Unsloth로 Qwen 2.5 모델 파인튜닝 완료!
1.1 파인튜닝 방식 선택
파인튜닝 방식으로는 QLoRA(Low-Rank Adaptation) 를 선택했다. 전체 모델 파라미터를 학습시키는 대신, 일부 계층에만 저차원 가중치를 추가하는 방식이다.
Unsloth는 이러한 QLoRA 파인튜닝을 빠르고 안정적으로 수행할 수 있도록 도와주는 라이브러리였다.
1.2 베이스 모델 로드
베이스 모델로는 앞선 주차복습에도 주구장창 말한것 처럼 Qwen2.5-3B-Instruct를 사용했다. Unsloth에서 제공하는 4bit 양자화 버전을 불러와 메모리 사용량을 줄였다.
1.3 LoRA 어댑터 설정

LoRA 설정은 다음과 같이 구성했다.
-
r 값은 16으로 설정
-
lora_alpha는 32로 설정
-
dropout은 0
-
이 모든걸 Qwen 구조에 맞는 projection layer에만 적용
이 설정을 통해 베이스 모델은 고정하고, LoRA 어댑터만 학습되도록 구성했다.
1.4 학습 데이터 로드
학습 데이터는 jsonl 형식의 대화 데이터였다. 파일을 한 줄씩 읽는 generator 방식을 사용했다.
이 방식으로 데이터 형식에 문제가 있는 줄은 자동으로 건너뛰도록 했다. 덕분에 데이터 오류로 학습이 중단되는 상황을 피할 수 있었다.
1.5 파인튜닝 수행
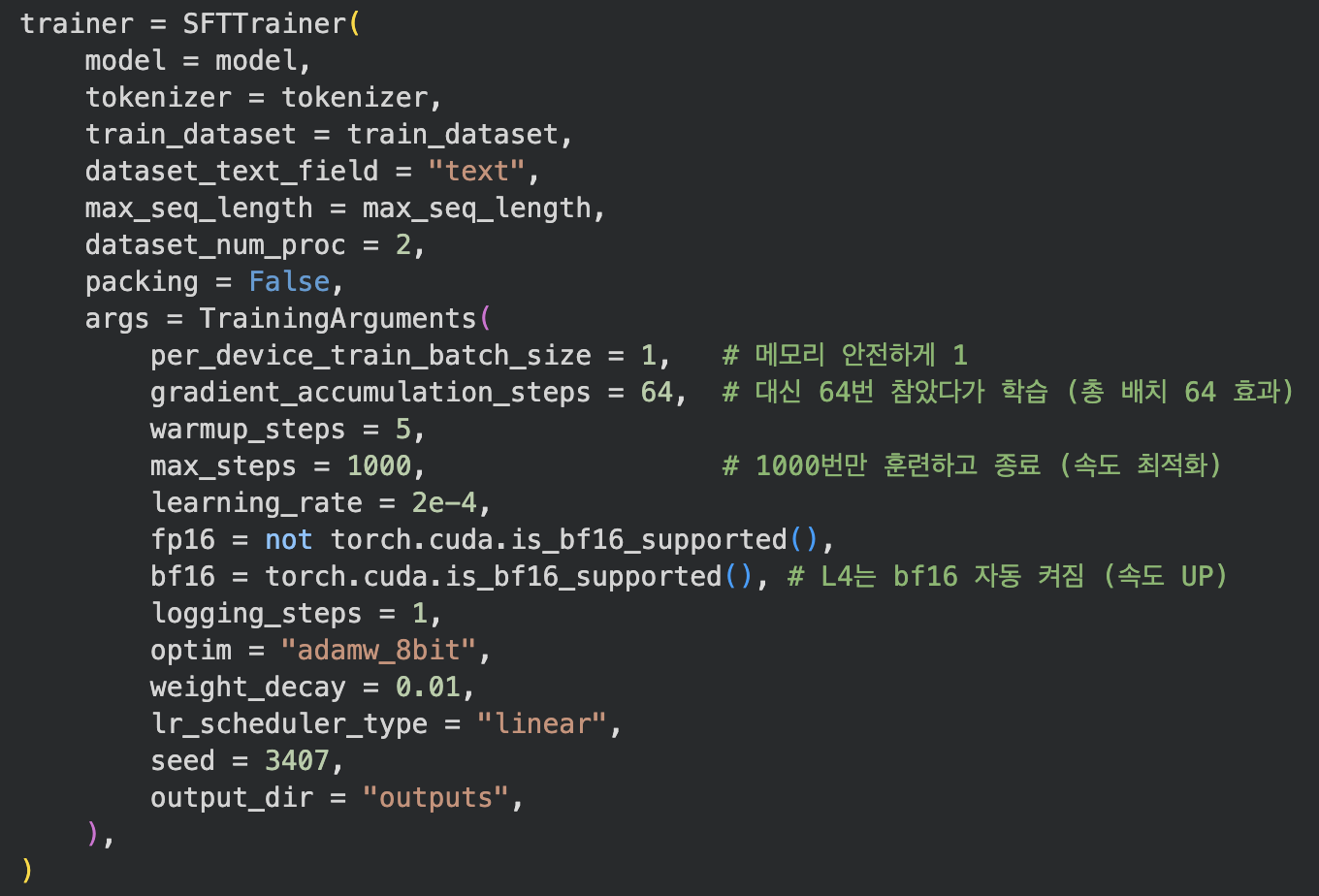
SFTTrainer를 사용해 파인튜닝을 수행했다.
Colab L4 환경에서 안정적으로 학습되도록 다음과 같이 설정했다.
-
배치 크기는 1로 설정
-
Gradient Accumulation을 64로 설정
-
학습 스텝은 1000으로 제한
-
8bit 옵티마이저를 사용
학습 중에는 loss가 점진적으로 감소하는 것 확인하였다!
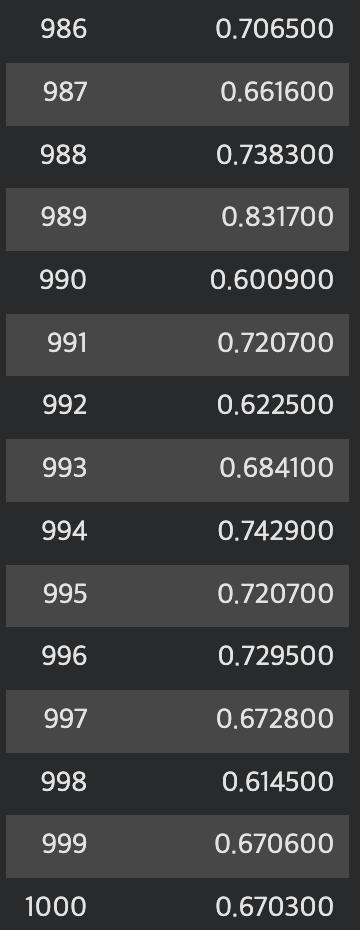

1.6 파인튜닝 결과 저장
학습이 끝난 뒤 모델을 저장했다. 이때 전체 모델이 아니라 LoRA 어댑터만 저장했다.
저장 결과는
Qwen2.5-3B-Legal-LoRA/
├─ adapter_model.safetensors
├─ adapter_config.json
├─ tokenizer.json
├─ vocab.json
├─ merges.txt
├─ chat_template.jinja
└─ tokenizer 관련 파일들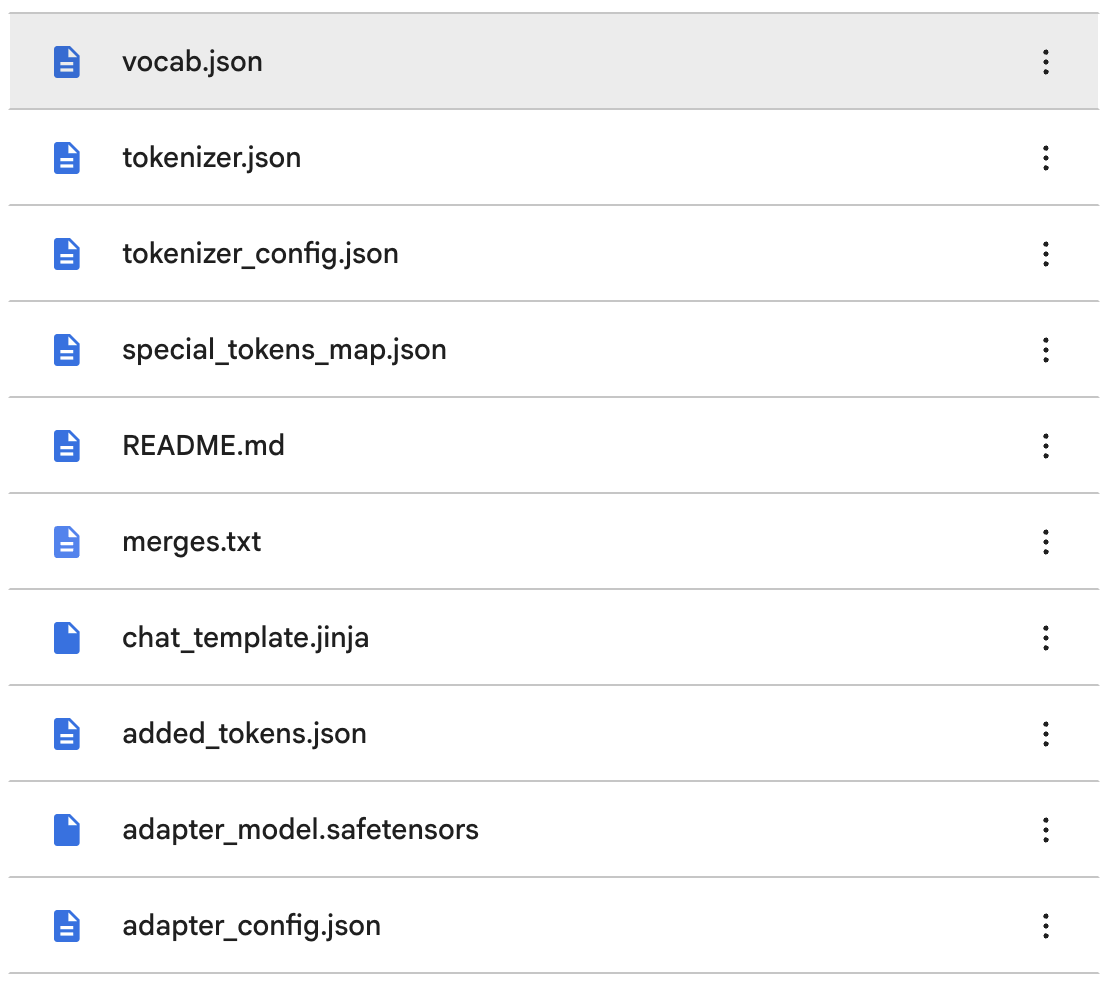
이러하다.
이렇게 저장한 이유는...
이후 다른 코드에서 이 폴더를 불러와 다시 사용할 수 있도록 하기 위해서다. RAG 방식도 해야하니까.. 그때 저장된 모델을 불러와야하니까!!! 저장한거다.
우선은 파인튜닝에 대한 미션을 완료했다. 이제는 해야할게... 바로 이 모델 성능을 평가하는 것이다. 성능 평가에 대한 건 아마 F1 score로 할 것 같다. 이젠 rag 단계를 완성해야한다.....우선은 rag를 써보고, 성능을 평가해보고 모델링을 마무리할 것 같다.
