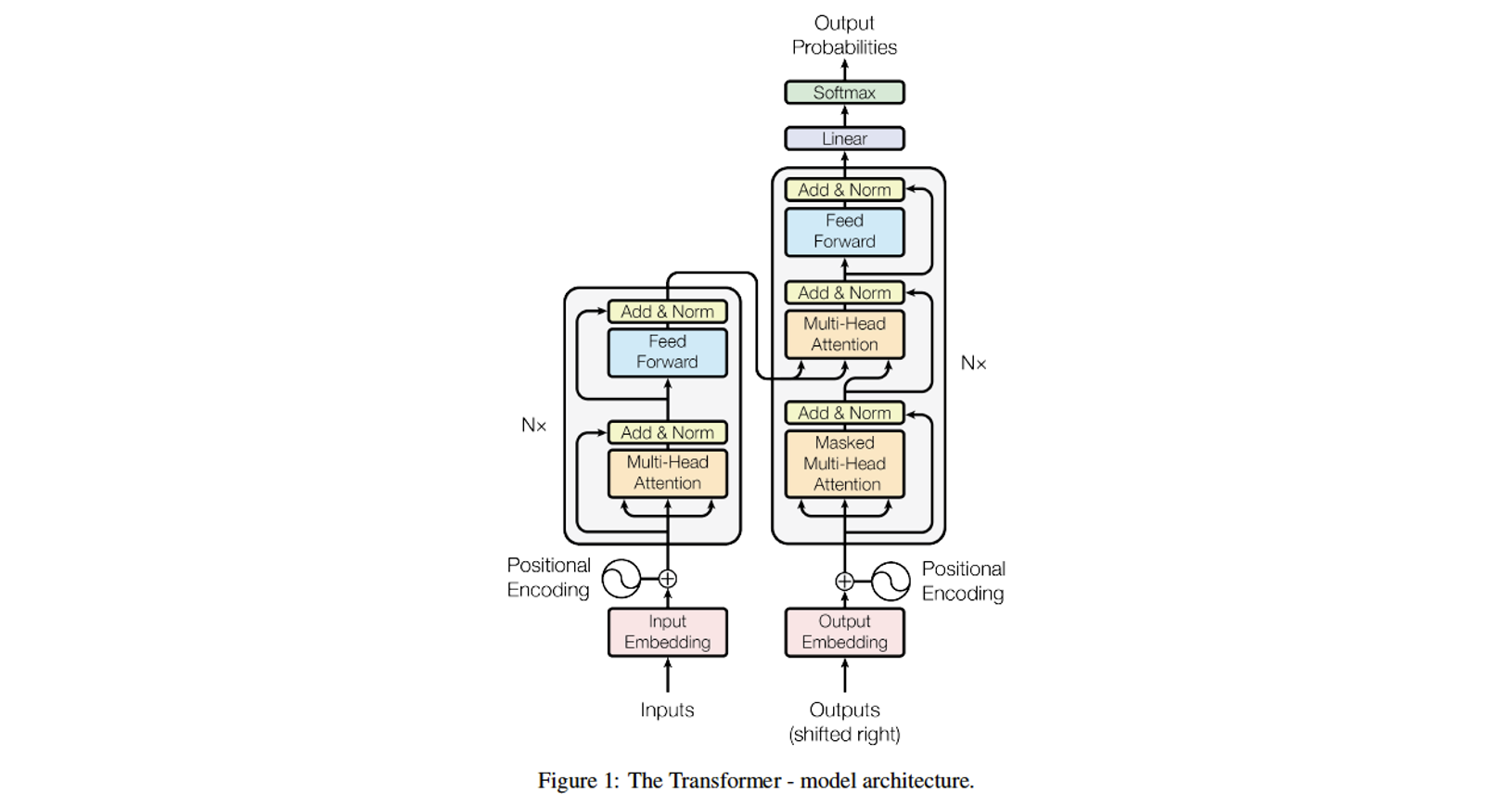
1. Introduction
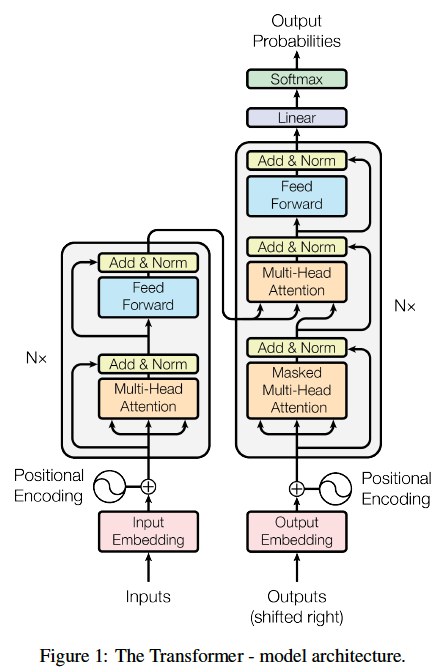
문장의 길이, 단어 간 거리에 따라 특정 단어에 대한 weight의 gradient가 소실되는 RNN의 고질적인 문제를 탈피한 새로운 모델 Transformer를 제시하였음.
2. Background
-
Seq2Seq (RNN)
RNN 기반의 번역 모델은 대표적으로 Seq2Seq 모델이 있음.
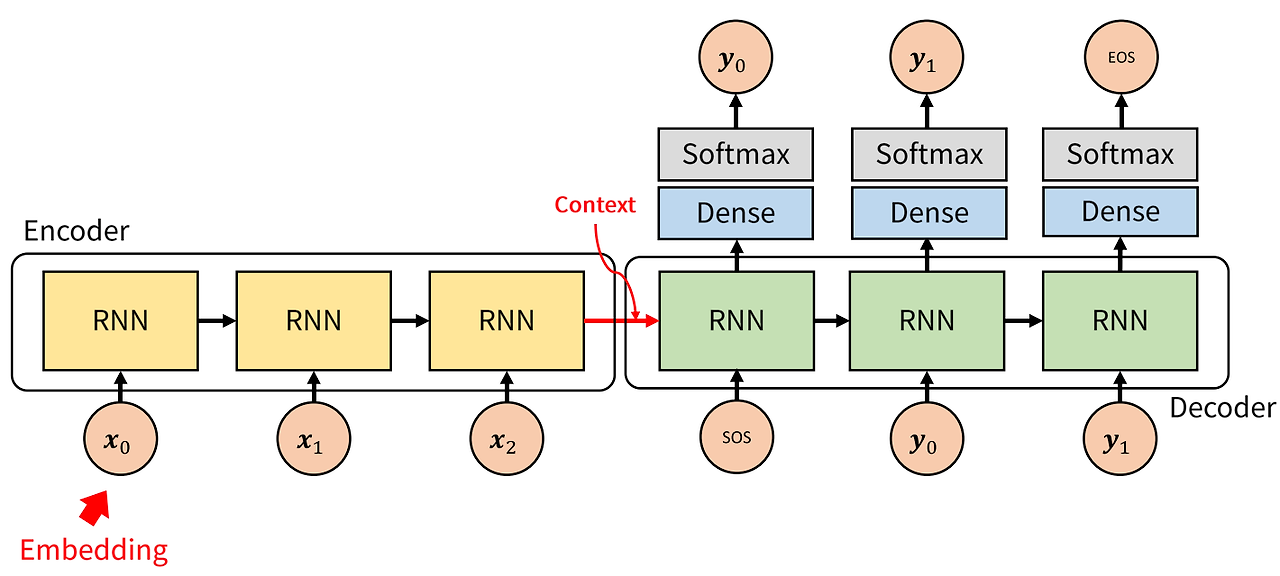 그림출처: https://ok-lab.tistory.com/180
그림출처: https://ok-lab.tistory.com/180
설명
문장을 단어들로 쪼개고 원핫 인코딩 한 후 Encoder를 구성하고 있는 RNN에 넣음. Encoder의 여러 RNN의 순전파 과정을 거치면서 Context 벡터가 만들어짐.
Context vector는 문장을 구성하는 단어들에 대한 정보를 순차적으로 모두 담고 있는 벡터임. 이 Context vector를 이용해 Decoder에서 문장 번역 작업을 함.
한계점
RNN은 activation function으로 tanh를 사용하는데 tanh의 값의 범위는 -1 ~ 1이다. RNN 구조상 가장 처음에 등장한 단어는 여러 번 tanh를 거치면서 값이 점점 작아지게 된다. 결론적으로 context vector에는 문장의 가장 마지막 단어에 대한 값이 가장 또렷하게 남아있고, 초기 단어일수록 흐려져 담긴다는 한계점이 있다. back propagation 관점에서도 tanh의 최대 기울기가 1인 것을 생각하면 weight를 업데이트를 위해 gradient를 계산할 때 문장 앞 쪽에 있는 단어는 고려하지 않을 것임을 알 수 있다. (Gradient가 매우 작아질 것이기 때문) -
RNN + attention
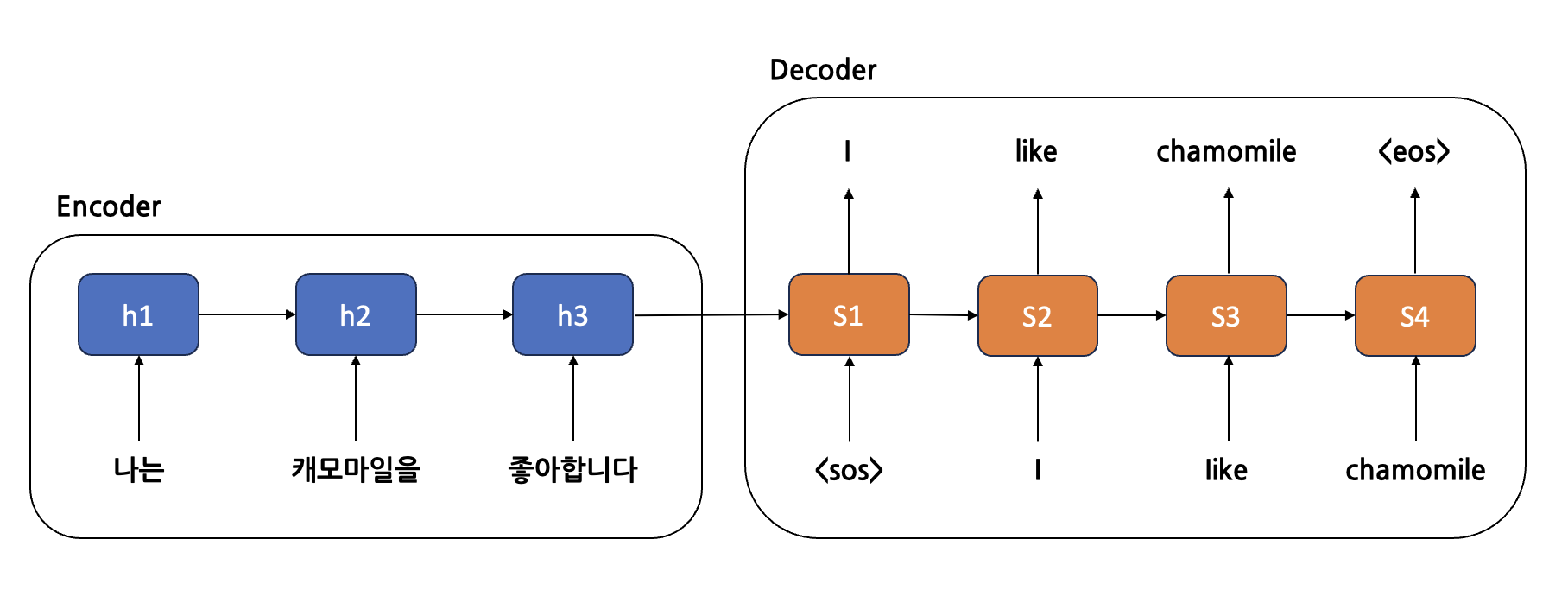 설명
설명
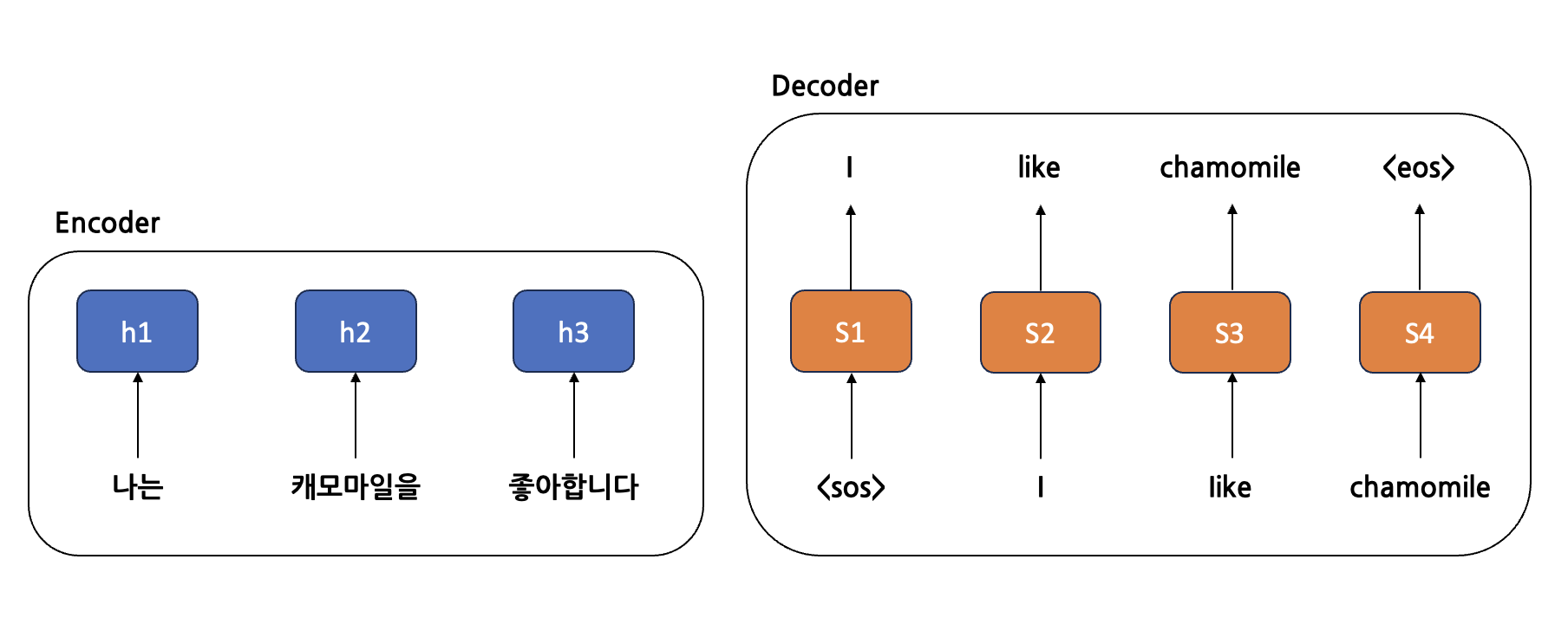
Attention mechanism을 적용하면 어떤 예측시점에서 어떤 단어를 주목할지 학습한다. 위 그림을 예시로 들어본다면, "나는 캐모마일을 좋아합니다" 문장을 "I like chamomile"로 번역하는 문제이다. 기존의 RNN 구조의 Seq2Seq의 문제점으로 하나의 Context vector를 사용했고, 그 Context vector의 정보에는 문장의 마지막 단어를 가장 강하게 담고 있다는 것인데 이를 해결하기 위해 attnetion을 도입하면서 각 예측시점마다 다른 Context vector를 사용하게 하였다.
각 단계에서 Contect vector는 h1, h2, h3의 정보가 담겨있어야 하고, 그 정보들을 각각 얼마나 반영할 지에 대해서도 표현되어야 한다.
이런 식으로 표현하면 될 것 같다. 예를 들어보자.
만약 S3시점에서 해당 context vector를 이용해 학습한다면 chamomile를 맞추기 위해 캐모마일을 임베딩 한 벡터인 에 더 비중을 두기 위해 를 키우는 방향으로 학습될 것이다.
실제로 attention은 아래와 같은 식으로 사용된다. (<> = 내적)
ex) 시점에서의 Context vector
이유는 다음과 같다.
(1) 는 의 함수여야 한다.
만약 문장이 "나는 캐모마일을 좋아합니다" 대신 "나는 캐모마일을 매우 좋아합니다" 라는 문장이 있다고 해보자. 그리고 각각 context vector를 만들 때 "좋아합니다." 라는 단어는 각각 , 로 인코딩 될 것이다. 의 비중을 높이려면 를 키워야 하고, 의 비중을 높이려면 를 키워야 한다. 즉, 같은 단어라도 문장의 길이에 따라 키워야 하는 weight가 달라지기 때문에 어떤 단어에 대한 를 키울 것인지 포함되어야 한다. 따라서 는 에 대한 함수여야 한다.
(2) 는 의 함수여야 한다.
예측시점마다 다른 Contect vector를 사용하기 때문에 예측시점을 알려줘야 한다.
(3) Scaler로 표현되면 좋을 것 같다.
내적을 사용하면 벡터간의 계산을 스칼라로 나타낼 수 있다.
한계점
Attention을 적용했지만 에는 의미를 잘 담지못하는 문제는 여전했다.
예를 들어, 문장을 구성하는 단어가 7개 있고, 마지막 단어는 쓰다()라는 단어가 있다고 해보자. 이 때 "쓰다" 라는 단어의 의미를 파악하기 위해서는 앞의 단어를 잘 살펴봐야 한다. (글을, 돈을, 모자를 ...) 그러나 RNN 구조상 문장 앞 쪽에 있는 단어의 의미는 흐려지기 때문에 를 임베딩 한 은 "쓰다" 라는 단어의 의미를 잘 담지 못하고 있다. 즉, 이 애초에 단어의 의미를 잘 담지 못하고 있으니 attention을 적용해도 소용이 없다.
-
Transformer
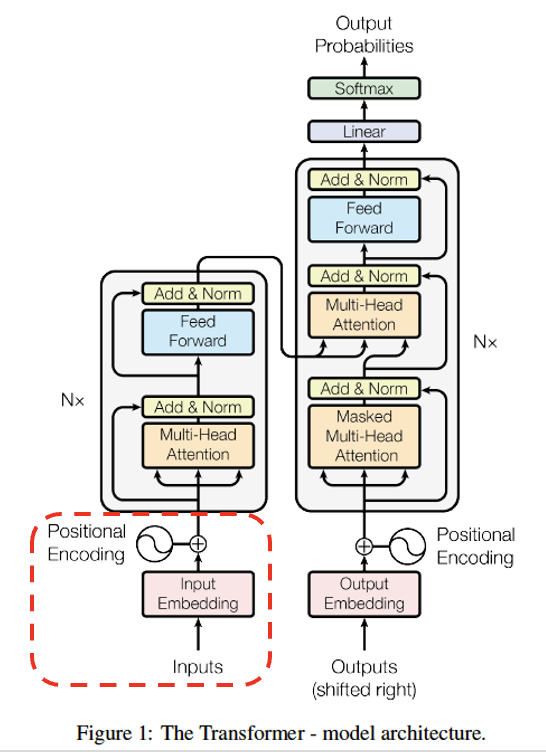
 이 논문의 저자들은 멀수록 단어의 의미를 잘 담지 못하는 문제가 RNN의 구조적인 문제에 있다고 판단하고 RNN을 완전히 버리고 (Recurrent 되는 연결을 끊고) attention mechanism을 적극 활용한 Transformer 논문을 발표하였다.
이 논문의 저자들은 멀수록 단어의 의미를 잘 담지 못하는 문제가 RNN의 구조적인 문제에 있다고 판단하고 RNN을 완전히 버리고 (Recurrent 되는 연결을 끊고) attention mechanism을 적극 활용한 Transformer 논문을 발표하였다.
Transformer에서 사용한 여러 Attention
(1) Self Attention
단어 임베딩 벡터를 쇄신하기 위한 attention이다.
(아래 예시는 를 쇄신하기 위한 self-attention 식이다.)
위에서 언급한 문제였던 "쓰다" 라는 단어를 Self-attention을 통해 앞 쪽의 단어들에 대한 attention으로 "쓰다"라는 의미를 쇄신할 수 있다.
(2) Masked Self Attention
부분적으로 masking이 된 Self-attention 이다.
디코더 부분의 단어를 self-attention할 때 현재 시점에서 뒷 부분에 있는 단어를 masking 해주어야 한다. (위 그림을 예시로 설명하자면.. 마스킹을 하지 않는다면 I를 보고 다음 단어인 like를 맞춰봐! 라고 하는 중에 정답을 보여주는 것과 같다.)
아래 예시는 를 쇄신하기 위한 Masked-Self-Attention 식이다.
에서 는 masking 해주어야 함. (=0으로 치환)
(3) Encoder-Decoder Self-Attention
Encoder와 부분과 Decoder부분에서 쇄신한 단어 임베딩 벡터들을 이용해 Context 벡터를 만들기 위한 Attention
아래 예시는 시점에서 들어갈 Context vector를 만들기 위한 Encoder-Decoder Attention 식이다.
3. Model
-
First Stage
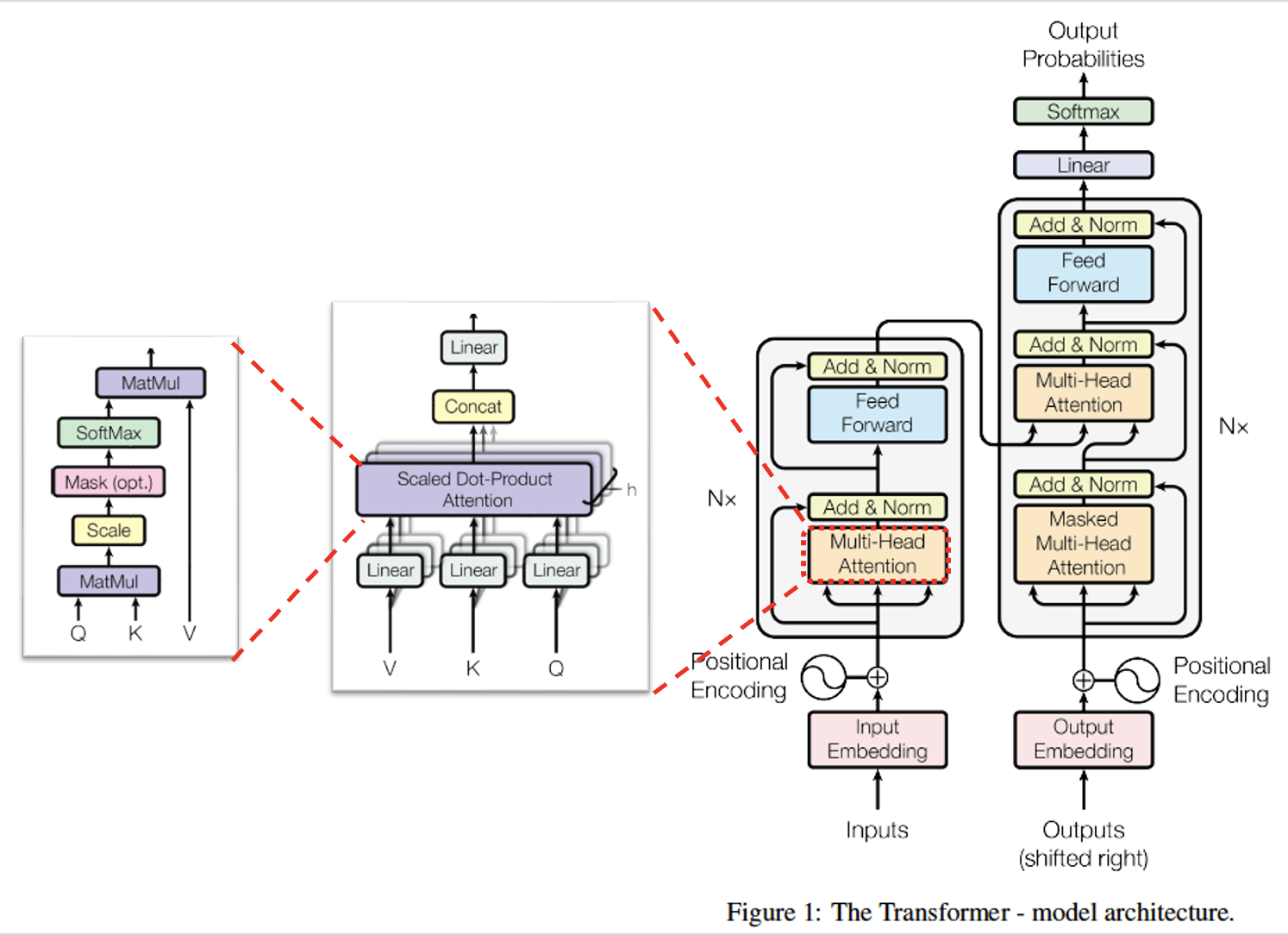
 (1) Input Embedding
(1) Input Embedding
맨처음 input은 이런 shape을 가진다.
(16은 문장의 개수, 30은 문장들 중 가장 긴 문장을 구성하고 있는 단어의 수, 7851은 사용할 수 있는 단어의 수이다.)
Input Embedding은nn.Linear라고 생각하면 쉽다. (실제 구현에서는nn.Embedding이지만nn.Linear으로 이해하는게 더 편하다.)
ex) 의 shape을 갖는 input을nn.Linear(7851, 512)를 통과시킨게 단어 임베딩 벡터이다.
()
(2) Positional Embedding
Recurrent구조를 끊어냄으로써 순서정보도 모두 사라졌다. 따라서 단어 순서에 대한 정보를 담고 있는 위치 임베딩 벡터를 만들어 attention에 활용하고자 한다. 단어의 위치를 원핫 인코딩 하고nn.Linear를 통과시키면 그게 위치 임베딩 벡터이다. (여기서도 마찬가지로 실제 구현에서는nn.Embedding)
ex)nn.Linear(max_len, 512)통과시키면 위치 임베딩 벡터이다.
()
(3) 단어 임베딩 벡터 + 위치 임베딩 벡터
그리고 단어 임베딩 벡터와 위치 임베딩 벡터를 더해준다. 이 때 단어 임베딩 벡터 정보를 더 고려하게끔 단어 임베딩 벡터에를 곱한 후 위치 임베딩 벡터를 더해준다. -> Self Attention할 준비 완료
()
-
Query & Key & Value
 First stage에서 만든 를 각각의
First stage에서 만든 를 각각의 nn.Linear에 통과시켜 Q, K, V를 얻는다.
()fc_q = nn.Linear(512, 64)Q ()
()fc_k = nn.Linear(512, 64)K ()
()fc_v = nn.Linear(512, 64)V ()
(1) Query: 관계를 물어볼 기준 단어 벡터
(2) Key: Query와 관계를 알아볼 단어 벡터
(3) Value: Key 단어의 의미를 담은 벡터 -
Multi-Head Attention
Multi-Head Attention은 여러 개의 Scaled Dot-Product Attention 결과를 Concat하고nn.Linear를 통과시킨 것을 말한다.
그렇다면 먼저 Scaled Dot-Product Attention을 살펴보자.
Scaled Dot-Product Attention
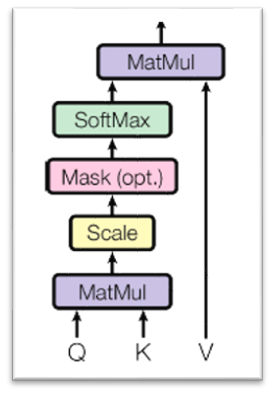 (1) MatMul: 와 를 내적
(1) MatMul: 와 를 내적
(2) Scale: 나눈다. ()
(3) Mask: Masking한다.
(4) Softmax 통과
(5) V를 내적.
이를 식으로 나타내면 아래와 같다.
Tensor의 shape은 변화하지 않는다.
() ()
Multi-Head Attention
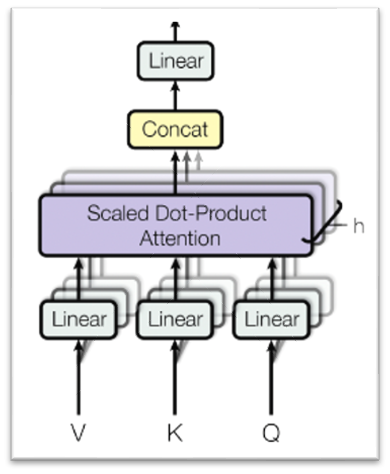
Scaled Dot-Product Attention을 8번 한다면? 를 8개 얻을 수 있다.
이를 head가 8개 있다고 표현한다.
(head가 8개라면, 각각 다른 가 8개가 생김.)
그리고 이것들을 가로로 concat한다면 이다.
이후nn.Linear(512, 512)를 통과시킨다.
끝이다.
이렇게 해서 얻는 효과는 무엇일까?
우선 Scaled Dot-Product를 여러번 함으로써 다양한 를 얻을 수 있다. 이는 각각 다른 관점으로 쇄신시킨 h를 8개 얻을 수 있다는 뜻이다. 그리고 이를 concat하고nn.Linear를 통과시킴으로써 각각 다른 관점으로 쇄신한 를 하나로 종합하는 것을 뜻한다.
또한 input size와 output size를 일치시킴으로써 skip-connection을 적용할 수 있게 한다. -
Encoder
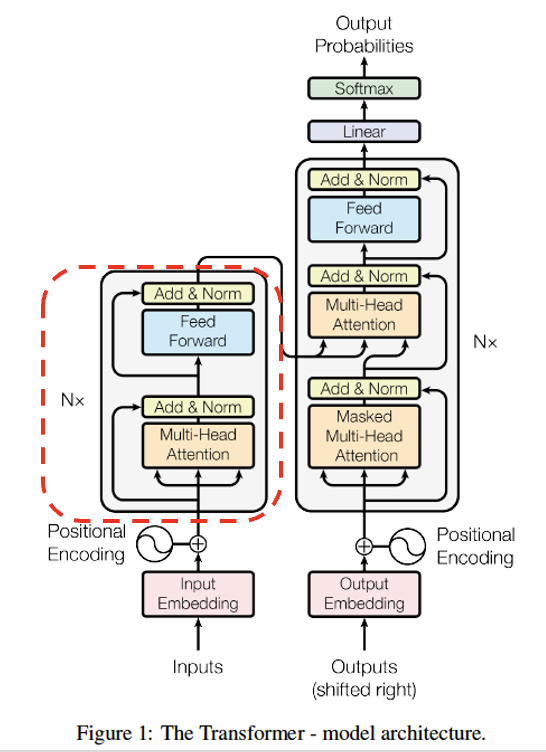 Encoder의 구성요소를 살펴보면, Multi-Head Attention, Add & Norm, Feed Forward이다. Multi-Head Attention은 위에서 살펴보았으므로 나머지를 살펴보자.
Encoder의 구성요소를 살펴보면, Multi-Head Attention, Add & Norm, Feed Forward이다. Multi-Head Attention은 위에서 살펴보았으므로 나머지를 살펴보자.
Add & Norm
Add: Skip-Connection
Norm: Layer Normalization (512개 샘플에 대해 normalization)
Feed Forward
nn.Linear(512, 2048)
nn.ReLU()
nn.Linear(2048, 512)
Encoder Layer
Encoder Layer는 아래와 같이 표현할 수 있다.
Multi-Head Attention - Add & Norm - Feed Forward - Add & Norm
Encoder
Encoder는 Encoder layer를 여러 번 반복한 것이다. (논문에서는 6번)
Encoder Layer 6
(을 만든다.) -
Decoder
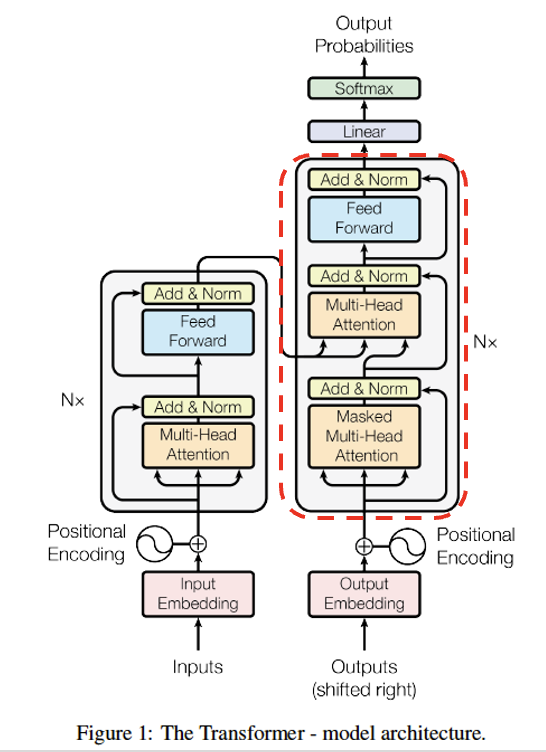 Decoder Layer
Decoder Layer
Masked Multi-Head Attention - Add & Norm
Multi-Head Attention - Add & Norm
Feed Forward - Add & Norm
으로 구성되어 있다.
Add & Norm과 Feed Forward는 Encoder에서 설명했던 것과 동일하다.
Masked-Multi-Head Attention, Multi-Head Attention (Encoder-Decoder Attention)을 살펴보자.
Masked-Multi-Head Attention
Attention 과정 중에 현재 시점의 뒷 단어를 보지 못하게 Softmax 직전 매우 작은 음수값을 취해 Softmax 함수 이후 0으로 나오도록 masking을 해주어야 해주는 과정이다. (코드에서 자세히 살펴보자.)
Encoder-Decoder Attention
Q로는 해당 Decoder layer에서 얻은 임베딩 벡터를,
K, V로는 마지막 Encoder Layer의 출력 임베딩 벡터를 사용하여 Attention 한다.
Decoder
Decoder는 Decoder layer를 여러 번 반복한 것이다. (논문에서는 6번)
Decoder Layer 6 -
the last stage
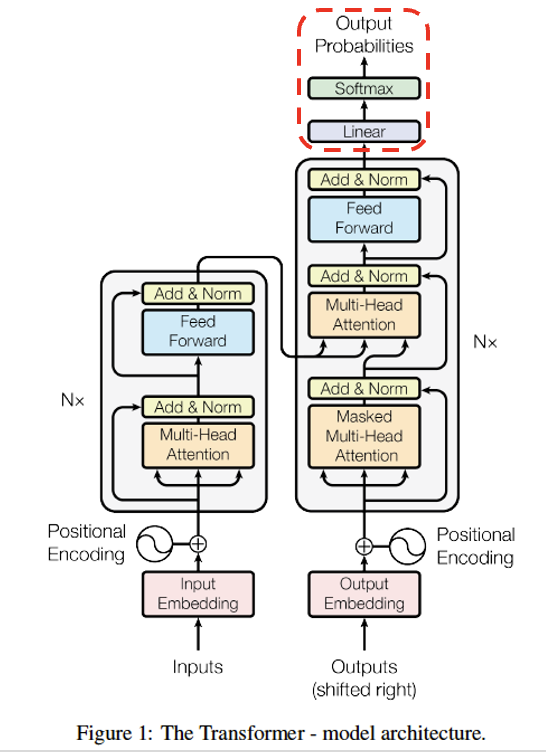 Decoder의 마지막 Layer의 출력을 사용
Decoder의 마지막 Layer의 출력을 사용
단순히 nn.Linear(512, 5972) 통과시키면 된다.
이후 softmax 통과시켜 가장 높은 확률에 해당하는 단어를 선택하면 된다.
4. Code
환경
- python 3.8.16
- pandas 2.0.3
- torch 2.2.2
- transformers 4.39.2
- einops 0.7.0
구현
Import packages
import pandas as pd
import numpy as np
import torch
from torch import nn, optim
from transformers import MarianTokenizer
from einops import rearrange
from torchinfo import summary
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(DEVICE)Load Tokenzier
# Load the tokenizer & input embedding layer & last fc layer
model_name = "Helsinki-NLP/opus-mt-ko-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
eos_idx = tokenizer.eos_token_id
pad_idx = tokenizer.pad_token_id
print("eos_idx: ", eos_idx) # eos_idx: 0
print("pad_idx: ", pad_idx) # pad_idx: 65000Set hyperparameter
max_len = 512
vocab_size = tokenizer.vocab_size #65001
n_layers = 6
d_model = 512
d_ff = 2048
n_heads = 8
drop_p = 0.1모델 구현 1 (Multi-Head Attention)
class MHA(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.n_heads = n_heads
self.scale = torch.sqrt(torch.tensor(d_model / n_heads))
self.fc_q = nn.Linear(d_model, d_model)
self.fc_k = nn.Linear(d_model, d_model)
self.fc_v = nn.Linear(d_model, d_model)
self.fc_o = nn.Linear(d_model, d_model)
def forward(self, Q, K, V, mask = None):
Q = self.fc_q(Q)
K = self.fc_k(K)
V = self.fc_v(V)
Q = rearrange(Q, "개 단 (헤 차) -> 개 헤 단 차", 헤 = self.n_heads)
K = rearrange(K, "개 단 (헤 차) -> 개 헤 단 차", 헤 = self.n_heads)
V = rearrange(V, "개 단 (헤 차) -> 개 헤 단 차", 헤 = self.n_heads)
attention_score = Q @ K.transpose(-2, -1) / self.scale
if mask is not None:
attention_score[mask] = -1e10
attention_weights = torch.softmax(attention_score, dim = -1)
attention = attention_weights @ V
x = rearrange(attention, "개 헤 단 차 -> 개 단 (헤 차)")
x = self.fc_o(x)
return x
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, drop_p):
super().__init__()
self.linear = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Dropout(drop_p),
nn.Linear(d_ff, d_model),
)
def forward(self, x):
x = self.linear(x)
return x모델 구현 2 (Encoder)
class EncoderLayer(nn.Module):
def __init__(self, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.self_atten = MHA(d_model, n_heads)
self.self_atten_LN = nn.LayerNorm(d_model)
self.FF = FeedForward(d_model, d_ff, drop_p)
self.FF_LN = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(drop_p)
def forward(self, x, enc_mask):
residual = self.self_atten(x, x, x, enc_mask)
residual = self.dropout(residual)
x = self.self_atten_LN(x + residual)
residual = self.FF(x)
residual = self.dropout(residual)
x = self.FF_LN(x + residual)
return x
class Encoder(nn.Module):
def __init__(self, input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.scale = torch.sqrt(torch.tensor(d_model))
self.input_embedding = input_embedding
self.pos_embedding = nn.Embedding(max_len, d_model)
self.dropout = nn.Dropout(drop_p)
self.layers = nn.ModuleList(
[EncoderLayer(d_model, d_ff, n_heads, drop_p) for _ in range(n_layers)]
)
def forward(self, src, mask):
pos = torch.arange(0, src.shape[1]).repeat(src.shape[0], 1).to(DEVICE)
x = self.scale * self.input_embedding(src) + self.pos_embedding(pos)
x = self.dropout(x)
for layer in self.layers:
x = layer(x, mask)
return x모델 구현 3 (Decoder)
class DecoderLayer(nn.Module):
def __init__(self, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.self_atten = MHA(d_model, n_heads)
self.self_atten_LN = nn.LayerNorm(d_model)
self.enc_dec_atten = MHA(d_model, n_heads)
self.enc_dec_atten_LN = nn.LayerNorm(d_model)
self.FF = FeedForward(d_model, d_ff, drop_p)
self.FF_LN = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(drop_p)
def forward(self, x, enc_out, dec_mask, enc_dec_mask):
residual = self.self_atten(x, x, x, dec_mask)
residual = self.dropout(residual)
x = self.self_atten_LN(x + residual)
residual = self.enc_dec_atten(x, enc_out, enc_out, enc_dec_mask)
residual = self.dropout(residual)
x = self.enc_dec_atten_LN(x + residual)
residual = self.FF(x)
residual = self.dropout(residual)
x = self.FF_LN(x + residual)
return x
class Decoder(nn.Module):
def __init__(self, input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p, vocab_size):
super().__init__()
self.scale = torch.sqrt(torch.tensor(d_model))
self.input_embedding = input_embedding
self.pos_embedding = nn.Embedding(max_len, d_model)
self.dropout = nn.Dropout(drop_p)
self.layers = nn.ModuleList(
[DecoderLayer(d_model, d_ff, n_heads, drop_p) for _ in range(n_layers)]
)
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, trg, enc_out, dec_mask, enc_dec_mask):
pos = torch.arange(0, trg.shape[1]).repeat(trg.shape[0], 1).to(DEVICE)
x = self.scale * self.input_embedding(trg) + self.pos_embedding(pos)
x = self.dropout(x)
for layer in self.layers:
x = layer(x, enc_out, dec_mask, enc_dec_mask)
x = self.fc_out(x)
return x모델 구현 4 (Transformer)
class Transformer(nn.Module):
def __init__(self, vocab_size, max_len, n_layers, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.input_embedding = nn.Embedding(vocab_size, d_model)
self.encoder = Encoder(self.input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p)
self.decoder = Decoder(self.input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p, vocab_size)
self.n_heads = n_heads
for m in self.modules():
if hasattr(m, "weight") and m.weight.dim() > 1: # input embedding은 그대로 쓰기 위함.
nn.init.xavier_uniform_(m.weight)
def make_enc_mask(self, src, pad_idx):
enc_mask = (src == pad_idx).unsqueeze(1).unsqueeze(2) #개11단
enc_mask = enc_mask.repeat(1, self.n_heads, src.shape[1], 1) #개헤단단
return enc_mask
def make_dec_mask(self, trg, pad_idx):
trg_pad_mask = (trg.to("cpu") == pad_idx).unsqueeze(1).unsqueeze(2)
trg_pad_mask = trg_pad_mask.repeat(1, self.n_heads, trg.shape[1], 1) #개헤단단
trg_future_mask = torch.tril(torch.ones(trg.shape[0], self.n_heads, trg.shape[1], trg.shape[1])) == 0
dec_mask = trg_pad_mask | trg_future_mask
return dec_mask
def make_enc_dec_mask(self, src, trg, pad_idx):
enc_dec_mask = (src == pad_idx).unsqueeze(1).unsqueeze(2)
enc_dec_mask = enc_dec_mask.repeat(1, self.n_heads, trg.shape[1], 1)
return enc_dec_mask
def forward(self, src, trg, pad_idx):
enc_mask = self.make_enc_mask(src, pad_idx)
dec_mask = self.make_dec_mask(trg, pad_idx)
enc_dec_mask = self.make_enc_dec_mask(src, trg, pad_idx)
enc_out = self.encoder(src, enc_mask)
out = self.decoder(trg, enc_out, dec_mask, enc_dec_mask)
return out모델 생성
model = Transformer(vocab_size, max_len, n_layers, d_model, d_ff, n_heads, drop_p).to(DEVICE)src = torch.tensor([[4,6,5,1,1,1],[7,7,1,1,1,1]]).to(DEVICE)
trg = torch.tensor([[2,5,4,4,3,65000,65000],[2,9,6,7,3,1,1]]).to(DEVICE)summary(model, input_data = [src, trg, pad_idx])===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Transformer [2, 7, 65001] --
├─Encoder: 1-1 [2, 6, 512] 52,456,960
├─Decoder: 1-2 -- (recursive)
│ └─Embedding: 2-1 [2, 6, 512] 33,280,512
├─Encoder: 1-3 -- (recursive)
│ └─Embedding: 2-2 [2, 6, 512] 262,144
│ └─Dropout: 2-3 [2, 6, 512] --
│ └─ModuleList: 2-4 -- --
│ │ └─EncoderLayer: 3-1 [2, 6, 512] 3,152,384
│ │ └─EncoderLayer: 3-2 [2, 6, 512] 3,152,384
│ │ └─EncoderLayer: 3-3 [2, 6, 512] 3,152,384
│ │ └─EncoderLayer: 3-4 [2, 6, 512] 3,152,384
│ │ └─EncoderLayer: 3-5 [2, 6, 512] 3,152,384
│ │ └─EncoderLayer: 3-6 [2, 6, 512] 3,152,384
├─Decoder: 1-4 [2, 7, 65001] 33,280,512
│ └─Embedding: 2-5 [2, 7, 512] (recursive)
│ └─Embedding: 2-6 [2, 7, 512] 262,144
│ └─Dropout: 2-7 [2, 7, 512] --
│ └─ModuleList: 2-8 -- --
│ │ └─DecoderLayer: 3-7 [2, 7, 512] 4,204,032
│ │ └─DecoderLayer: 3-8 [2, 7, 512] 4,204,032
│ │ └─DecoderLayer: 3-9 [2, 7, 512] 4,204,032
│ │ └─DecoderLayer: 3-10 [2, 7, 512] 4,204,032
│ │ └─DecoderLayer: 3-11 [2, 7, 512] 4,204,032
│ │ └─DecoderLayer: 3-12 [2, 7, 512] 4,204,032
│ └─Linear: 2-9 [2, 7, 65001] 33,345,513
===============================================================================================
Total params: 197,026,281
Trainable params: 197,026,281
Non-trainable params: 0
Total mult-adds (M): 289.14
===============================================================================================
Input size (MB): 0.07
Forward/backward pass size (MB): 16.14
Params size (MB): 445.16
Estimated Total Size (MB): 461.36
===============================================================================================