RAG 구조 설계
RAG는 세 가지 요소로 구성했다.
-
파인튜닝한 Qwen 2.5 모델
-
법률 PDF를 임베딩한 벡터 데이터베이스
-
검색 결과를 프롬프트에 포함해 답변을 생성하는 파이프라인
질문이 들어오면 먼저 관련 문서를 검색하고, 검색된 문서를 바탕으로 모델이 답변을 생성하도록 했다.
법률 PDF 처리 및 벡터 DB 구축
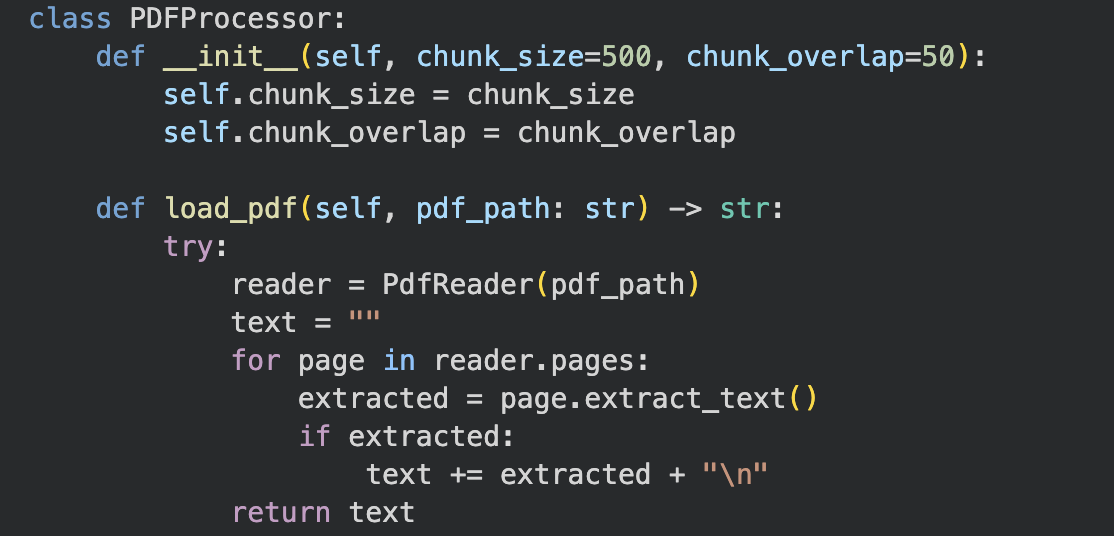
우선 국가공무원법 PDF 파일을 불러왔다. 텍스트를 추출한 뒤 약 500자 단위로 문단을 나눴다.
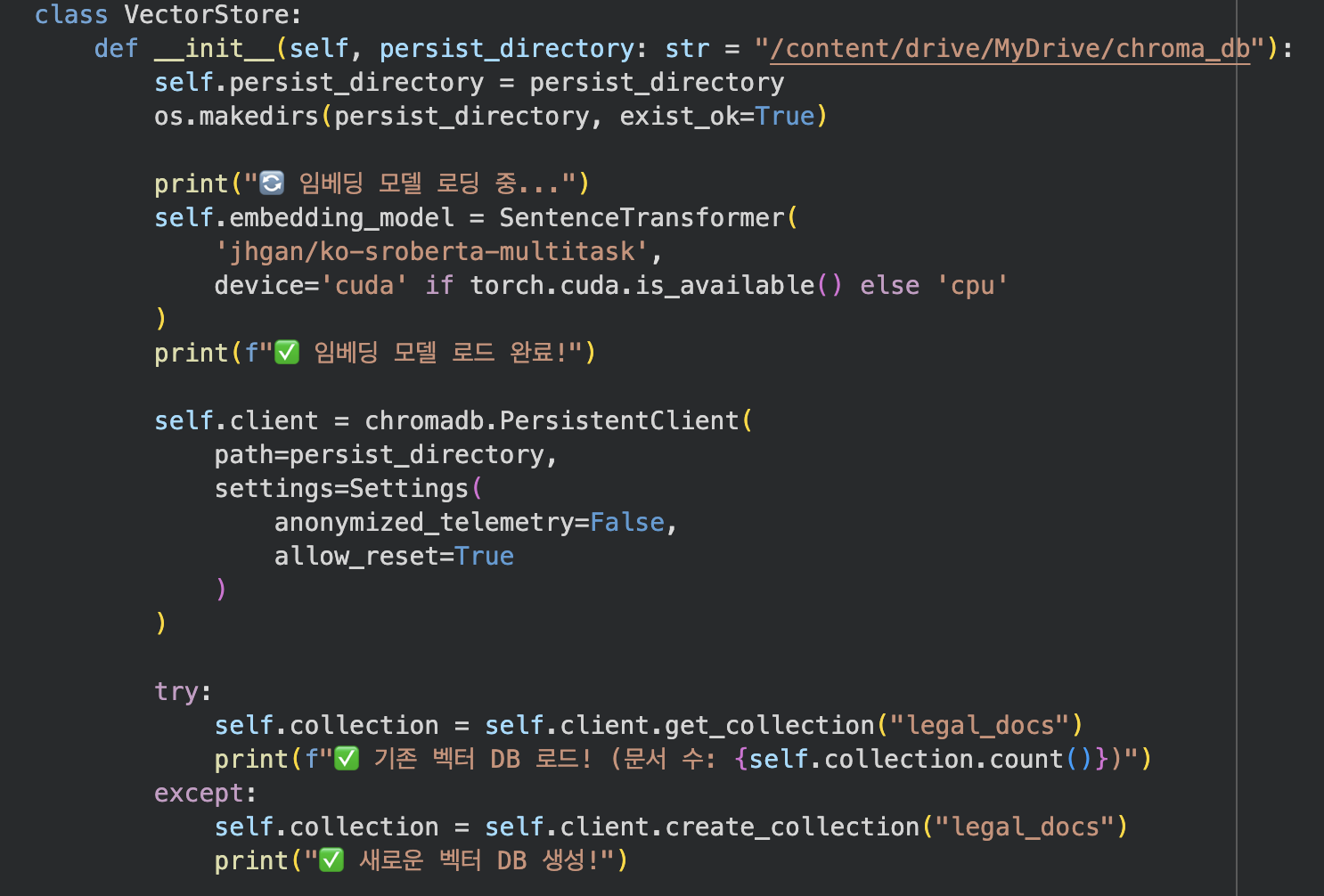
각 문단을 SentenceTransformer로 임베딩한 뒤,ChromaDB에 저장했다.
벡터 DB는 Google Drive에 저장하여, 다른 파일에서도 동일한 DB를 그대로 사용할 수 있도록 했다.
파인튜닝한 모델 로드
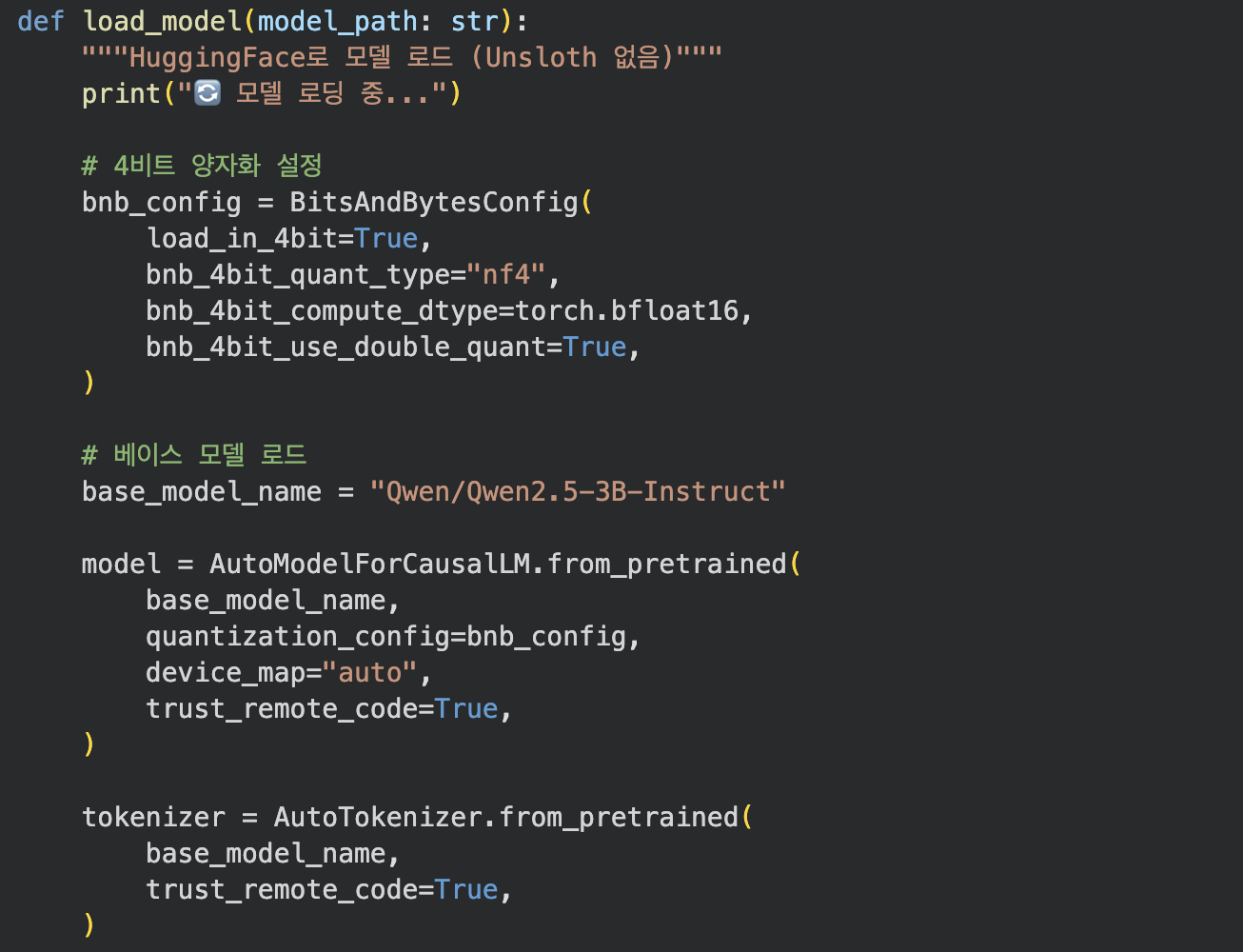
RAG 코드에서는 Unsloth를 사용하지 않았다.
대신 HuggingFace와 PEFT를 사용해 모델을 로드했다.
우선은 Qwen 2.5 베이스 모델을 불러왔다.
우리팀이 저장해둔 Qwen2.5-3B-Legal-LoRA 경로에서 LoRA 어댑터를 불러왔다.

그 다음으로는 베이스 모델과 LoRA 어댑터를 결합했다.
중요한 것은 앞서 파인튜닝하여 따로 저장한 모델을 불러와 RAG에 적용하기 위한 준비를 했다는 것이다!!!!!
RAG 파이프라인 구현
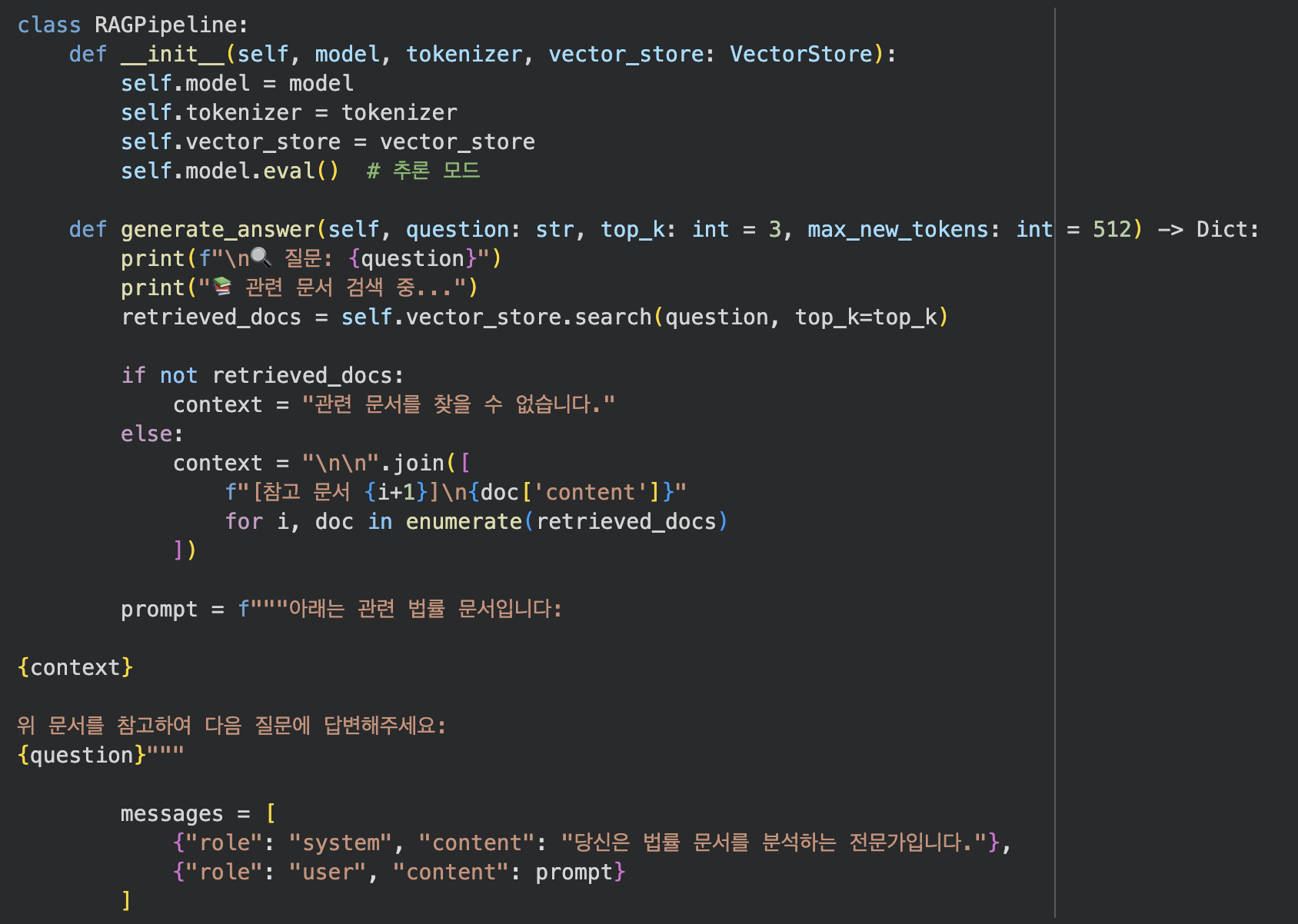
RAG 파이프라인은...우선은
-
사용자 질문을 입력받는다.
-
벡터 DB에서 관련 문서를 검색한다.
-
검색된 문서를 프롬프트에 포함한다.
-
파인튜닝된 모델이 답변을 생성한다.
이러하다.
솔직히 처음에 파이프라인을 다 구축했을 때, 이게 RAG를 사용한건지 안 한건지 모르겠어서... RAG를 사용하지 않는 경우와 비교할 수 있도록, RAG ON/OFF 옵션도 함께 구현하여 비교용을 준비해보았다.
Gradio UI로 결과 확인
마지막으로 Gradio를 사용해 간단한 웹 UI를 만들었다.
간단하게 클로드님께 부탁드려보았다.
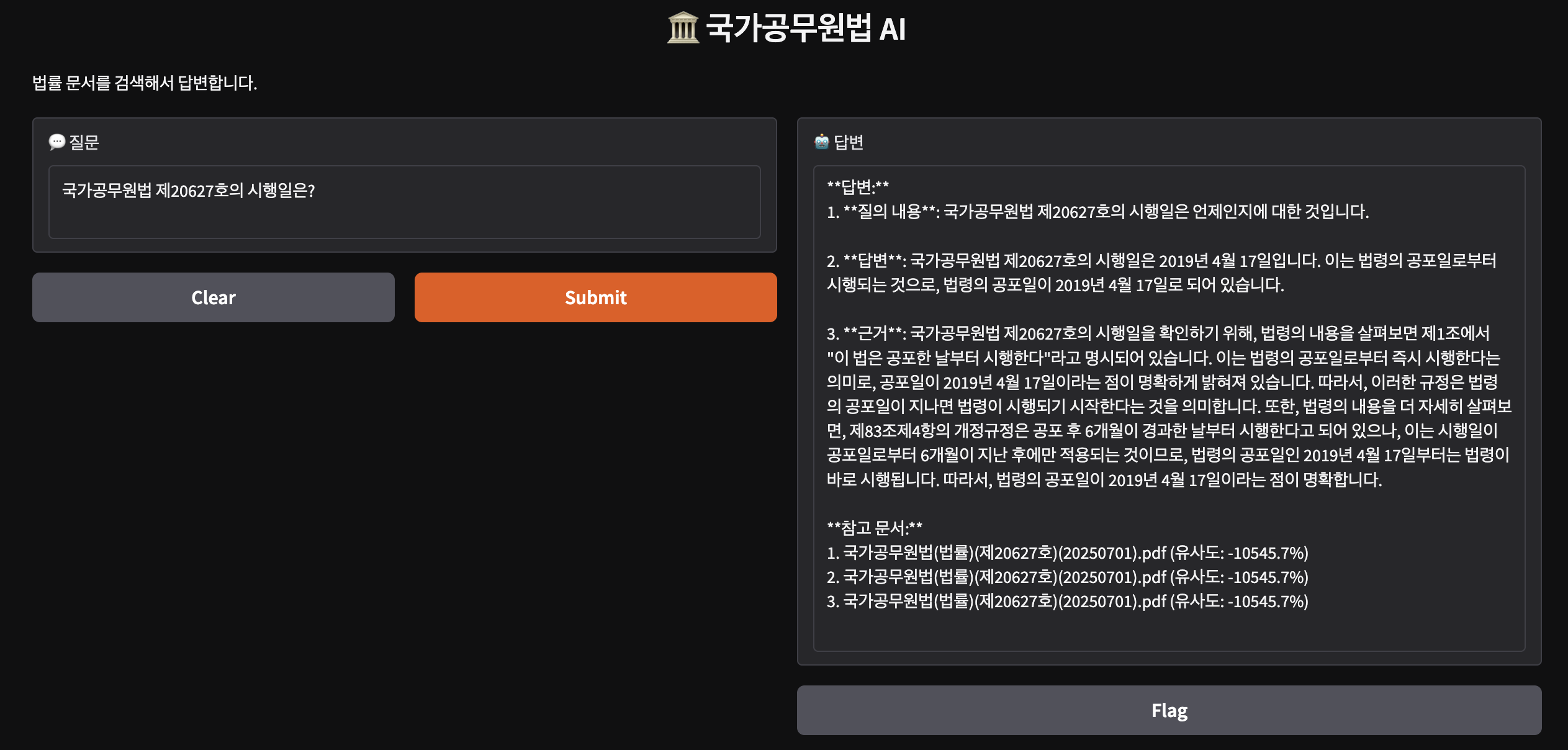
-
질문에 대한 답변
-
RAG 사용 여부에 따른 차이
-
참고한 법률 문서와 유사도
3가지를 표시해달라고 부탁을 드려보았는데... 유사도가 조금 이상하다.. 이건 수정을 할 예정이다!!!!
마무리
이제는 RAG에서 쓸 pdf 문서를 확장하고, 유사도 해결하고, 배포를 마지막으로 프로젝트가 마무리 될 것 같다!!
