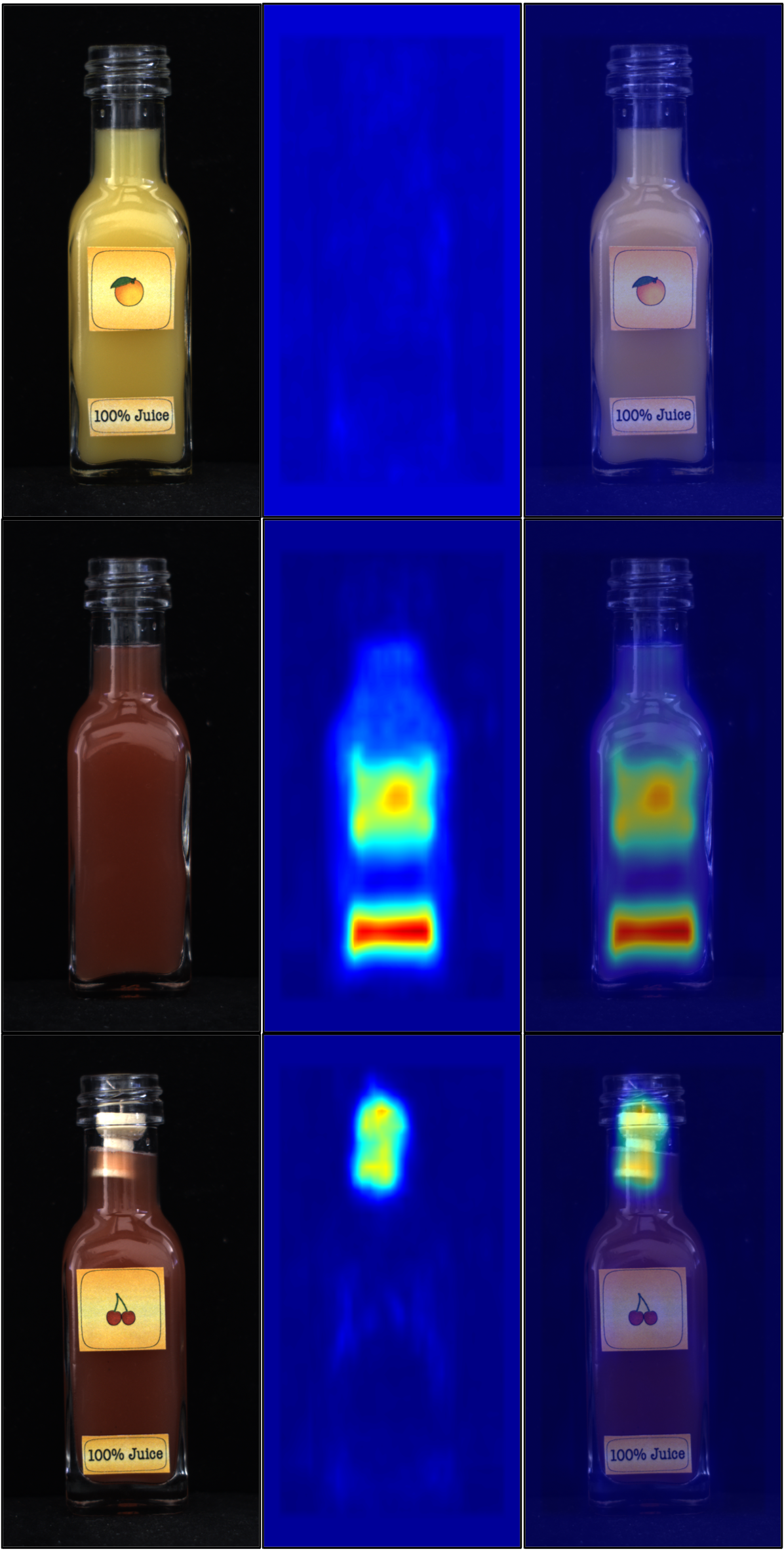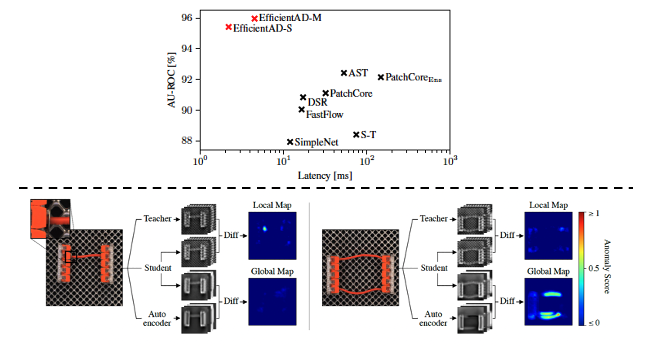
1. Introduction
EfficientAD는 Visual Anomaly Detection 분야에서 적은 weights들로 구성된 CNN network를 사용하여 real-time inference가 가능하게 컴퓨팅 효율성에 포커스를 맞추면서도 우수한 성능을 달성한 모델입니다.
Knowledge distillation 방법을 활용한 Unsupervised learning 알고리즘으로써 정상 이미지만으로 구성한 데이터를 이용해 Teacher 네트워크의 feature map을 Student 네트워크가 모방하도록 학습이 진행됩니다. (pretrained 모델인 Teacher 네트워크는 EfficientAD를 학습할 때는 학습되지 않음.)
학습이 잘 된 모델에 비정상 이미지를 통과시키면 비정상적인 부분은 Student가 Teacher를 잘 모방하지 못 해 Teacher가 생성한 feature map과는 값이 다른 feature map이 생성될 것입니다. 이와 같은 원리로 사과가 상했다거나, 부품이 부서졌다거나, 비닐이 찢어졌다와 같은 부분적인 결함을 탐지할 수 있습니다. Structual anomaly detection을 가능하게 합니다.
그러나 얕은 네트워크를 사용한 만큼 receptive field가 작기 때문에 Teacher-Student 만으로는 이미지의 전체적인 맥락을 볼 수 없으므로 물건의 위치가 잘못 놓였다던지, 부품 중 하나가 부족하다던지와 같은 이미지 전체를 봐야 알 수 있는 Logical anomaly에 대해서는 탐지하기가 어렵습니다.
저자들은 이 문제를 이미지 전체 맥락을 보는 Autoencoder를 EfficientAD에 편입시켜 해소하였습니다. Logical anomaly detection을 가능하게 합니다.
2. Method
-
Efficient Patch Descriptors
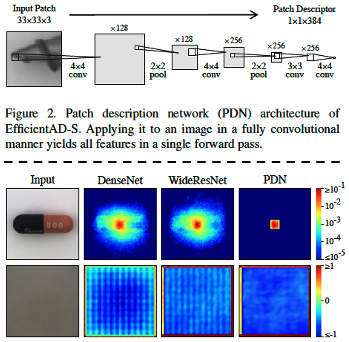 사용한 teacher network, student network는 각각 4개의 Conv layer로 구성되며 (EfficientAD-S) output feature map의 receptive field의 크기는 33x33 입니다.
사용한 teacher network, student network는 각각 4개의 Conv layer로 구성되며 (EfficientAD-S) output feature map의 receptive field의 크기는 33x33 입니다.
Conv layer로만 구성된 network 특성상 input image size에 의존적이지 않으며, output feature map 하나의 픽셀은 항상 원본 이미지의 33x33 patch에 대한 정보를 담고 있습니다. 저자들은 이 network를 PDN(Patch description Network)으로 정의했습니다.
아래 figure는 알약 이미지를 각각 pretrained된 DenseNet, WideResNet, PDN에 통과시켜 output feature map을 얻고 output feature map의 중심에 위치한 feature vector의 gradient를 시각화 한 이미지입니다. DenseNet, WideResNet은 feature map 중심에 위치한 vector를 얻기 위해 이미지의 많은 영역의 정보가 사용되는 것을 볼 수 있습니다. 반면 PDN은 특정 패치 범위를 벗어나지 않는 것을 볼 수 있습니다.
PDN은 teacher network와 student network로 사용됩니다.
-
Lightweight Student-Teacher
PDN을 teacher, student network로 사용함으로써 1 ms 이하의 속도로 실행이 가능하게 됩니다. EfficientAD는 다른 anomaly detection 알고리즘에서 성능 향상을 위해 사용한 여러 기법들을 사용하지 않았는데요. 대신 training loss를 도입합니다.
일반적인 S-T framework의 경우 학습 데이터가 매우 많다면 student가 teacher를 지나치게 잘 모방하게 되면서 anomaly detection 성능이 떨어집니다. 그렇다고 학습 데이터를 줄이게 되면 normal한 이미지 조차도 잘 모방하지 못합니다.
저자들은 충분한 학습 데이터를 사용하여 정상 이미지에 대해 Student가 Teacher를 잘 모방하도록 하면서도 비정상 이미지에 대해서는 일반화를 피하고자 했습니다.
이를 위해 저자들은 OHEM(Online Hard Example Mining)의 컨셉과 유사한 방법인 Student가 Teacher를 잘 모방하지 못하는 부분(loss가 높은 부분)에 집중하여 학습이 진행되도록 hard feature loss를 제안합니다.

teacher를 , student를 , training image를 라고 해봅시다.
를 teacher와 student에 각각 통과시키고 squared difference를 구하면 아래와 같은 식이 나옵니다.
그리고 0~1 사이의 값을 갖는 mining factor인 를 이용해 분위값을 계산합니다. (논문에서는 의 값을 0.999로 지정하였습니다.)
-quantile 값인 를 구하고 조건을 충족하는 element들을 에서 추출하고 평균을 내어 training loss 을 구할 수 있습니다.
Figure 4는 가 0.999일 때 backpropagation에 참여하는 element들을 시각화 한 것입니다.
추가적으로 student가 학습 이미지들과 분포가 다른 OOD(out-of-distribution) 이미지에 대한 예측성능을 떨어뜨려 비정상적인 부분에 대해서 student가 잘 예측하지 못하도록 유도하기 위해 loss penalty를 추가했습니다. (teacher를 pretrain하는데 사용했던 ImageNet 데이터를 랜덤하게 뽑은 이미지 를 에 통과시켜 loss penalty를 구합니다.)
최종적으로 는 와 의 합으로 구할 수 있습니다.
-
Logical Anomaly Detection
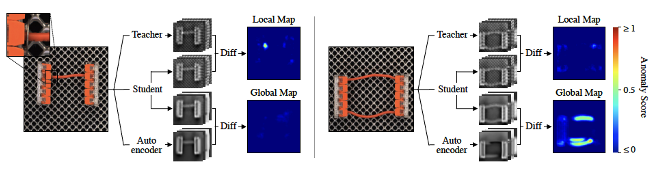 object를 누락했거나, 잘못 배치되었거나 와 같이 이미지 전체 맥락을 봐야 알 수 있는 logical anomaly detection을 위해 특정 패치 범위만을 보는 PDN를 적용하는 것은 적절하지 않습니다. 이에 저자들은 EfficientAD에 Autoencoder를 도입했습니다.
object를 누락했거나, 잘못 배치되었거나 와 같이 이미지 전체 맥락을 봐야 알 수 있는 logical anomaly detection을 위해 특정 패치 범위만을 보는 PDN를 적용하는 것은 적절하지 않습니다. 이에 저자들은 EfficientAD에 Autoencoder를 도입했습니다.
Autoencoder는 teacher의 output을 예측하도록 학습됩니다.
autoencoder를 , training image를 라고 했을 때 는 아래 식으로 구할 수 있습니다.
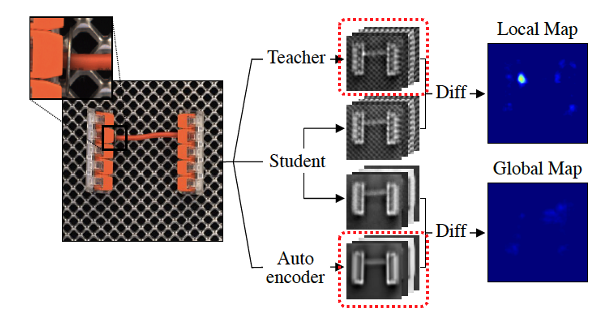
하지만 Autoencoder는 아래 첨부한 그림처럼 이미지의 전체적인 맥락을 보고 재구성 하는 것은 잘 하지만 background grid와 같이 지엽적이고 디테일한 부분에 대해서는 잘 재구성하지 못합니다. 따라서 만을 사용해서 학습한 autoencoder를 anomaly detection에 사용한다면 background grid를 anomaly하다고 잘못 예측할 우려가 있습니다. (False Positive)
 이를 보완하기 위해서 저자들은 Student의 output channel을 두 배 더 늘려서 반은 teacher output을 모방하도록, 나머지 반은 autoencoder를 모방하도록 유도했고, 이를 위해서 를 도입했습니다. (는 에서 autoencoder를 모방하는 부분입니다.)
이를 보완하기 위해서 저자들은 Student의 output channel을 두 배 더 늘려서 반은 teacher output을 모방하도록, 나머지 반은 autoencoder를 모방하도록 유도했고, 이를 위해서 를 도입했습니다. (는 에서 autoencoder를 모방하는 부분입니다.)
만약, 케이블 하나를 갖는 장치 이미지들로 구성된 정상 데이터셋으로 잘 학습한 EfficientAD에 케이블 두 개를 갖는 logical 겷함이 있는 이미지로 input으로 넣어 logical anomaly detection을 한다고 해봅시다.
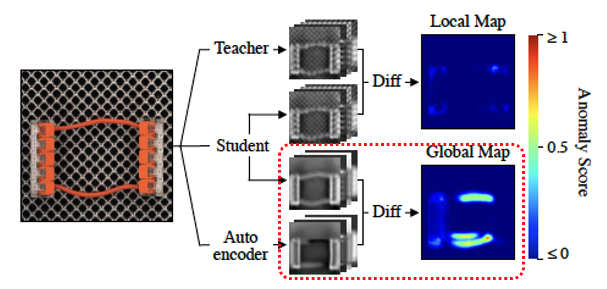 는 PDN로 구성되어 있기 때문에 이미지 전체의 맥락을 보지 못합니다. 따라서 케이블이 몇 개가 있던 상관없이 위 이미지처럼 케이블에 대해 feature map을 Teacher와 유사하게 output feature map을 뽑아낼 것 입니다. 반면 이미지 전체를 보고 재구성하는 Autoencoder 입장에서는 케이블 두 개를 갖는 이미지를 본 적이 없기 때문에 케이블 부분의 output feature map이 정상적으로 재구성 되지 못할 것입니다. 따라서 와 가 케이블 부분에서 차이가 생기므로 logical 결함을 탐지할 수 있습니다.
는 PDN로 구성되어 있기 때문에 이미지 전체의 맥락을 보지 못합니다. 따라서 케이블이 몇 개가 있던 상관없이 위 이미지처럼 케이블에 대해 feature map을 Teacher와 유사하게 output feature map을 뽑아낼 것 입니다. 반면 이미지 전체를 보고 재구성하는 Autoencoder 입장에서는 케이블 두 개를 갖는 이미지를 본 적이 없기 때문에 케이블 부분의 output feature map이 정상적으로 재구성 되지 못할 것입니다. 따라서 와 가 케이블 부분에서 차이가 생기므로 logical 결함을 탐지할 수 있습니다.
전체 loss식은 아래와 같습니다.
teacher-student로 부터 얻은 Local map과 student autoencoder로 부터 얻은 Global map을 결합해서(평균내서) 최종 anomaly map을 얻을 수 있습니다.
anomaly map에서 최대값을 anomaly score로 정의했고, anomaly score를 이용해 정상 이미지인지 비정상 이미지인지에 대한 binary classification을 위해 활용됩니다.
-
Anomaly Map Normalization
최종 anomaly map을 얻기 전에 Local map과 Global map간의 scale을 유사하게 만들어 주어야 합니다. 학습에 사용되지 않은 Validation data 전부를 EfficientAD에 통과시켜 local map과 global map 각각의 feature map의 평균값을 구한 뒤, 그 평균값들에 대한 분위, 분위 값을 구합니다. (논문에서는 , 로 설정하였습니다.)
아래와 같이 총 4개의 값을 구합니다.
q_st_start: local map들의 평균값들 중 분위 수에 해당하는 값
q_st_end: local map들의 평균값들 중 분위 수에 해당하는 값
q_ae_start: global map들의 평균값들 중 분위 수에 해당하는 값
q_ae_end: global map들의 평균값들 중 분위 수에 해당하는 값
q_start는 score가 0으로 매핑되게 하고,q_end는 score가 0.1에 매핑되게 각각의 map을 normalization 합니다.
정규화 된 local map과 global map은 평균을 내어 () 최종 anomaly map으로 활용됩니다.
3. Results
- 이상치 탐지 및 이상치 위치에 대한 성능 평가 및 추론 속도 비교
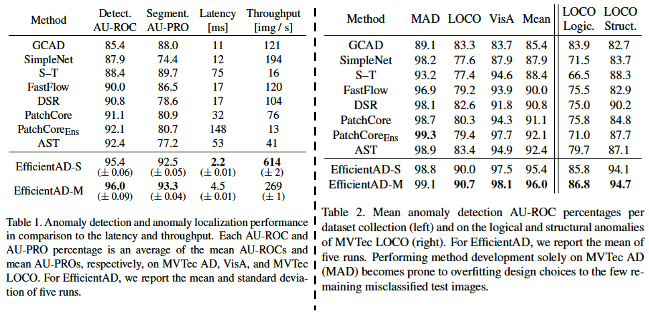
<Table 1>
(AU-ROC는 이상치를 얼마나 잘 탐지하는지를 평가하는 지표이고, AU-PRO는 이상치의 위치를 얼마나 정확하게 찾았는지를 평가하는 지표입니다.)
MAD(MVTec AD), VisA, LOCO(MVTec LOCO) 세 개의 데이터 셋에 대한 anomaly detection 성능을 평균낸 표 입니다.
이상치 탐지 성능, 이상치 위치, 추론 속도 모두 EfficientAD가 다른 anomaly detection 알고리즘보다 압도적으로 좋은 성능을 보여줍니다.
<Table 2>
MAD(MVTec AD), VisA, LOCO(MVTec LOCO) 세 개의 데이터 셋에 대한 anomaly detection 성능을 각각 나타낸 표 입니다.
특히 LOCO의 logical anomlay detection, structural anomaly detection 모두 다른 알고리즘보다 압도적인 성능을 보여줍니다.
4. Code
https://github.com/krec7748/EfficientAD