Pipeline 이란?
- 데이터 사전 처리 및 분류, 모델학습 분석 및 배포 모든 단계를 포함하는 단일 개체를 만들 수 있는 방법으로 코드가 간결해진다.

사용방법
pipeline([('작업명1', 작업 클래스1), ('작업명2', 작업클래스2), ...])from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn/preprocessing import StandardScaler
xtrain, xtest, ytrain, ytest = train_test_split(df, target, test_size = 0.2, random_state = 123)
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier()))]
pipe = PipeLine(estimators)
pipe.fit(xtrain, ytrain)
pipe.score(xtest, ytest)🔎 분할 전까지는 코드가 같으나 데이터 전처리 및 모델 학습, 예측 과정을 파이프라인으로 해결
✏️ 머신러닝이나 sklearn 라이브러리에서 보이는 clf는 classifier를 의미하는 것
파라미터 접근
pipeline.steps를 사용하면 적용한 step 즉 단계를 보여준다.

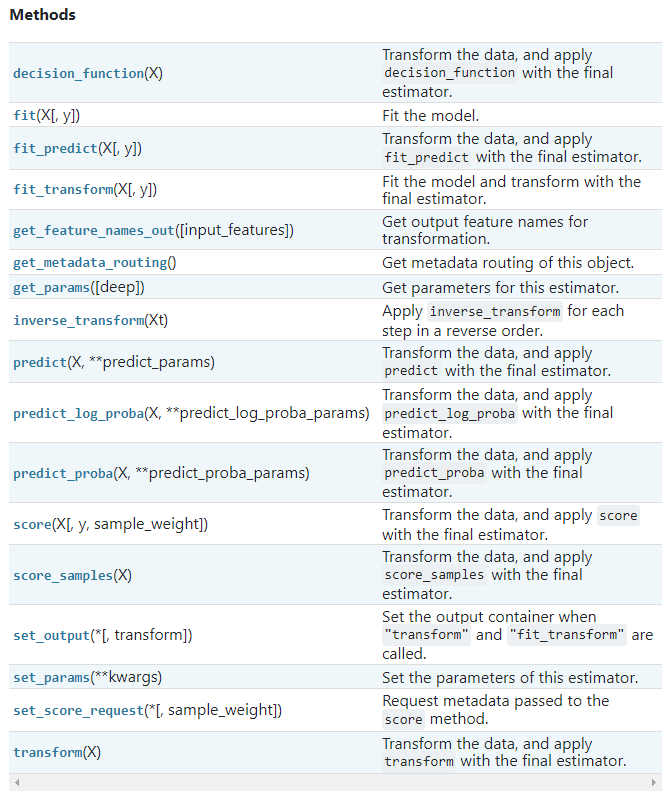
.
.
.
-
set_params(**kwargs): 매개변수 설정
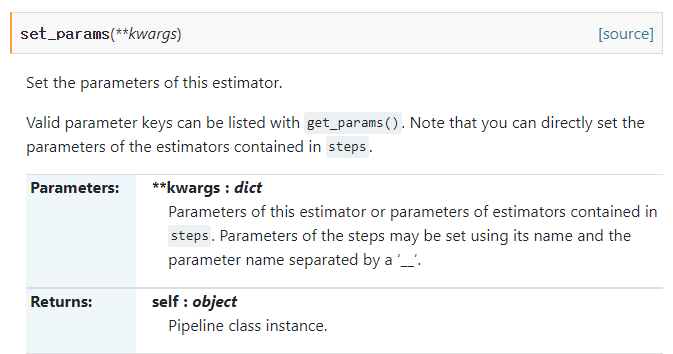

-
get_params(): 추정기에 대한 매개변수 가져옴

-
get_feature_names_out(): 변환을 위한 feature name을 출력하며 str을 return 한다.
🔎 **kwargs는 keyword arguments를 의미한다.
(키워드 = 특정 값) 형태로 함수를 호출할 수 있다. 그러면 딕셔너리 형태로 {'키워드' : '특정값'} 형태로 함수 내부로 전달된다.
🔎 *args는 arguments, 연속되는 positional arguments
*args는 일반 변수보다 뒤에 있어야 하며 반드시 **kwargs보다 먼저 쓰여야 한다. keyword argument 전까지 args가 tuple 형식으로 가져가고, 이어 오는 keyword argument는 dictionary 형태로 가져간다.
🔎 best_params_ 최고의 점수를 낸 파라미터
🔎 best_estimator_ 최고의 점수를 낸 파라미터를 가진 모형

데이터로 경로를 탐색합니다.