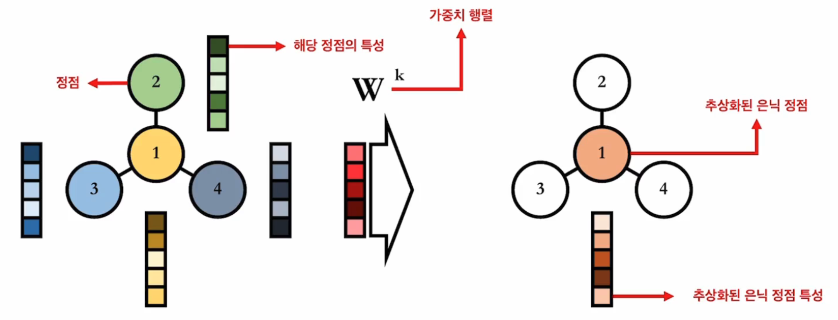
는 은닉 노드 특성 행렬, 는 합성곱 연산,
는 인접행렬, 는 특성행렬,
는 가중치 행렬, 는 비선형 활성화 함수 이다.
- 는 각 layer별로 공유한다. (CNN처럼 각 layer 별 동일한 가중치 사용)
- 기본적인 GCN은 간선(link) 특성은 사용되지 않는다.
- 먼저 그래프가 포함된 노드나 그래프 자체를 벡터 형태의 데이터로 변환하는 과정이 필요하다.
(1) 행렬 연산 예시
아래과 같은 그래프에 대해 연산해보자.
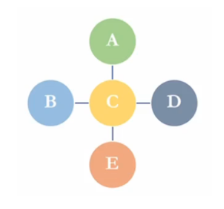
일 때,
인접 행렬은 아래와 같이 나올 것이다.
인접행렬() shape:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| A | 0 | 0 | 1 | 0 | 0 |
| B | 0 | 0 | 1 | 0 | 0 |
| C | 1 | 1 | 0 | 1 | 1 |
| D | 0 | 0 | 1 | 0 | 0 |
| E | 0 | 0 | 1 | 0 | 0 |
그리고 특성 행렬은 아래와 같다고 해보자.
특성행렬 () shape:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| A | 0 | 1 | 0 | 1 | 0 | 1 |
| B | 1 | 1 | 1 | 0 | 0 | 1 |
| C | 1 | 0 | 0 | 0 | 1 | 0 |
| D | 1 | 1 | 1 | 0 | 0 | 1 |
| E | 0 | 0 | 1 | 1 | 0 | 0 |
이제 를 구하기 위해 연산을 한다고 해보자.
이 때 는 학습 가능한 파라미터, 는 단순 비선형 함수이기 때문에 생략하고,
연산만 살펴본다면 결과는 아래와 같다.
: shape:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| A | 1 | 0 | 0 | 0 | 1 | 0 |
| B | 1 | 0 | 0 | 0 | 1 | 0 |
| C | 2 | 3 | 3 | 2 | 0 | 3 |
| D | 1 | 0 | 0 | 0 | 1 | 0 |
| E | 1 | 0 | 0 | 0 | 1 | 0 |
뭔가 이상하지 않은가?
A, B, C, D, E의 특성행렬()가 전부 다른데도, C를 제외하고 전부 똑같은 것을 볼 수 있다.
이는 인접 행렬의 한계로
- 인접 행렬에는 노드의 연결만 표현되어 있기 때문에 이를 바로 사용 할 경우 각 노드 자체에 대한 정보가 유실되는 현상이다.
- 또한 인접 행렬은 정규화 되어 있지 않기 때문에 특성 벡터와 곱 연산을 수행할 경우 크기가 불안정 하게 변할 수 있다.
이에 대한 해결방안으로
식 대신
아래와 같은 식을 도입하였다.
기존 식에서 가 로 바뀌고, 의 양 옆에 를 곱해주는 것으로 변환되었다.
하나씩 차근차근 살펴보자.
(1) 는 인접행렬()에 self-loop를 추가하여 정보가 유실되는 현상을 완화할 수 있다.
self-loop를 추가한 인접행렬() shape:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| A | 0 | 1 | 0 | 0 | |
| B | 0 | 1 | 0 | 0 | |
| C | 1 | 1 | 1 | 1 | |
| D | 0 | 0 | 1 | 0 | |
| E | 0 | 0 | 1 | 0 |
: shape:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| A | 1 | 1 | 0 | 1 | 1 | 1 |
| B | 1 | 1 | 1 | 0 | 1 | 1 |
| C | 3 | 3 | 3 | 2 | 1 | 3 |
| D | 1 | 1 | 1 | 0 | 1 | 1 |
| E | 1 | 0 | 1 | 1 | 1 | 0 |
에 비해 가 확실히 소실되는 정보가 줄어든 것을 볼 수 있다.
(2) 양 옆에 를 곱해줌으로써 를 정규화 한다.
는 의 차수행렬이다.
차수행렬() shape:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| A | 1 | 0 | 0 | 0 | 0 |
| B | 0 | 1 | 0 | 0 | 0 |
| C | 0 | 0 | 5 | 0 | 0 |
| D | 0 | 0 | 0 | 1 | 0 |
| E | 0 | 0 | 0 | 0 | 1 |
차수행렬() shape:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| A | 0 | 0 | 0 | 0 | |
| B | 0 | 0 | 0 | 0 | |
| C | 0 | 0 | 0 | 0 | |
| D | 0 | 0 | 0 | 0 | |
| E | 0 | 0 | 0 | 0 |
이므로,
는 아래와 같은 행렬로 나타낼 수 있다.
| A | B | C | D | E | |
|---|---|---|---|---|---|
| A | 0 | 0 | 0 | ||
| B | 0 | 0 | 0 | ||
| C | |||||
| D | 0 | 0 | 0 | ||
| E | 0 | 0 | 0 |
특정 노드에서 차수가 높은 노드의 값은 더 작아지고, 차수가 낮은 정점의 값은 비교적 덜 작아진 것을 볼 수 있다.
위 행렬에 특성행렬을 곱한 것을 input으로 학습을 진행한다면, 정점별 간선의 개수 (이웃한 노드의 수)와 상관없이 모든 노드별 정보를 고르게 반영하여 학습이 가능할 것이다.
최종적으로, 에 를 곱하면 아래와 같은 행렬을 얻을 수 있다.
shape:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| A | 0 | |||||
| B | 0 | |||||
| C | ||||||
| D | 0 | |||||
| E | 0 | 0 |
(2) GCN 수식
위와 같은 GCN layer 연산 과정을 수식으로는 아래와 같이 표현할 수 있다.
- 는 번째 층 GCN layer의 출력이다.
- 는 이전 층 GCN layer의 출력이다.
위 식을 응용해 각 를 번째 GCN layer에 통과시킨다면,
(3) Layer 구성
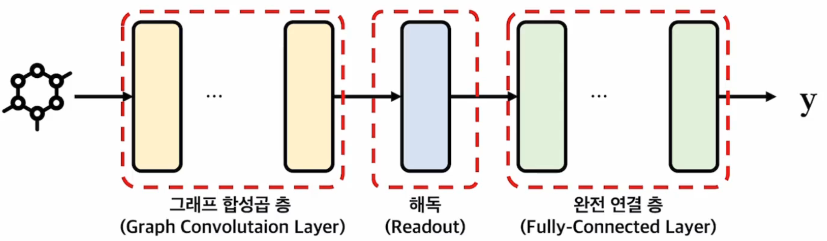 일반적으로 GCN layer와 FC layer로 구성된다.
일반적으로 GCN layer와 FC layer로 구성된다.
GCN은 위에서 설명했고, FC layer는 다들 알텐데 Readout이 뭘까
Readout은 GCN의 output으로 나오는 그래프 matrix를 FC layer의 input으로 잘 입력될 수 있게 변환해주는 역할을 한다.
따라서, 분류 및 회귀 문제와 같이 그래프를 종합하여 어떤 하나의 예측값을 얻고자 하는 경우에는 Readout을 필요로 한다.
해당 게시글의 내용과 첨부파일의 출처는 LAIDD의 약물최적화를 위한 분자그래프 기반 AI기술 강의에서 2강. 그래프의 응용: 그래프 신경망 에 있음을 밝힙니다.
