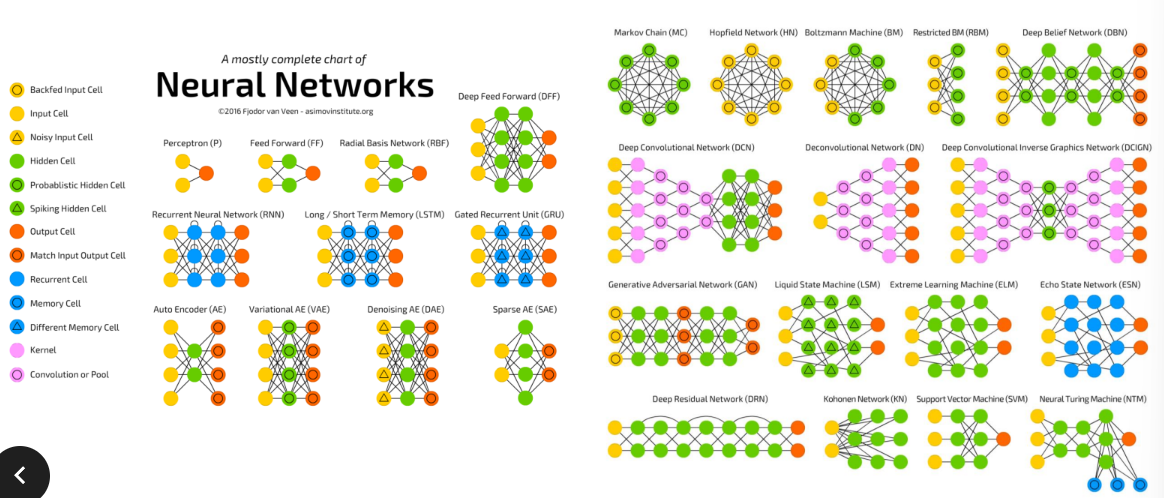
신경망은 어떻게 동작할까?
선형 대수 기초 – 행렬이란 무엇인가?
선형 대수학(linear algebra) : (데이터의) 공간을 분석하는 학문 (e.g. 3차원)
행렬(Matrix) → 숫자를 네모나게 모은 것. Vector(데이터)들의 묶음
Matrix를 쌓으면? 행렬을 묶은걸 또 쌓으면?
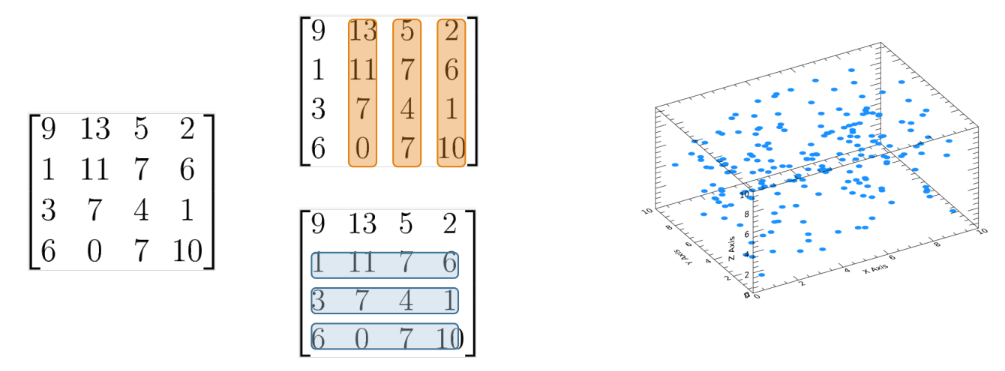
Matrix → Vector를 변환하는 역할
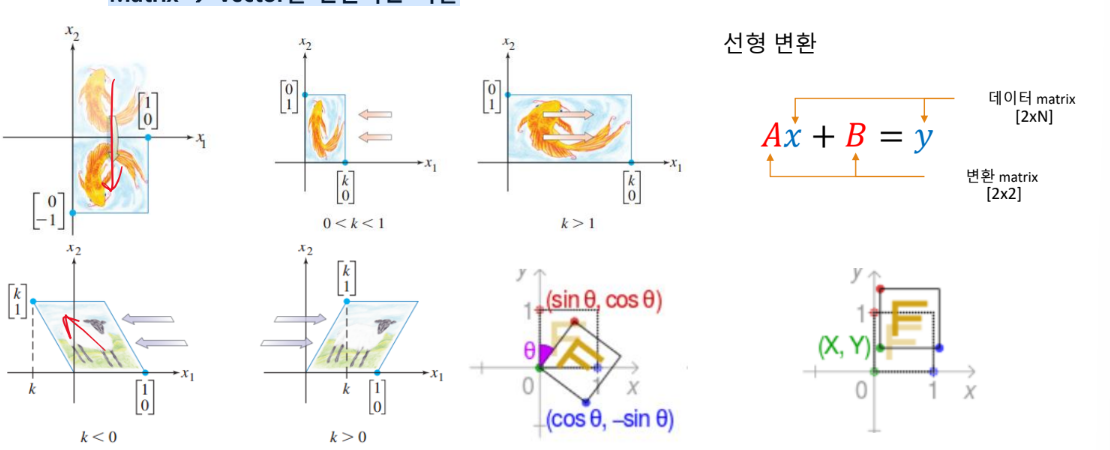
행렬 변환과 인공 신경망
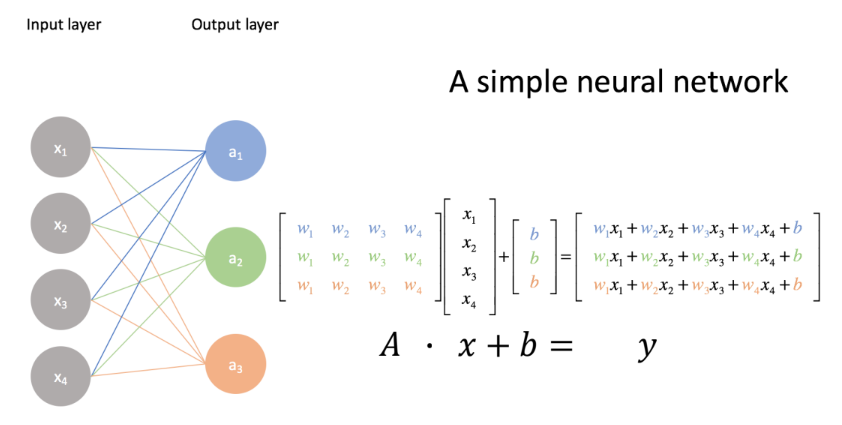
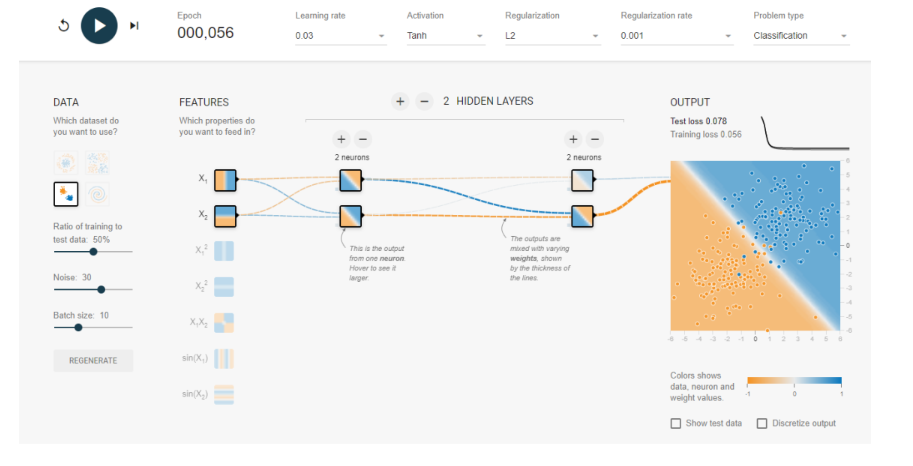
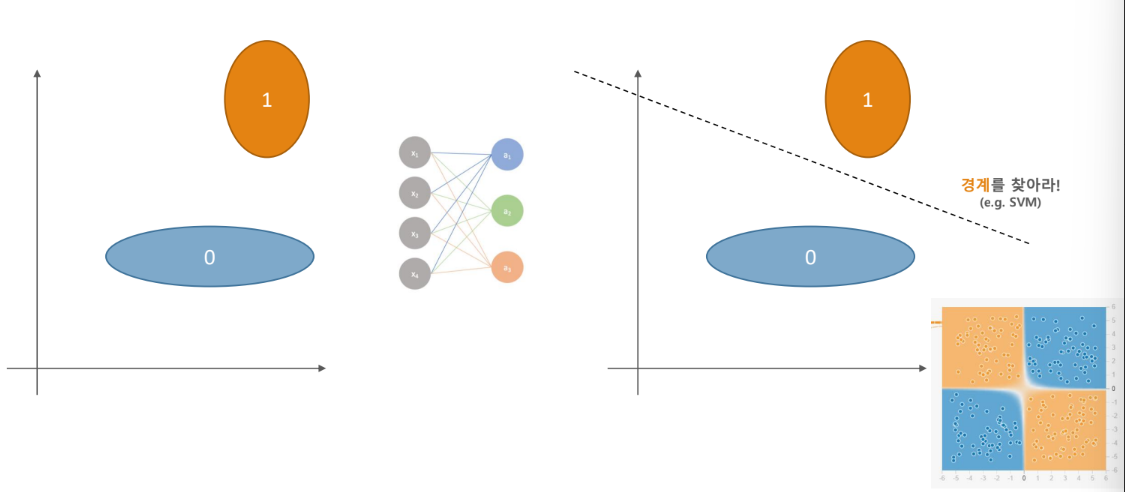
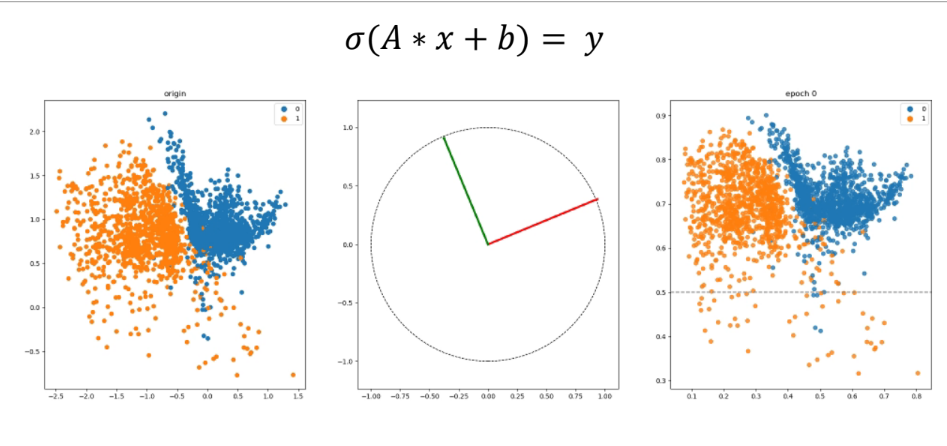
인공신경망 분류기는 어떻게 동작하는가?
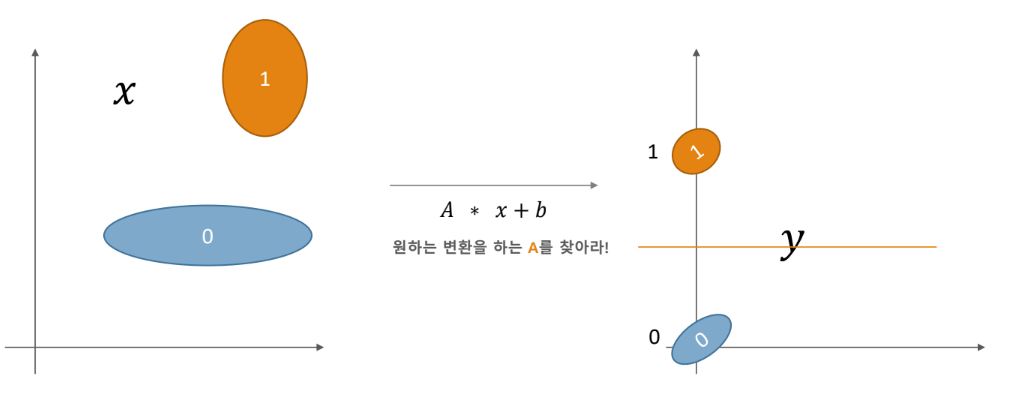
인공신경망과 좌표변환
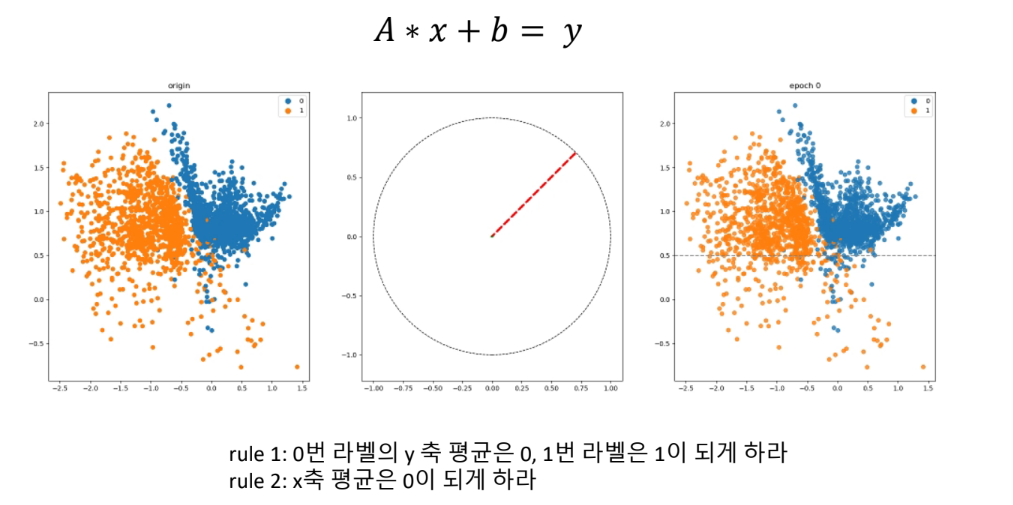
인공신경망과 좌표변환 + Sigmoid
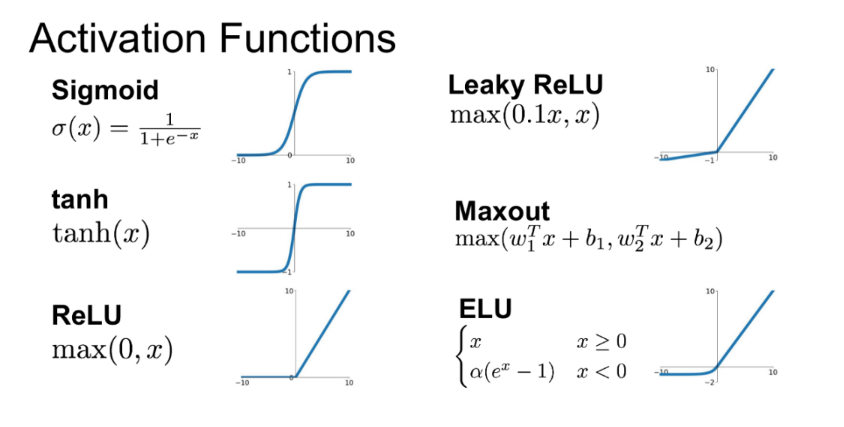
비선형 함수의 필요성
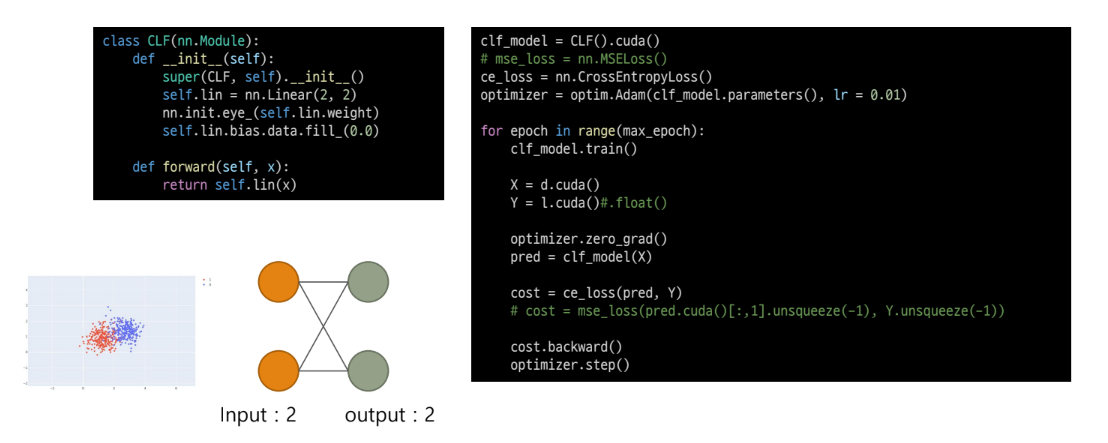
Simple ANN example
코드예시
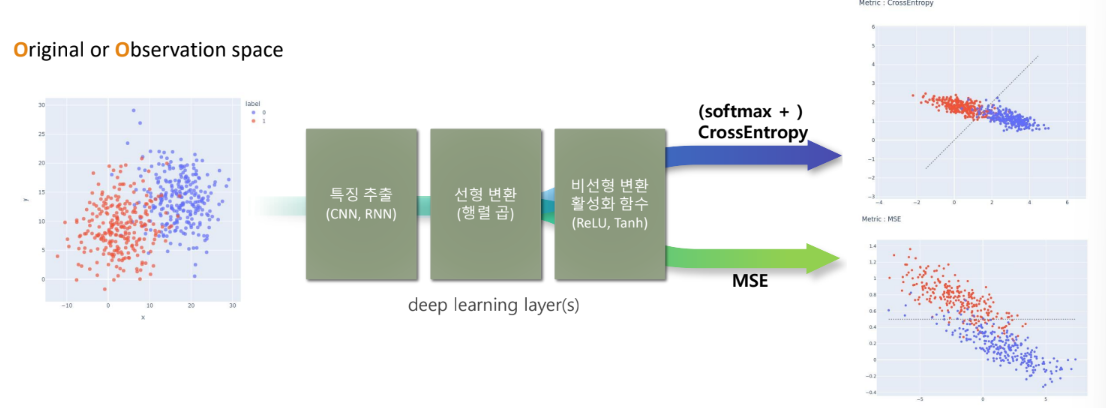
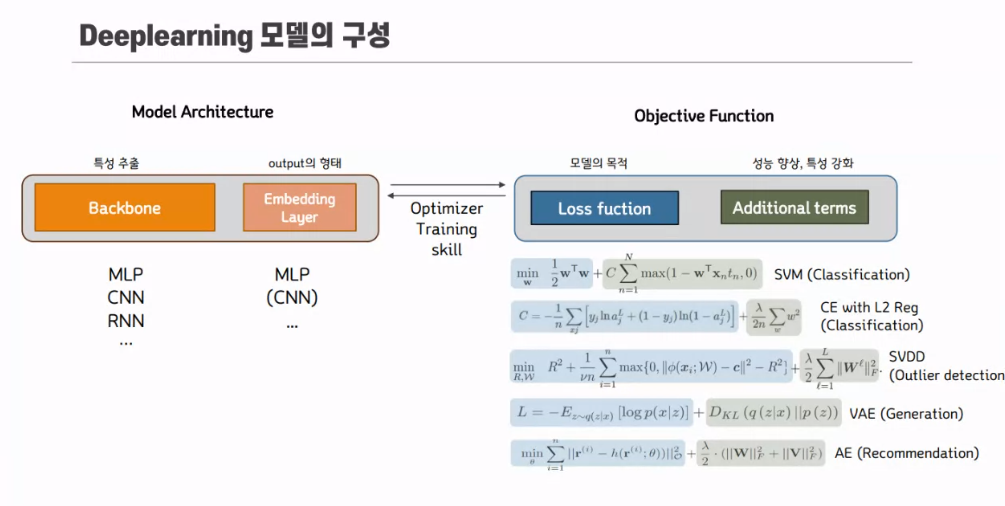
딥러닝이란?
원본 데이터(공간)를 선형 또는 비선형으로 변환하여
목적에 부합하는 잠재공간에 대응시킬 수 있는 parameter들을 찾는 과정
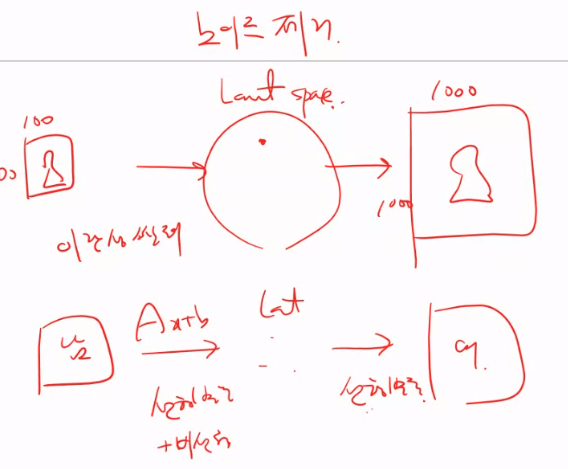
잠재공간 (Latent space) : Z
• 목적에 맞게 변형된 공간
• 데이터를 잘 표현할 수 있게 재구성된 공간
• 데이터의 잠재된 의미가 드러난 공간
딥러닝은 곧 차원 축소(변환)이다.
딥러닝 모델의 개념:
딥러닝(MLP)은 사실 비선형적인 boundary를 찾는 것이 아닌
데이터를 구기고 돌리고 늘려서 선형적인 boundary에 맞추는 것이다.
잠재공간(Latent Space) 이란?
•데이터를 잘 표현할 수 있는 구성된 공간을 latent space(z)라고 함 → Representation Learning (T-sne, U-MAP, autoencoder)
• Observation Space에서 latent Space로 치환하는 과정을 Embedding이라고도 함
•잠재 공간(latent space)은 실제 관찰 공간(observation space)보다 작을 수 있음
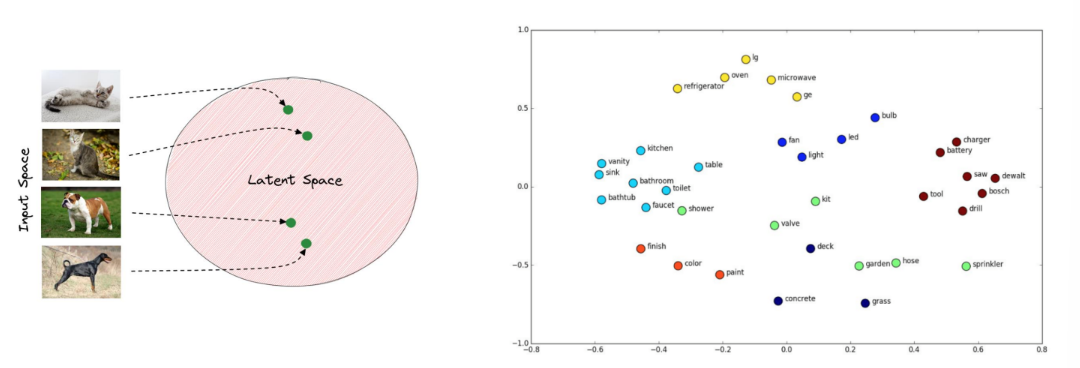
참고:https://www.baeldung.com/cs/dl-latent-space
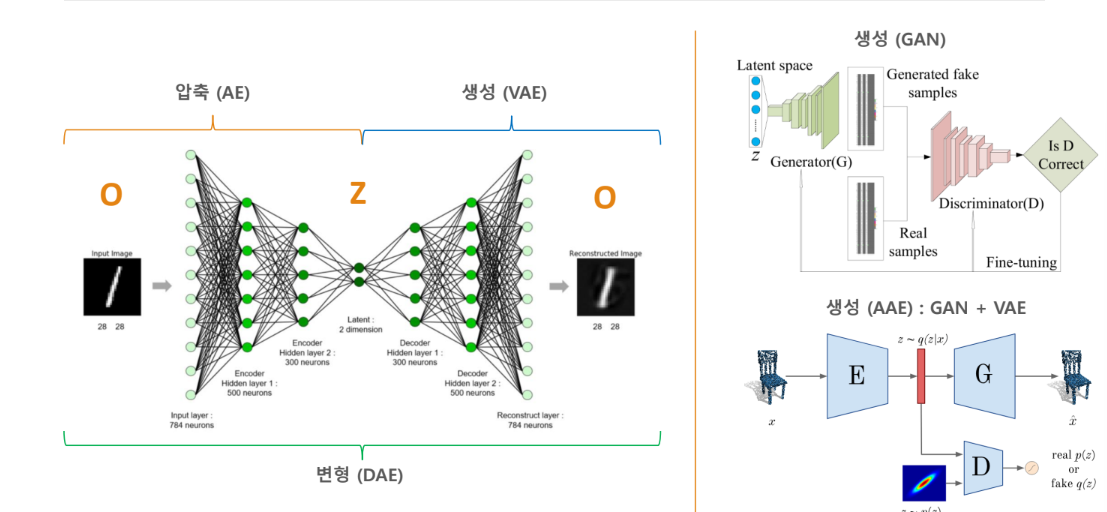
잠재공간을 응용한 딥러닝 모델 - AutoEncoder
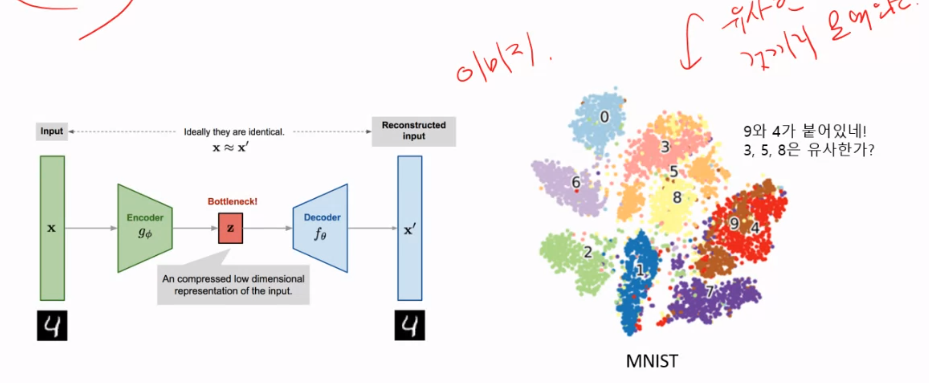
참고: https://argmax.ai/blog/vhp-vae/
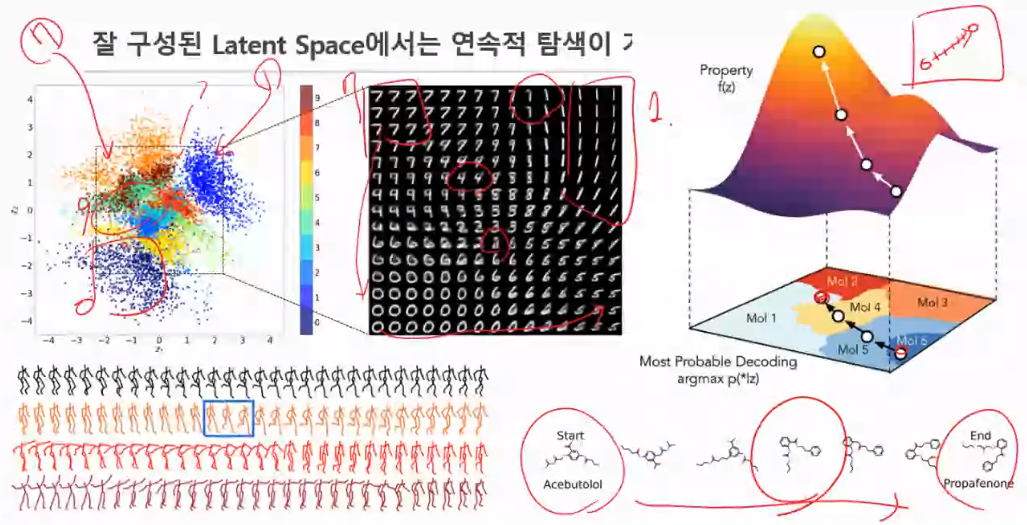
Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules
Applications using Latent Space
데이터 압축, 생성
이상치 탐색
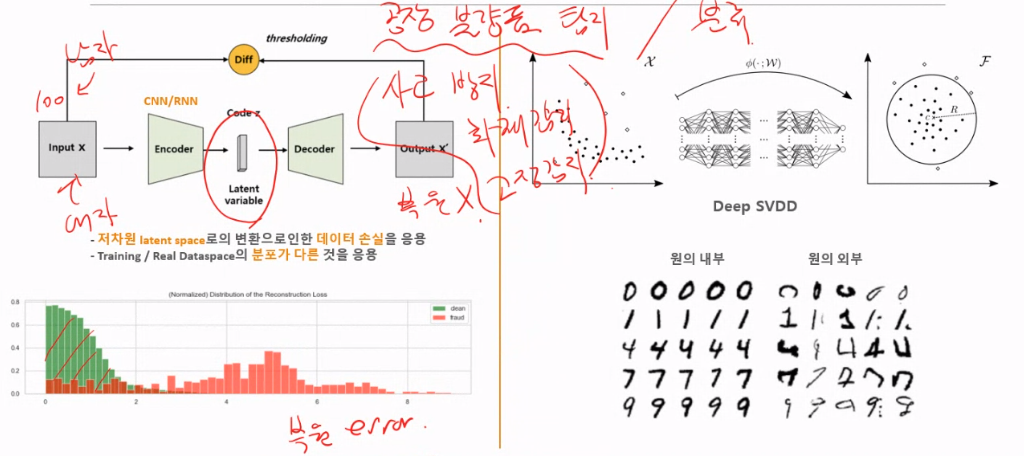
참고 : https://www.kaggle.com/code/robinteuwens/anomaly-detection-with-auto-encoders/notebook
(2018) Deep One-Class Classification, Lukas Ruff et al
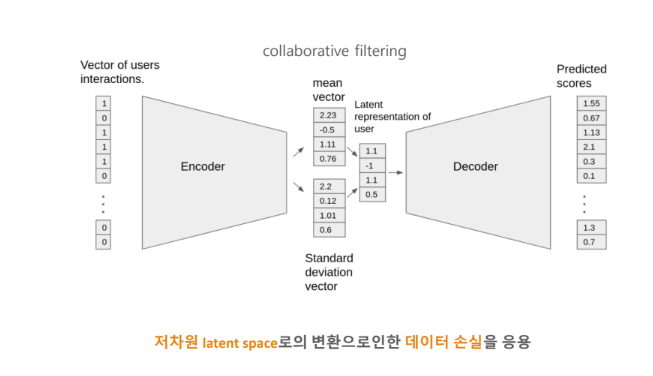
추천 시스템
Frame interpolation
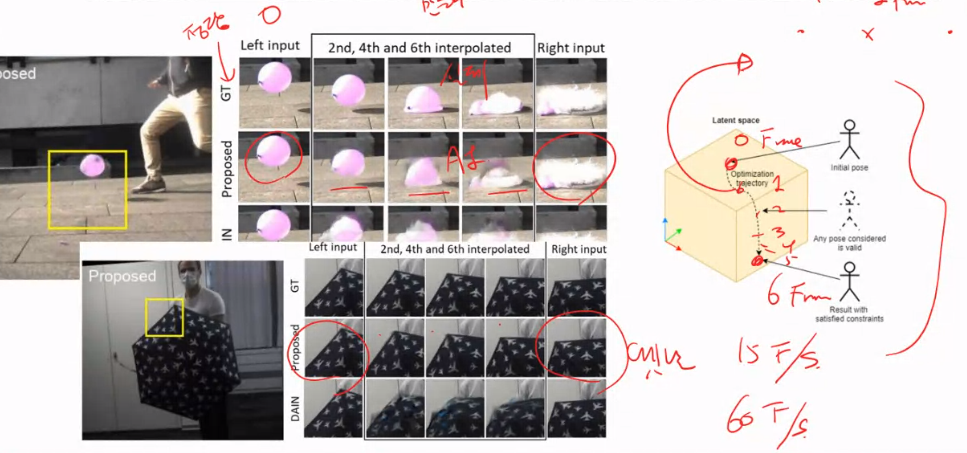
참고: Time Lens: Event-based Video Frame Interpolation
https://argmax.ai/blog/vhp-vae/
탐색 / Interpolation

Contrastive/Metric learning
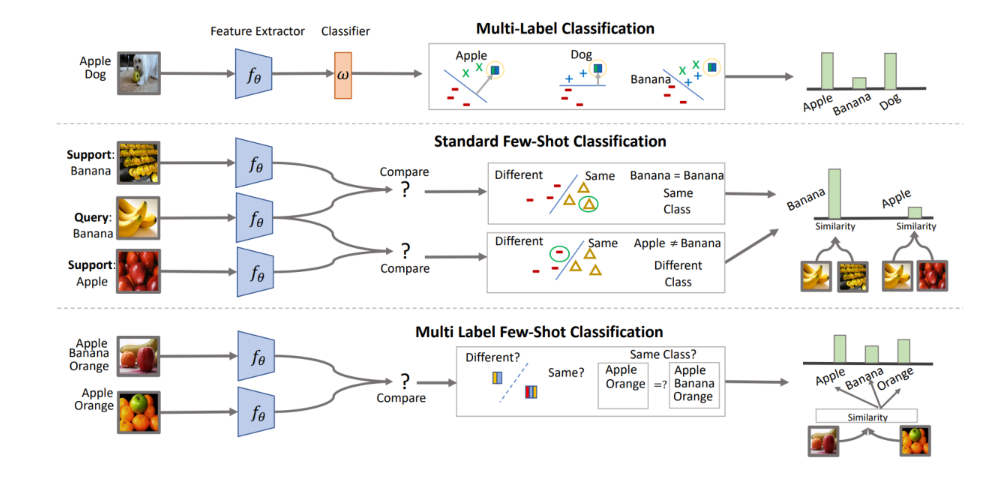
기존 Classification의 문제점들

• MNIST classification하기 위해서는 최종적으로 몇 차원이 필요한가? class 별 데이터 수는?
• CIFAR100 classification하기 위해서는 몇 차원이 필요한가? class 별 데이터 수는?
• 회사 직원 얼굴 인식을 하기 위해서는 몇 차원이 필요한가? class 별 데이터 수는
우리가 모델을 구축하고 데이터 수집부터 기획해야하는 입장이라면?
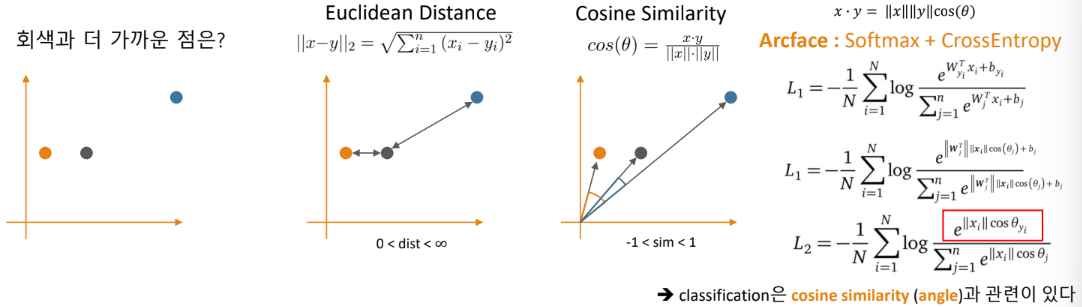
Metric과 유사도
척도(metric) :
◦ 학습을 통해 목표를 얼마나 잘 / 못 달성했는지를 나타내는 값 (MSE, CE, Accuracy, AUROC)
◦ 특정 기준 혹은 데이터와 데이터의 차이 또는 거리
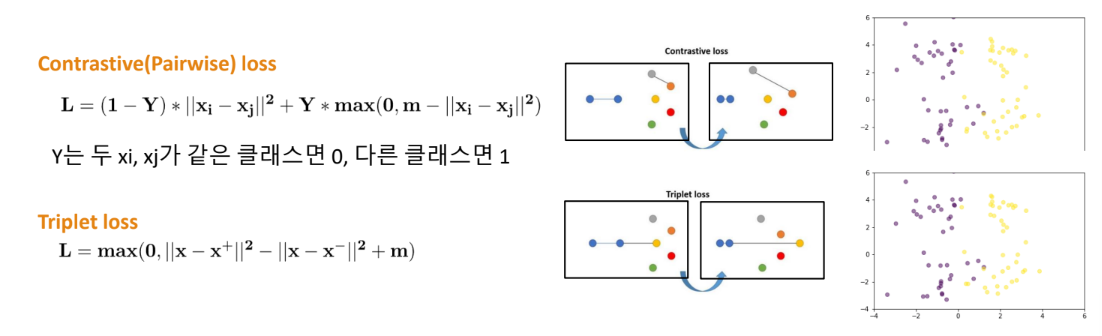
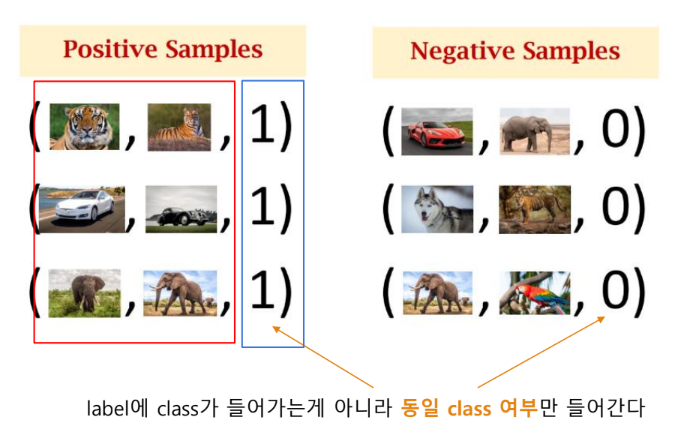
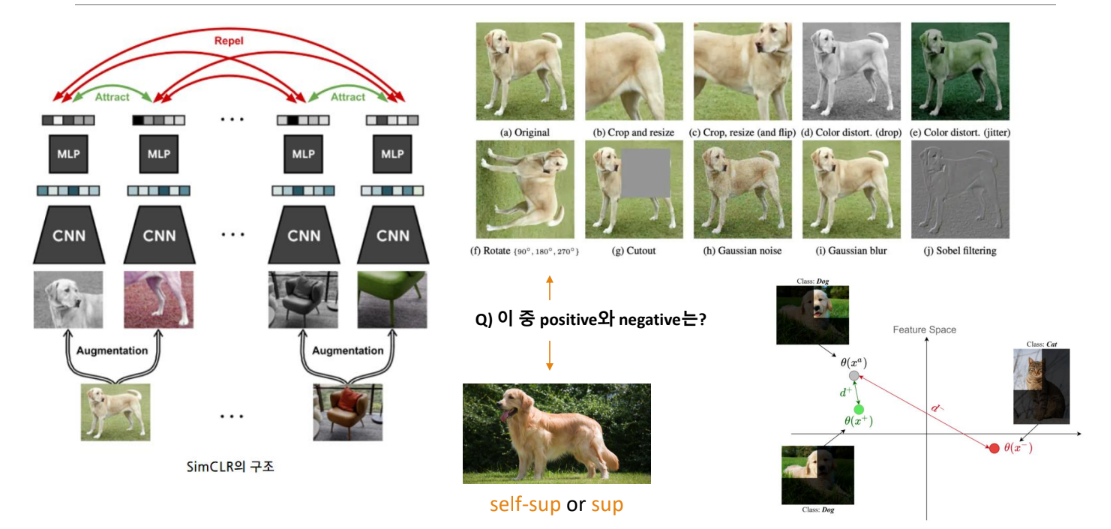
Contrastive (Representation) learning
학습 데이터들을 대조함으로써 latent space상에서 같은 범주(positive pair)의 데이터는 가깝게 당기고(pull)
서로 다른 범주는(negative pair)끼리는 서로 밀어내도록(push) 학습
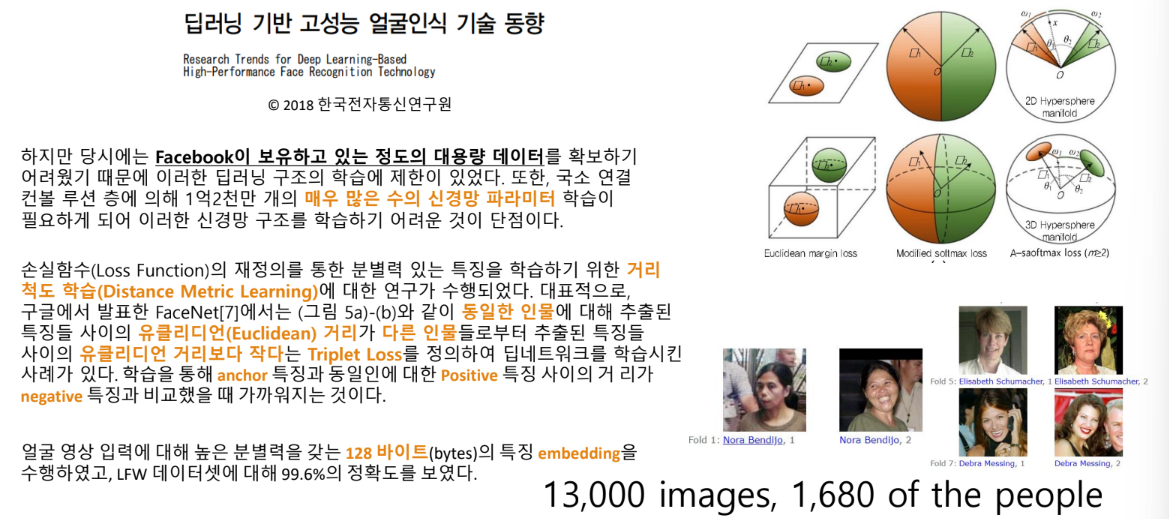
기술 동향 보고서
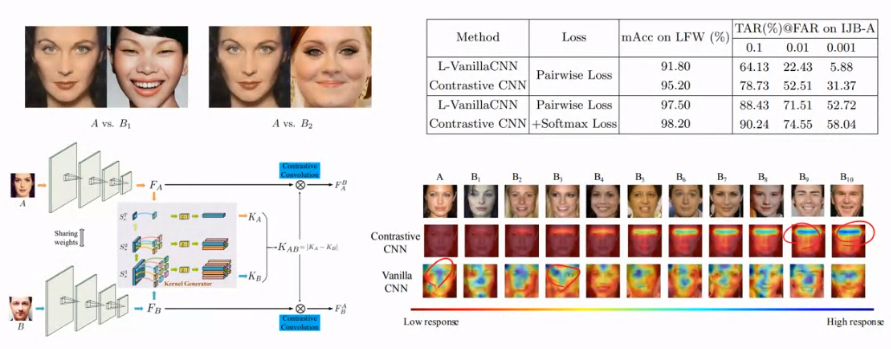
Simaese Network
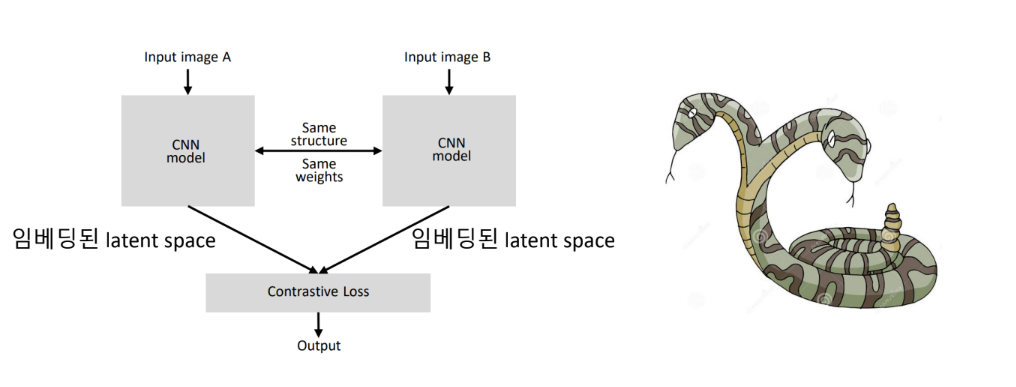
Few-shot learning 이란?
생김의 유사도만 보고 판단하는것
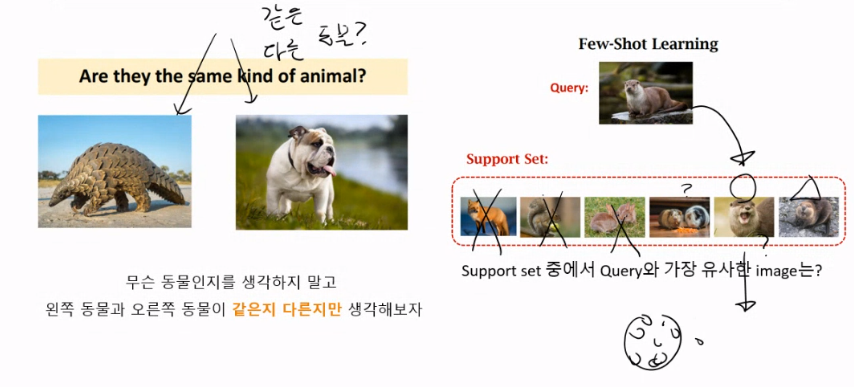
Fewshot-learning의 dataset 구성
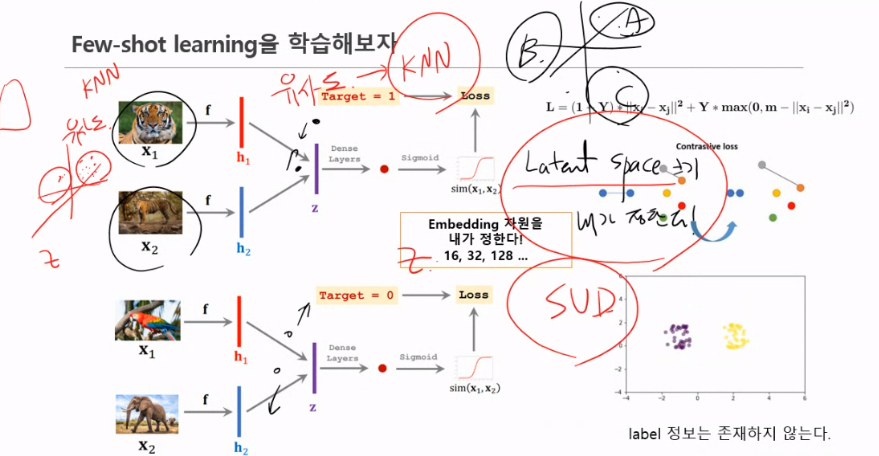
Few-shot learning을 학습해보자
Few-shot learning에서 새 이미지를 추론해보자
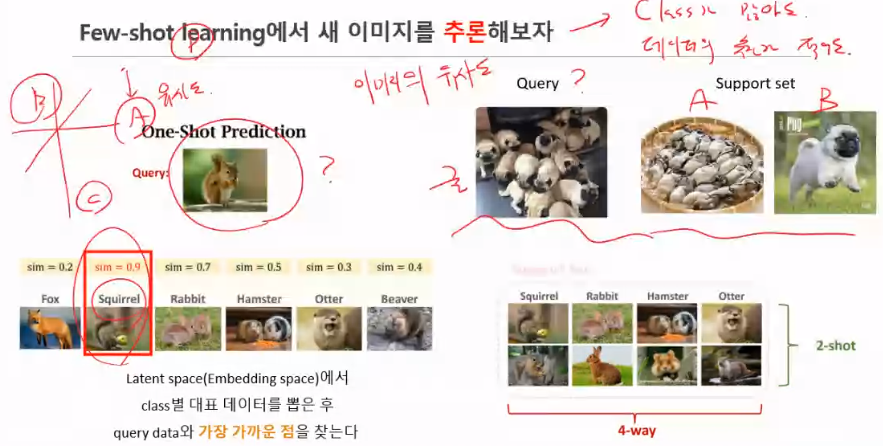
참고: https://zzaebok.github.io/machine_learning/FSL/
라이브러리 예시
Keras Code Examples
https://keras.io/examples/vision/siamese_contrastive/
Pytorch metric learning package
https://kevinmusgrave.github.io/pytorch-metric-learning/losses/
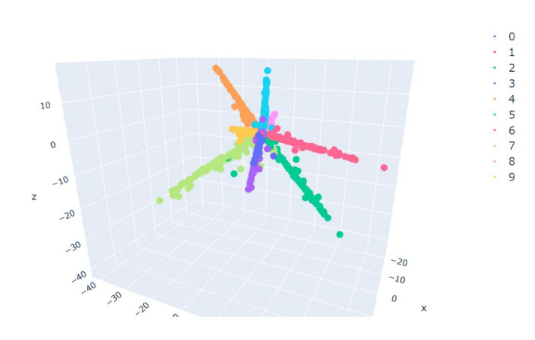
Training 결과
10개의 class를 3차원에 embedding!
class가 늘어나면 유동적으로 적절하게 embedding space의 차원을 설정할 수 있다.
너무 작으면 class간 충분한 angle이 주어지지 않는다.
너무 크면 차원의 저주로 인해 많은 데이터가 필요해진다.
Inference 과정
- target data의 embedding 좌표를 구한다
- database에서 각 class 별 몇 개씩 뽑아서
embedding 좌표를 구한다
(미리 계산해 놓을 수 있다) - target data와 대표 데이터들의 유사도를 비교해서
제일 가까운 class 별로 나열한다. - top n일 경우 추천모델, top 1일 경우 분류 모델이 된다.
Contrastive learning 정리
개념
• 절대적인 축이 아닌 데이터간의 유사함을 기준으로 임의의 차원의 latent space에 embedding하는 방법
장점
• 많은 class, 적은 데이터에도 상대적으로 높은 성능을 낸다. (meta-learning)
단점
• dataloader의 구성이 어렵다.
• 쌍을 구축하는 경우에 따라 학습데이터가 기하급수적으로 늘어난다. pair-wise : n^2, triplet : n^3
• batch의 영향을 많이 받기 때문에 batch를 크게 잡아야 할 때가 많다.
심화과정

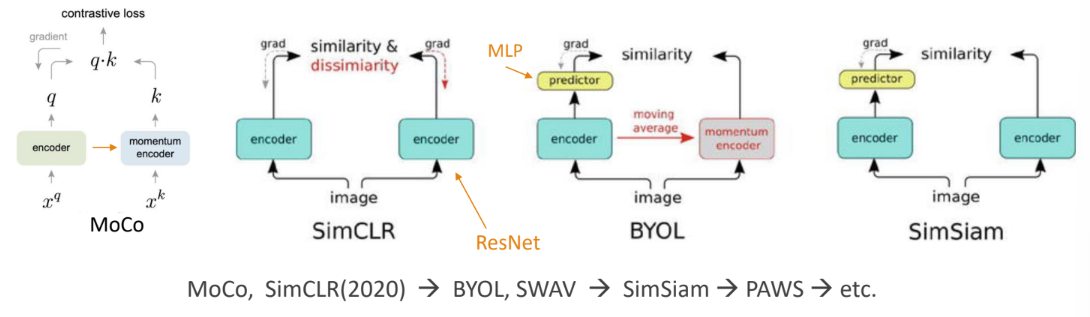
One-shot learning (Self-supervised learning)
Self-supervised learning (자기 지도 학습) :
• 내가 나를 스스로 가르친다. 내가 나의 label이 된다.
• Augmentated data는 모두 동일한 이미지(positive set)로 고려한다. 나머지는 negative set
SimCLR (simple framework for contrastive learning of visual representations)
Self-supervised learning
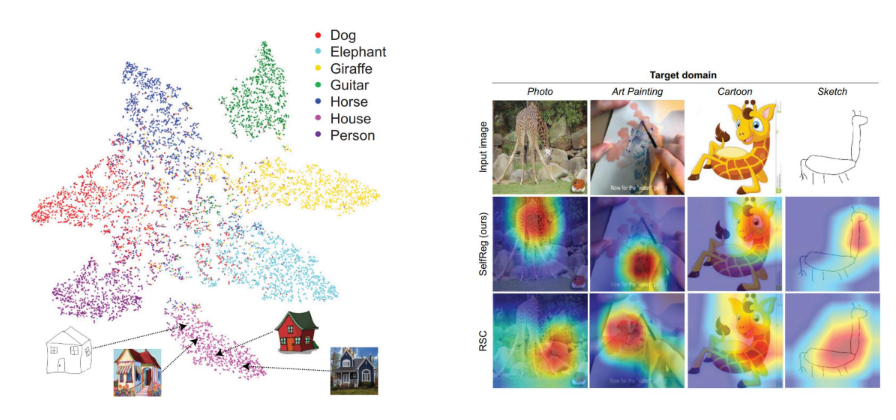
Zero-shot learning의 개념
• 대상을 설명할 수 있는 metadata를 같이 학습함 (e.g. Wikipedia)
• 내가 보지 못한 것들도 분류하거나 생성할 수 있음

참고:https://www.v7labs.com/blog/zero-shot-learning-guide
Zero-shot learning의 구조
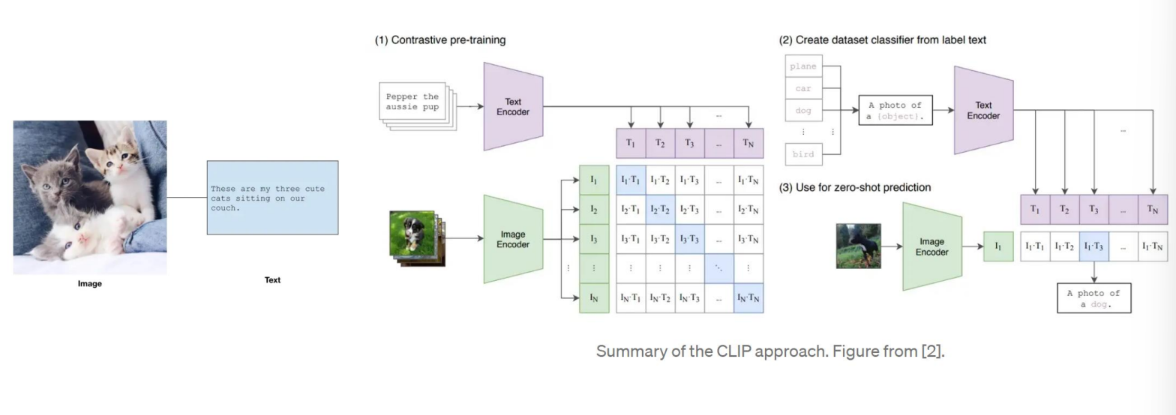
Metric learning Applications
Contrastive learning
Pairwise
Triplet
Multitask
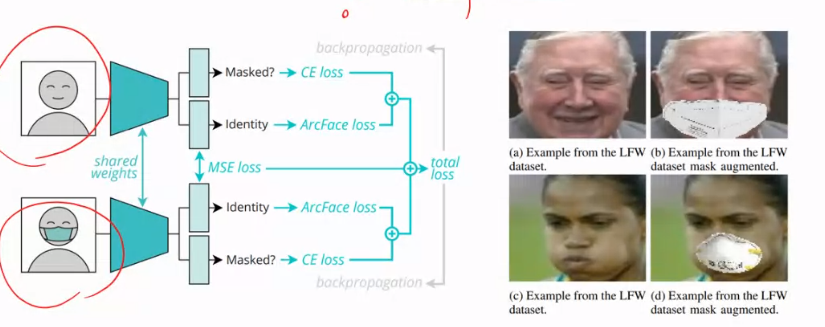
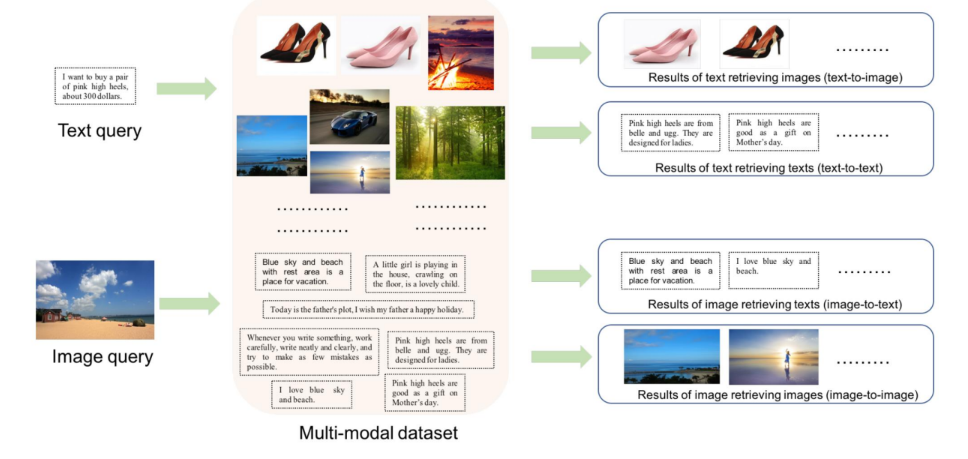
Multi-modal data
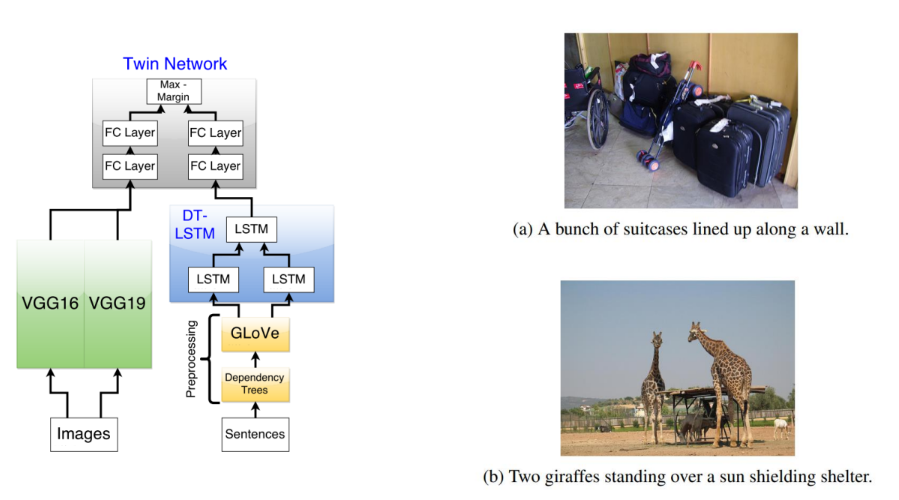
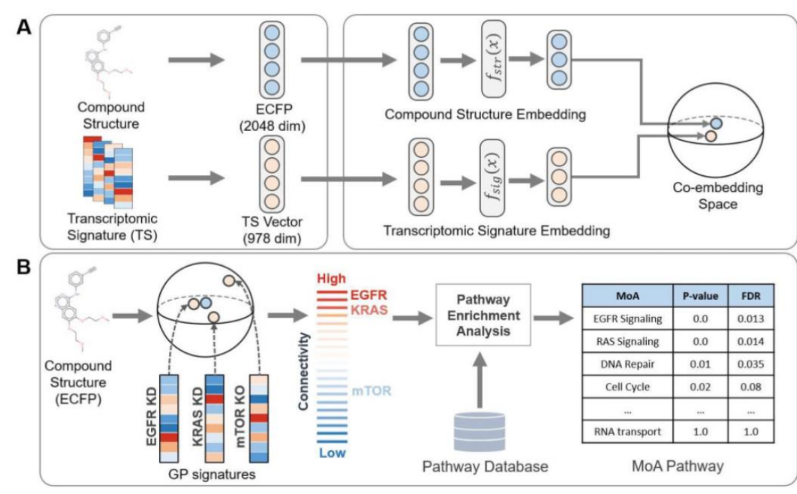
Self-supervised learning

흑백을 컬러로 가능

퍼즐로 만들고 빈공간 채우기도 가능
Zero-shot learning - Resolution Enhancement

고해상도로 만들기 가능
Zero-shot learning – Text to Image generation

글자로만 원하는 이미지 창조 가능
숫자는 파라미터의 갯수
