
💡 최적화에 대한 많은 용어가 생기는데 용어에 명확한 이해가 없다면 뒤로 갈수록 큰 오해가 쌓일 수 있다
Gradient Descent
- 미분 가능한 최소값을 찾기위한 최적화 알고리즘
Important Concepts in Optimization
Generalization( 일반화 )
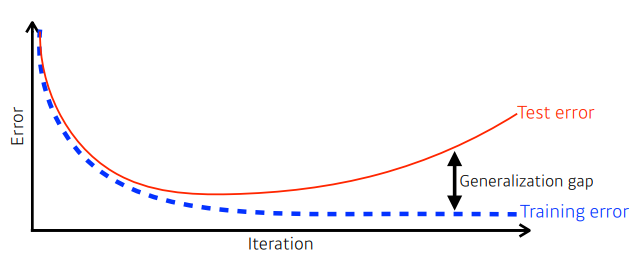
- 학습된 모델은 보이지 않는 데이터를 얼마나 잘 수행할 것인가?
- 많은 경우에 우리는 일반화 성능을 높이는 것이 목표이다
- Training error가 0이 되었다해서 우리가 원하는 최적화 값에 도달했다고 보장할 수 없다
- 일반적으로 Training error가 줄어들지만 시간이 지날수록 Test error( 학습하지 않는 데이터 )가 증가한다
- 따라서 Generalization gap이 증가하게 된다
- Test error와 Training error 와의 차
- 학습데이터의 성능 자체가 안 좋을 때는 Generalization performance가 좋다고 해서 Test performance가 좋다고 할 수 없다
Underfitting vs Overfitting
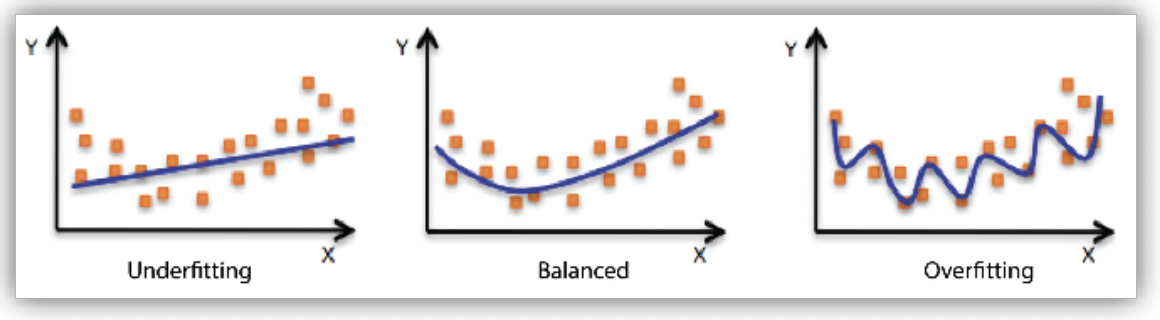
Underfitting
- 학습데이터에 대해서 잘 동작하지 못하는 것
Overfitting
- 학습데이터에 대해선 잘 동작하지만 Test data에 대해선 잘 동작하지 않는 것
Cross-Validation ( 교차 검증 )
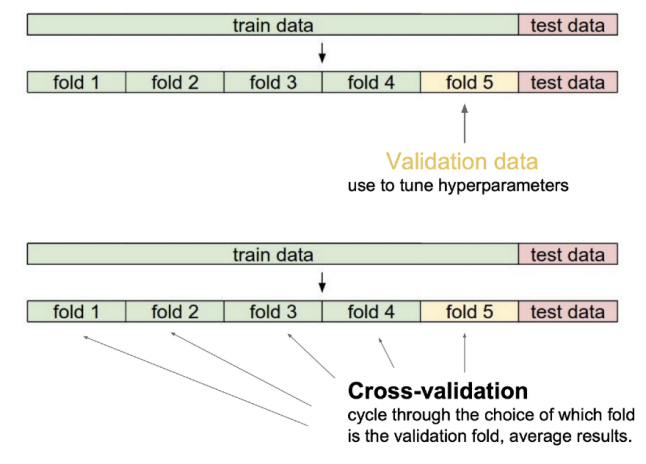
- K for validation이라고도 한다
- train data와 validation data를 k개로 나눠서 k-1개로 학습을 시키고 나머지 1개로 test를 해보는 것
- Cross-validation을 통해 hyperparameter를 찾는다
- test validation을 활용해 Cross-validation 하거나, hyperparameter를 찾을 수 없다
Bias and Variance
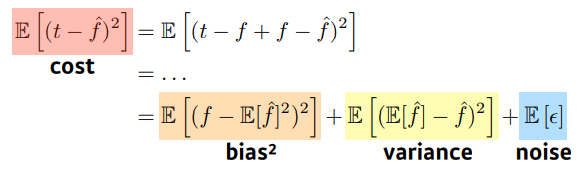
- 비용을 최소화 하려 할 때 , variance, noise** 을 통해 시도해 볼 수있다
- 학습데이터에 노이즈가 껴있다고 가정했을 때
- tradeoff : 값 하나가 작아지면 다른 값 하나가 커지게 된다
- t : target
- : neural network 출력 값
- cost를 minimize 하려하면 bias, variance, noise를 줄여야하는데 동시에 줄일 수 없다
- bias를 줄이면 variance가 높아지고, variance를 줄이면 bias가 높아질 확률이 크다
Boostrapping
- 랜덤 샘플링에 의존하는 test 또는 metric
- 학습데이터가 고정되어 있을 때 그 안에서 sub sampling을 통해 학습데이터를 여러개 만든다
- 이를 통해 여러 모델, metric을 만든다
Bagging vs Boosting
Bagging( Bootstrapping aggregating )
- 여러 모델들이 Bootstrapping으로 학습되고 있다
- 학습데이터를 여러개 만들어 여러 모델을 통해 출력값의 평균을 내는 것 ( 앙상블 )
Boosting
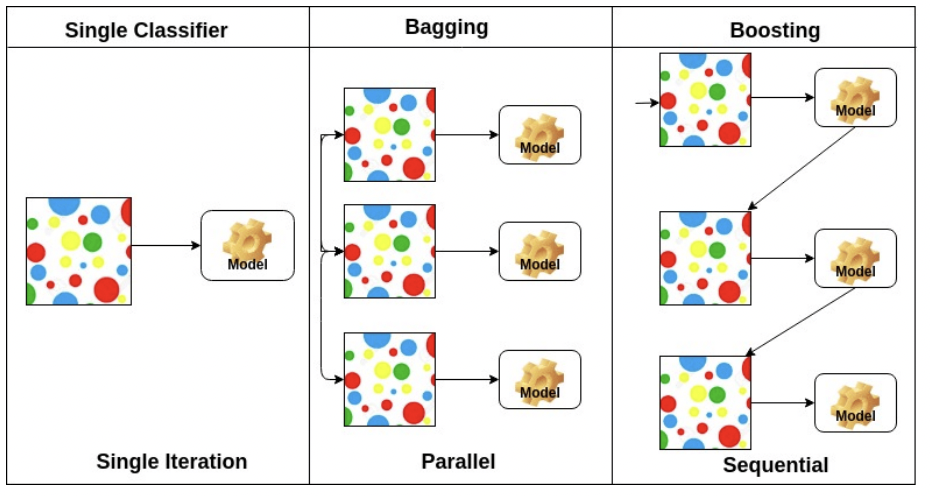
- 분류하기 어려운 특정 훈련 샘플에 중점을 둔다
- 강한 모델( strong model )은 각 학습자가 이전 약한 학습자( weak learner )의 실수에서 배우는 약한 학습자를 순서대로 결합하여 구축된다
- 여러개의 weak learner를 통해 하나의 strong model을 만든다
Gradient Descent Methods
Stochastic gradient descent
- 단일 샘플에서 계산된 가중치로 업데이트
Mini-batch gradient descent
- subset data를 통해 계산된 가중치로 업데이트
Batch gradient descent
- 전체 데이터에서 계산된 가중치로 업데이트
- Stochastic gradient descent
- Momentum
- Nesterov accelerated gradient
- Adagrad
- Adadelta
- RMSprop
- Adam
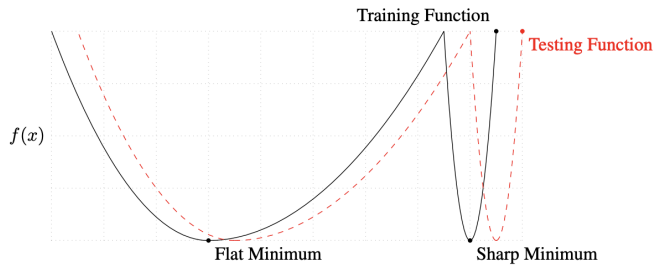
Batch-size Matters

Regularization
- Earlystopping
- Parameternormpenalty
- Dataaugmentation
- Noiserobustness
- Labelsmoothing
- Dropout
- Batchnormalization

data science!!, data analyst!! ///// hello world