Summary
-
DETR는 Object detection task에서 Transformer를 도입한 모델 입니다.
ViT처럼 이미지 자체를 Transformer에 적용하는 방식은 아니며, CNN backbone (ResNet50)을 통과한 feature map들을 flatten하여 Transformer의 입력으로 넣는 구조입니다. -
이전에 등장했던 Faster RCNN 계열이나, Yolo와는 달리 anchor box가 없어 architecture나 loss function을 구하는 코드가 굉장히 깔끔합니다.
-
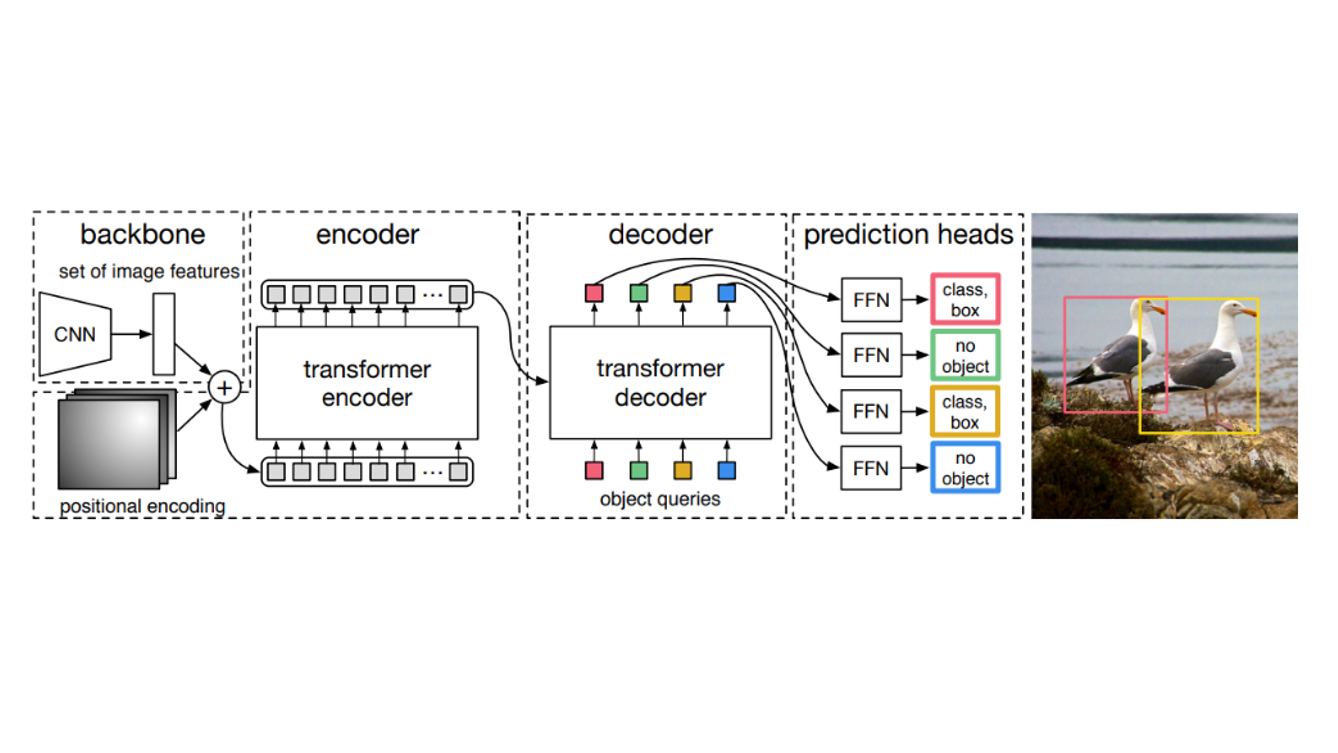
학습 시에는 위 그림처럼 각각의 Transformer decoder layer로 부터 얻은 output으로 class, bbox를 예측하여 loss 계산 및 모델을 업데이트 하지만, 추론 단계에서는 마지막 decoder layer에서 나온 class, bbox 만을 사용합니다.
-
성능은 Faster RCNN+ 모델과 비슷합니다. (COCO val)
-
특히 큰 객체의 탐지에는 더 강한 모습을 보이나 (높은 ), 작은 객체 탐지에는 약한 모습을 보입니다.
1. Introduction
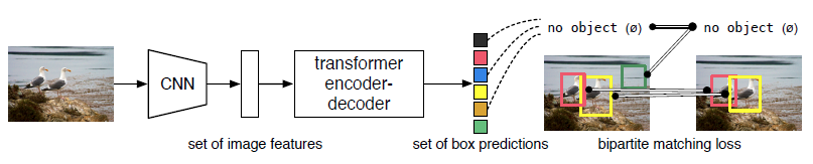
-
그 동안의 Object detection 분야에서는 proposals나 anchor 그리고 NMS(Non-maximum Suppression)와 같은 anchor box 관련 여러 전후처리 기법들을 적용하였고 이는 꽤 복잡했습니다. 저자들은 다른 분야들(Image classification, Semantic segmentation)처럼 Object detection도 이런 복잡한 전후처리 과정이 없는 end-to-end 모델을 만들고자 하였습니다.
-
그 동안 많은 Object detection 모델에서 NMS를 사용했던 이유는 anchor box 위치 기반으로 예측 bbox가 조정되기 때문에 비슷한 예측을 하는 bbox가 상당히 많고, 모델의 예측이 ground truth와 1:1로 대응하지 않기 때문입니다. 그리고 모델의 이러한 예측의 원인은 탐지 성능을 높이기 위해 도입된 proposals나 anchor 때문입니다.
-
Anchor box 없애기
저자들은 미리 anchor box를 정의하고, 그것을 조정하여 객체를 탐지하는 이전 방식과 달리 미리 몇 개의 객체를 찾을 지만 정해두고 anchor box 없이 모델이 알아서 어떤 위치에 어떤 객체가 있는 지를 찾도록 하였습니다.
제 생각에 이게 가능한 이유는 CNN과 다르게 attention을 통한 global context 정보를 활용할 수 있기 때문에 anchor box가 부여하는 정보 ("어디에 어떤 객체가 있을 것이다.") 없이도 전역 정보를 보면서 찾고자 하는 객체를 추릴 수 있기 때문이지 않을까 생각합니다. -
NMS 없애기
Anchor box를 버렸지만, 몇 개의 객체를 찾을 지는 정해두었고 또한 이미지 마다 객체의 수가 다르기 때문에 Loss 계산을 위해서는 모델의 예측과 1:1로 대응 시키는 작업이 필요했습니다. 여기서 DETR의 저자들은 NMS 대신 Hungarian Algorithm을 도입하여 모델의 예측과 ground truth가 1:1 대응 (bipartite matching) 하게 함으로써 NMS 또한 버릴 수 있었습니다.
- 결과적으로 복잡한 전후처리 과정이 없는 end-to-end object detection 모델이 만들어졌습니다.
- 모델의 이름은 DEtection TRansformer의 약자로 DETR로 명명하였습니다.
2. Method
-
Architecture
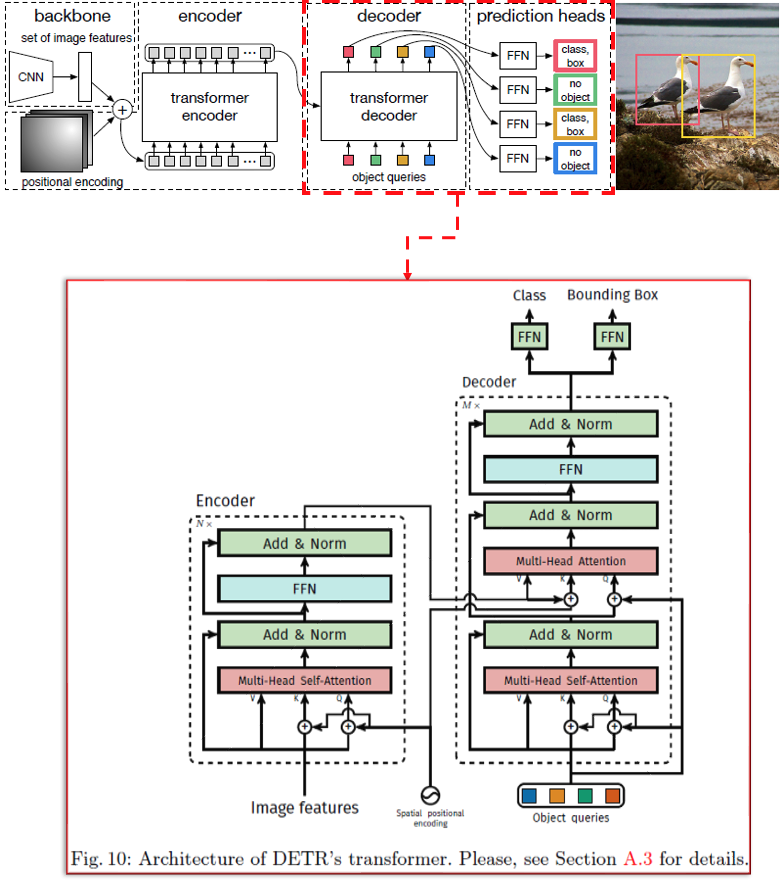
DETR는 Transformer의 구조를 거의 그대로 차용하였고, Backbone으로는 ResNet을 사용하였습니다. 따라서 구조 설명은 생략하고, 기존 CNN 기반 detector와는 다른 부분인 Image features 준비 과정과 Object queries를 알아보겠습니다.
Image features
(1) ResNet을 통과한 feature map들을 linear projection
(2) Flatten & Permute
(3) Positional encoding을 더하기()
(4) Transformer에 input으로 넣기
Object queries
구조적으로 Object queires는 학습 가능한 n개의 고정 벡터 입니다.
학습이 진행되면서 자신이 주목할 부분을 찾는 역할을 합니다.
암묵적인 Anchor 역할을 한다고 이해하면 쉽습니다.
Anchor-free dectector인 DETR에서 anchor 없이도 각 query가 하나의 객체를 담당하도록 학습됩니다.
Auxiliary decoding losses
학습할 때는 마지막 decoder layer의 output뿐 아니라, 모든 decoder layer와 output에 대해 loss 계산 및 학습에 참여하게 하였습니다. Auxiliary decoding losses
DETR에서 Auxiliary decoding losses를 도입하는 이유는 gradient가 중간중간 decoder layer에서 잘 전달되게 하기 위함입니다.
그렇다면 왜 Auxiliary decoding losses가 없으면 gradient가 중간중간 decoder layer에 잘 전달되지 않을까요?
Loss는 객체가 매칭된 일부 query에만 적용 됩니다. 뒤에 Cost function에서 설명하겠지만, DETR 구조상 Hungarian Matcher를 이용해 pred와 gt를 1:1 매칭 시킨 후에 Loss를 계산합니다.
그리고 학습 초기 대부분의 query들은 "no object"로 분류되기 때문에 대부분의 query는 학습 신호가 매우 약하기 때문입니다. 즉, 초반에 맞는 query가 거의 없어서 어디를 봐야 할 지를 배울 수 없기 때문에 수렴이 매우 느려집니다.
-
Cost function - Hungarian Matcher
위에서 설명한 것처럼 DETR는 proposals나 anchor box가 없습니다. 대신 몇 개를 예측할 지를 hyperparameter로 지정해주는데요. 만약 100개라고 지정했다면, output shape은 bbox, class label 각각 , 이 됩니다.
Loss를 구하기 위해서는 먼저 100개의 pred를 gt와 1:1로 매칭 시켜야 합니다. 이 과정에서 Hungarian algorithm이 사용됩니다. Loss를 구하기 전에 이런 매칭과정이 이루어 지는데요. 이 과정 Loss function와 구분짓기 위해 Hungarian Matcher로 명명하겠습니다.
Hungarian Matcher를 이용해 preds와 gt를 1:1로 매칭하는 과정은 아래와 같습니다. DETR이 예측하는 bbox를 100개라고 지정했다면,
(1) DETR의 output shape:
(2) 반면 gt의 shape은 일 것입니다. 따라서 background를 추가하여 100를 채워줍니다. (padding의 개념과 유사합니다.)
(3) 둘 다 shape이 같으므로 hungarian algorithm을 이용해 pred와 gt를 1:1로 매칭해줍니다.
(4) 이 때 사용되는 Cost 함수는 아래와 같습니다.
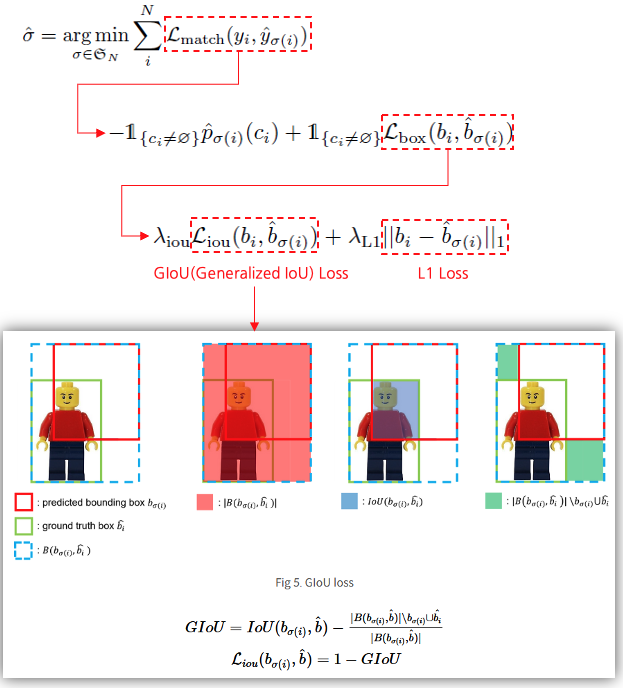 그림 출처: https://herbwood.tistory.com/26
그림 출처: https://herbwood.tistory.com/26
주의할 점은 Hungarian Matcher는 학습을 위한 Loss function이 아니라, 단순히 pred와 gt의 1:1 매칭을 하기 위한 Coss function 입니다.
- Cost function - Hungarian Loss
Hungarian Matcher를 이용해 pred와 gt와 1:1 매칭을 했다면, Hungarian Loss를 이용해 Loss를 구합니다.
식은 아래와 같습니다.
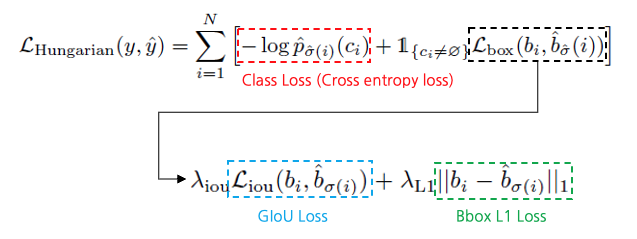
3. Results
- COCO val
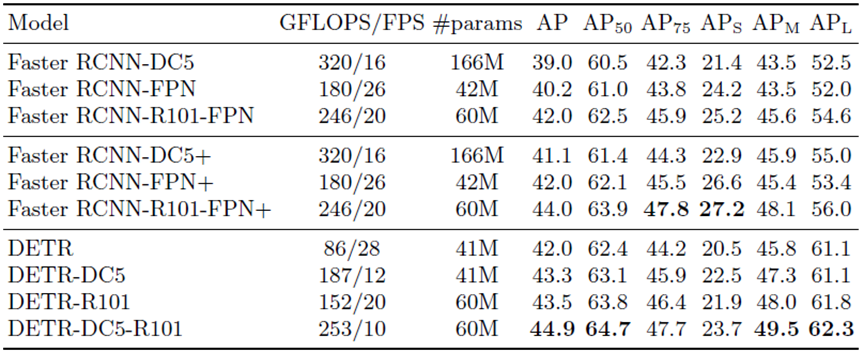 DETR와 Faster RCNN 모델 별 COCO val set에 대한 결과 입니다.
DETR와 Faster RCNN 모델 별 COCO val set에 대한 결과 입니다.
DETR보다 Faster RCNN 계열이 small object detection에 대한 성능이 더 높은 것을 볼 수 있습니다. () 반면 큰 물체에 대한 탐지 성능은 DETR가 훨씬 뛰어난 성능을 보입니다. ()
전반적으로는 Faster RCNN과 비슷비슷한 성능을 보입니다.
- Encoder layers
 Encoder Layer 수가 늘어 날수록 (모델이 커질 수록) 성능이 증가하는 경향을 보입니다. 여느 transformer 계열 모델들처럼 scaling laws를 따릅니다.
Encoder Layer 수가 늘어 날수록 (모델이 커질 수록) 성능이 증가하는 경향을 보입니다. 여느 transformer 계열 모델들처럼 scaling laws를 따릅니다.
- Self-Attention map
 특정 지점에서 self-attention을 시각화 한 것 입니다. 객체를 분리해서 self-attention을 하는 것을 볼 수 있습니다.
특정 지점에서 self-attention을 시각화 한 것 입니다. 객체를 분리해서 self-attention을 하는 것을 볼 수 있습니다.
- NMS
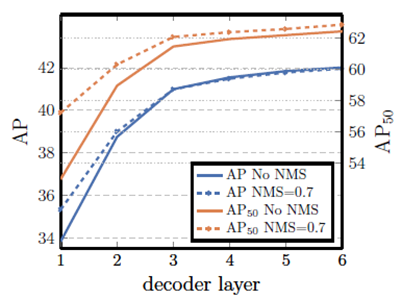 DETR에서 왜 NMS가 필요 없는지를 보여 주는 그래프입니다. 얕은 Decoder layer를 갖는 DETR의 경우 object query들 간의 충분한 상호작용이 없기 때문에 같은 객체를 여러 query가 중복 예측할 수도 있어서 NMS를 적용한 것이 성능이 훨씬 좋습니다. 하지만 깊은 decoder layer를 갖는 DETR는 NMS의 유무가 성능에 큰 상관이 없는 것을 볼 수 있습니다. 오히려 AP 그래프 (파란색)를 보면 NMS를 적용하지 않은 것이 더 좋은 결과를 보입니다. DETR의 저자들은 이를 서로 일부 영역이 겹쳐 있는 TP들이 NMS로 인해 제거 되었기 때문이라고 설명합니다.
DETR에서 왜 NMS가 필요 없는지를 보여 주는 그래프입니다. 얕은 Decoder layer를 갖는 DETR의 경우 object query들 간의 충분한 상호작용이 없기 때문에 같은 객체를 여러 query가 중복 예측할 수도 있어서 NMS를 적용한 것이 성능이 훨씬 좋습니다. 하지만 깊은 decoder layer를 갖는 DETR는 NMS의 유무가 성능에 큰 상관이 없는 것을 볼 수 있습니다. 오히려 AP 그래프 (파란색)를 보면 NMS를 적용하지 않은 것이 더 좋은 결과를 보입니다. DETR의 저자들은 이를 서로 일부 영역이 겹쳐 있는 TP들이 NMS로 인해 제거 되었기 때문이라고 설명합니다.
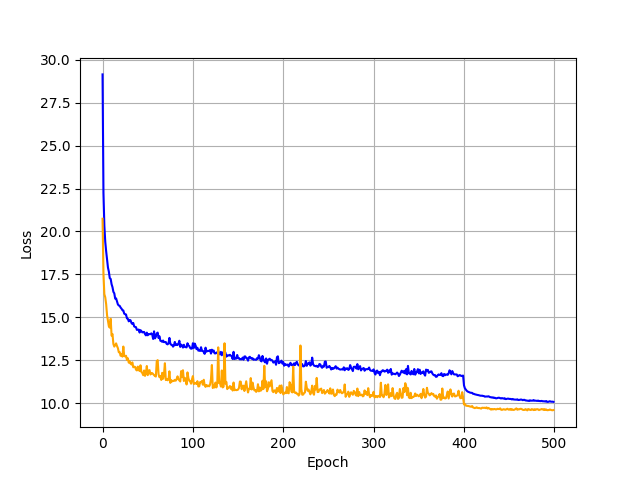
- Loss
 Loss도 L1, GIoU를 모두 포함하는 것이 더 성능에 유리했습니다.
Loss도 L1, GIoU를 모두 포함하는 것이 더 성능에 유리했습니다.
4. Code
https://github.com/krec7748/DETR