라이브러리 import 및 TensorFlow 버전 확인
# 라이브러리 import 및 TensorFlow 버전 확인
import tensorflow as tf
import numpy as np
import pandas as pd
print("TensorFlow version:", tf.__version__)Numpy, Pandas, TensorFlow
Numpy
Numpy의 공식문서(https://numpy.org/doc/stable/)에 따르면, 파이썬에서 과학적 계산(scientific computing)을 하기 위한 핵심 라이브러리라고 한다. 데이터 분석, 인공지능, 수학, 물리학, 통계학 등 거의 모든 과학적 연산의 기초가 된다고 한다.
Pandas
Pandas는 오픈 소스(BSD 라이선스) 로 배포되는 고성능(high-performance), 사용하기 쉬운(easy-to-use) 데이터 구조(data structures) 와 데이터 분석 도구(data analysis tools) 를 제공하는 Python용 라이브러리이다.
Tensorflow
TensorFlow는 구글의 Google Brain 팀이 만든 오픈소스 머신러닝/딥러닝 프레임워크이다. 초보자이건 전문가이건 관계없이, 머신러닝 모델을 구축하고 배포하기 쉽게 해주는 엔드투엔드(end-to-end) 플랫폼이다.
데이터 다운로드
# 데이터 다운로드
path_to_train_file = tf.keras.utils.get_file(
'train.txt',
'https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt'
)
path_to_test_file = tf.keras.utils.get_file(
'test.txt',
'https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt'
)Keras 와 Tensorflow의 관계
Keras는 딥러닝 모델을 쉽고 빠르게 설계하기 위한 고수준 API이다. Keras는 TensorFlow 위에서 동작하는 사용자 인터페이스이다. 즉 다시말해서 tensorflow는 디테일한 조작이 가능하고, keras는 조금 더 사용자 친화적이다.
text로 로드
# 텍스트로 로드
path_to_train_file = tf.keras.utils.get_file(
'train.txt',
'https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt'
)
path_to_test_file = tf.keras.utils.get_file(
'test.txt',
'https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt'
)
train_text = open(path_to_train_file, 'rb').read().decode(encoding='utf-8')
test_text = open(path_to_test_file, 'rb').read().decode(encoding='utf-8')
print('Length of train text: {} characters'.format(len(train_text)))
print('Length of test text: {} characters'.format(len(test_text)))
print(train_text[:300]) train data와 test data, Overfitting
train data는 말 그대로 훈련시키는데 사용되는 데이터이다.
test data는 train data로 학습시킨 머신러닝 모델의 성능을 확인하는 데이터이다.
이 둘을 나누는 이유는 바로 과적합을 없애기 위해서이다.
과적합이란, 모델이 훈련 데이터에 너무 지나치게 특화되어 훈련 데이터 성능은 매우 높게 나오지만, test data(새로운 데이터)에서는 성능이 현저히 떨어지는 현상을 말한다.
쉽게 설명하자면, 모델이 데이터를 암기만 해버린 결과라고 볼 수 있다.
예를 들어, 우리가 시험을 보기전, 문제집을 푸는데 100점이 나온다고, 실제 시험에서 100점이 나오는게 아니다. 이처럼 모델도 train data의 모든 잡음을 다 외워버리면, 훈련 성능과 테스트 성능 사이에 큰 차이가 나타나게 된다.
Y(정답 라벨) 데이터 만들기
# Y(정답 라벨) 데이터 만들기
train_Y = np.array([
[int(row.split('\t')[2])]
for row in train_text.split('\n')[1:]
if row.count('\t') > 0
])
test_Y = np.array([
[int(row.split('\t')[2])]
for row in test_text.split('\n')[1:]
if row.count('\t') > 0
])
print("train_Y shape:", train_Y.shape)
print("test_Y shape:", test_Y.shape)
print("train_Y sample:", train_Y[:5])데이터 정제
import re
def clean_str(string):
string = re.sub(r"[^가-힣A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
string = re.sub(r"\'{2,}", "\'", string)
string = re.sub(r"\'", "", string)
return string.lower()
train_text_X = [row.split('\t')[1] for row in train_text.split('\n')[1:] if row.count('\t') > 0]
train_text_X = [clean_str(sentence) for sentence in train_text_X]
# 문장을 띄어쓰기 단위로 단어 분리
sentences = [sentence.split(' ') for sentence in train_text_X]
for i in range(5):
print(sentences[i])지도학습
지도 학습은 '정답(label)이 있는 문제집'으로 모델을 가르치고, '정답이 없는 새로운 시험지(test data)'로 실력을 평가하는 방식이다.
지도학습 vs 비지도학습
지도 학습은 정답을 알고 학습하는 방식이라면, 비지도 학습은 모델이 스스로 데이터를 탐색하고, 분류하고, 정리하면서 데이터의 숨겨진 의미를 파악하는 학습 방법이다.
예를 들자면, 지도 학습은 "이 사진은 고양이야."라고 정답을 제시해주는 방법이고, 비지도 학습은 "여기 사진 100장이 있어. 뭐가 뭔지 네가 알아서 분류해 봐." 라고 정답 없이 데이터만 제시해주는 방법이다.
데이터 전처리
VOCAB_SIZE = 2000 # 단어 사전 크기
MAX_LEN = 25 # 최대 문장 길이 (패딩 기준)
vectorize_layer = tf.keras.layers.TextVectorization(
standardize='lower_and_strip_punctuation', # 소문자 변환 + 구두점 제거
split='whitespace', # 띄어쓰기 기준 토큰화
max_tokens=VOCAB_SIZE, # 단어 사전 크기
output_mode='int', # 정수 인코딩
output_sequence_length=MAX_LEN # 자동 패딩
)
vectorize_layer.adapt(train_text_X) # 단어 사전 학습
# 텍스트를 정수 시퀀스로 변환 (패딩 포함)
train_X = vectorize_layer(train_text_X)
print(train_X[:5])전처리(Preprocessing)
데이터 전처리란 모델이 이해할 수 있도록 데이터를 정제하고 변환하는 과정이다. IBM의 CPLEX Optimization Studio 문서에서는 전처리를 “모델링 이전 단계에서 데이터를 일관성 있게 준비하고, 최적화 모델이 잘 작동하도록 도와주는 과정” 이라고 정의한다.
즉, 전처리는 단순히 데이터를 예쁘게 다듬는 과정이 아니라
모델이 최적의 결정을 내릴 수 있도록 데이터의 구조를 준비하는 핵심 단계이다.
1. 데이터 정제(Cleaning)
데이터 정제는 가장 기본적이고 중요한 단계이다. 이 과정에서는 결측치, 이상치, 중복값 등을 찾아 제거하거나 보완한다.
- 결측치 처리: 평균값, 중앙값 대체 또는 행·열 삭제
- 이상치 제거: 통계적 범위(IQR) 또는 표준편차 기준으로 제거
- 중복 데이터 제거: 동일한 레코드 중복 시 하나만 남긴다
2. 데이터 변환(Transformation)
데이터를 일정한 스케일로 맞추거나, 모델이 이해하기 쉬운 형태로 변환하는 단계이다.
-
정규화(Normalization): 데이터를 0~1 범위로 조정
-
표준화(Standardization): 평균 0, 표준편차 1로 변환
-
로그 변환(Log Transformation): 값의 크기 차이가 큰 경우 분포를 안정화
이러한 수치 변환 외에도, 비정형 데이터를 수치형으로 바꾸는 과정이 포함된다. 대표적인 예가 바로 벡터화(Vectorization) 이다.
벡터화는 텍스트, 이미지, 오디오와 같은 데이터를
모델이 계산할 수 있는 숫자 벡터 형태로 표현하는 과정이다.
머신러닝과 딥러닝 모델은 문자나 이미지를 직접 이해하지 못하므로,
모든 입력 데이터는 결국 벡터 형태로 변환되어야 한다.
예를 들어,
"이 영화 정말 재미있다" → [2, 5, 9, 11]
처럼 숫자 인덱스 시퀀스로 표현될 수 있다.
즉, 벡터화는 데이터 변환(Transformation) 단계에서
비정형 데이터를 수치화하는 핵심 절차이며,
모델이 실제로 학습 가능한 형태로 데이터를 변환해주는 과정이다.
3. 인코딩(Encoding)
문자형 데이터(범주형 데이터)를 숫자형으로 바꾸는 과정이다. 숫자형으로 바꾸는 이유는 머신러닝 모델은 문자열을 직접 처리할 수 없기 때문이다.
-
라벨 인코딩(Label Encoding): 카테고리에 정수 번호를 부여한다.
예: “red, blue, green” → 0, 1, 2 -
원-핫 인코딩(One-Hot Encoding): 각 카테고리를 별도 열로 변환
예: “red” → [1,0,0], “blue” → [0,1,0], “green” → [0,0,1]
4. 차원 축소(Dimensionality Reduction)
데이터의 변수(차원)가 너무 많을 경우,
정보 손실을 최소화하면서 데이터의 구조를 간단하게 만드는 과정이다.
-
PCA (Principal Component Analysis): 주성분 분석
-
t-SNE: 시각화용 비선형 차원 축소 기법
-
LDA: 클래스 간 분리를 극대화하는 방식
차원 축소는 학습 속도를 향상시키고, 과적합(overfitting)을 방지하는 데 도움이 된다.
5. 데이터 분할(Splitting)
모델 평가를 위해 데이터를 훈련(Train), 검증(Validation), 테스트(Test) 세 부분으로 나누는 단계이다.
나눈 데이터를 가지고, train data로 학습하고, validation data로 하이퍼파라미터를 조정하며, test data로 최종 성능을 평가한다.
패딩(Padding)
패딩(Padding)은 벡터의 길이를 통일시켜 주는 기능이다.
데이터를 벡터화(Vectorization)했을 때, 길이가 다른 벡터들을 맞추기 위해, 뒷부분에 0 (padding token)을 추가해준다.
이러한 패딩을 사용하는 이유는 길이가 다른 문장들을 한 묶음(batch)으로 효율적으로 처리하기 위해, 모든 벡터의 길이를 가장 긴 시퀀스에 맞춰 고정해야 하기 때문이다.
시각화
import matplotlib.pyplot as plt
sentence_len = [len(sentence) for sentence in sentences]
sentence_len.sort()
plt.plot(sentence_len)
plt.show()
print(sum([int(l<=25) for l in sentence_len]))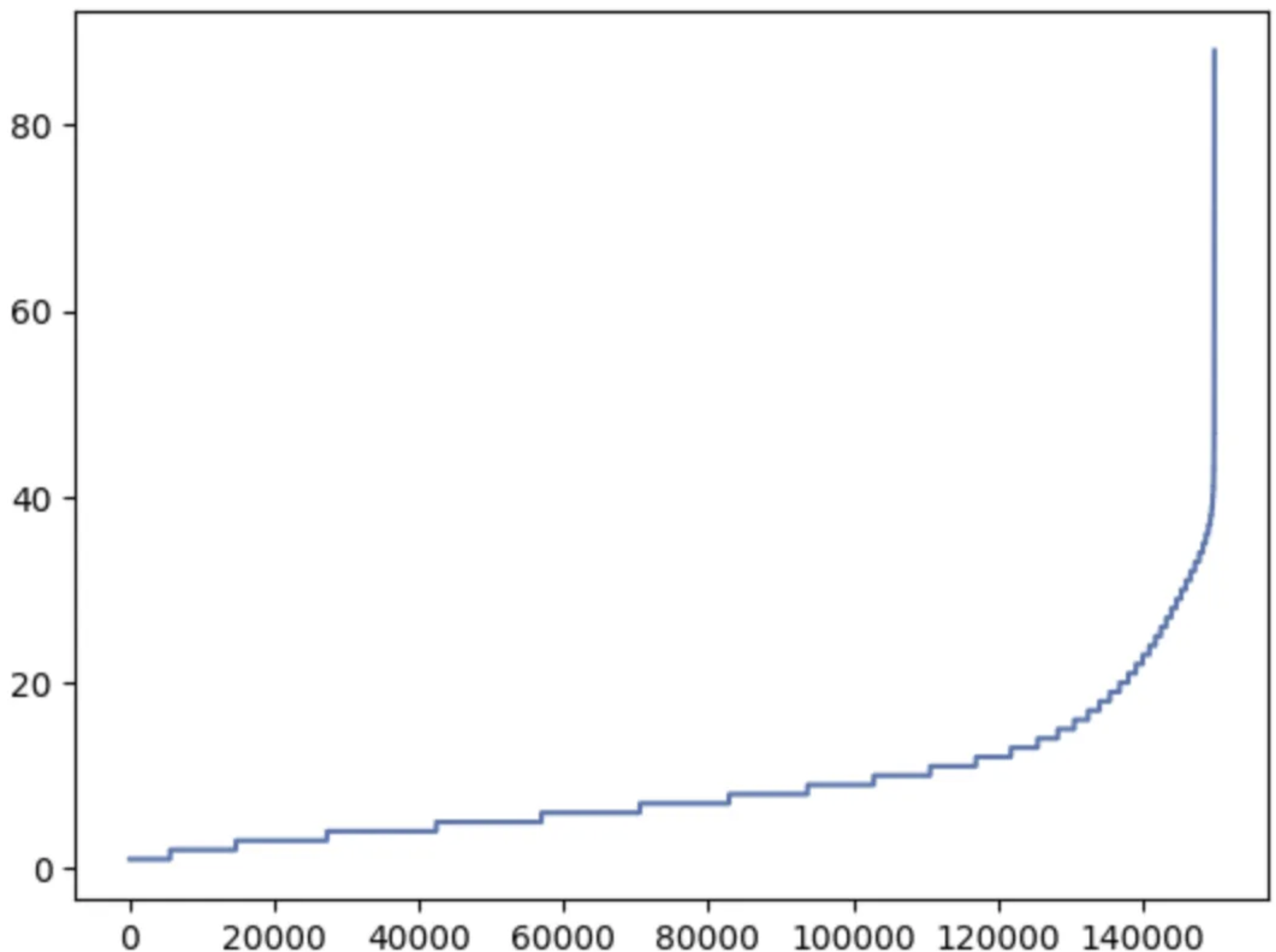
Matplotlib
Matplotlib은 파이썬에서 가장 널리 사용되는 데이터 시각화(Data Visualization) 라이브러리이다. 데이터 분석이나 머신러닝 프로젝트에서 얻은 결과를 그래프로 표현할 때 주로 사용된다.
느낀점(WIL)
이번 활동에서 가장 흥미로웠던 부분은 데이터 전처리 과정이었다.
처음에는 단순히 모델 학습 전에 데이터를 정리하는 절차 정도로 생각했지만,
직접 수행해보니 이 단계가 모델의 성능을 좌우하는 핵심이라는 것을 알게 되었다.
특히 텍스트 데이터를 벡터화하고 패딩을 적용하면서, 모델이 데이터를 이해하기 위해서는 사람이 보기 좋은 형태가 아니라 모델이 이해할 수 있는 수치적 구조로 표현되어야 한다는 점이 인상 깊었다.
데이터를 ‘어떻게 다루느냐’가 곧 모델의 성능과 신뢰도를 결정짓는다는 사실을 깨달았다.
이번 활동을 통해 기본 신경망을 구축하기 전에 데이터를 체계적으로 정리하고 전처리하는 과정의 중요성을 이해할 수 있었다.
