✔️ BeautifulSoup
import requests
from bs4 import BeautifulSoup
r = requests.get(r"https://comic.naver.com/webtoon/weekday")
r.status_code
html = BeautifulSoup(r.text, "html.parser")
html.select(r"a.title")[4].text
이미지 스크래핑
import io
r = requests.get(r"https://comic.naver.com/webtoon/weekday")
r.status_code
html = BeautifulSoup(r.text, "html.parser")
a = html.select(r"div.thumb>a>img")
thumb_image = []
for i in a:
url = i.attrs["src"]
img = Image.open(io.BytesIO(requests.get(url).content))
thumb_image.append(img)
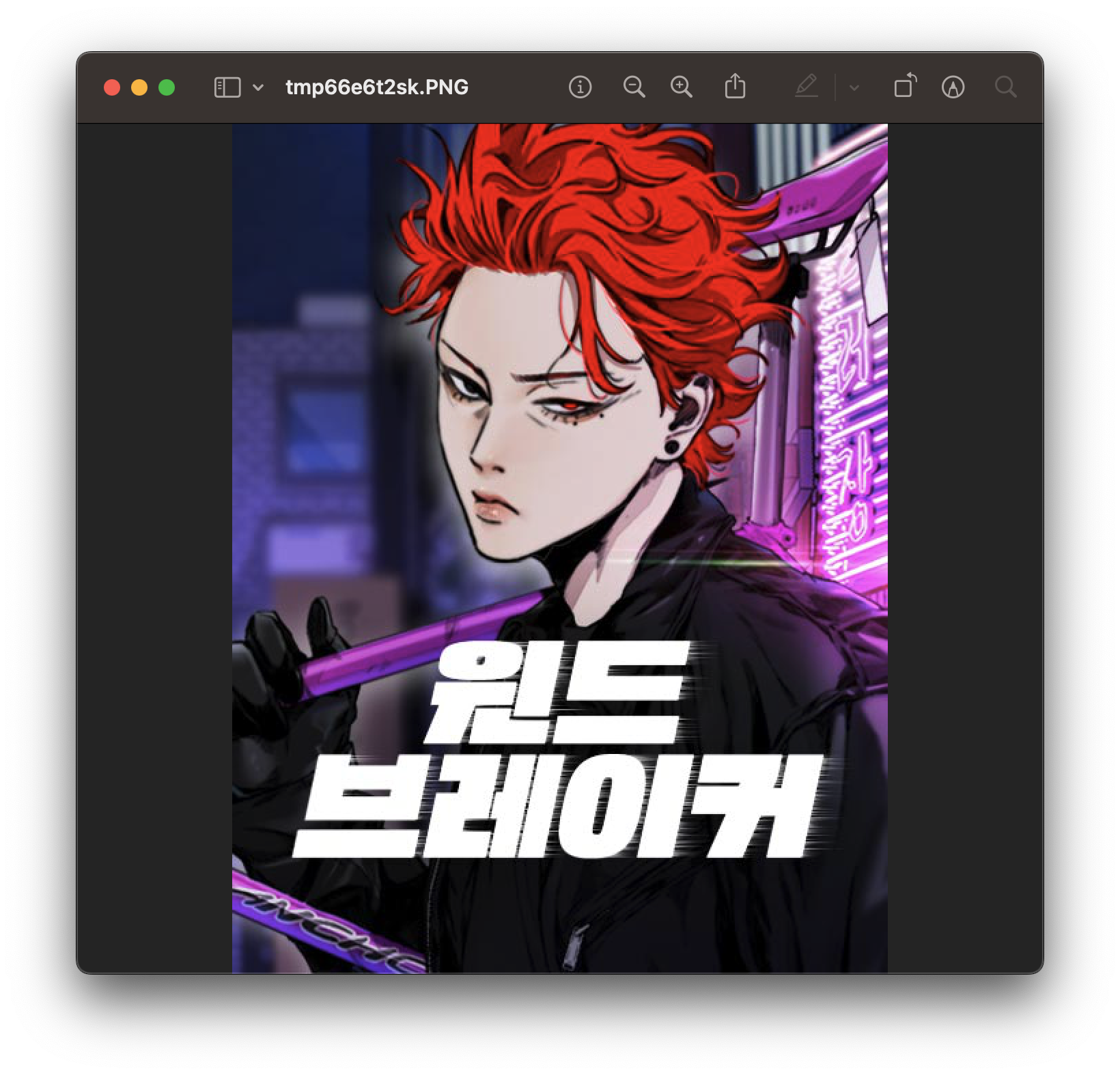
thumb_image[4].show()
막혀있는 웹 스크래핑
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
r = requests.get(r"https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=104", headers = headers)
r.status_code
html = BeautifulSoup(r.text, "html.parser")
headlines = html.select("a.cluster_text_headline")
headlines_text = [s.text for s in headlines]
cleaner = re.compile("\[.*\]|'")
clean_text = [cleaner.sub("", s).strip() for s in headlines_text]