트러블 슈팅 정리
전처리 단계: GPT-4o mini를 선택한 이유
전처리 단계에서 가장 먼저 고민한 질문은
“왜 GPT-OSS가 아니라 GPT-4o mini인가”이다.
전처리의 특성
전처리는 단일 문서를 처리하는 작업이 아니다. 많은 텍스트를 대상으로 정제, 요약, 구조화를 반복적으로 수행하는 단계이다.
따라서 이 단계에서는 모델의 성능보다도 API 안정성과 파이프라인 유지 가능성이 중요하다.
GPT-4o mini의 장점
-
API 형태로 즉시 사용 가능하다
-
텍스트 정제, 요약, 구조화 작업에 충분한 성능을 제공한다
-
별도의 실행 환경을 구성할 필요가 없다
이러한 이유로 전처리 파이프라인을 빠르게 구축하고 유지하는 데 적합하다고 판단했다.
GPT-OSS를 고려했으나 선택하지 않은 이유
GPT-OSS 역시 검토 대상이었다.
GPT-OSS는
-
토큰 비용이 들지 않고
-
모델을 직접 다운로드해 사용할 수 있으며
-
전처리를 내부에서 처리할 수 있다는 장점이 있다.
그러나 실제 실험 환경에서는 다음과 같은 한계가 존재한다.
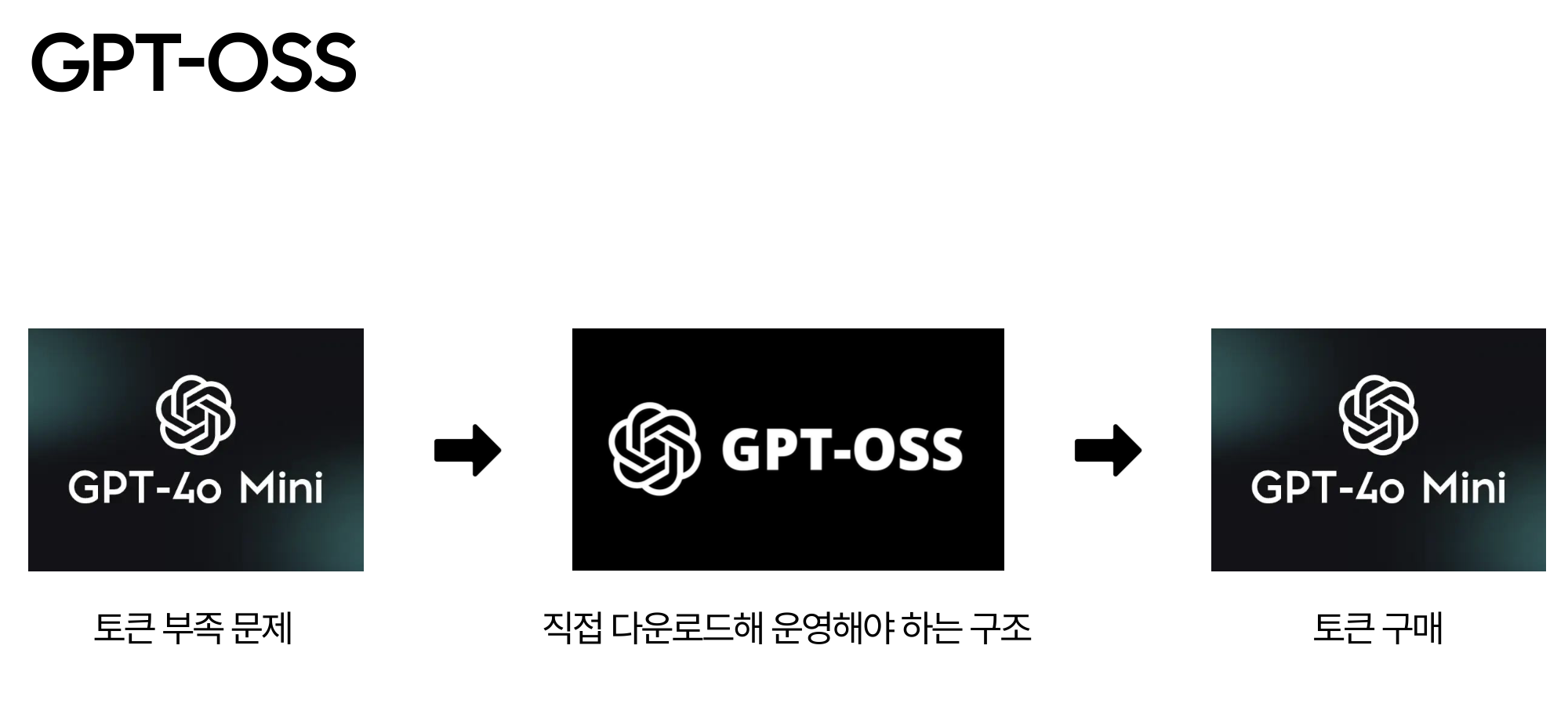
API 형태가 아닌, 모델 가중치를 직접 다운로드해야 하는 구조이다
Colab 환경에서 모델 로딩과 실행 부담이 크기 때문에, 전처리 파이프라인을 안정적으로 유지하기 어렵다.
이 때문에 우리의 DIET 프로젝트의 실험 환경에서는 리스크가 더 크다고 판단했다.
최종 선택: GPT-4o mini 유지
전처리 과정에서 토큰 부족 문제가 발생하기도 했다.
따라서 우리 팀은 토큰 사용량을 감안하고 추가 토큰을 구매하는 방식으로 해결하며 전처리 파이프라인의 안정성을 유지하는 방향을 선택했다.
모델링 단계: AutoTrain 대신 Unsloth를 선택한 이유
“왜 AutoTrain이 아니라 Unsloth인가?”
AutoTrain의 특징과 한계
사실 Autotrain 방식을 처음에 고려하여 진행하였다.
AutoTrain은
-
학습 데이터를 업로드하면
-
모델 선택, 하이퍼파라미터 설정, 학습까지
-
대부분의 과정을 자동으로 처리해주는 도구이다.
짧은 시간 안에 결과를 얻고 싶을 때는 매우 유용하다.
그러나 AutoTrain에는 다음과 같은 한계가 존재한다.
-
어떤 LoRA 설정이 사용되었는지 알기 어렵다
-
양자화가 어느 단계에서 적용되었는지 확인하기 어렵다
어떤 파라미터가 실제로 학습되었는지 드러나지 않는다
즉, 학습 과정이 불투명하다는 문제가 있다.
DIET 프로젝트와 AutoTrain의 거리감
DIET 프로젝트의 목적은 “파인튜닝된 모델을 하나 얻는 것”이 아니다.
- 경량화 기법을 직접 다루고
- 무엇을 줄였는지,
- 왜 줄였는지를 설명하며,
- 실험 과정을 명확하게 전달하는 것
이러한 목표에는 AutoTrain이 적합하지 않다고 판단했다.
Unsloth를 선택한 이유
Unsloth는 다음과 같은 특징을 가진다.
-
QLoRA를 기본 학습 방식으로 사용한다
-
양자화된 모델에 최적화된 구조를 가진다
-
학습 과정을 코드 레벨에서 직접 확인할 수 있다
즉,
- 모델 전체를 학습하지 않고
- 저랭크 어댑터만 학습하여
- 메모리 사용량을 크게 줄이는 방식이다.
Unsloth의 장점
-
학습 속도가 빠르다
-
반복 실험이 가능하다
-
다양한 설정을 직접 비교할 수 있다
따라서 이러한 특성 때문에 경량화 실험을 중심으로 한 DIET 프로젝트의 방향성에는 unsloth 학습 방식이 더 알맞다고 판단을 하여 학습 방식을 autotrain에서 바꾸었다.

