1. Introduction
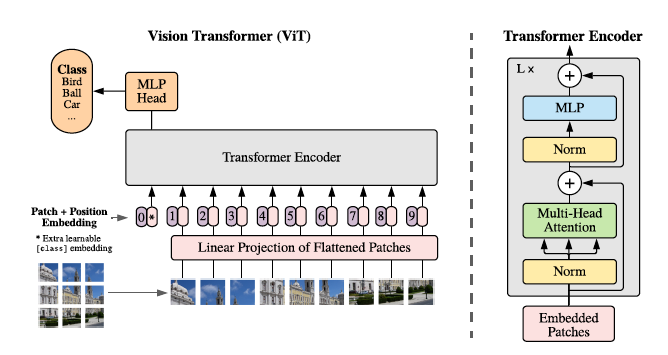
Transformer 이후 NLP 분야의 성공에 영향을 받아 CV 쪽에서도 self-attention을 사용하려는 시도가 있었지만 large-scale 이미지 인식에 있어서는 여전히 고전적인 ResNet-like architecture (CNN)이 SOTA 였습니다.
이 ViT 논문의 저자들도 이미지 인식에 self-attention을 도입해보고자 했고, Transformer Encoder쪽을 도입한 이미지 분류 모델을 만들었습니다. 모델 이름은 Vision Transformer (ViT) 입니다.
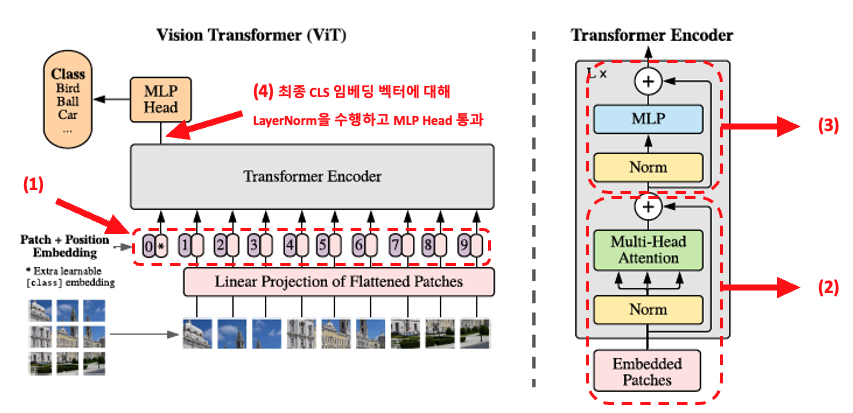
저자들은 이미지를 패치 단위로 잘라서 Transformer에 적용하는 방법을 고안하였습니다. 이미지 전체를 하나의 문장으로 보았고, 각 패치들은 문장을 구성하고 있는 단어들로 생각하였습니다.
(그래서 논문의 제목이 "An Image is worth 16x16 words: ...")
ViT의 Transformer encoder는 Transformer (Attention is All you need)와 거의 동일합니다. 결국 핵심은 어떻게 이미지를 Transformer가 받아들일 수 있는 형태인 임베딩 벡터로 변환하였는가 라고 생각합니다.
이미지에서 Transformer 임베딩 벡터를 어떻게 만들었는지 간단히 살펴봅시다.
1. 이미지를 패치로 분할합니다.
([3, img_h, img_w] -> [3, patch_h, patch_w, patch_num])
2. 각각의 패치들을 편 것이 입력 벡터가 됩니다.
([3, patch_h, patch_w, patch_num] -> [3 x patch_h x patch_w, patch_num])
3. 입력 벡터들에 대해 임베딩을 수행하면 임베딩 벡터가 됩니다.
nn.Linear(3 x patch_h x patch_w, dim)
여기서는 패치를 임베딩 한 것이기 때문에 Patch Embedding Vector라고도 표현할 수 있을 것 같습니다.
([3 x patch_h x patch_w, patch_num] -> [dim, patch_num] ->
-> (Permute) -> [patch_num, dim])
Transformer의 input과 똑같이 생긴 것을 볼 수 있습니다.
([seq_length, num_words] -> [seq_length, dim])
이제 한 번 자세히 살펴봅시다.
2. Method
- Inductive bias
직역하자면, "귀납적 편향" 입니다. 이것만 보면 이해가 어려운데요.
여기서 말하는 inductive bias는 모델이 갖고 있는 고정관념 (또는 가이드) 라고 이해하시면 될 것 같습니다. 저자들은 ViT가 CNN보다 inductive bias가 더 적다고 합니다. 그 이유를 살펴봅시다.
CNN은 구조상 처음에는 좁은 영역만을 보지만 layer가 쌓여감에 따라 receptive field가 점차 넒어지면서 이미지를 인식합니다. 이는 비유하자면 AI에게 "초반에는 좀 주변을 바라보고 점점 넓혀가면서 봐!" 라고 하며 일종의 가이드를 제시해주는 셈이 됩니다.
반면 ViT의 transformer encoder는 self-attention을 이용해서 언제 (몇 번째 layer에서) 어디를 볼 지 (몇 번째 패치)를 데이터를 통해서 스스로 알아내! 라고 하는 말하는 것 입니다.(강하게 키우기)
Results 부분에서 보실 수 있겠지만 Pre-training data가 적을 때는 ResNet의 성능이 더 우수하지만 모델이 크고, 데이터 수가 많을 때는 ViT 모델의 성능이 더 뛰어난 것을 볼 수 있습니다.
CNN의 관점에서 이는 데이터가 적을 때는 inductive bias가 가이드(positive)처럼 작용되어서 힘을 발휘하지만, 데이터 수가 충분히 많을 때는 inductive bias가 고정관념(negative)처럼 작용한다고도 해석이 가능할 것 같습니다.
- Vision Transformer (ViT)
모델 구조는 위와 같습니다. 동작 방식을 shape과 함께 살펴봅시다.
(1) 이미지를 패치들로 나누고 폅니다. (Flattened Patches 생성)
([32, 3, 60, 60] -> [32, 3x20x20, 3, 3])
(2) Flattened patches 에 대해 임베딩을 수행. (Patch embedding, (= Linear Projection))
예를 들어, 임베딩 차원dim = 768이라고 가정한다면,
각각의 flattend patch들에 대해 임베딩 (nn.Linear(3x20x20, 768))을 하면[32, 3x20x20, 3, 3] -> [32, 768, 3, 3]가 나옵니다.
이후,rearrange를 수행합니다.[32, 768, 3, 3] -> [32, 9, 768])
(3) CLS token을 도입합니다.
CLS token (class token)은 BERT의 CLS token과 매우 유사한 역할을 하는데요. (아래 첨부한 글은 BERT 논문의 일부 입니다.) ViT CLS token를 구성하는 초기 값들은 "0(zero)" 이지만 self-attention을 하면서 CLS 토큰에 패치들의 정보가 종합적으로 담기도록 의도하였습니다. (초기값이 0이기 때문에 Linear projection은 필요가 없는 것도 그림 상에 나타나 있습니다.)
ViT CLS token를 구성하는 초기 값들은 "0(zero)" 이지만 self-attention을 하면서 CLS 토큰에 패치들의 정보가 종합적으로 담기도록 의도하였습니다. (초기값이 0이기 때문에 Linear projection은 필요가 없는 것도 그림 상에 나타나 있습니다.)
([32, 9, 768] -> [32, 10, 768])
(4) 패치의 위치 정보를 담고 있는 Positional embedding 을 더해줍니다. (Patches + Positional embedding)
([32, 10, 768] -> [32, 10, 768])
(5) Transformer Encoder를 통과시킨 후 나온 CLS의 최종 임베딩 벡터를 획득합니다.
([32, 10, 768] -> [32, 1, 768] -> [32, 768])
(6) MLP를 통과시켜 분류 합니다.
([32, 768] -> [32, num_classes])
실제 구현에서는 (1) ~ (2) 과정을nn.Conv2d와einops의rearrange로 수행합니다.
(예시)
[32, 3, 60, 60]가,nn.Conv2d(3, 768, 20, stride = 20)를 통과하면[32, 768, 3, 3]가 됩니다. 이를rearrange(x, "B C H W -> B (H W) C")를 수행하면[32, 9, 768]이 됩니다.
- Transformer Encoder와의 차이점
(1) Encoder 내부의 Block 순서를 변경하였습니다.
pre-activation ResNet의 방식을 반영하였습니다.
Backpropagation 관점에서 본다면 LayerNorm에 대한 미분을 반영하지 않고, identity에 대한 gradient path를 만들고자 하였습니다.
(2) MLP의 activation function을ReLU대신GELU로 변경하였습니다
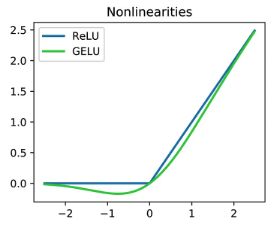 GELU의 식은 아래와 같습니다.
GELU의 식은 아래와 같습니다.
는 표준 정규 분포의 누적 분포 함수(CDF) 입니다.
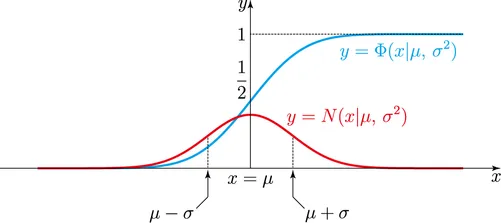 가 클수록 1에 가까워 지고, 작을수록 0에 가까워 집니다.
가 클수록 1에 가까워 지고, 작을수록 0에 가까워 집니다.
즉, 입력 를 정규분포에 따라 확률적으로 통과시킵니다.
작은 입력에 대해서도 ReLU처럼 0 부근에서 그래프가 팍팍 꺾이는 것이 아닌 완만하게 반응하고 (smoothness), 음수 정보도 반영함으로써 정보 손실을 줄이는 등 ReLU의 문제점을 보완하는 여러 장점들을 가지고 있기 때문에 GPT, BERT 모델 등 LLM 모델들이 GELU를 사용합니다. 마찬가지로 ViT에서도 GELU를 채택하였습니다.
- 수식
ViT의 수식입니다.

는 embedded patches 입니다. 의 묶음이며 는 번째 patch이고 는 embedding projection 입니다. 는 positional embedding 입니다.
이후 나오는 (2), (3), (4) 식도 Transformer Encoder를 식으로 잘 표현하고 있습니다. (는 Multi head Self Attention의 약자이고, 은 LayerNorm의 약자 입니다.)
- 제안하는 모델
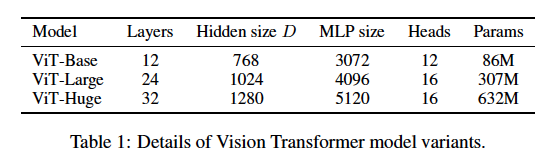 제안하는 모델은 총 3가지 입니다. 아키텍쳐는 동일하고 layer 수, Hidden size 등의 수만 조정하였습니다. Huge 모델은 무려 6억개의 파라미터가 넘는 것을 볼 수 있습니다.
제안하는 모델은 총 3가지 입니다. 아키텍쳐는 동일하고 layer 수, Hidden size 등의 수만 조정하였습니다. Huge 모델은 무려 6억개의 파라미터가 넘는 것을 볼 수 있습니다.
3. Results
- 여러 데이터 셋에 대한 Top1 Accuracy
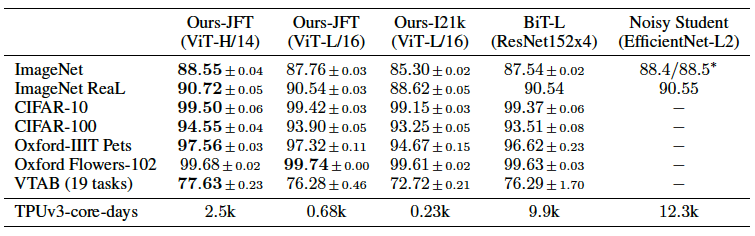 ViT-L/14는 patch 사이즈가 14x14인 ViTLarge 모델을 의미합니다.
ViT-L/14는 patch 사이즈가 14x14인 ViTLarge 모델을 의미합니다.
모든 데이터 셋에 대해 뛰어난 성능을 보입니다. 그리고 모델에서 JFT-300M (Ours JFT)로 pre-training한 ViT-L/16와 ImageNet21K (Ours-I21K)로 pre-training한 ViT-L/16의 결과를 비교해보면 더 많은 데이터로 pre-training을 한 모델의 성능이 뛰어난 것도 확인 할 수 있습니다.
- Pre-training dataset 별 ImageNet Top1 Accuracy
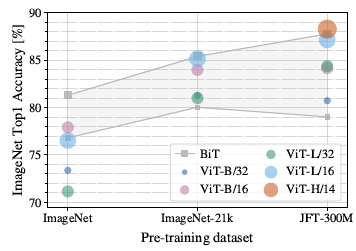 Pre-training dataset에 따라 ImageNet 1K의 성능을 나타낸 그래프 입니다.
Pre-training dataset에 따라 ImageNet 1K의 성능을 나타낸 그래프 입니다.
(아래에 있는 BiT는 ResNet50x1, 상단에 있는 BiT는 ResNet152x4 입니다, x4는 채널 수를 4배 늘린 것 입니다.)
Pre-training dataset이 작아도 CNN(BiT, Big Transfer)은 어느정도 성능이 잘 나옵니다. 반면 ViT는 Pre-training dataset이 커야 성능이 잘 나오는 것을 볼 수 있습니다. 이는 사전학습 데이터 수가 적을 때는 CNN 모델을 사용하여 inductive bias를 이용하는 것이 유리하지만, 사전학습 데이터 수가 많을 때는 데이터로 부터 직접 패턴을 학습하는 것이 유리하다는 것을 시사합니다.
- Few-shot Learning ImageNet Top 1 Accuracy
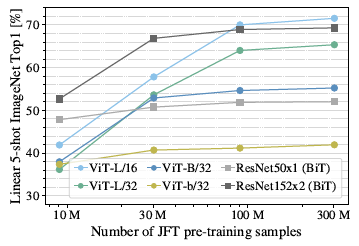 표의 좌측에 Linear 5-few shot ImageNet Top 1이라고 되어 있는데 5-shot learning은 각 class당 5개 데이터만 가지고 학습하는 것을 의미하고 Linear는 fine-tuning시 MLP head 부분을 한 층의
표의 좌측에 Linear 5-few shot ImageNet Top 1이라고 되어 있는데 5-shot learning은 각 class당 5개 데이터만 가지고 학습하는 것을 의미하고 Linear는 fine-tuning시 MLP head 부분을 한 층의 nn.Linear로 바꾸고 그 층만 학습 시킨 것을 뜻합니다.
마찬가지로 Pre-training data가 많을수록 성능이 증가하는 것을 볼 수 있습니다. 주목할 점은 CNN 모델은 빠르게 수렴하는 모습을 보이지만, ViT (ViT-L)는 데이터가 좀 더 많다면 성능 상승의 여지가 있어보입니다.
이는 마찬가지로 사전학습 데이터 수가 많을 때는 inductive bias에 의존하기 보다는 데이터로부터 직접 패턴을 학습하는 것이 더 유익할 수 있다고 해석할 수 있습니다.
4. Code
환경
- python 3.10.16
- numpy 1.24.3
- pytorch 2.1.0
- torchvision 0.16.0
- torchinfo 1.8.0
- Pillow 10.1.0
- tqdm 4.66.1
1. Import Library
import math
import torch
from torch import nn
from einops import rearrange
from torchinfo import summary2. Model
class MHA(nn.Module):
def __init__(self, hidden_dim, n_heads):
super().__init__()
self.n_heads = n_heads
self.scale = torch.sqrt(torch.tensor(hidden_dim / n_heads))
self.fc_q = nn.Linear(hidden_dim, hidden_dim)
self.fc_k = nn.Linear(hidden_dim, hidden_dim)
self.fc_v = nn.Linear(hidden_dim, hidden_dim)
self.fc_o = nn.Linear(hidden_dim, hidden_dim)
# Weight initialization
nn.init.xavier_uniform_(self.fc_q.weight)
nn.init.xavier_uniform_(self.fc_k.weight)
nn.init.xavier_uniform_(self.fc_v.weight)
nn.init.xavier_uniform_(self.fc_o.weight)
if self.fc_q.bias is not None:
nn.init.constant_(self.fc_q.bias, 0)
if self.fc_k.bias is not None:
nn.init.constant_(self.fc_k.bias, 0)
if self.fc_v.bias is not None:
nn.init.constant_(self.fc_v.bias, 0)
if self.fc_o.bias is not None:
nn.init.constant_(self.fc_o.bias, 0)
def forward(self, x):
Q = self.fc_q(x)
K = self.fc_k(x)
V = self.fc_v(x)
Q = rearrange(Q, "B W (H D) -> B H W D", H = self.n_heads)
K = rearrange(K, "B W (H D) -> B H W D", H = self.n_heads)
V = rearrange(V, "B W (H D) -> B H W D", H = self.n_heads)
attention_score = Q @ K.permute(0, 1, 3, 2) / self.scale
attention_weight = torch.softmax(attention_score, dim = -1)
attention = attention_weight @ V
x = rearrange(attention, "B H W D -> B W (H D)")
x = self.fc_o(x)
return x
class FeedForward(nn.Module):
def __init__(self, hidden_dim, d_ff, drop_p):
super().__init__()
self.linear = nn.Sequential(
nn.Linear(hidden_dim, d_ff),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(d_ff, hidden_dim)
)
def forward(self, x):
x = self.linear(x)
return x
class EncoderLayer(nn.Module):
def __init__(self, hidden_dim, d_ff, n_heads, drop_p):
super().__init__()
self.self_atten_LN = nn.LayerNorm(hidden_dim, eps = 1e-6)
self.self_atten = MHA(hidden_dim, n_heads)
self.FF_LN = nn.LayerNorm(hidden_dim, eps = 1e-6)
self.FF = FeedForward(hidden_dim, d_ff, drop_p)
self.dropout = nn.Dropout(drop_p)
def forward(self, x):
residual = self.self_atten_LN(x)
residual = self.self_atten(residual)
residual = self.dropout(residual)
x = x + residual
residual = self.FF_LN(x)
residual = self.FF(residual)
residual = self.dropout(residual)
x = x + residual
return x
class Encoder(nn.Module):
def __init__(self, seq_length, n_layers, hidden_dim, d_ff, n_heads, drop_p):
super().__init__()
self.pos_embedding = nn.Parameter(0.02 * torch.randn(seq_length, hidden_dim))
self.dropout = nn.Dropout(drop_p)
self.layers = nn.ModuleList(
[EncoderLayer(hidden_dim, d_ff, n_heads, drop_p) for _ in range(n_layers)]
)
self.ln = nn.LayerNorm(hidden_dim, eps = 1e-6)
def forward(self, x):
x = x + self.pos_embedding.expand_as(x)
x = self.dropout(x)
for layer in self.layers:
x = layer(x)
x = x[:, 0, :]
x = self.ln(x)
return x
class VisionTransformer(nn.Module):
def __init__(self, img_size, patch_size, n_layers, hidden_dim, d_ff, n_heads, representation_size = None, drop_p = 0., num_classes = 1000):
super().__init__()
self.hidden_dim = hidden_dim # optimizer 선언시 필요
seq_length = (img_size // patch_size) ** 2 + 1 # +1 은 cls token
self.input_embedding = nn.Conv2d(3, hidden_dim, patch_size, patch_size)
self.class_token = nn.Parameter(torch.zeros(hidden_dim))
self.encoder = Encoder(seq_length, n_layers, hidden_dim, d_ff, n_heads, drop_p)
if representation_size is None: # Fine tuning
self.head = nn.Linear(hidden_dim, num_classes)
else: # Pre-training
self.head = nn.Sequential(
nn.Linear(hidden_dim, representation_size),
nn.Tanh(),
nn.Linear(representation_size, num_classes)
)
# Weight initialization
## conv weight
fan_in = self.input_embedding.in_channels * self.input_embedding.kernel_size[0] * self.input_embedding.kernel_size[1]
nn.init.trunc_normal_(self.input_embedding.weight, std = math.sqrt(1/fan_in))
if self.input_embedding.bias is not None:
nn.init.zeros_(self.input_embedding.bias)
## Linear weight
if representation_size is None:
nn.init.zeros_(self.head.weight)
nn.init.zeros_(self.head.bias)
else:
fan_in = self.head[0].in_features
nn.init.trunc_normal_(self.head[0].weight, std = math.sqrt(1/fan_in))
nn.init.zeros_(self.head[0].bias)
def forward(self, x):
x = self.input_embedding(x)
x = rearrange(x, "B C H W -> B (H W) C")
batch_class_token = self.class_token.expand(x.shape[0], 1, -1)
x = torch.cat([batch_class_token, x], dim = 1)
x = self.encoder(x)
x = self.head(x)
return xdef vit_b_16(**kwargs):
return VisionTransformer(img_size = 224, patch_size = 16, n_layers = 12, hidden_dim = 768, d_ff = 3072, n_heads = 12, representation_size = 768, **kwargs)
def vit_b_32(**kwargs):
return VisionTransformer(img_size = 224, patch_size = 32, n_layers = 12, hidden_dim = 768, d_ff = 3072, n_heads = 12, representation_size = 768, **kwargs)
def vit_l_16(**kwargs):
return VisionTransformer(img_size = 224, patch_size = 16, n_layers = 24, hidden_dim = 1024, d_ff = 4096, n_heads = 16, representation_size = 1024, **kwargs)
def vit_l_32(**kwargs):
return VisionTransformer(img_size = 224, patch_size = 32, n_layers = 24, hidden_dim = 1024, d_ff = 4096, n_heads = 16, representation_size = 1024, **kwargs)
def vit_h_14(**kwargs):
return VisionTransformer(img_size = 224, patch_size = 14, n_layers = 32, hidden_dim = 1280, d_ff = 5120, n_heads = 16, representation_size = 1280, **kwargs)model = vit_h_14(num_classes = 1000)summary(model, input_size=(2,3,224,224))
### Output ###
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
VisionTransformer [2, 1000] 1,280
├─Conv2d: 1-1 [2, 1280, 16, 16] 753,920
├─Encoder: 1-2 [2, 1280] 328,960
│ └─Dropout: 2-1 [2, 257, 1280] --
│ └─ModuleList: 2-2 -- --
│ │ └─EncoderLayer: 3-1 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-2 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-3 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-4 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-5 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-6 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-7 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-8 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-9 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-10 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-11 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-12 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-13 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-14 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-15 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-16 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-17 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-18 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-19 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-20 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-21 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-22 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-23 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-24 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-25 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-26 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-27 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-28 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-29 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-30 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-31 [2, 257, 1280] 19,677,440
│ │ └─EncoderLayer: 3-32 [2, 257, 1280] 19,677,440
│ └─LayerNorm: 2-3 [2, 1280] 2,560
├─Sequential: 1-3 [2, 1000] --
│ └─Linear: 2-4 [2, 1280] 1,639,680
│ └─Tanh: 2-5 [2, 1280] --
│ └─Linear: 2-6 [2, 1000] 1,281,000
===============================================================================================
Total params: 633,685,480
Trainable params: 633,685,480
Non-trainable params: 0
Total mult-adds (G): 1.65
===============================================================================================
Input size (MB): 1.20
Forward/backward pass size (MB): 1858.00
Params size (MB): 2533.42
Estimated Total Size (MB): 4392.63
===============================================================================================