- 알고리즘 : 문제를 풀어내기 위한 공식화된 형태의 절차나 방법
선형검색
: 선형으로 나열되어 있는 데이터를 순차적으로 스캔해서 원하는 값을 찾는다.
방법
1. 리스트의 첫 번째 요소와 원하는 요소를 검사하여 찾으려는 값을 비교
2. 원하는 요소가 찾으려는 값과 일치하지 않으면 다음 데이터로 이동하고 다시 비교
3. 탐색 중간에 일치하는 값을 찾지 못하면 리스트 끝까지 검색
4. 검색이 끝나면 검색 결과를 반환, 찾으려는 값이 없으면 종료 후 "값을 찾을 수 없음(-1)"을 나타내는 특별한 값을 반환할 수 있음
- 보초법 : 리스트 마지막에 원하는 값을 추가한 뒤 검색하여 리스트 길이 이전 위치에서 찾으면 리스트는 원하는 값을 가지고 있는 것, 리스트 마지막 인덱스 위치가 나오면 검색결과가 없음을 알 수 있다.
이진검색
: 정렬되어 있는 자료구조에서 중앙값과 크고 작음을 이용해서 데이터를 검색한다.
방법
1. 자료구조에서 중앙값 탐색
2. 중앙값과 찾고자 하는 값을 비교
3. 찾으려는 값이 중앙값과 같다면 탐색 종료 후 인덱스 반환
4. 찾으려하는 값이 중앙값보다 작다면 검색 범위를 중앙값보다 작은 범위로 축소 (중앙값이 제일 큰 값으로 변경)
중앙값보다 크다면 검색범위를 중앙값의 큰 범위로 축소(중앙값이 제일 작은 값으로 변경)
5. 새로운 범위에서 중앙값을 다시 탐색
6. 이런 과정을 원하는 항목을 찾거나 검색 범위가 더 이상 줄어들지 않을 때까지 반복
순위
: 수의 크고 작음을 이용해 수의 순서를 정하는 것
방법
1. 오름차순으로 자료구조를 정렬
2. 동일한 크기의 리스트나 자료구조 생성 (카피리스트라 칭하겠음)
3. 첫 번째 값이 기준, 두 번째 값을 비교해서 작은 값의 카피리스트의 동일한 인덱스 번호를 가진 위치에 +1
4. 첫 번째 값 기준 자료 리스트 끝까지 비교하여 작은 수의 카피리스트 인덱스는 1을 누적
5. 한 회차를 돌았다면 두 번째 값도 위와 동일한 방식으로 비교하며 진행하며 카피리스트 값은 누적됨
import random
nums = random.sample(range(50, 101), 20)
ranks = [0 for i in range(20)] #아이템의 값이 0인 길이 20짜리 리스트
print(f'nums: {nums}')
print(f'ranks : {ranks}')
for idx, num1 in enumerate(nums):
for num2 in nums:
if num1 < num2:
ranks[idx] += 1
print(f'nums: {nums}')
print(f'ranks : {ranks}')
for i, m in enumerate(nums): #보기 편하게 정렬시키는 방법
print(f'nums: {m} \t rank: {ranks[i] + 1}')버블정렬
: 처음부터 끝까지 인접하는 인덱스 값을 순차적으로 비교하면서 큰 숫자를 가장 끝으로 옮기는 알고리즘
방법
- 첫 번째 아이템부터 시작하여 인접한 두 아이템을 비교
- 큰 아이템이 작은 아이템보다 앞에 있다면, 두 원소의 위치 교환
- 위 과정을 반복해 가장 큰 아이템이 리스트의 맨 끝으로 이동
- 위 과정이 마무리 되면 다음 번(2번째) 아이템도 끝에서 하나씩 줄여가며 같은 과정을 반복
- 이러한 과정을 모든 원소가 정렬될 때까지 반복
nums = [10, 2, 7, 21, 0]
print(f'not sorted nums : {nums}')
length = len(nums) - 1
for i in range(length) - 1:
for j in range(length - 1):
if num[j] > nums[j+1]:
temp = nums[j] #자리바꿈 과정
nums[j] = nums[j+1]
num[j+1] = temp
#자리바꿈 동일한 과정
num[j], num[j+1] = num[j+1], num[j]
print(f'sorted nums: {nums}')
삽입 정렬
: 정렬되어 있는 자료 배열과 비교해서 정렬 위치를 찾는다.
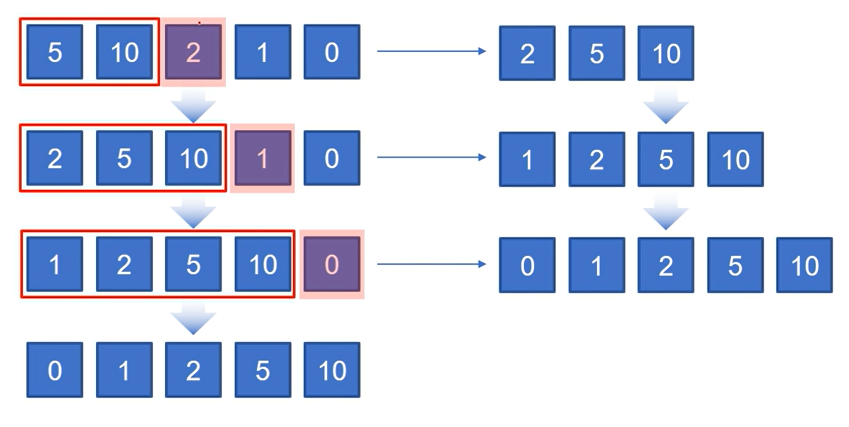
nums = [5, 10, 2, 1, 0] #len(nums) = 5
for i1 in range(1, len(nums)):
i2 = i1 - 1 #i1보다 앞
cNum = nums[i1]
while nums[i2] > cNum and i2 >= 0:
nums[i2 + 1] = nums[i2] #i2 +1 을 그냥 i1이라 해도 됨
i2 -= 1 #while문이 계속 돌아가기 위해서
nums[i2 + 1] = cNum
print(f'nums:{nums}')[Output]
선택 정렬
: 주어진 리스트 중에 1) 최소값을 찾아, 그 값을 맨 앞에 위치한 값과 2) 교체하는 방식으로 자료를 정렬하는 알고리즘이다.
nums = [4, 2, 5, 1, 3]
for i in range(len(nums) - 1): #맨 마지막은 할 필요 없어서 - 1
minIdx = i
for j in range(i + 1, len(nums));
if nums[minIdx] > nums[j]:
minIdx = j #여기서 가장 작은 값을 찾게 됨
tempNum = nums[i] #찾은 가장 작은 값과 맨 앞에 기준이 되었던 값이 교환
nums[i] = nums[minIdx]
nums[minIdx] = tempNum
#한 줄로 만들기
nums[i], nums[minIdx] = nums[minIdx],nums[i]
print(f'nums: {nums})최댓값 : 가장 큰 값
class MaxAlgorithm:
def __init__(self, ns):
self.nums = ns
self.maxNum = 0
def getMaxnums(self):
self.maxNum = self.nums[0]
for n in self.nums:
if self.maxNum < n :
self.maxNum = m
return self.maxNum
ma = MaxAlgorithm([-2, -4, 5, 7, 10, 0, 8, 20, -11]
maxNum = ma.GetMaxNum()
print(f'maxNum : {maxNum}')최솟값 : 가장 작은 값
class MinAlgorirthm: #쉬운 버전이라 함수로 만들어도 무방
def __init__(self, ns):
self.nums = ns
self.minNum = 0
def getMinNum(self):
self.minNum = self.nums[0]
for n in self.nums:
if self.minNum > n:
self.minNum = n
return self.minNum
ma = MinAlgorithm([-2, -4, 5, 7, 10, 0, 8, 20, -11]
minNum = ma.GetMinNum()
print(f'minNum : {minNum}')최빈값 : 가장 많은 데이터
방법
1. 리스트(크기 : 17)의 가장 큰 값(최댓값) 서칭
2. 위에서 구한 최댓값(+1)만큼의 빈 배열 리스트 생성 (초기값: [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] 인덱스 18개)
3. 기존 데이터의 값을 인덱스로 인식하여 빈 배열 리스트에 인덱스 값에 +1 씩 추가
4. 리스트에서 1이 누적된 값중 가장 큰 값을 다시 최댓값 알고리즘을 이용하여 기존 리스트에서 최빈값 확인
근삿값 : 특정 값에 가장 가까운 값
import random
nums = random.sample(range(0, 50), 20)
print(f'nums: {nums}')
inputNum = int(input('input number : '))
print(f'inputNum : {inputNum}')
nearNum = 0
minNum = 50
for n in nums:
absNum = abs(n - inputNum)
if absNum < minNum:
minNum = absNum
nearNum = n
print(f'{nearNum}')평균 : 여러 수나 양의 중간 값을 갖는 수
import random
nums = random.sample(range(1,100),50)
total = 0
targetNums = []
for n in nums:
if n > 50 and n < 100:
total += n
targetNums.append(n)
average = total / len(targetNums)
print(f'targetNums:{targetNums}')
print(f'average: {round(average,2)}')재귀 : 나 자신을 다시 호출하는 것
-장점 : 간결하고 효율적으로 코드를 만들어낼 수 있음
1) 반복문을 이용하지 않고 재귀함수를 사용하는 방법
def recusion(num):
if num > 0:
print('*'*num)
return recusion(num - 1)
else:
return 1
recusion(10)
[Output]
*********
********
*******
******
*****
****
***
**
*
2) 팩토리얼도 재귀 예제로 많이 나옴
def facorial(num):
if num > 0:
return num * factorial(num -1)
else:
return 1
print(f'factorial(10): {factorial(10)}')3) 재귀로 최대공약수 구하기
def gcd(n1,n2):
if n1 % n2 == 0:
return n2
else:
return gcd(n2, n1 % n2)
print(f'gcd(82,32):{gcd(82,32)}')- 하노이의 탑(실습)
def moveDisc(discCnt, fromBar, toBar, viaBar):
#원판 개수, 출발기둥, 도착기둥, 경유기둥
if discCnt == 1::
print(f'{discCnt}disc를 {fromBar}에서 {toBar}로 이동')
else:
#(discCnt-1)개들을 경유 기둥으로 이동
moveDisc(discCnt - 1, fromBar, viaBar, toBar) #재귀함수
#discCnt 목적 기둥으로 이동
print(f'{discCnt}disc를 {fromBar}에서 {toBar}로 이동')
#(discCnt-1)개들을 도착 기둥으로 이동
moveDisc(discCnt - 1, viaBar, toBar, fromBar)
moveDisc(3, 1, 3, 2)
병합 정렬
: 자료 구조를 분할하고 각각의 분할된 자료 구조를 정렬한 후 다시 병합하여 정렬한다.
분할 단계 ▷ 병합 단계(하나씩 데이터를 비교해가면서)
def mSort(ns):
if len(ns) < 2:
return ns
midIdx = len(ns) // 2
leftNums = mSort(ns[0:midIdx])
rightNums = mSort(ns[midIdx:len(ns)]) #여기까지 분할단계
mergeNums = [] #병합하니까~
leftIdx = 0; rightIdx = 0
while leftIdx < len(leftNums) and rightIdx < len(rightNums):
if leftNums[leftIdx] < rightNums[rightIdx]:
mergeNums.append(leftNums[leftIdx])
leftIdx += 1
else:
mergeNums.append(rightNums[rightIdx])
rightIdx += 1
mergeNums += leftNums[leftIdx:]
mergeNums += rightNums[rightIdx:]
return mergeNums
nums = [8, 1, 4, 3, 2, 5, 10, 6]
print(f'mSort(nums): {mSort(nums)}')
퀵 정렬
: 기준 값보다 작은 값과 큰 값으로 분리한 후 다시 합친다.
def qSort(ns):
if len(ns) < 2:
return ns
midIdx = len(ns)) // 2
midVal = ns[midIdx]
smallNums = []; sameNums = []; bigNums = []
for n in ns:
if n < midVal:
smallNums.append(n)
elif n == midVal:
sameNums.append(n)
else:
bigNums.append(n)
return qSort(smallNums) + sameNums + qSort(bigNums)
nums = [8, 1, 4, 3, 2, 5, 4, 10, 6, 8]
print(f'qSort(nums) : {qSort}')
