
실무에서 지이이이이이이이이이이인짜 중요하다고 한다.
페치 조인 (fetch join)이 뭐시여?
SELECT * FROM Member M JOIN Team T ON T.id = M.team;이거 아니야....?
라고 생각하실 수 있는데, 이건 그냥 SQL Join문이다.
우리가 지금부터 배울 조인은 JPA에서만 사용되는 문법인 페치 조인 이란 문법이다.
JPA에서 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능으로,
JPQL에서 성능 최적화를 위해 제공하는 기능이다.
join fetch 명령어를 사용하면 된다.
사용방법 & 예시
일단 테이블 두개가 있다고 가정하자.
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
@ManyToOne(fetch = FetchType.LAZY)
//@BatchSize(size = 100)
private Team team;
// 기본 생성자
public Member() {}
public Member(String username, Team team) {
this.id = id;
this.username = username;
this.team = team;
}
}
public class Team {
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "team", fetch = FetchType.EAGER)
private List<Member> members = new ArrayList<>();
// 기본 생성자
public Team() {}
public Team(String name) {
this.name = name;
}
}
이렇게 되어 있는 상태다.
// JPQL
SELECT m FROM Member m JOIN FETCH m.team
// SQL
SELECT M.*, T.*
FROM Member M
INNER JOIN TEAM T
ON M.TEAM_ID = T.ID;JPQL문을 보면, 회원을 조회하면서 연관된 팀도 함께 조회한다. (SQL 한 번에)
SQL을 보면 회원 뿐만 아니라 팀(T.*)도 함께 SELECT 하게 된다.
이렇게 가져오면 어떻게 되냐면...
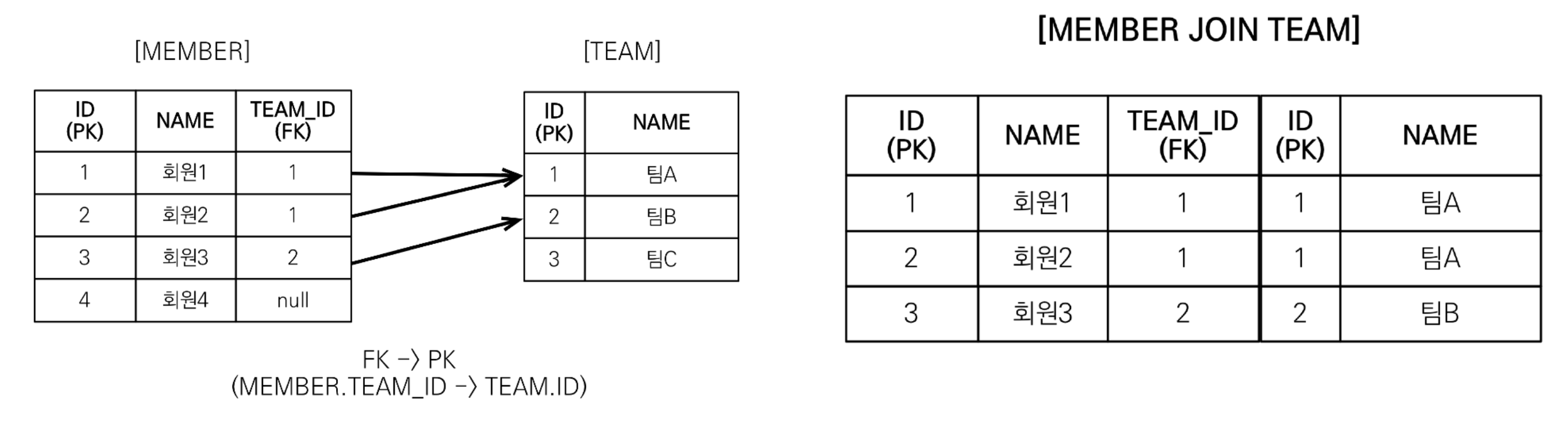
Memeber 테이블의 Team_ID를 각각 연결해서 한 테이블마냥 Java로 넘어온다.
컬렉션 페치 조인
// JPQL
SELECT t FROM Team t join fetch t.members
where t.name = ‘팀A'// SQL
SELECT T.*, M.*
FROM TEAM T
INNER JOIN MEMBER M
ON T.ID=M.TEAM_ID
WHERE T.NAME = '팀A';
이처럼 원하는 조건만 걸어서 가져올 수도 있다.
그럼 왜 페치조인을 사용해?
1. 일반 조인 실행시 연관된 엔티티를 함께 조회하지 않음
무슨 소리인지는 바로 예시를 보자..
// JPQL
SELECT t
FROM Team t
JOIN t.members m
WHERE t.name = ‘팀A'이런식으로 JPQL에서 일반적인 JOIN을 할 경우,
// SQL
SELECT T.*
FROM TEAM T
JOIN MEMBER M ON T.ID=M.TEAM_ID
WHERE T.NAME = '팀A'Team 테이블의 값만 가져오고, 연관되어 있는 Member 테이블의 데이터는 가져오지 않는다.
이러첨 JPQL은 결과를 반환할 때 연관관계 고려하지 않는다.
단지, SELECT 절에 지정한 엔티티만 조회할 뿐이다.
그래서 Team Entity만 조회하고, Member Entity는 조회하지 않았다.
2. N+1 문제 해결
아마 페치조인 개념을 볼려고 들어오신거면,
즉시로딩(EAGER) & 지연로딩(LAZY) 이 두가지의 개념을 아실거라 생각한다.
보통 실무에서는 거의 지연로딩(LAZY)을 사용한다고 한다.
하지만, 지연로딩을 사용하더라도 N+1의 문제를 완벽하게 해결할 수 없다.
FETCH 타입을 지연로딩(LAZY)으로 해놓은 다음,
페치조인을 사용하면 N+1 문제를 해결할 수 있다.
"....? 그럼 또 연관된 Entity는 값이 느리게 들어오는거 아니야? 지연로딩이자나 ㅡㅡ;;"
아니다. 페치조인에는 특징이 있다.
페치조인 특징
1. Entity에 직접 적용하는 글로벌 로딩 전략보다 우선순위
2. 둘 이상의 컬렉션은 fetch join X
3. 컬렉션을 fetch join하면 페이징 API(setFirstResult, setMaxResults)를 사용 X
1번의 특징에 의해, 지연로딩(LAZY)은 묵살(?)이 되어 버리고, 페치조인이 작동하게 된다.
그래서 기본적으로는 글로벌 특성으로 지연로딩(LAZY)을 사용하면서,
페치조인을 사용하면 원하는 데이터를 필요할때만 함께 가져올 수 있게 된다.
주의사항!
1. 둘 이상의 컬렉션은 fetch join X
1:N:M 관계인 3개의 엔티티가 존재한다고 가정하자.
이런 관계일 때, fetch join은 한 번만 사용할 수 있다는 것이다.
2. 컬렉션을 fetch join하면 페이징 API를 사용 X
fetch join은 결국 SQL로 변환되어 join 쿼리가 나가는 것이다.
OneToMany (1대다) 관계인 두 테이블을 join하면 1의 관계인 쪽의 데이터는 Many(다)쪽 데이터만큼 불어난 데이터를 보여준다.
TEAM의 데이터는 한개인데, MEMBER의 데이터가 2개가 연관되어 있다.
그래서 총 두개의 데이터가 반환됐다.
"난 그저 One 쪽의 데이터를 가져오는게 목적이었는데, 왜 늘어났어 ㅠㅠㅠㅠ"
이게 문제다. One쪽의 데이터를 불렀지만, 돌아오는 데이터 량은 Many 쪽의 량이 온 것이다.
어찌보면 당연한건데 이게 뭐가 문제가 될까?
페이징(Paging)이 문제가 된다.
불어난 데이터들 때문에, 원하는 개수만큼의 데이터를 얻는 것이 불가능해진다.
물론! 값이 나오긴 하는데, 하이버네이트는 경고 로그를 남긴다.
예시를 한번 보자!
| Id | 이름 | 소속 팀 |
|---|---|---|
| 1L | Member1 | TeamA |
| 2L | Member2 | TeamA |
| 3L | Member3 | TeamB |
| 4L | Member4 | TeamB |
| Id | 팀 이름 |
|---|---|
| 1L | TeamA |
| 2L | TeamB |
이런 JPQL을 입력했다고 가정하자.
String sql = "select t from Team t join FETCH t.members";
List<Team> findMember1 = em.createQuery(sql, Team.class)
.setFirstResult(0) // 시작 위치
.setMaxResults(2) // 가져올 최대 개수
.getResultList();그럼 콘솔에선 하이버네이트가 화낸다.
HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory| Id | 팀 이름 | 이름 |
|---|---|---|
| 1L | TeamA | Member1 |
| 1L | TeamA | Member2 |
| 2L | TeamB | Member3 |
| 2L | TeamB | Member4 |
이런식으로 가져온 다음, 2개를 가져올려고 하면,
| Id | 팀 이름 | 이름 |
|---|---|---|
| 1L | TeamA | Member1 |
| 2L | TeamB | Member3 |
얘네가 출력이 된다.
그럼 Member2의 데이터는 묵살이 된다.
기준이 One쪽(Team)의 엔티티로 잡혀 있기 때문에 이런 상황이 벌어지는 거다.
그래서 해결법은!!
Batch Size라는 것을 적용하면 된다.
그거 역시 N+1 문제는 여기서! 요쪽에 가서 보면 된다.
제발!! One To Many (1대다)만 적용되는 주의사항이다.
다른건 데이터량은 그대로라 페이징이 가능하다.
3. 페치 조인 대상에는 별칭을 줄 수 없다.
되긴 하는데, 그냥 사용하지마라ㅠㅠㅠㅠㅠ
JPA가 의도하는게 아니라고 한다.
4. 모든 것을 페치 조인으로 해결할 수 는 없음
페치조인을 너무 맹신하지 말자!
5. 하이버네이트6 부터는 DISTINCT 명령어를 사용 안해도 된다.
이때부턴 알아서 애플리케이션에서 중복 제거가 자동으로 적용된다고 한다.
그래서 따로 여기다가 적지 않았다.
