1. 연구주제
제목의 의미를 통해 연구 주제를 살펴볼 수 있을 것 같습니다. 제목을 해석해보면, LLM의 emergent abilities는 신기루인가? 인데요. 즉, 이 논문에서는 작은 모델엔 없고 큰 모델에만 나타나는 능력이 모델의 본질적 변화 때문이 아니라 metric choice 때문일 수 있다라는 점을 주장합니다.
2. 이 연구를 진행하는 데 필요한 배경지식
emergent ability 라는 개념이 등장하는데요. “갑자기 능력이 생긴다”라는 의미를 갖고 있습니다.
- Sharpness: 갑자기 생김
- Unpredictability: 언제 생길지 미리 예측하기 어려움
이러한 2가지 특징을 가진다는 것이 emergent ability의 특징입니다.
3. 논문 내용 설명
첫번째로 논문에서 보인것이 task에 따라 emergent ability가 발생한다고 주장합니다.
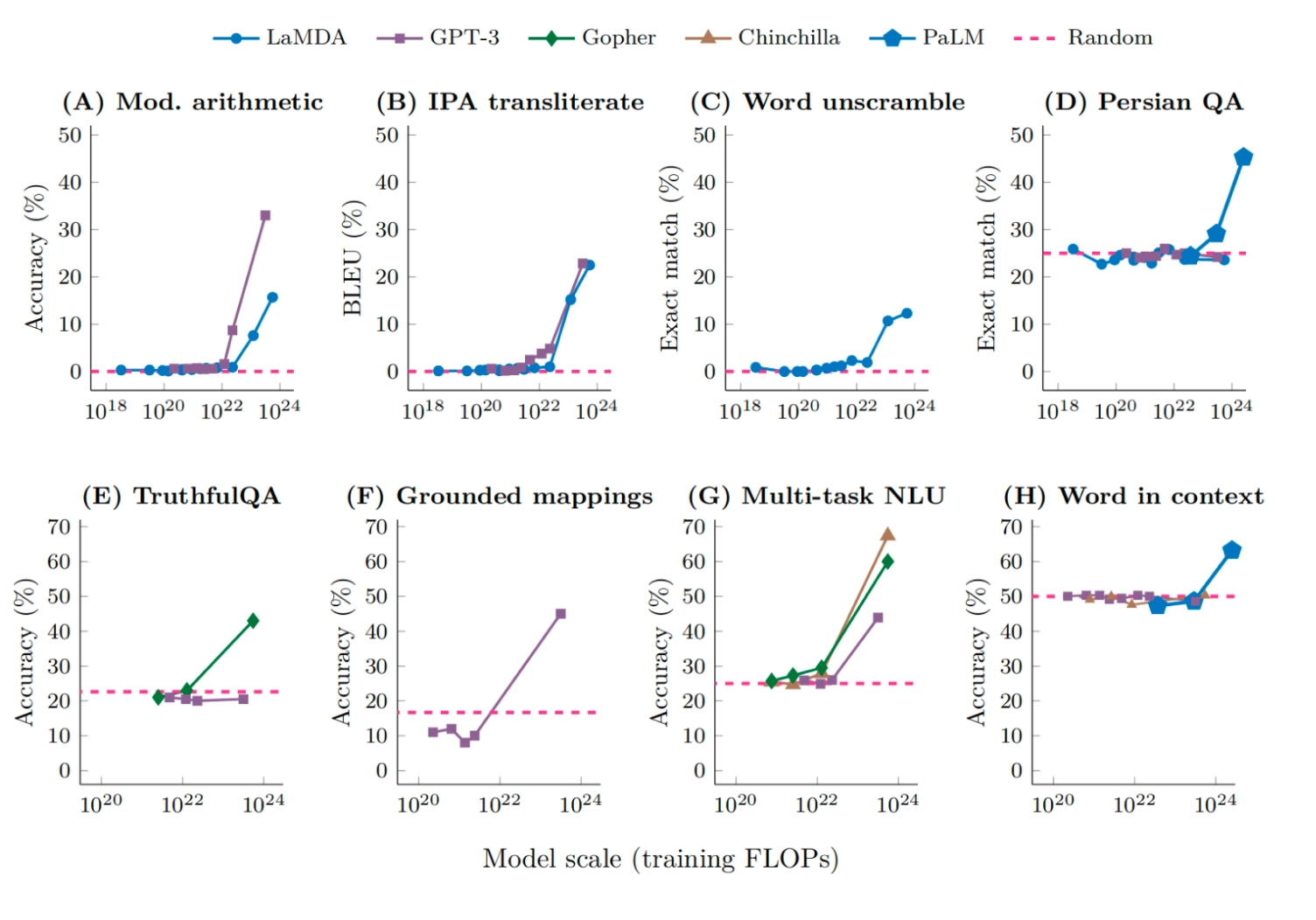
위 그래프는
- (A) Mod. arithmetic: 나머지 연산 문제
- (B) IPA transliterate: 단어를 국제음성기호(IPA)로 변환하는 문제
- (C) Word unscramble: 섞인 철자를 원래 단어로 복원하는 문제
- (D) Persian QA: 페르시아어 질문응답 문제
- (E) TruthfulQA: 사실에 맞는 답을 하는지 평가하는 문제
- (F)Grounded mappings: 주어진 규칙에 따라 올바르게 대응시키는 문제
- (G) Multi-task NLU: 여러 자연어 이해 과제를 종합적으로 평가하는 문제
- (H) Word in context: 문맥 속 단어의 의미를 파악하는 문제
다양한 task를 사용한 모델마다의 accuracy를 측정한 값인데요. 모델 크기가 커질수록 성능이 갑자기 뛰는 것처럼 보인는 현상을 볼 수 있습니다.
논문에서 emergent ability가 발생하는 metrics 2가지를 제시합니다.
- Multiple Choice Grade - 정답 선택지에 가장 높은 확률을 줬으면 1, 아니면 0
- Exact String Match - 출력 문자열이 정답과 완전히 같으면 1, 아니면 0
즉, 조금이라도 틀리면 0, 완전히 맞아야 1을 주는 all or nothing metrics 인데요.
다음으로는 논문에서 metric choice에 따라 emergent ability 발생할 수도 있고, 발생하지 않을 수도 있다는 것을 보입니다.
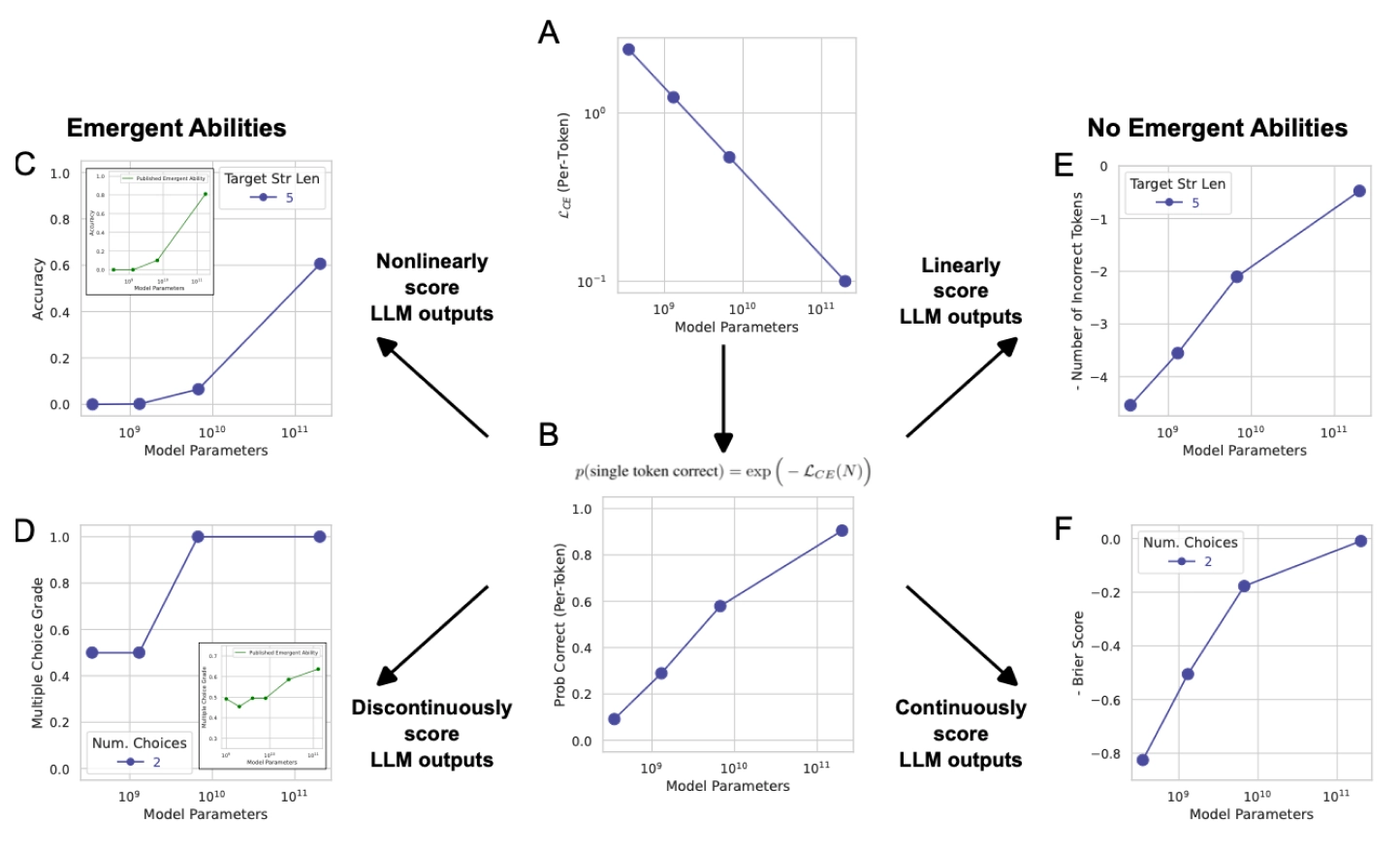
A - 모델 파라미터가 커질수록 Per-token cross-entropy loss가 어떻게 되는지에 대한 그래프
토큰 하나를 예측할 때의 평균적인 손실은 모델 파라미터가 커질수록 손실이 3 정도에서 3→ 1→ 0.5→ 0.1 꾸준히 감소하는 것을 볼 수 있습니다. 즉, 실제 모델 내부의 기본 성능 신호는 원래부터 매끈하게 좋아지고 있었을 수 있다라는 것을 보여줍니다.
B - A 그래프를 더 직관적으로 바꾼 그래프로,손실이 아닌, 토큰 하나를 맞힐 확률 계산
작은 모델은 10% 정도 확률로 맞히고 조금 더 크면 30% → 60%→ 90% 로 점전직으로 좋아지는 것을 볼 수 있습니다. 즉 아무런 emergence가 없다는 것을 볼 수 있습니다.
C - Target Str Len = 5 , y축은 Accuracy 동작 즉, 5개를 전부 다 맞히면 1, 하나라도 틀리면 0이라는 값의 metrics

수학적으로 이 확률을 계산해보면, 토큰 하나 맞힐 확률은 0.3 → 0.6 → 0.9로 부드럽게 증가하지만 전체 accuracy는 거의 0이거나 갑자기 많이 올라가는 emrgence가 발생한 것을 볼 수 있습니다.
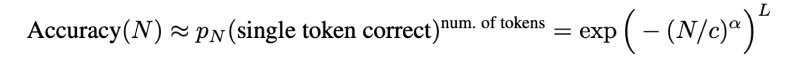
실제로 metrics가 계산되는 공식을 보시면, L제곱을 통해 배우 비선형적인 형태로 증가하는 것을 볼 수 있습니다.
D- Multiple Choice Grade
이 mertrics가 어떻게 평가되는지 살펴보면,
A: 0.30
B: 0.28 ← 정답
C: 0.22
D: 0.20
정답 B가 2등이면, metric에서는 그냥 0점
A: 0.29
B: 0.30 ← 정답
C: 0.21
D: 0.20
정답 B가 1등, 점수는 갑자기 1점으로 평가가 되는데, 이 metrics의 문제가 무엇이냐하면, 0.02밖에 증가하지 않았는데, 점수는 1점 차이가 나버리게 된다는 것입니다. 따라서 step 함수처럼 보이게 되는 것인데요.
E - Token Edit Distance : 몇 개 토큰이 틀렸는지
이 metrics는
- 5개 다 틀리면 오차 큼
- 3개 틀리면 중간
- 1개 틀리면 작음
- 0개 틀리면 완벽
하게 평가되는 지표입니다. 같은 모델 출력도 “전부 맞았냐 아니냐”로 보지 말고 “얼
마나 덜 틀렸냐”로 보면 emergence 가 사라지는 것을 볼 수 있습니다.
F- Brier Score : continuous metric
“정답에 얼마나 높은 확률을 줬는가”를 연속적으로 평가하는 점수인데요.
정답에
- 0.51 줬는지
- 0.70 줬는지
- 0.95 줬는지
정답에 대해 모델이 얼마나 confidence하고 있는지까지 반영하기 때문에 emergence가 사라지고 있는 것을 볼 수 있습니다.
GPT-3에게 task를 시켜보고 다른 metrics로 평가해보자!
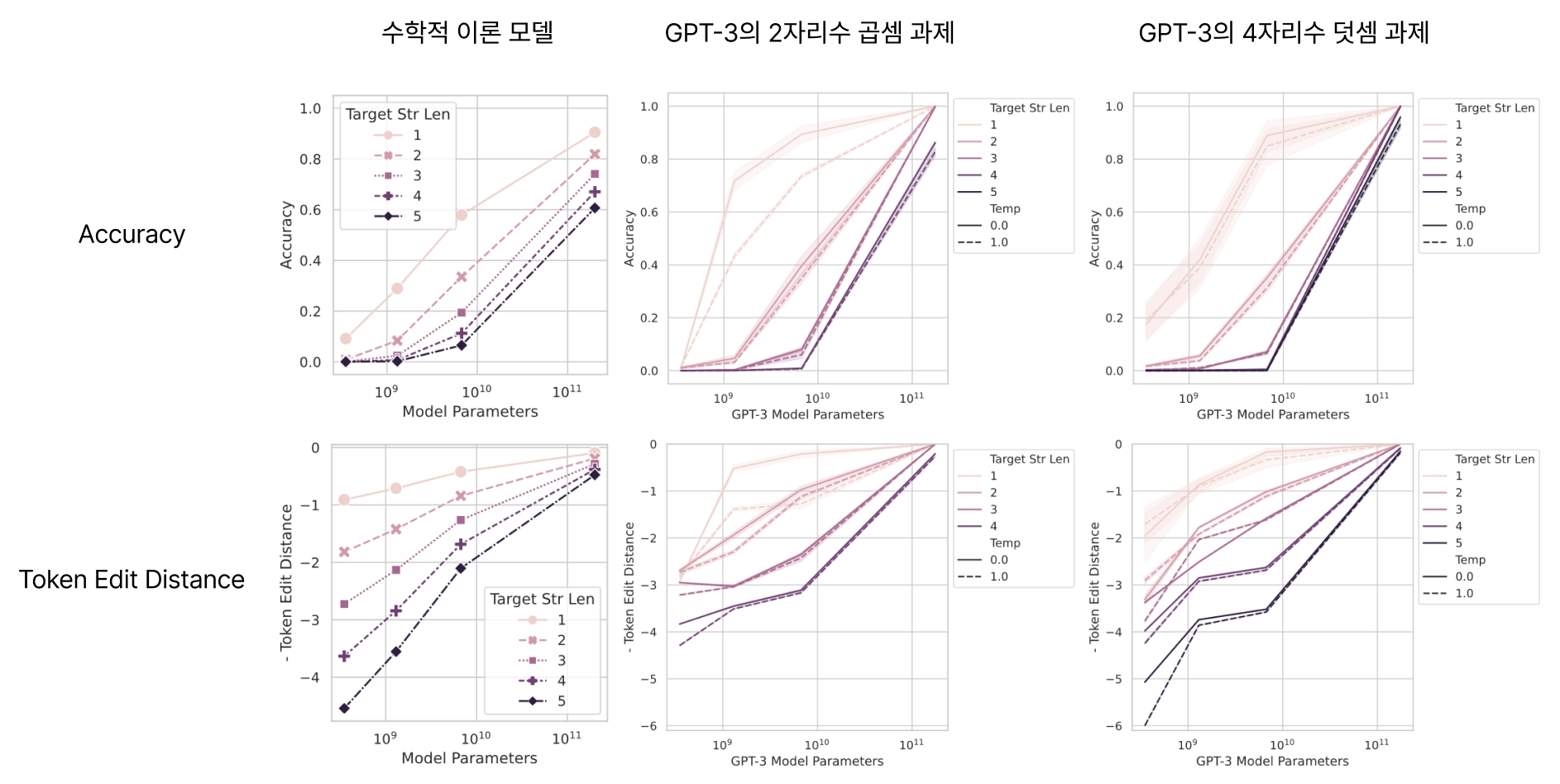
첫번째 행은 accuracy라는 지표로 평가한 것, 두번째 행은 token edit distance 지표로 평가한 결과인데요. 첫번째 열은 수학적 이론 task이며, 두번째 열은 GPT-3의 2자리수 곱셈 과제 task, 세번째 열은 GPT-3의 4자리수 덧셈 task입니다.
accuracy라는 metrics로 평가한 정답 문자열 길이(Target Str Len)가 길수록, 작은 모델에서는 성능이 거의 0처럼 보이다가, 큰 모델에서 갑자기 확 올라가는 것처럼 보입니다. 즉, → emergent ability가 발생했다고 볼 수 있습니다.
Token Edit Distance 그래프에서는 같은 모델 출력이 점진적으로 향상되는 모습이 나타나며, 실제 성능은 갑작스럽게 생긴 것이 아니라 조금씩 개선되는 현상을 볼 수 있습니다.
즉, 우리가 이 실험에서 볼 수 있는 것은 Accuracy로 보면 갑자기 잘하게 된 것처럼 보이지만, Token Edit Distance로 보면 사실은 원래부터 점점 덜 틀리고 있었던 것이였다 라는 점입니다.
BIG-Bench 메타분석
본 논문에선 2가지 가정을 합니다.
- Emergence는 특정 task-model pair에 붙는 현상이라기보다, 특정 metric에서 주로 나타나야 한다.특히 비선형적(non-linear) 이거나 불연속적(discontinuous) 인 metric에서 많이 보여야 한다.
- 어떤 task-metric-model family(어떤 과제를 어떤 모델 계열이 수행하는 경우) 조합에서 emergence가 보였다면, 그 metric을 더 선형적이거나 연속적인 metric으로 바꾸면 emergence가 사라져야 한다.
→ 이걸 검증하기 위해 BIG-Bench 사용합니다.

이 수치가 계산되는 식을 보면,
- 큼 → 급격한 성능 점프
- 작음 → 점진적 성능 향상
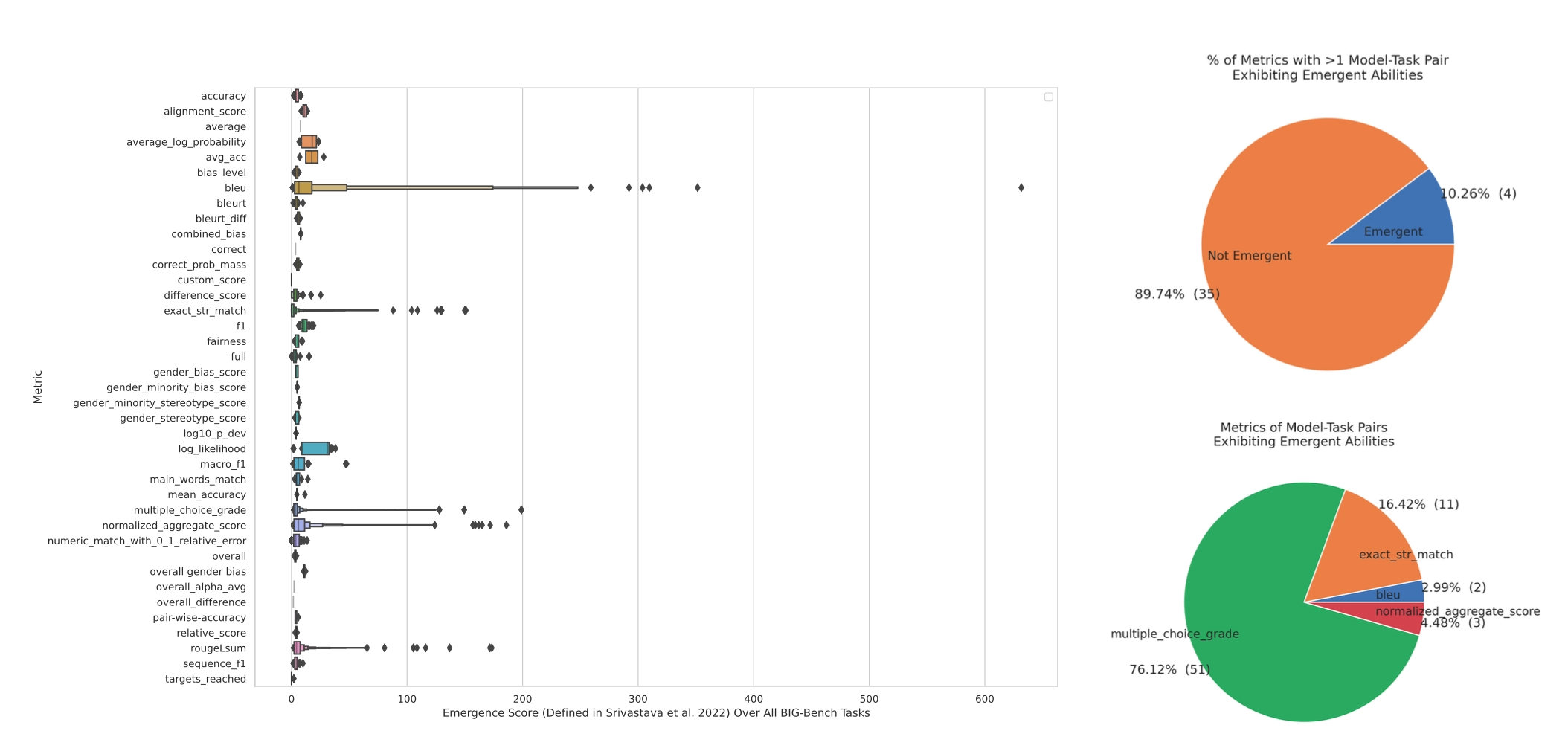
BIG-Bench 전체를 메타분석했을 때, emergence가 어떤 metric에서 주로 나타나는지 보여주는 그림입니다. 몇 metric만 오른쪽으로 길게 뻗어 있는 것을 볼 수 있습니다.
옆에 원형 그래프는 not emergent metric, emergent metric의 비율을 보여주는데요.
- Not Emergent: 89.74% (35개)
- Emergent: 10.26% (4개)
즉, emergence는 아무 metric에서나 생기는 게 아니다라는 것을 확인할 수 있습니다.
emergent ability를 인위적으로 만들어보자!
지금까지는 metric choice에 따라 emergent ability 발생한다라는것을 연구 결과를 통해 입증했습니다.
그렇다면 반대로 emergent ability를 metric choice으로 만들어봅니다.
논문에서는 vision task를 사용해서 여러 신경망 구조에서 emergence-like 현상을 유도합니다. (왜 vision model을 선택했는지 궁금하여 찾아보니, vision model에서는 보통 LLM처럼 “갑자기 능력이 생겼다”는 식의 얘기가 잘 안 나왔기 때문이라고 합니다. )
본 논문에서는 CIFAR100 오토인코더 모델에 reconstruction metric을 인위적으로 만들어 emergence ability를 발생시킵니다.
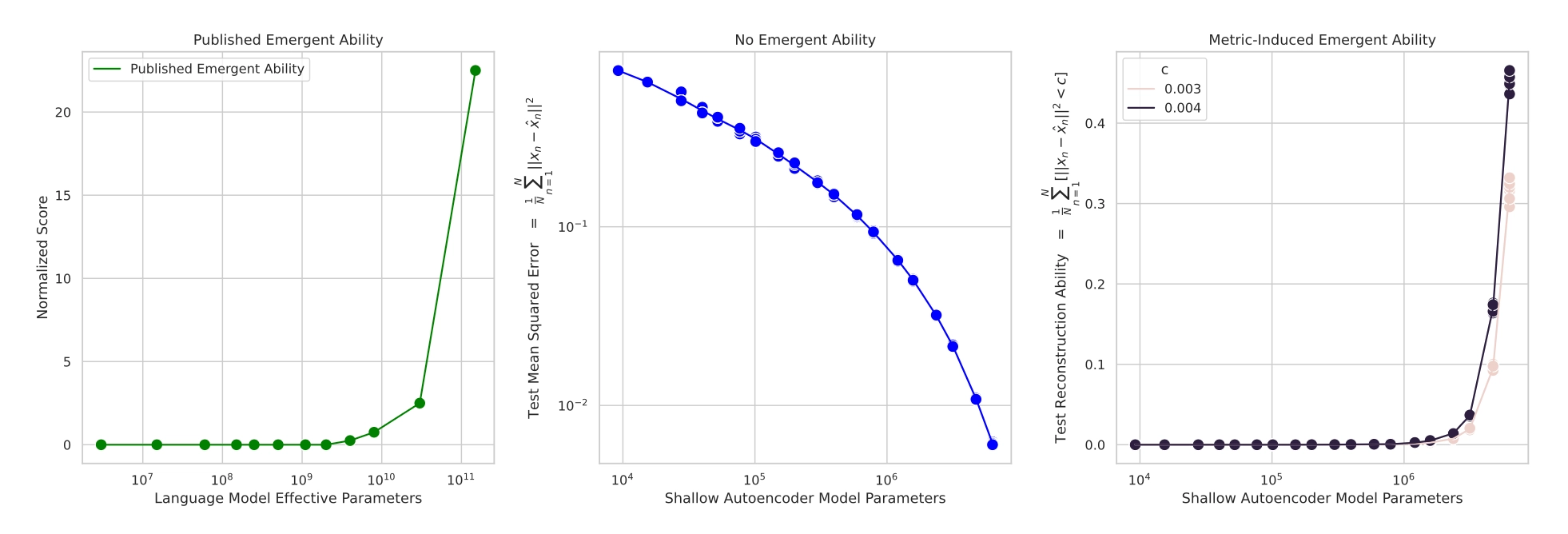
젤 왼쪽에 있는 그래프가 LLM에서 나타나는 emergent ability 예시 그래프입니다. 중간에 있는 그래프는 실제 오토인코더를 일반적인 지표인 MSE로 평가한것인데, 그래프를 통해 우리는 emergence 발생하지 않았다는 것을 볼 수 있습니다. 젤 오른쪽에 있는 그래프는 본 논문에서 인위적으로 emergent ability가 발생했다는 것을 보이기 위해 만든 metric입니다.
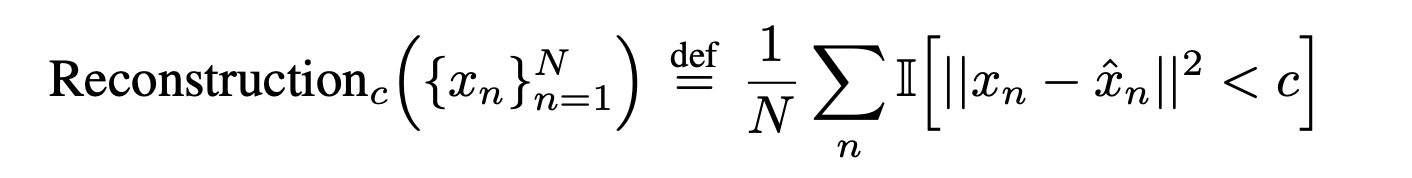
위와 같은 계산 방식을 사용하며, 그래프 결과를 해석해보면, emergent ability가 명확하게 나타나는 것을 볼 수 있습니다.
최종 논문에서 말하고 싶은 것
최종적으로 정리를 해보자면, 우리가 현재 LLM을 평가하고 있는 metric이 all or nothing 성격이 강하기 때문에, LLM의 발전이 신기루라고 느끼는 것이다. 라는 것을 논문은 말하고 싶은 것 같습니다.
그렇다면 이러한 의문이 들 수 있을 것 같습니다.
우리가 자주 사용하는 accuracy라는 metrics가 문제인거냐?
우리는 여태까지 metrics choice를 잘못 해왔는가?
인데요.
논문에서 말하는 accuracy metrics는 sequence task에서
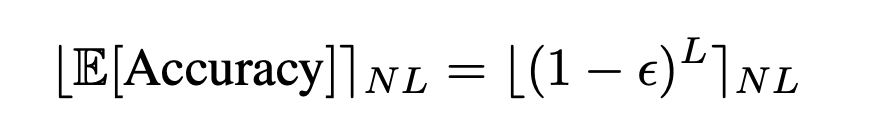
위와 같이 계산이 됩니다. 즉, all-or-nothing 성격이 강해서 특히 문자열 전체를 다 맞혀야 하는 llm에서는 emergent ability처럼 보이는 현상이 나타나기 쉽습니다.
즉, 논문에서 최종적으로 말하고 싶은 바는 accuracy 같은 emergence ability가 나타나는 metrics를 쓰지 마라! 가 아니라, accuracy를 썼다면, 그 metric이 가진 all-or-nothing 성격 문제를 통제한 뒤 해석해야 한다. 입니다.
느낀점
논문이 metric choice에 따라 emergent ability가 나타나거나 사라질 수 있음을 보인 점에 그치지 않고, 실제로 vision task에서도 metric choice만으로 emergent ability처럼 보이는 현상을 Reconstruction_c라는 metrics를 직접 만들어낸 점에서 논문 주장의 설득력이 더 커졌다고 느꼈습니다.
마지막으로 느낀점은 모델의 성능을 해석할 때는 결과 자체를 받아들이기보다, 어떤 metric으로 평가했는지까지 함께 봐야 한다는 점을 다시 생각하게 되었습니다.


좋댓구알