45번 영상 : 2개의 튜플의 합집합과 교집합을 출력
( 내 풀이 )
tuple1 = (1, 3, 2, 6, 12, 5, 7, 8)
tuple2 = (0, 5, 2, 9, 8, 6, 17, 3)
# tuple1 = list(tuple1) #튜플도 수정하는 거외에는 다할 수 있다. 필요없는 작업
# tuple2 = list(tuple2)
interGp = []
unionGp = []
for i in tuple1:
for j in tuple2:
if i == j: #굳이 같은지 안 같은지 볼 필요가 없음.
interGp.append(j)
if j not in unionGp:
unionGp.append(j)
else: #in ,not in만 쓰면 되거든!
if j not in unionGp:
unionGp.append(j)
if i not in unionGp:
unionGp.append(i)
unionGp.sort()
interGp.sort()
print('합집합 : {}'.format(tuple(unionGp)))
print('교집합 : {}'.format(tuple(interGp)))[Output]
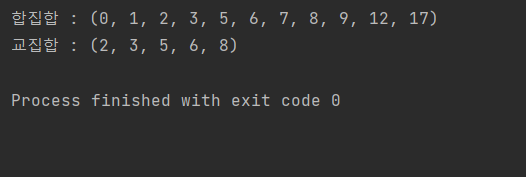
🤔 결과 값은 나왔지만 구구절절인 부분이 너무 많다.
( 영상 풀이 / for문 사용 )
tuple1 = (1, 3, 2, 6, 12, 5, 7, 8)
tuple2 = (0, 5, 2, 9, 8, 6, 17, 3)
tempHap = list(tuple1) #합집합
tempGyo = list() #교집합
#어차피 합치는 거니까 합집합은 tuple1을 가지고 있어 계산을 줄일 수 있음
for n in tuple2:
if n not in tempHap:
tempHap.append(n)
else:
tempGyo.append(n)
tempHap = tuple(tempHap)
tempGyo = tuple(tempGyo)( 영상 풀이 / while문 사용 )
tuple1 = (1, 3, 2, 6, 12, 5, 7, 8)
tuple2 = (0, 5, 2, 9, 8, 6, 17, 3)
tempHap = tuple1 + tuple2 #중복된 상태
tempGyo = list()
tempHap = list(tempHap)
idx = 0
while True:
if idx >= len(tempHap):
break
if tempHap.count(tempHap[idx]) > = 2:
tempGyo.append(tempHap[idx])
tempHap.remove(tempHap[idx])
continue #idx 그대로인 상태에서 다시 맨위의 if문을 쓰기 위해서!
idx += 1
list.index(max(list)) : 리스트에서 가장 큰 값의 인덱스 위치를 알 수 있음
47번 영상 : 튜플 과일 개수에 대해서 오름차순 및 내림차순으로 정렬해보자
fruits = ({'수박': 8}, {'포도':13}, {'참외':12}, {'사과':17}, {'자두':19} ,{'자몽':15})
fruits = list(fruits)
cIdx = 0; nIdx = 1; eIdx = len(fruits) - 1
#cIdx와 그 다음 nIdx, 그 다음을 다 비교나서 cIdx + 1, 즉 cIdx가 비교의 기준, nIdx가 비대상으로 볼 수 있다
flag = True
while flag:
curDic = fruits[cIdx]
nextDic = fruits[nIdx]
curDiccnt = list(curDic.values())[0]
nextDiccnt = list(nextDic.values())[0]
#왜 이렇게 하는지 아래 설명 참고
if nextDiccnt < curDiccnt:
fruits.insert(cIdx, fruits.pop(nIdx))
#cIdx 위치에 pop한 값을 삽입
nIdx = cIdx + 1 #반복 초기화. 위치가 바뀌어서 새로운 idx가 뒤에 왔으니 지금 위치에서 다시 시작~
continue
nIdx += 1
if nIdx > eIdx: #길이 다 끝났으니 비교 기준 바꾸기
cIdx += 1
nIdx = cIdx + 1
if cIdx == 5:
flag = False
print(tuple(fruits))
[Output]
({'수박': 8}, {'포도': 13}, {'참외': 12}, {'사과': 17}, {'자두': 19}, {'자몽': 15})
.
.
🔎 왜 값을 쓰기 위해서 그냥 values() 값을 안 쓰고, list(curDic.values())[0] 을 썼을까?
#처음에는 딕셔너리여서 값이 key, value 두 개 나와서 인덱싱 하나보다! 했는데,
values()로 값만 불러내는 거라서 아님
하나하나 풀어보면,
1단계) curDic.values() ▷ type이 dict_values으로, 출력하면 'dict_values([8])' 이 나온다.
2단계) list(curDic.values()) ▷ 리스트로 감싸면, 출력값 [8]
3단계) list(curDic.values())[0] ▷ 인덱스를 집어넣기에 내용만 추출 가능, 출력값 8
if list를 붙이지 않고 curDic.values()[0] 할 경우,
▷ TypeError: 'dict_values' object is not subscriptable이 뜸.
▷ subscriptable = 인덱싱이 가능한, 슬라이싱이 가능한 이정도인데, dict_values는 인덱싱이 불가능해서 뜨는 에러
▷ 이런 에러가 뜰 때 리스트로 바꾸고 인덱스에 접근해야 함.
.
.
48번 영상 : 튜플을 이용해 요구사항에 맞는 데이터를 출력하는 프로그램
전체 학생 수, 평균 학생 수, 학생 수가 가장 적은 학급, 학생 수가 가장 많은 학급, 학급별 학생편차를 구해라
studentCnt = ({'cls01':18},
{'cls02':21},
{'cls03':22},
{'cls04':19},
{'cls05':22},
{'cls06':20},
{'cls07':23},
{'cls08':17})
for idk, dic in enumerate(studentCnt):
for k, v in dic.items():
totalCnt += v
if minStdcnt == 0 or minStdcnt > v:
minStdcnt = v
minCls = k
elif maxStdcnt < v:
maxStdcnt = v
maxCls = k
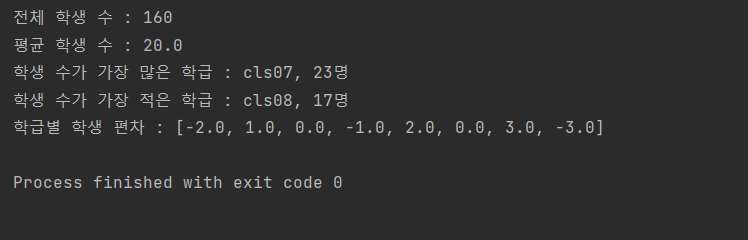
print('전체 학생 수 : {}'.format(totalCnt))
avgCnt = totalCnt / len(studentCnt)
print('평균 학생 수 : {}'.format(avgCnt))
print('학생 수가 가장 많은 학급 : {}, {}명'.format(maxCls, maxStdcnt))
print('학생 수가 가장 적은 학급 : {}, {}명'.format(minCls, minStdcnt))
devStd = []
for idx, dic in enumerate(studentCnt):
for k, v in dic.items():
devStd.append(v - avgCnt)
print('학급별 학생 편차 : {}'.format(devStd))
[Output]

데이터로 경로를 탐색합니다.