제로베이스 데이터분석 공부
1.제로베이스 데이터 스쿨 19기 OT 후기

커뮤니티, 교육 프로그램 기획/운영 매니저로 일하면서 내가 느끼는 불편함, 문제의식에서 시작된 프로젝트, 캠프를 만들었다.재밌게 다양한 활동을 했는데, 어느 순간부터 IN > OUT 방식 기획의 한계를 느꼈고, 진짜 사람들의 생각, 행동은 무엇일지 궁금해졌다.그와 동시
2.1.1 파이썬 기초 스터디노트
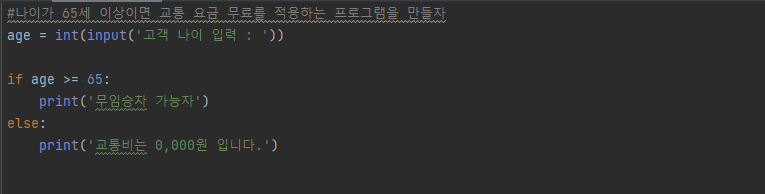
Part 01. Python Chapter 01-02. 파이썬 기초 & 문제풀이
3.팀스터디 1주차 (23.09.14)
제로베이스 데이터스쿨 팀스터디📖 1주차 과제와 후기이!
4.1.4 파이썬 중급 문풀_단리/복리
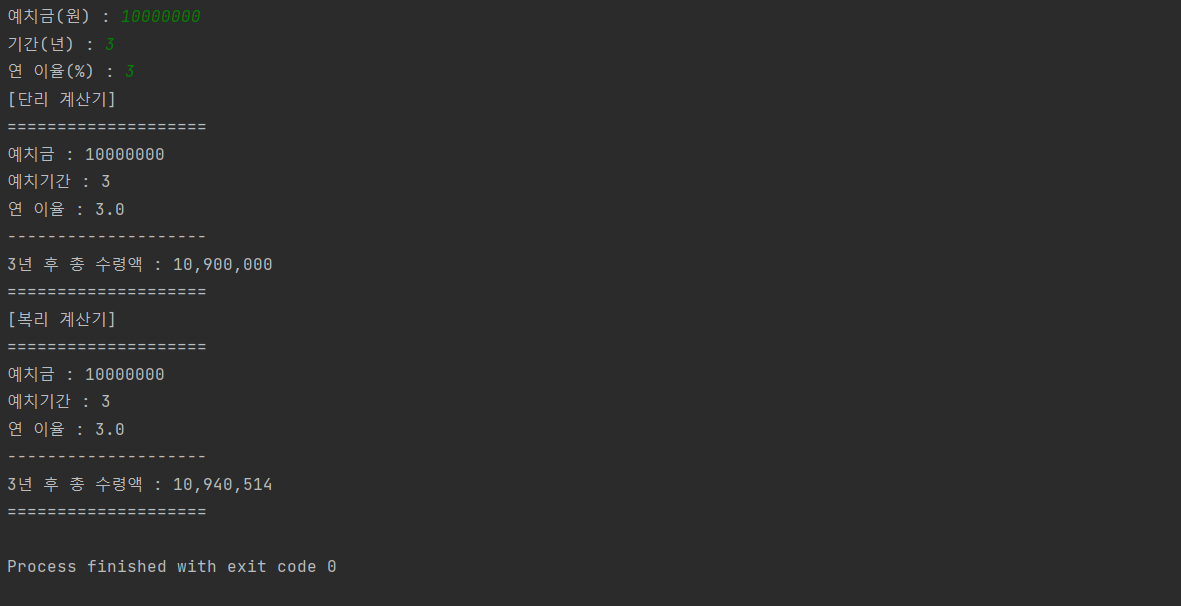
파이썬 중급_단리/월복리 계산기 문제풀이
5.1.4 중급 파이썬 문풀_재귀/variable shadowing
재귀함수, Variable Shadowing, UnboundLocalError
6.1.4 중급 파이썬 문_등차/등비수열
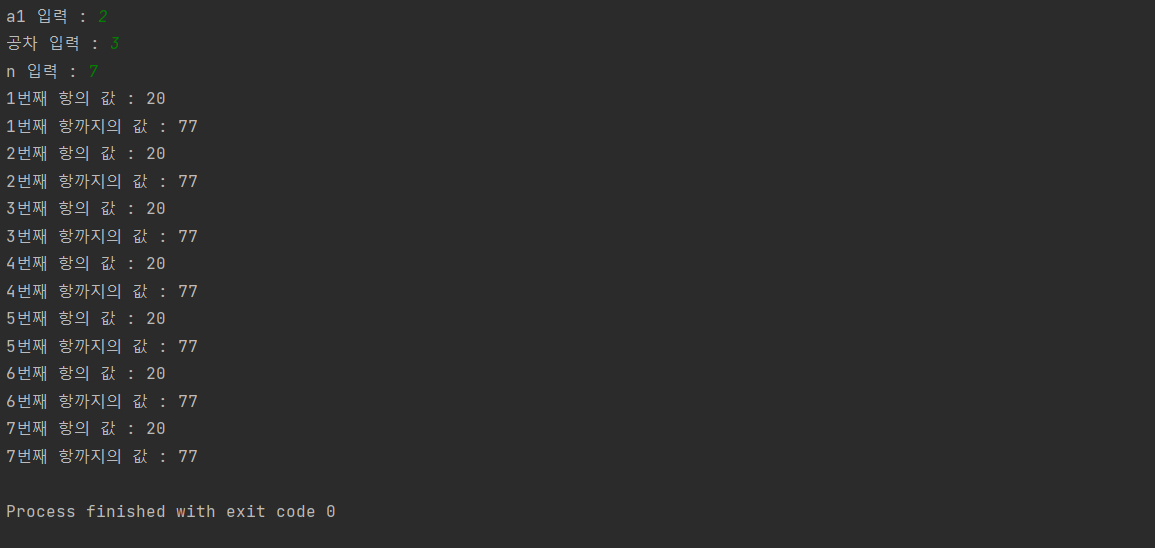
등차수열, 등비수열 문제풀이
7.2.1 기초수학 스터디노트

진수변환, 등차수열/등비수열, 계차수열, 군수열, 순열, 조합, 확률
8.3.1 파이썬 자료구조_list 스터디노트
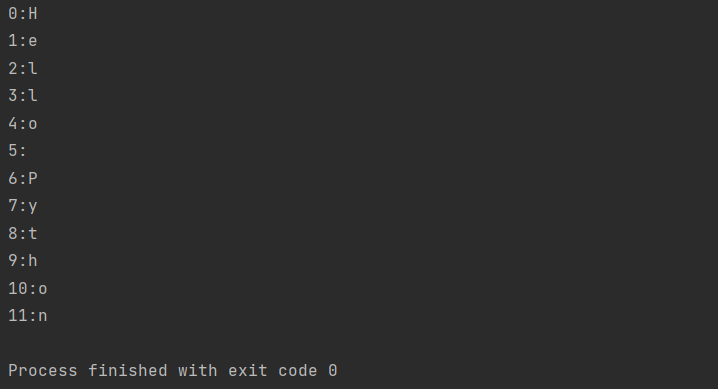
파이썬 자료구조 리스트 내용 정리
9.3.1 파이썬 자료구조_tuple, dict 스터디노트

튜플, 리스트 기본 내용
10.3.3 파이썬 알고리즘 스터디노트
선형검색, 이진검색, 버블정렬, 삽입 정렬, 선택정렬, 최댓값, 최솟값, 최빈값, 근삿값, 평균, 재귀, 병합 정렬, 퀵 정렬 정의
11.3.2 파이썬 자료구조 문제풀이1 / sort() None 반환하는 이유

40번, 41번, 42번, 정렬함수 sort( )와 sorted ( ) 차이, sort( ) 쓸 때 None이 반환되는 이유
12.파이썬 Random 모듈 정리
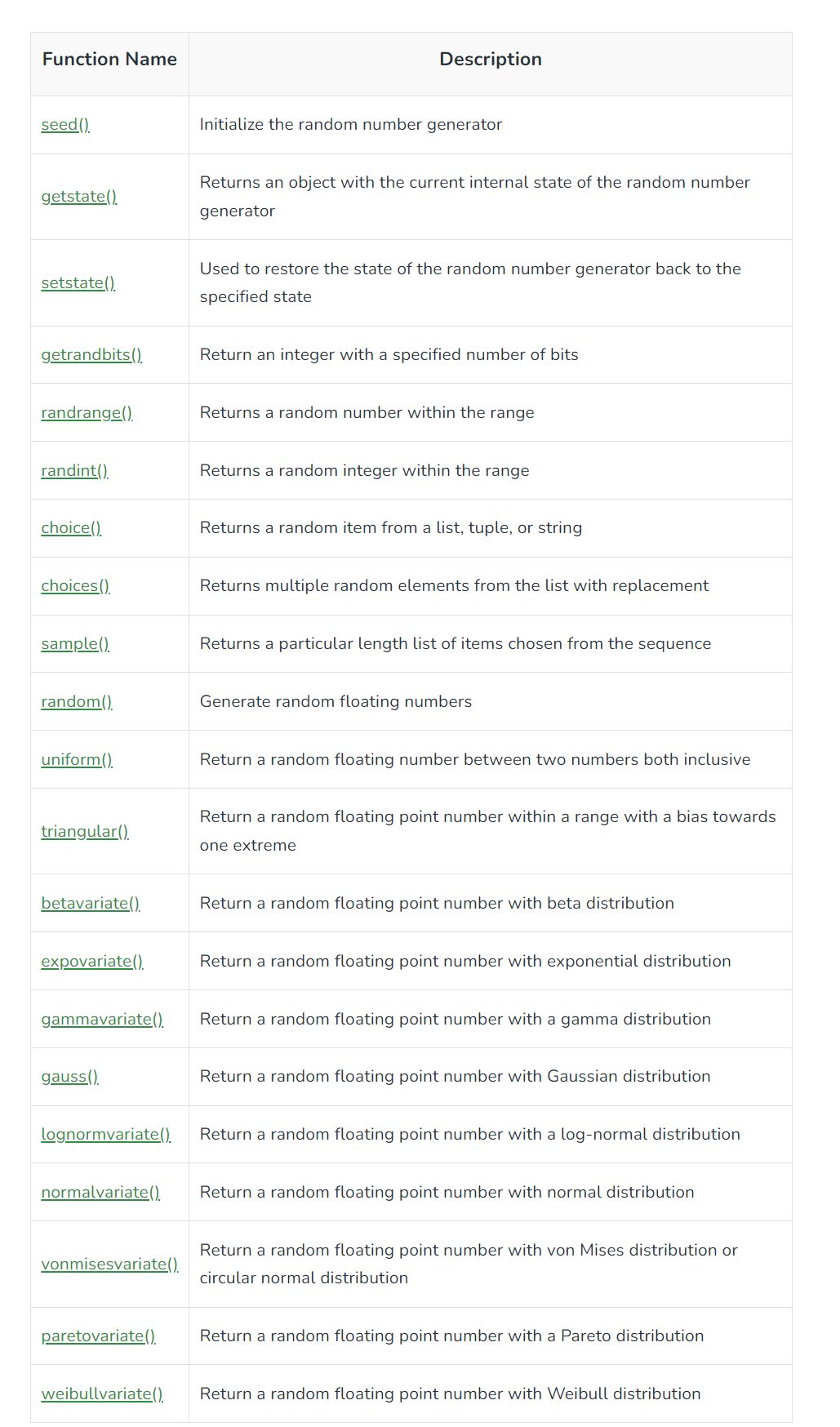
랜덤 모듈정리
13.시간 Time 모듈 정리
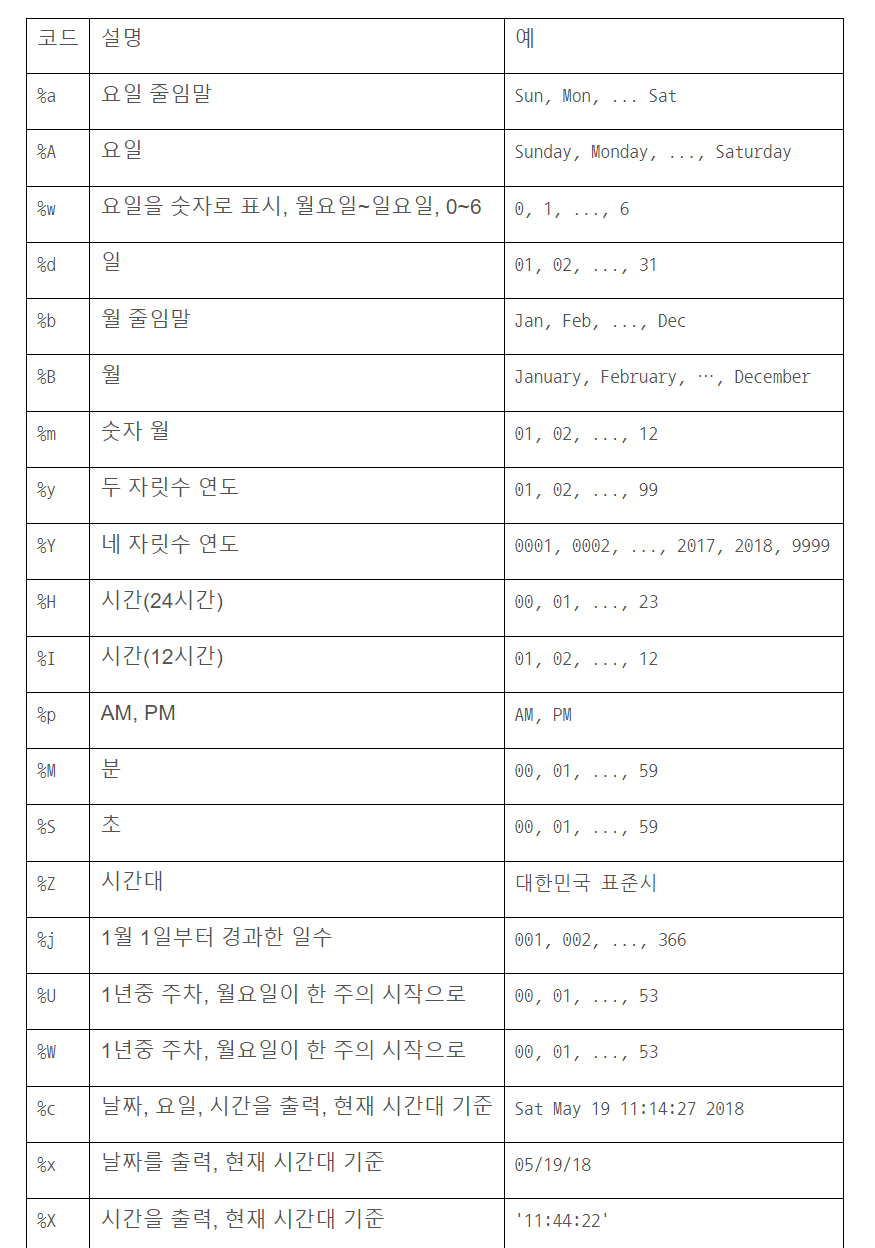
time, datetime 정리
14.3.2 파이썬 자료구조 문제풀이2_list2
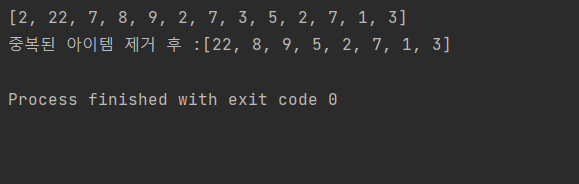
42번 , 43번
15.3.2 파이썬 자료구조 문제풀이3_tuple
45 ~ 48번 문제
16.3.2 파이썬 자료구조 문제풀이4_Dictionary
딕셔너리을 사용하는 방법
17.4.2 pandas/matplotlib 기초
Pandas 기초 import pandas as pd > ### Series : Pandas의 데이터를 구성하는 기본 index, value로 구성 시리즈는 한 타입의 데이터만 가질 수 있다. 시간이용 : pd.date_range("20230101", peri
18.파이썬 조건문 | 정수인지 확인하는 여러 가지 방법
정수인지 확인하는 여러 가지 방법
19.3.3 파이썬 알고리즘 실습 스터디노트
선형검색, 이진검색, 버블정렬, 삽입 정렬, 선택정렬, 최댓값, 최솟값, 최빈값, 근삿값, 평균, 재귀 실습
20.파이썬 프로그래밍 테스트1 풀이와 막힌 부분
제로베이스 파이썬 프로그래밍 테스트 1번 문제 풀이(주관 주의)
21.1.2 파이썬 기초 문풀 스터디노트

조건문, 반복문
22.오답노트 | 퀴즈_서울시 범죄현황
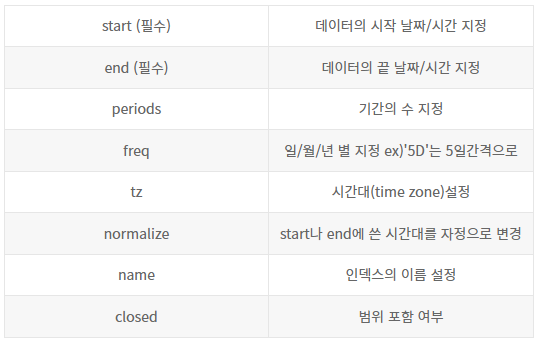
퀴즈에서 헷갈린 내용과 몰랐던 내용을 정리합니다. list comprehension, date_range, iterrows, linspace vs arange, get_level_values, poly1d
23.4.2 EDA | 서울시 CCTV 현황 데이터분석 스터디노트
pip conda
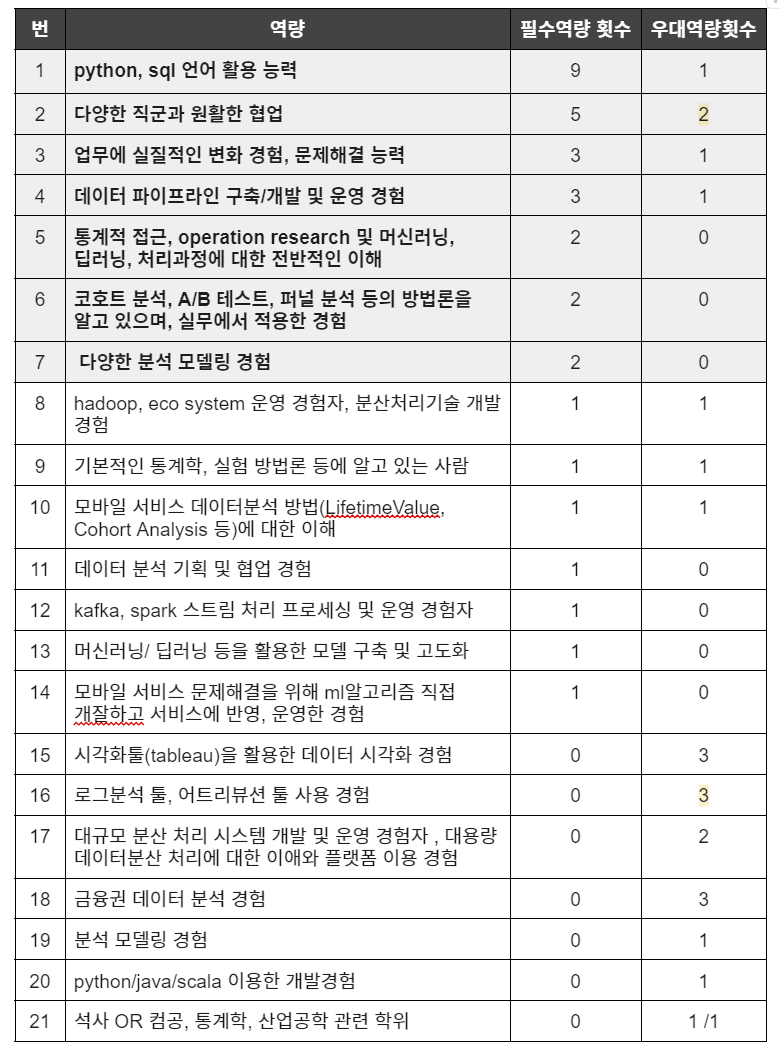
24.팀스터디 3주차 (23.09.25)
분야와 직부를 탐색한 후 필터링한 기존 스크랩 기반 채용 공고에서 공통적으로 보는 역량은 무엇인지 파악
25.팀스터디 4주차 (23.10.07)
직무 분석
26.4.4. HTML | Beautiful Soup 기초
웹페이지 데이터 분석파트 / Beautiful Soup, HTMl 기초
27.3.3 파이썬 알고리즘 실습 스터디노트1
선형검색, 이진 검색, 순위, 버블정렬, 삽입정렬 실습 문제풀이
28.3.3 파이썬 알고리즘 실습 스터디노트2
선택정렬, 최댓값, 최솟값, 평균 실습 문제풀이
29.3.3 파이썬 알고리즘 실습 스터디노트3
근삿값, 재귀, 병합정렬, 퀵정렬 실습 풀이
30.3.4 알고리즘 문제풀이1_검색, 순위
검색 , 순위 알고리즘 문제
31.4.5 Selenium 기초1
Selenium 개념
32.4.5 Selenium 기초2_데이터 수집
셀프 주유소가 정말 저렴한가?에 대한 EDA 실습
33.6.4 시계열 분석 스터디노트_fbprophet
fbprophet, 함수 기초 (함수 내 return과 print 차이)
34.오답노트 | urllib, regular expression 메타문자
웹데이터 분석 퀴즈 오답노트
35.오답노트 | 객관식 선지로 더 자세하게 알아가기
BeautifulSoup 특징, Selenium driver.page_source, rcParams
36.Matplotlib | legend 배치하기, plt.subplots() 이유
그래프의 legend 배치하기, fig, ax = plt.subplots() 를 사용하는 이유 plt.text(그래프 내 글자), 그래프 컬러
37.Pandas | replace와 str.replace 함수는 다르다
🔑str이 문자로 바꾸는 함수인 줄 알고 왜 이미 type이 object인데 str를 붙이지 했다 ㅋㅋㅋㅋㅋ 아 시원해!
38.HTML | 웹 크롤링 BeautifulSoup와 Requests 무슨 차이야?
웹 크롤링 시 bs와 request 함수와 문법이 어떻게 쓰이는지 헷갈려서 하는 정리
39.HTML | 헷갈렸던 html 요소 불러오는 방법 정리 (select, find)
똑같이 불러오기 기능인데 find / find_all / select . find_element 이 헷갈릴 때
40.iterrows와 enumerate, 비슷해보이는데 언제 써야 할까?
iterrows, enumerate, next, iter, zip
41.SQL 기초 | 개념, table 관리 방법
MYSQL 설치 및 기초
42.Python | itertools 라이브러리
출처\-> 조합형 : 조합, 순열 함수에서 사용함itertools 에 대해 찾아보게 된 코드
43.SQL | 기초 문법2
Logical Operations, UNION, JOIN(INNER, LEFT, RIGHT, SELF), CONCAT, ALIAS, DISTINCT, LIMIT
44.SQL | Primary key, Foreign key
sql 기본 키와 외래 키 정의와 문법, 코드
45.SQL | 집계함수, 스칼라 함수, 서브쿼리
Aggregate fuction, Scalar function, SQL subquery
46.Git | 기본 용어 & 설치 후
버전관리(형상관리) 시스템 중 하나로, 여러 사용자 간의 분산 작업을 가능케하는 분산형 관리 시스템이다.
47.Python | datetime.shrftime, strptime
datetime1 ) 날짜/시간 형식과 문자열 바꾸는 법 : strftime, strptime
48.Python | apply, map, applymap 차이
apply(), map(), applymap() : 각 값에 대응하는 값을 매핑하는데 많이 사용된다. 기능이 비슷하고, 대상의 차이만 있다.
49.EDA 과제1 | 스타벅스와 이디야 매장 위치 비교하기
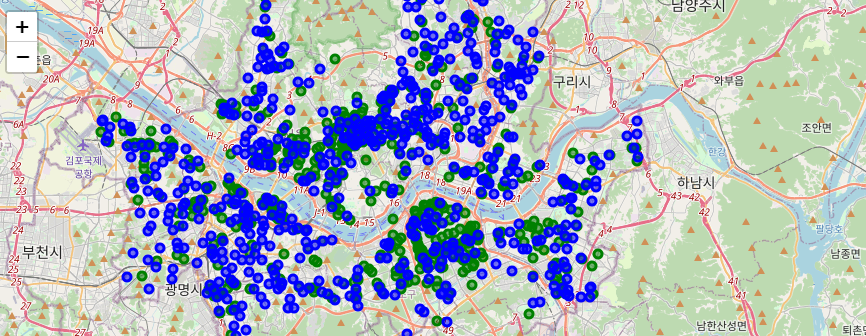
제로베이스 EDA 과제1
50.EDA 과제2 | 셀프 주유소가 정말 저렴한가, 주유소 데이터분석과제
🔎 LEARNING POINT🔎 tqdm.notebook을 활용할 수 있게 됨 웹크롤링으로 다양한 정보를 추출한 경험 python : replace, astype 습득 그래프를 통해 확인하고 싶은 결과값 확인(swarmplot) CSV 내보내기 오늘은 내 풀이와 보완한 풀이를 모두 담아 비교한다. > #### 문...
51.EDA TEST | 서울시 인구 데이터
현재의 컬럼명을 NEW_COLUMS와 같이 변경 current_columns = ['기간', '자치구', '세대', '인구', '인구.1', '인구.2', '인구.3', '인구.4', '인구.5', '인구.6', '인구.7', '인구.8', '세대당인구', '65세이상고령자'] new_columns = ['기간', '자치구', '세대', '합계', '남...
52.EDA TEST | 화장품 성분 데이터 분석
1-1) 성분사전 DataFrame 만들기 ✏️ concat과 merge를 언제 사용해야 하는지 잘 알기. concat은 특정 행을 기준으로 합칠 때 활용 > #### 1-2) 성분사전 DataFrame 내의 Data 수정 hint1: '\r'를 대체 할 때 한글('표준 성분명', '구명칭')의 경우 띄어쓰기가 없고, 영어('표준 영문명', '구영문...
53.EDA TEST | 올림픽 데이터 분석
1-2) Preprocessing: missing data 처리 조건1: missing data가 있다면, 해당 row(행)를 삭제(drop)하세요 조건2: Index를 초기화(reset)하고, 기존 Index는 삭제(drop)하세요. 1) 2) > #### 1-3) Preprocessing: Data Type 정리 조건1: float data는 ...
54.보충 | None과 np.NaN 차이 / any() 와 all() 구분하기
🤔 결측치를 표현할 때 None과 NaN이 있다. 문제를 풀면서 둘의 차이를 모른다는 것을 깨달았다. /🤔 어떤 함수인지 알겠는데 헷갈려
55.보충 | pivot과 pivot_table, groupby의 차이
Pivot (피벗 전환) 정의 : 테이블 재배치(구조 변경) 여러 컬럼을 index, values, columns로 사용할 수 있다. set_index로 계층적 색인 생성 후, unstack 매서드로 형태를 변환하는 과정의 축약형 문법 : DataFrame.pivot(index=None, columns=None, values=None) index : 인...
56.전처리 | 이름 바꿀 때 <rename 함수>, 띄어쓰기 제거에는 <replace 함수>
rename, reset_index, replace, split, duplicated, drop_duplicates
57.ML | Pipeline 개념 정리
머신러닝 코드 길이를 단축해줄 pipeline 과 파라미터 파기, kwarg와 arg란
58.ML | 그래프 그릴 때 뭐 써야해? Matplotlib VS Seaborn VS Plotly
plotly 개념 및 타 그래프 생성 모듈과 비교
59.Python | 비교 연산자 함수로 쓰기(eq, ne, lt, gt, le, ge)
이항 비교 메서드(binary comparision method)란? eq, ne, lt, gt, le, ge 함수 살펴보기
60.ML | sklearn.preprocessing 스케일링 함수
Standard Scaler, MinMax Scaler, Robust Scaler, LabelEncoder
61.Python | 유용한 Zip 함수
zip 함수란? 특징으로 병렬처리, 사전만들기가 쉽다.
62.Python | join 함수로 문자열 합치기
join 함수는 매개변수로 들어온 리스트에 있는 요소를 모두 합쳐 하나의 문자열로 반환한다.
63.Python | 자료구조 deque 데크 정의, stack queue 함수
deque, stack, queue 정의와 문법 파헤치기
64.통계 | 기초, z분포, 베이즈정의, 포아송분포, t분포 개념모음
정의 요소(elements) : 수집되는 대상 변수(variable) : 요소의 특성 관찰값(observation) : 특정 요소의 수집된 측정치의 집합 자료 집합 : 자료값 총수 = 요소의 수 X 변수의 수 측정 척도 : 명목 / 등간 / 서열 / 비율 분류 : 질적 자료(범주형) / 양적 자료(수치형) -질적자료 : 명목, 서열 척도 중의 하나, ...
65.통계 | 이산형확률분포 종류와 기초
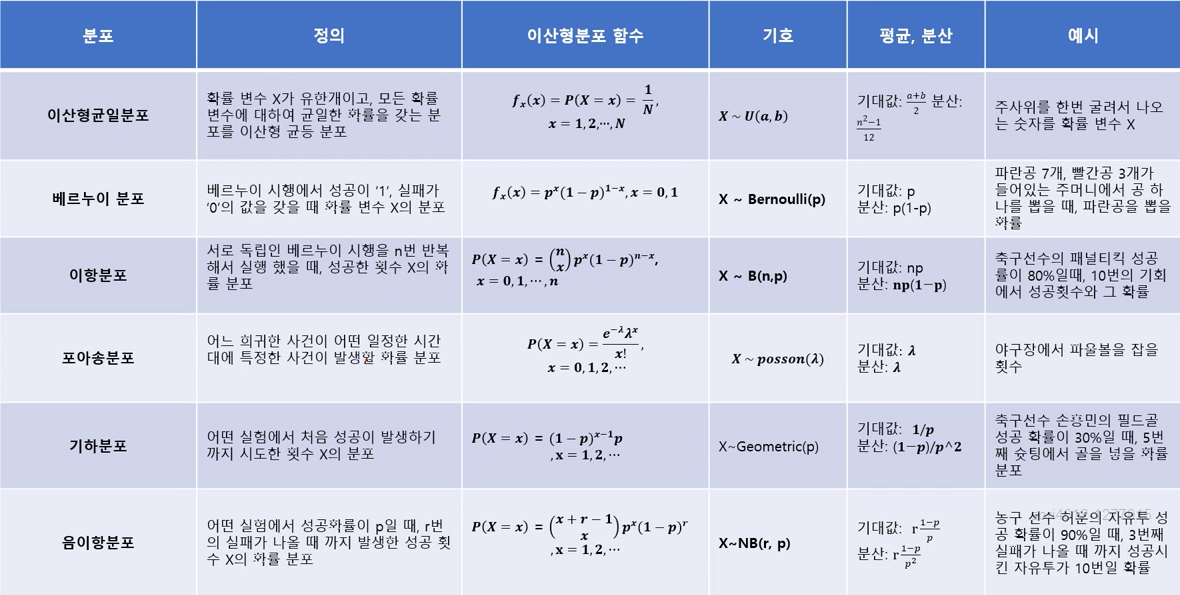
이산형 균등분포, 베르누이 분포, 포아송 분포, 기하분포, 이항 분포, 음이항 분포
66.통계 | 연속형확률분포 종류와 기초
확률밀도분포, 정규분포, 표준정규분포, 누적분포, 균일분포
67.통계 | F분포, ANOVA 일원분산분석
F분포 F값의 확률분포 정규분포를 이루는 모집단에서 독립적으로 추출한 표본들의 분산비율이 나타내는 연속 확률 분포 ✅ F분포 = 집단 간 분포 / 집단 내 분포 집단 간 분포가 클 수록, 집단 내 분포가 작을 수록(F분포 값이 커질수록) 집단 평균이 다를 가능성이 증가한다. > ### one-way ANOVA 일원분산분석 : 집단을 구분하는 독립 ...
68.ML 프로젝트 | 자료가 너무 적으면 어떡하나 (2주차)

이전까지 진행사항 : understat 모듈을 사용해서 진행하기로 결정 이번 주에 주제와 데이터를 선정하면서 한 가지 놓친 부분을 깨달았다. 바로 최대로 구할 수 있는 데이터 양이 얼마인지 확인하지 않은 것 > 문제사항 : 한 시즌 한 프로축구 팀 경기 정보만으로는 데이터 수가 현저히 적어서 진행할 수 없었다. 최대 38경기 수집 가능 이에 대한 내용...
69.ML 프로젝트 | 자료 수집하고 엎기를 반복 (3주차)
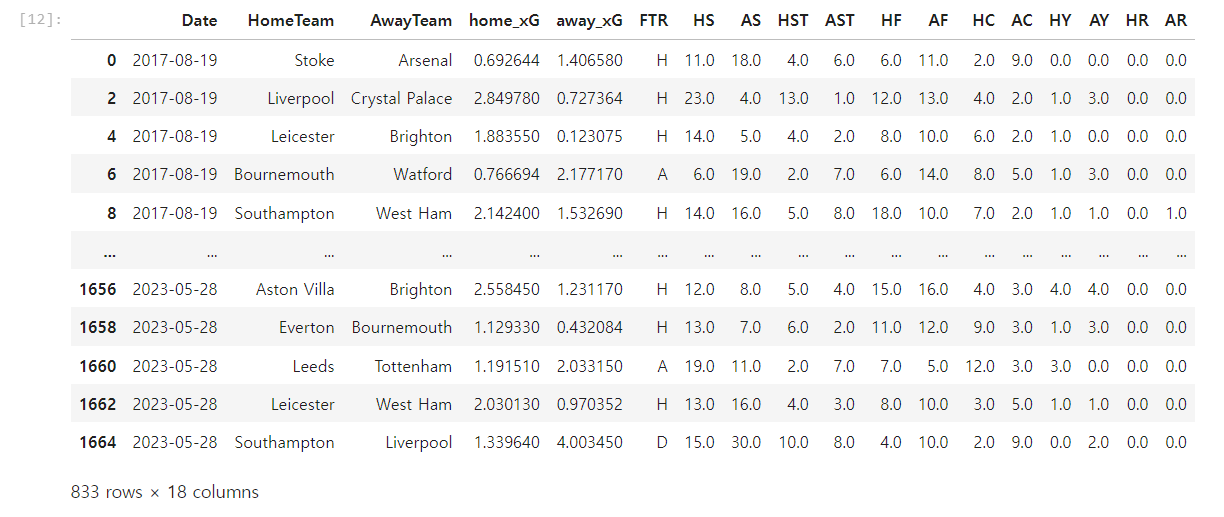
진행사항 : 데이터 양을 늘리기 위해 데이터를 추가로 스크랩했다. 앞서 말했듯이 생각하지 못했던 게 2280개로 이미 경기 수가 제한된 상황에서 추가 데이터를 수집하는 것은 그저 다양성을 더 가져오는 것에 불과하다는 것. 예측을 높이기 위해서 중요도가 적은 열을 삭제하는데, 우리는 오히려 반대로 가고 있었다. 다만 현재 데이터에 만족하지 않고 더 좋은 ...
70.ML TEST | 야구 선수 연봉 예측
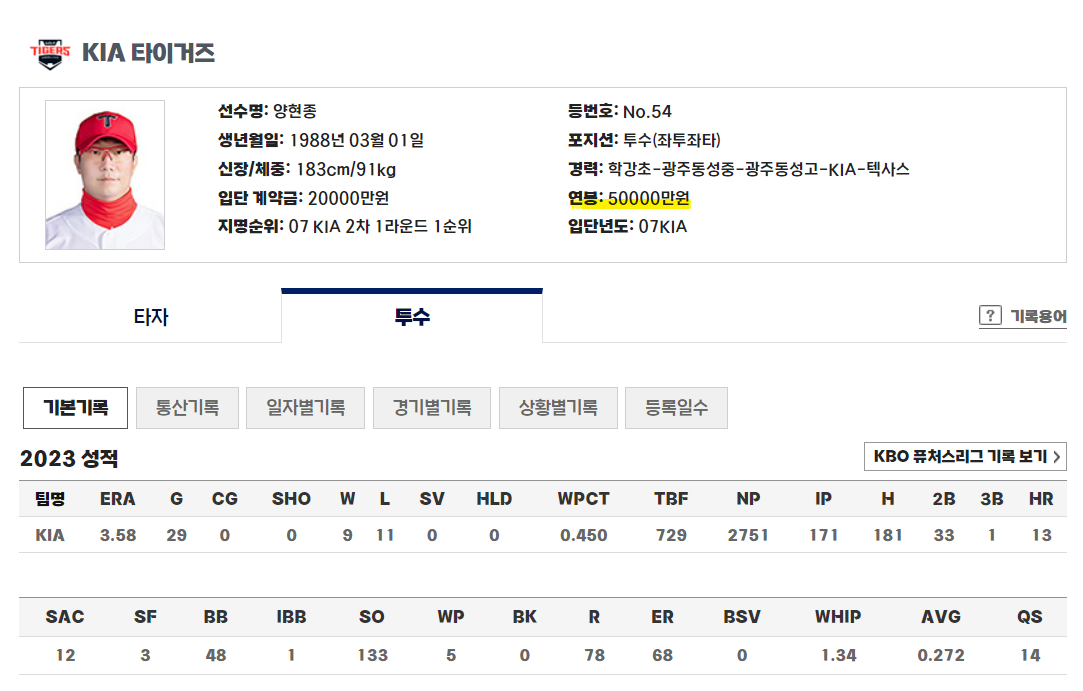
(문제) 최동원 선수의 2010년대 연봉을 예측하라 KBO 기록실에서 데이터를 수집하기로 했다. ✅ 해당 사이트에서 데이터를 다운받을 수 있는 방법이 없어서 웹크롤링을 하기로 결정 ✅ 1980년대와 2010년대 데이터의 열이 달라서 따로 수집 ✅ 사이트의 문제인지 모르겠지만, 웹크롤링 과정에서 데이터가 잘 수집되지 않는 문제가 발생(연도마다 선수 수가 ...
71.딥러닝 | 인공지능, 머신러닝, 딥러닝 개념과 차이
Artificail intelligence : 컴퓨터가 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술 . . > ### Machine Learning : 기계학습, 컴퓨터가 주어진 데이터를 이용해 스스로 학습, 자동으로 데이터에서 규칙을 학
72.딥러닝 | 퍼셉트론 & XOR 문제
다층 퍼셉트론은 왜 필요했을까? 인공신경망에 대해서 좀더 알아보기, 활성화함수, 계층의 종류
73.tensorflow | 기초 문법
기초 문법의 모든 것
74.딥러닝 | hugging face & 자연어 처리
Transformer 모델은 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망이다. > ### Hugging Face는 다양한 트랜스포머 모델과 학습 스크립트를 제공하는 모듈 이미지출처 > ## 사용 방법 🔎 파이프라인에서 3단계가 내부에서 실행 Proprecessing 텍스트는 모델이 이해할 수 있는 형식으로 ...
75.딥러닝 | 컴퓨티 비전 시작하기
컴퓨터 비전이란? 영상 데이터 기초 및 주요 모듈
76.딥러닝 | tf.keras 주요 모듈 정리
tf.keras 특징, 모듈(layers, datasets, Sequencial, optimizer) & Tensorflow 2.0.0 버전 후 변경된 부분 (eval, session 등)
77.딥러닝 | 신경망개념 CNN, RNN, LSTM, GPU
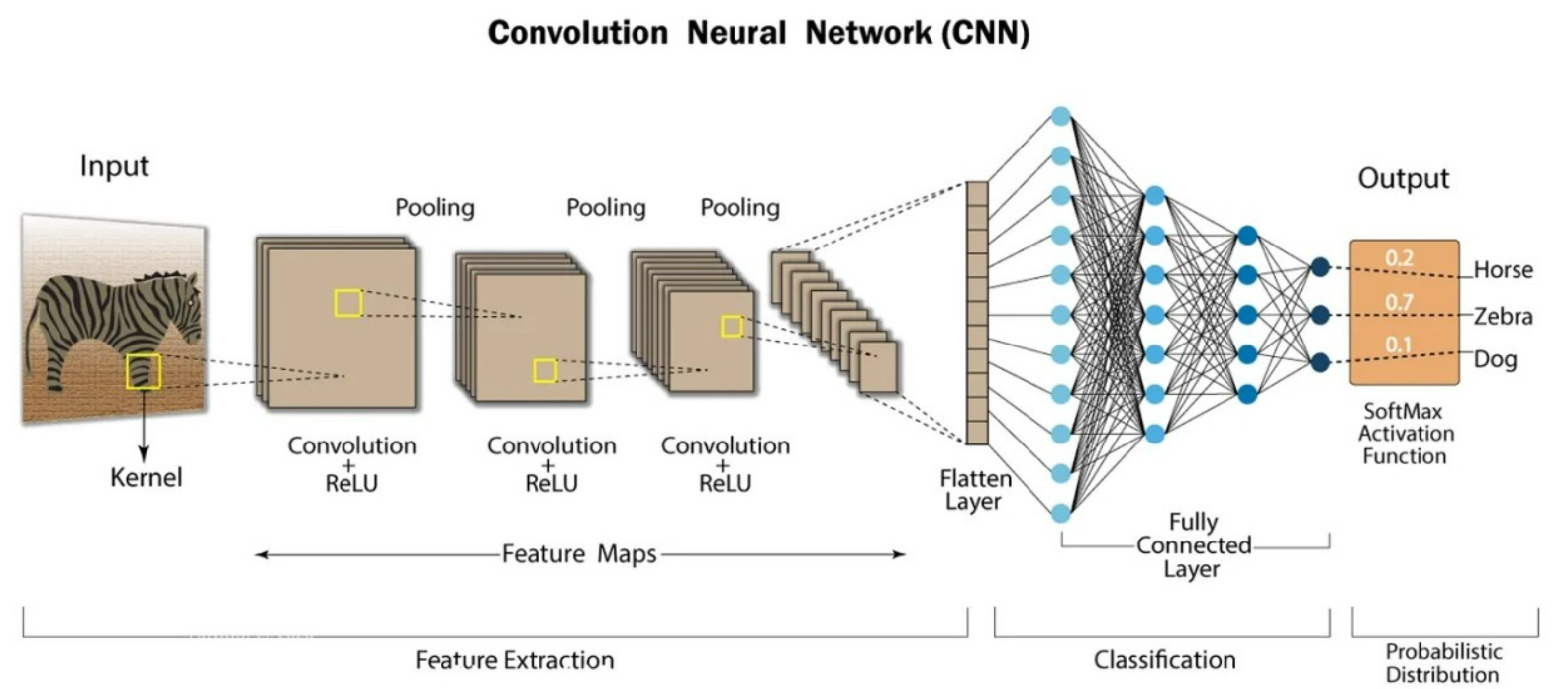
CNN (컨볼루션/합성곱 신경망) 이미지 인식에 주로 사용되는, 합성곱층(컨볼루션 층)과 풀링층으로 이루어져 있는 특징을 가진 딥러닝 아키텍처 시각 피질 뉴런으로부터 힌트를 얻음 구조 Input Layer - 합성곱층 - 풀링층 - FNL - Output Layer 1) 합성곱층 : 여러 필터(kernal)을 사용해 합성곱을 수행하고 특징 맵을 생성한다...
78.딥러닝 | 신경망 개념 오토인코더, 강화학습
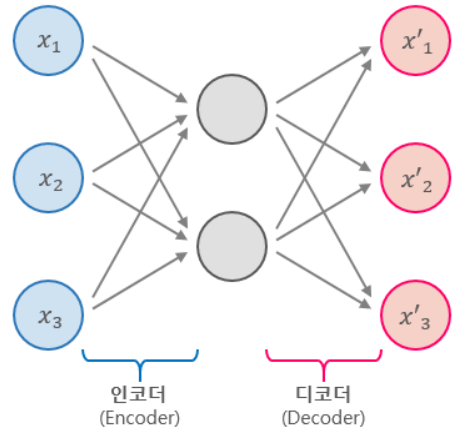
Auto Encoder : 데이터의 효율적인 표현을 학습하는 인공신경망 모델 데이터를 압축해 중요한 특성을 찾아내고 다시 복원하는 과정을 거친다. 그래서 input와 output이 거의 동일하다. 오토인코더는 크게 두 부분으로 구성되어있다. Encoder 입력 데이터를 받아 작은 차원으로 압축한다. 이 때 압축한 표현을 Coding 혹은 잠재공간(lat...
79.EDA | 인터파크 주말 영화 웹크롤링
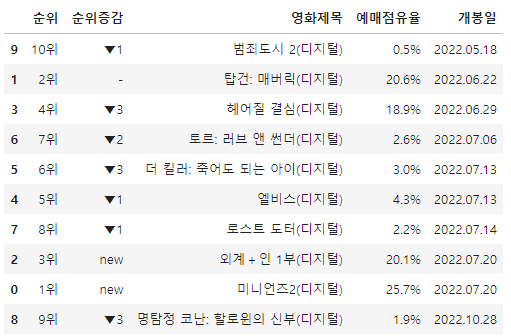
문제1 : 인터파크 영화 랭킹리포트 2022년 7월 21일(목) ~ 7월 24일 (일) 기준 영화 Top10의 1위 ~ 10위에 해당하는 영화의 순위 / 순위증감 / 영화 제목 / 예매점유율 / 개봉일 데이터 크롤링 🤔 영화를 클릭할 때 나는 option:nth-child(76) CSS selector를 사용했는데, 이게 최신일 수록 낮은 숫자여서 계...
80.Python | *args 와 **kwargs 란
: Positional Argument (포지셔널 아규먼트)함수에 정의한 순서대로 인자를 보내는 방법으로, 인수의 순서를 지켜야 한다.: keyword Argument인수를 전달할 때 매개변수명을 명시하는 방법으로, 순서가 바뀌어도 상관없다.인수를 받을 때 인수의 개수
81.EDA | 서울시 지하철 호선별 유무임 승하차 데이터 분석
1번 중복 제거 조건1 : 각 Row(행) 중 내용이 모두 똑같은(중복되는) Row(행)이 있다면 가장 앞의 Row(Index가 가장 낮은 Row(행))는 남기고 나머지 중복되는 Row(행)를 삭제 조건2 : 각 Row(행) 중 ['사용월', '호선명', '지
82.EDA | 서울시 교통사고 사고유형별 통계
1단계 데이터 프레임 수정 조건1: ['자치구별(1)', '사고유형별(2)'] Column(열)을 삭제 조건2: ['자치구별(2)', '사고유형별(1)'] Column(열)명 변경 '자치구별(2)' -> '자치구' '사고유형별(1)' -> '사고유형' '구분별(1)' -> '구분' 조건3: '구분' Colum...
83.ML 프로젝트 | 예측하기 (4주차)
진행사항 : 어떤 데이터를 쓸 것인지 정했다. 이제 23년도 경기를 예측해보자 지금까지 정리한 데이터 원본 가져 오기 훈련데이터, 실험데이터 나누기 범주형 수치 전처리 : one hot encoding ` 🔎 데이터는 onehotencoding을 진행한 이유
84.ML | Optuna : 하이퍼파라미터 최적화 라이브러리
하이퍼파라미터 최적화 예시코드 및 설명