자료구조
자료구조란 여러 데이터의 묶음을 저장하고, 사용하는 방법을 정의한 것입니다.
자료구조를 설명하기에 앞서, 데이터(data)는 무엇일까요? 데이터는 문자, 숫자, 소리, 그림, 영상 등 실생활을 구성하고 있는 모든 값입니다.
우리의 이름, 나이, 키, 집 주소, 목소리 혹은 유전자 DNA까지 데이터로 분류할 수 있습니다. 그러나 데이터는 그 자체만으로 어떤 정보를 가지기 힘듭니다. 예를 들어 나이라는 데이터만 알고 있다면, 사람의 나이인지, 강아지의 나이인지, 나무의 나이인지 알 수 없습니다.
이처럼 데이터는 분석하고 정리하여 활용해야만 의미를 가질 수 있습니다.
그뿐만 아니라 데이터를 사용하려는 목적에 따라 형태를 구분하고, 분류하여 사용합니다. 만약 서로 다른 형태의 데이터를 하나의 방법으로만 정리하고 활용한다고 가정해 보겠습니다.
전화번호부를 작성할 때처럼, 숫자를 3개 또는 4개씩 묶음 짓고 하이픈(-)으로 합칩니다. 이 숫자의 묶음에 이름을 붙여 보관해야 한다면, 해당 데이터를 꺼낼 때는 항상 특정 이름을 입력해야 숫자를 얻을 수 있습니다. 전화번호부를 만든다면 그대로 사용해도 무방하지만, 전화번호부가 아닌 메일 주소와 이름을 매칭해 보관하거나, 메신저 아이디와 이름을 매칭해 보관해야 할 때는 하이픈()이 필요하지 않습니다. 이런 방법으로 숫자 데이터를 저장한다면, 모든 숫자에 필요하지 않은 이름을 꾸역꾸역 붙여야 합니다. 이처럼 필요에 따라 데이터의 특징을 잘 파악(분석)하여 정리하고, 활용해야 합니다.
데이터를 정해진 규칙 없이 저장하거나, 하나의 구조로만 정리하고 활용하는 것보다 데이터를 체계적으로 정리하여 저장해 두는 게, 데이터를 활용하는 데 있어 훨씬 유리합니다.
자료구조의 분류
수많은 선배 개발자는 무수한 상황에 데이터를 효율적으로 다룰 수 있는 여러 방법을 연구해 두었습니다.
무수한 상황의 예시
- 번호를 다 알지 않아도, 이름을 아는 것만으로 전화를 할 수 있는 방법은 무엇이 있을까?
- 웹 브라우저에서 뒤로 / 앞으로 가는 방법은 무엇이 있을까?
- 게임 매칭을 잡을 때, 수많은 사람을 통제하는 방법엔 무엇이 있을까? ...등등
그리고 선배 개발자들은 아래의 그림과 같이 수많은 데이터를 분류해 뒀습니다.
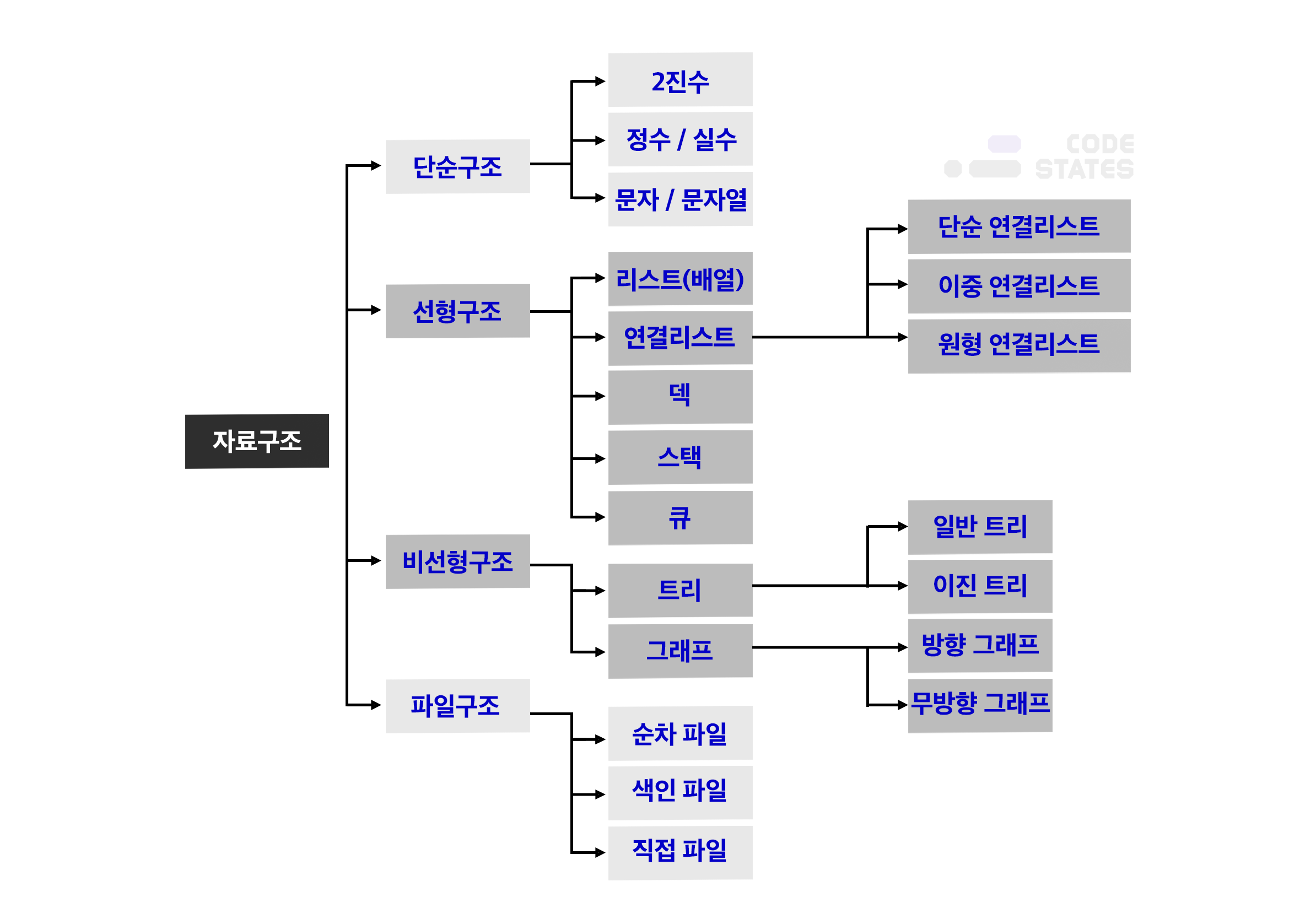
선배 개발자들은 무수한 상황에서 데이터를 효율적으로 다룰 방법을 모두 모아, 자료구조라는 이름을 붙였습니다. 우리는 이 많은 방법 중에서, 가장 많이 쓰이고 알고리즘 테스트(코딩 테스트)에 자주 등장하는 네 가지를 학습합니다.
- Stack, Queue, Tree, Graph
자료구조의 특징
대부분의 자료구조는 특정한 상황에 놓인 문제를 해결하는 데에 특화되어 있습니다. 따라서 많은 자료구조를 알아두면, 어떠한 상황이 닥쳤을 때 적합한 자료구조를 빠르고 정확하게 적용하여 문제를 해결할 수 있습니다.
이것은 문제 해결력을 필요로 하는 알고리즘 테스트(코딩 테스트)와 굉장히 밀접한 연관성이 있습니다. 특정 문제를 해결하는 데에 적합한 자료구조를 찾아 데이터를 정리하고 활용할 줄 알면, 상황에 가장 적합하고 정확한 코드를 작성할 수 있습니다.
Roadmap
자료구조에 대해 배우고, 문제를 풀기에 앞서 먼저 알아둬야 할 것이 있습니다.
스택(Stack)이나 큐(Queue) 등의 단어는 여러분에게는 다소 생소하여 어렵게 느껴질 수 있습니다. 그러나 여러분은 이미 대표적인 자료구조 중 하나를 써 왔습니다. 그 자료구조는 바로 배열(Array)입니다.
수차례에 걸친 연습으로, 여러분은 데이터를 순서대로 쭉 나열하여 저장한 배열이라는 자료구조의 특징과 활용 방안을 이미 알고 있습니다. 지금부터 학습할 자료구조도 별반 다르지 않습니다.
유닛의 핵심
-
각 자료구조가 가진 특징을 학습한다.
-
각 자료구조를 사용하기 적합한 상황을 이해한다.
-
다른 자료구조와의 차이점을 이해하기 위해 자료구조 내부를 직접 구현한다.
-
자료구조를 구현하며, 자료구조의 동작 원리를 이해한다.
유닛 학습 방식
-
주어진 챕터를 학습합니다.
-
class 키워드를 사용하여 자료구조의 데이터 타입을 직접 정의합니다. 이 과정에서 필요한 속성과 메서드를 학습합니다. 이 부분이 연습문제 챕터의 구현하기 부분입니다. 페어와 같이 진행합니다.
// class 키워드의 예
class Person {
constructor(name, hand, foot) {
this.name = name
this.hand = hand;
this.foot = foot;
}
speak() {
return `저는 ${this.name}입니다.`}
}
const kimcoding = new Person('김코딩', 2, 2);
console.log(kimcoding.speak()); // '저는 김코딩입니다.'- 자료구조를 활용해 알고리즘 문제를 풉니다. 이 부분이 연습문제 챕터의 연습문제입니다. 페어와 같이 진행합니다.
알고리즘 문제를 마주했을 때 문제를 풀기에 적합한 자료구조를 파악하고, 그에 알맞게 자료구조를 사용해야 합니다.
자료구조를 학습하기 시작한 지금, 문제를 마주하고 어떤 자료구조를 사용할지 결정할 수 없습니다. 그리고 알고리즘 문제를 만날 때마다 필요한 자료구조를 클래스로 직접 정의해서 풀기에는 다소 많은 시간이 소요됩니다. 테스트 시간이 무제한이라면 상관없지만, 대부분의 알고리즘 테스트에는 제한 시간이 존재합니다.
테스트에 걸리는 시간을 단축하고 알고리즘 문제 풀이에 집중하기 위해, JavaScript에서 제공하는 배열(Array)과 같은 데이터 타입을 이용해 자료구조의 형태와 유사하게 구현하여 문제를 해결합니다.
Stack의 정의
Stack은 쌓다, 쌓이다, 포개지다 와 같은 뜻을 가지고 있습니다. 마치 접시를 쌓아 놓은 형태와 비슷한 이 자료구조는 직역 그대로, 데이터(data)를 순서대로 쌓는 자료구조입니다. 일상생활에서 Stack과 비슷한 예를 찾아볼 수 있습니다:
동그란 원통에 차례대로 구슬을 넣는다고 상상해 보세요. 우리는 원통의 맨 위에 뚫려있는 구멍을 통해 구슬을 넣을 수 있고, 구술을 뺄 때 또한 원통의 맨 위에 뚫려있는 구멍을 통해 맨 위에 있는 구슬을 먼저 뺄 수 있습니다.
Stack의 구조
원통을 자료구조 Stack, 구슬을 데이터(data)로 비유할 수 있습니다.
우리가 구슬을 차례대로 원통에 넣었을 때 가장 나중에 넣은 구슬이 원통의 가장 상단에 자리 잡고 있고,
그렇기 때문에 구슬을 빼는 경우에 가장 나중에 넣었던, 원통 상단에 위치한 구슬을 가장 먼저 뺄 수 있습니다.
-
자료구조 Stack의 특징은 입력과 출력이 하나의 방향, 즉 스택의 최상단에서만 이루어지는 제한적 접근에 있습니다.
-
이런 Stack 자료구조의 정책을 LIFO(Last In First Out) 혹은 FILO(First In Last Out)라고 부르기도 합니다.
-
Stack에 데이터를 넣는 것을 'PUSH', 데이터를 꺼내는 것을 'POP'이라고 합니다.
Stack의 특징
1. LIFO(Last In First Out)
먼저 들어간 데이터는 제일 나중에 나오는 후입선출의 구조로 되어 있습니다.
예1) 1, 2, 3, 4를 스택에 차례대로 넣습니다.
stack.push(데이터)
| 4 | <- top
| 3 |
| 2 |
| 1 |
들어간 순서대로, 1번이 제일 먼저 들어가고 4번이 마지막으로 들어가게 됩니다.
예2) 스택이 빌 때까지 데이터를 전부 빼냅니다.
stack.pop()
| |
| |
| |
| |
4, 3, 2, 1
제일 마지막에 있는 데이터부터 차례대로 나오게 됩니다.이러한 특성으로 인해 스택 구조 내에서 특정 데이터를 조회할 수 없으며, 스택의 최상단에서만 데이터를 저장하고 꺼낼 수 있는 특징이 있습니다.
그 때문에 데이터를 저장할 때나 검색할 때 항상 스택의 최상단에서만 행위가 이루어지며 이에 따라 데이터를 저장하고 검색하는 프로세스가 매우 빠릅니다.
2. 하나의 입출력 방향을 가지고 있습니다.
Stack 자료구조는 데이터를 넣고 뺄 수 있는 곳이 스택의 가장 최상단, 한 군데입니다. 즉 데이터를 넣을 때도 스택의 가장 최상단으로 넣고(입력) 뺄 때 또한 스택의 가장 최상단으로 데이터를 뺄 수(출력) 있습니다.
3. 데이터는 하나씩 넣고 뺄 수 있습니다.
앞서 말했듯, Stack 자료구조는 데이터를 넣고 뺄 수 있는 경로가 스택의 최상단, 한 군데이기 때문에 스택 내부에 데이터를 넣을 때도 하나씩 최상단을 통해 넣고 데이터를 뺄 때 또한 항상 스택 최상단에서 하나씩 데이터를 뺄 수 있습니다.
즉, 스택에 한 개씩 여러 번 데이터를 넣어 스택 내부에 데이터가 여러 개 쌓여 있다고 하더라도, 데이터를 뺄 때는 스택의 가장 최상단에서 한 번에 한 개의 데이터만을 뺄 수 있습니다.
Stack의 실사용 예제
컴퓨터에서 자료구조 Stack은 어떤 곳에 사용되고 있을까요? 대표적으로 우리가 자주 사용하는 브라우저의 뒤로 가기, 앞으로 가기 기능을 구현할 때 자료구조 Stack이 활용됩니다.

브라우저에서 자료구조 Stack이 사용될 때는 다음과 같은 순서를 거칩니다.
- 새로운 페이지로 접속할 때, 현재 페이지를 Prev Stack에 보관합니다.
- 뒤로 가기 버튼을 눌러 이전 페이지로 돌아갈 때는, 현재 페이지를 Next Stack에 보관하고 Prev Stack에 가장 나중에 보관된 페이지를 현재 페이지로 가져옵니다.
- 앞으로 가기 버튼을 눌러 앞서 방문한 페이지로 이동을 원할 때는, Next Stack의 가장 마지막으로 보관된 페이지를 가져옵니다.
- 마지막으로 현재 페이지를 Prev Stack에 보관합니다.
이렇게 자료구조 Stack을 이용하면, 뒤로 가기와 앞으로 가기 버튼을 구현할 수 있습니다.
Queue의 정의
큐(Queue)는 줄을 서서 기다리다, 대기행렬이라는 뜻을 가지고 있습니다. 어떤 구조로 되어 있는지 짐작할 수 있나요?
명절에는 고향으로 가기 위해 많은 자동차가 고속도로를 지납니다. 고속도로에는 톨게이트가 있고, 자동차는 톨게이트에 진입한 순서대로 통행료를 내고 톨게이트를 통과합니다.
톨게이트를 Queue 자료구조, 자동차는 데이터(data)로 비유할 수 있습니다.
이 그림에서 볼 수 있듯이 가장 먼저 진입한 자동차가 가장 먼저 톨게이트를 통과합니다. 다시 말해, 가장 나중에 진입한 자동차는 먼저 도착한 자동차가 모두 빠져나가기 전까지는 톨게이트를 빠져나갈 수 없다는 말입니다.
Queue의 구조
자료구조 Queue는 Stack과 반대되는 개념으로, 먼저 들어간 데이터(data)가 먼저 나오는 FIFO(First In First Out) 혹은 LILO(Last In Last Out)을 특징으로 가지고 있습니다.
티켓을 사려고 줄을 서서 기다리는 모습과 흡사한 이 자료구조는 입력의 방향과 출력의 방향이 각각 고정되어 있으며, 데이터를 입력할 시에는 큐의 끝에서(tail), 데이터를 출력할 때는 큐의 맨 앞에서(head) 진행됩니다.
Queue에 데이터를 넣는 것을 'enqueue', 데이터를 꺼내는 것을 'dequeue'라고 합니다.
자료구조 Queue는 데이터(data)가 입력된 순서대로 처리할 때 주로 사용합니다.
Queue의 특징
1. FIFO (First In First Out)
먼저 들어간 데이터가 제일 처음에 나오는 선입선출의 구조로 되어 있습니다.
예1) 1, 2, 3, 4를 큐에 차례대로 넣습니다.
queue.enqueue(데이터)
출력 방향(head) <---------------------------< 입력 방향(tail)
1 <- 2 <- 3 <- 4
<---------------------------<
들어간 순서대로, 1번이 제일 먼저 들어가고 4번이 마지막으로 들어가게 됩니다.
예2) 큐가 빌 때까지 데이터를 전부 빼냅니다.
queue.dequeue(데이터)
출력 방향(head) <---------------------------< 입력 방향(tail)
<---------------------------<
1, 2, 3, 4
제일 첫 번째 있는 데이터부터 차례대로 나오게 됩니다.2. 두 개의 입출력 방향을 가지고 있습니다.
Queue 자료구조는 데이터의 입력, 출력 방향이 다릅니다.
데이터를 입력할 때는 큐의 맨 끝(tail)으로만 입력이 가능하며 데이터를 출력할 때는 큐의 맨 앞(head)으로만 출력이 가능합니다.
즉, 큐는 데이터를 입력하는 곳과 출력하는 곳이 각각 정해져 있으며 이렇게 총 2개의 입출력 방향을 가지고 있습니다.
만약 입출력 방향이 같다면 Queue 자료구조라고 볼 수 없습니다.
3. 데이터는 하나씩 넣고 뺄 수 있습니다.
앞서 말했듯, Queue 자료구조는 데이터를 넣을 때는 큐의 맨 뒷부분에서 뺄 때는 큐의 맨 앞부분에서 처리를 진행합니다.
각 처리 시마다 한 개의 데이터를 넣거나 뺄 수 있습니다.
즉, 큐에 한 개씩 여러 번 데이터를 넣어 큐 내부에 데이터가 여러 개 쌓여 있다고 하더라도, 데이터를 뺄 때는 큐의 맨 앞에서 한 번에 한 개의 데이터만을 뺄 수 있습니다.
Queue의 실사용 예제
자료구조 Queue는 컴퓨터에서도 광범위하게 활용됩니다. 컴퓨터와 연결된 프린터에서 여러 문서를 순서대로 인쇄하려면 어떻게 해야 할까요?
-
우리가 문서를 작성하고 출력 버튼을 누르면 해당 문서는 인쇄 작업 (임시 기억 장치의) Queue에 들어갑니다.
-
프린터는 인쇄 작업 Queue에 들어온 문서를 들어온 순서대로 인쇄합니다.
컴퓨터(출력 버튼) - (임시 기억 장치의) Queue에 하나씩 들어옴 - Queue에 들어온 문서를 들어온 순서대로 인쇄
만약 Queue에 들어온 순서대로 출력하지 않는다면, 인쇄 결과물이 뒤죽박죽일 겁니다.
위 예시처럼 컴퓨터 장치들 사이에서 데이터(data)를 주고받을 때, 각 장치 사이에 존재하는 속도의 차이나 시간 차이을 극복하기 위해 임시 기억 장치의 자료구조로 Queue를 사용합니다. 이것을 통틀어 버퍼(buffer)라고 합니다.
아래 이미지는 버퍼링(buffering)의 개념을 보여주고 있습니다.
대부분의 컴퓨터 장치에서 발생하는 이벤트는 파동 그래프와 같이 불규칙적으로 발생합니다. 이에 비해 CPU와 같이 발생한 이벤트를 처리하는 장치는 일정한 처리 속도를 갖습니다. 불규칙적으로 발생한 이벤트를 규칙적으로 처리하기 위해 버퍼(buffer)를 사용합니다.
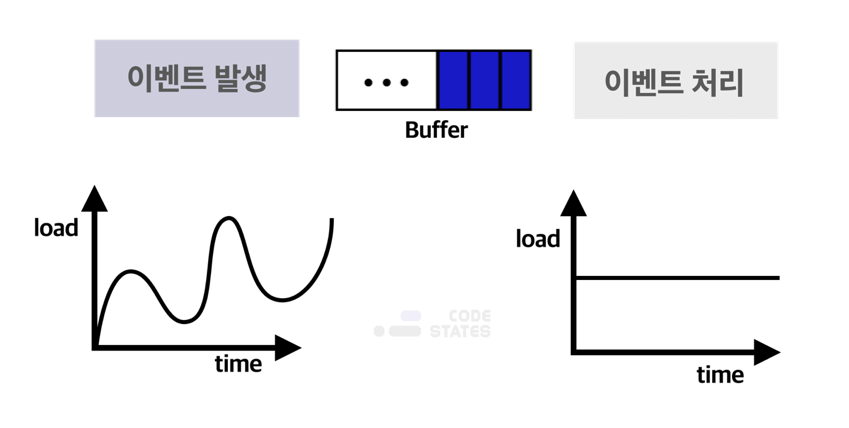
컴퓨터와 프린터 사이의 데이터(data) 통신을 정리하면 다음과 같습니다.
-
일반적으로 프린터는 속도가 느립니다.
-
CPU는 프린터와 비교하여, 데이터를 처리하는 속도가 빠릅니다.
-
따라서, CPU는 빠른 속도로 인쇄에 필요한 데이터(data)를 만든 다음, 인쇄 작업 Queue에 저장하고 다른 작업을 수행합니다.
-
프린터는 인쇄 작업 Queue에서 데이터(data)를 받아 들어온 순서대로 일정한 속도로 인쇄합니다.
유튜브와 같은 동영상 스트리밍 앱을 통해 동영상을 시청할 때, 다운로드된 데이터(data)가 영상을 재생하기에 충분하지 않은 경우가 있습니다. 이때 동영상을 정상적으로 재생하기 위해 Queue에 모아 두었다가 동영상을 재생하기에 충분한 양의 데이터가 모였을 때 동영상을 재생합니다.
