목적
VGGNet 을 이해하고 Pytorch로 구현할 수 있다.
Architecture
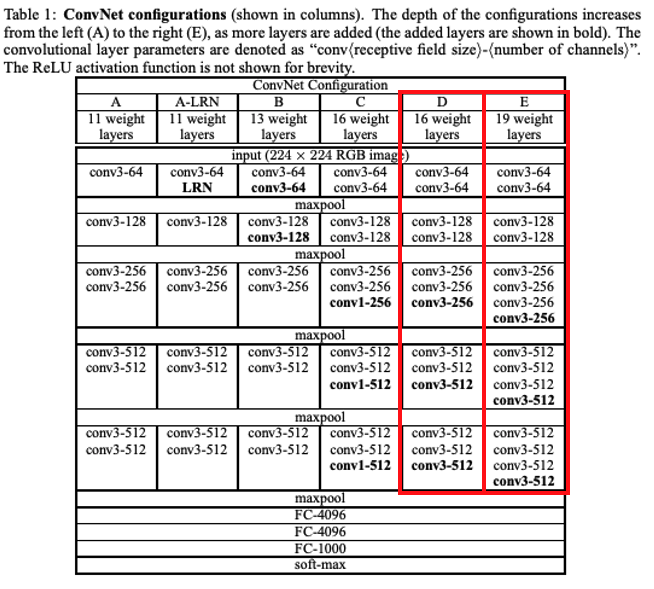
- Table에서 D, E가 흔히 알고 있는 VGGNet16, VGGNet19의 구조 이다.
특징
- VGGNet16, 19를 구성하고 있는 모든 Conv layer의 필터 사이즈는 3x3이다. (그리고 padding = 1, stride = 1은 고정)
- Trainable weight layer가 각각 16 layer, 19 layer로 구성되어 있다.
- 큰 필터 사이즈를 갖는 conv layer를 사용하지 않고, 작은 필터 사이즈를 갖는 conv layer를 여러 번 통과 시키는 방법을 사용해 더 효율적으로 넓은 receptive field를 얻을 수 있게 하였다. (이는 파라미터 수, 비선형성, 집중도 측면에서 유리하다.)
(ex) 3x3 두 번 vs 5x5 한 번- 파라미터 수: 18 vs 25
- 비선형성: Activation func 2 번 vs Activation func 1 번
- 집중도: layer를 쌓을 수록 담당하는 위치를 더 많이 봄. (진하게 봄)
- 현대 모델과 비교했을 때 성능에 비해 weight 수가 지나치게 많다. (특히 FC layer의 weight가 모델 전체 weight의 80 % 이상을 차지)
Code
환경
- python 3.8.16
- pytorch 2.1.0
- torchinfo 1.8.0
구현
import torch
from torch import nn
from torchinfo import summaryVGG_cfgs = {"D": [64, 64, "MP", 128, 128, "MP", 256, 256, 256, "MP", 512, 512, 512, "MP", 512, 512 ,512, "MP"],
"E": [64, 64, "MP", 128, 128, "MP", 256, 256, 256 ,256, "MP", 512, 512, 512, 512, "MP", 512, 512, 512, 512, "MP"]}class VGGNet(nn.Module):
def __init__(self, cfg, batch_norm = False, num_classes = 1000):
super().__init__()
self.conv_layers = self.create_conv_layers(cfg, batch_norm)
self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) # input 행렬 크기가 어떻든 output 행렬의 7x7이 되도록 avgpool (채널 수는 영향 X)
self.fcs = nn.Sequential(nn.Linear(512 * 7 * 7, 4096), # input size: 224 -> "Maxpool" 5번 거치므로 224 / (2 ** 5) = 7
nn.ReLU(),
nn.Dropout(p = 0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p = 0.5),
nn.Linear(4096, num_classes))
def forward(self, x):
x = self.conv_layers(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fcs(x)
return x
def create_conv_layers(self, cfg, batch_norm):
in_channels = 3 #RGB
layers = []
for x in cfg:
if type(x) == int:
if batch_norm:
layers += [nn.Conv2d(in_channels, x, kernel_size = 3, padding = 1, bias = False),
nn.BatchNorm2d(x), #Paper에는 이 부분이 없지만 현대에는 Conv-BatchNorm-ReLU 형태로 많이 쓰임.
nn.ReLU()]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size = 3, padding = 1),
nn.ReLU()]
in_channels = x
elif x == "MP": #maxpool
layers += [nn.MaxPool2d(2)]
return nn.Sequential(*layers) # *: upzip operationmodel = VGGNet(VGG_cfgs["D"], batch_norm = True)
summary(model, input_size=(1,3,224,224), device='cpu')#### <Output> ####
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VGGNet [1, 1000] --
├─Sequential: 1-1 [1, 512, 7, 7] --
│ └─Conv2d: 2-1 [1, 64, 224, 224] 1,728
│ └─BatchNorm2d: 2-2 [1, 64, 224, 224] 128
│ └─ReLU: 2-3 [1, 64, 224, 224] --
│ └─Conv2d: 2-4 [1, 64, 224, 224] 36,864
│ └─BatchNorm2d: 2-5 [1, 64, 224, 224] 128
│ └─ReLU: 2-6 [1, 64, 224, 224] --
│ └─MaxPool2d: 2-7 [1, 64, 112, 112] --
│ └─Conv2d: 2-8 [1, 128, 112, 112] 73,728
│ └─BatchNorm2d: 2-9 [1, 128, 112, 112] 256
│ └─ReLU: 2-10 [1, 128, 112, 112] --
│ └─Conv2d: 2-11 [1, 128, 112, 112] 147,456
│ └─BatchNorm2d: 2-12 [1, 128, 112, 112] 256
│ └─ReLU: 2-13 [1, 128, 112, 112] --
│ └─MaxPool2d: 2-14 [1, 128, 56, 56] --
│ └─Conv2d: 2-15 [1, 256, 56, 56] 294,912
│ └─BatchNorm2d: 2-16 [1, 256, 56, 56] 512
│ └─ReLU: 2-17 [1, 256, 56, 56] --
│ └─Conv2d: 2-18 [1, 256, 56, 56] 589,824
│ └─BatchNorm2d: 2-19 [1, 256, 56, 56] 512
│ └─ReLU: 2-20 [1, 256, 56, 56] --
│ └─Conv2d: 2-21 [1, 256, 56, 56] 589,824
│ └─BatchNorm2d: 2-22 [1, 256, 56, 56] 512
│ └─ReLU: 2-23 [1, 256, 56, 56] --
│ └─MaxPool2d: 2-24 [1, 256, 28, 28] --
│ └─Conv2d: 2-25 [1, 512, 28, 28] 1,179,648
│ └─BatchNorm2d: 2-26 [1, 512, 28, 28] 1,024
│ └─ReLU: 2-27 [1, 512, 28, 28] --
│ └─Conv2d: 2-28 [1, 512, 28, 28] 2,359,296
│ └─BatchNorm2d: 2-29 [1, 512, 28, 28] 1,024
│ └─ReLU: 2-30 [1, 512, 28, 28] --
│ └─Conv2d: 2-31 [1, 512, 28, 28] 2,359,296
│ └─BatchNorm2d: 2-32 [1, 512, 28, 28] 1,024
│ └─ReLU: 2-33 [1, 512, 28, 28] --
│ └─MaxPool2d: 2-34 [1, 512, 14, 14] --
│ └─Conv2d: 2-35 [1, 512, 14, 14] 2,359,296
│ └─BatchNorm2d: 2-36 [1, 512, 14, 14] 1,024
│ └─ReLU: 2-37 [1, 512, 14, 14] --
│ └─Conv2d: 2-38 [1, 512, 14, 14] 2,359,296
│ └─BatchNorm2d: 2-39 [1, 512, 14, 14] 1,024
│ └─ReLU: 2-40 [1, 512, 14, 14] --
│ └─Conv2d: 2-41 [1, 512, 14, 14] 2,359,296
│ └─BatchNorm2d: 2-42 [1, 512, 14, 14] 1,024
│ └─ReLU: 2-43 [1, 512, 14, 14] --
│ └─MaxPool2d: 2-44 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-2 [1, 512, 7, 7] --
├─Sequential: 1-3 [1, 1000] --
│ └─Linear: 2-45 [1, 4096] 102,764,544
│ └─ReLU: 2-46 [1, 4096] --
│ └─Dropout: 2-47 [1, 4096] --
│ └─Linear: 2-48 [1, 4096] 16,781,312
│ └─ReLU: 2-49 [1, 4096] --
│ └─Dropout: 2-50 [1, 4096] --
│ └─Linear: 2-51 [1, 1000] 4,097,000
==========================================================================================
Total params: 138,361,768
Trainable params: 138,361,768
Non-trainable params: 0
Total mult-adds (G): 15.47
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 216.83
Params size (MB): 553.45
Estimated Total Size (MB): 770.88
==========================================================================================