(문제) 최동원 선수의 2010년대 연봉을 예측하라
KBO 기록실에서 데이터를 수집하기로 했다.
import pandas as pd
import numpy as np
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC✅ 해당 사이트에서 데이터를 다운받을 수 있는 방법이 없어서 웹크롤링을 하기로 결정
✅ 1980년대와 2010년대 데이터의 열이 달라서 따로 수집
✅ 사이트의 문제인지 모르겠지만, 웹크롤링 과정에서 데이터가 잘 수집되지 않는 문제가 발생(연도마다 선수 수가 다른데, 1983년 자료에 1982년 선수 데이터가 수집되는 문제가 발생, 해결하려고 거의 2일을 쓴 듯)
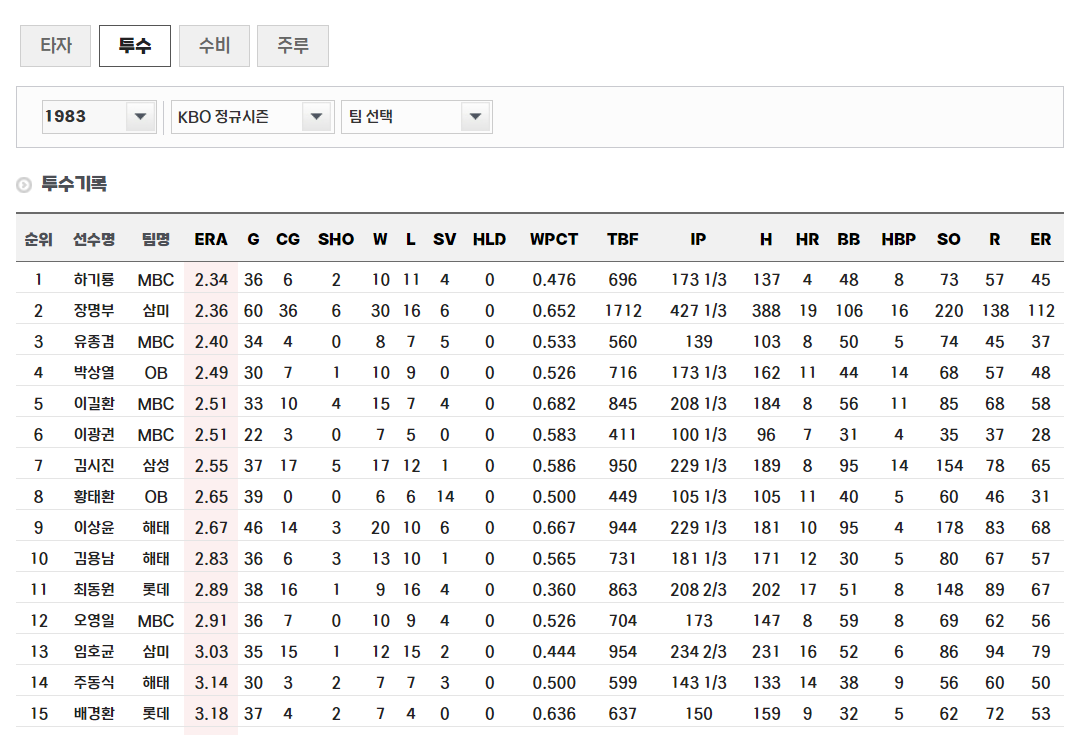
1983-1988년 데이터 수집
#데이터 적재
name = []; team = []; ERA = []; G = []; CG = []; SHO = []; W = []; L = []; year= [];5
SV = []; HLD = []; WPCT = []; TBF = []; IP = []; H = []; HR = []; BB = []; HBP = []; SO = []; R = []; ER = []
# 1983-1988년 수집
for season_index in range(2, 9):
# 시즌 선택
btn = driver.find_element(By.CSS_SELECTOR, f"#cphContents_cphContents_cphContents_ddlSeason_ddlSeason > option:nth-child({season_index})")
btn.click()
# 팀 정보 요소의 ID를 사용하여 대기
element_id = "cphContents_cphContents_cphContents_ddlSeason_ddlSeason"
# 대기 조건을 해당 요소의 존재로 변경
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, element_id)))
# 선택한 시즌의 데이터 수집
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
length = len(soup.select('#cphContents_cphContents_cphContents_udpContent > div.record_result > table > tbody > tr')) + 1
for i in range(1, length):
get_source = soup.select('#cphContents_cphContents_cphContents_udpContent > div.record_result > table > tbody > tr:nth-child(' + str(i) + ')')
# 이름 수집 파트
name_element = get_source[0].select_one('td:nth-child(2) a').get_text(strip=True)
name.append(name_element)
# 팀 수집 파트
team_element = get_source[0].select_one('td:nth-child(3)').get_text(strip=True)
team.append(team_element)
#ERA
era_element = get_source[0].select_one('td.asc').get_text()
ERA.append(era_element)
g_element = get_source[0].select_one('td:nth-child(5)').get_text()
G.append(g_element)
cg_element = get_source[0].select_one('td:nth-child(6)').get_text()
CG.append(cg_element)
sho_element = get_source[0].select_one('td:nth-child(7)').get_text()
SHO.append(sho_element)
w_element = get_source[0].select_one('td:nth-child(8)').get_text()
W.append(w_element)
l_element = get_source[0].select_one('td:nth-child(9)').get_text()
L.append(l_element)
sv_element = get_source[0].select_one('td:nth-child(10)').get_text()
SV.append(sv_element)
hld_element = get_source[0].select_one('td:nth-child(11)').get_text()
HLD.append(hld_element)
wpct_element = get_source[0].select_one('td:nth-child(12)').get_text()
WPCT.append(wpct_element)
tbf_element = get_source[0].select_one('td:nth-child(13)').get_text()
TBF.append(tbf_element)
ip_element = get_source[0].select_one('td:nth-child(14)').get_text()
IP.append(ip_element)
h_element = get_source[0].select_one('td:nth-child(15)').get_text()
H.append(h_element)
hr_element = get_source[0].select_one('td:nth-child(16)').get_text()
HR.append(hr_element)
bb_element = get_source[0].select_one('td:nth-child(17)').get_text()
BB.append(bb_element)
hbp_element = get_source[0].select_one('td:nth-child(18)').get_text()
HBP.append(hbp_element)
so_element = get_source[0].select_one('td:nth-child(19)').get_text()
SO.append(so_element)
r_element = get_source[0].select_one('td:nth-child(20)').get_text()
R.append(r_element)
er_element = get_source[0].select_one('td:nth-child(21)').get_text()
ER.append(er_element)
year_element = 1983 + season_index - 3
year.append(year_element)
pd.set_option('display.max_columns', None)
df_pitcher = pd.DataFrame(
{'name' : name,
'team' : team,
'ERA' : ERA,
'G' : G,
'CG' : CG,
'SHO' : SHO,
'W' : W,
'L' : L,
'SV' : SV,
'HLD' : HLD,
'WPCT' : WPCT,
'TBF' : TBF,
'IP' : IP,
'H' : H,
'HR' : HR,
'BB' : BB,
'HBP' : HBP,
'SO' : SO,
'R' : R,
'ER' : ER,
'year' : year})
df_pitcher(페디는 2022년 선수인데 페이지 문제로 1982년에 수집, 하지만 1982년은 수집 대상이 아니라서 삭제예정)
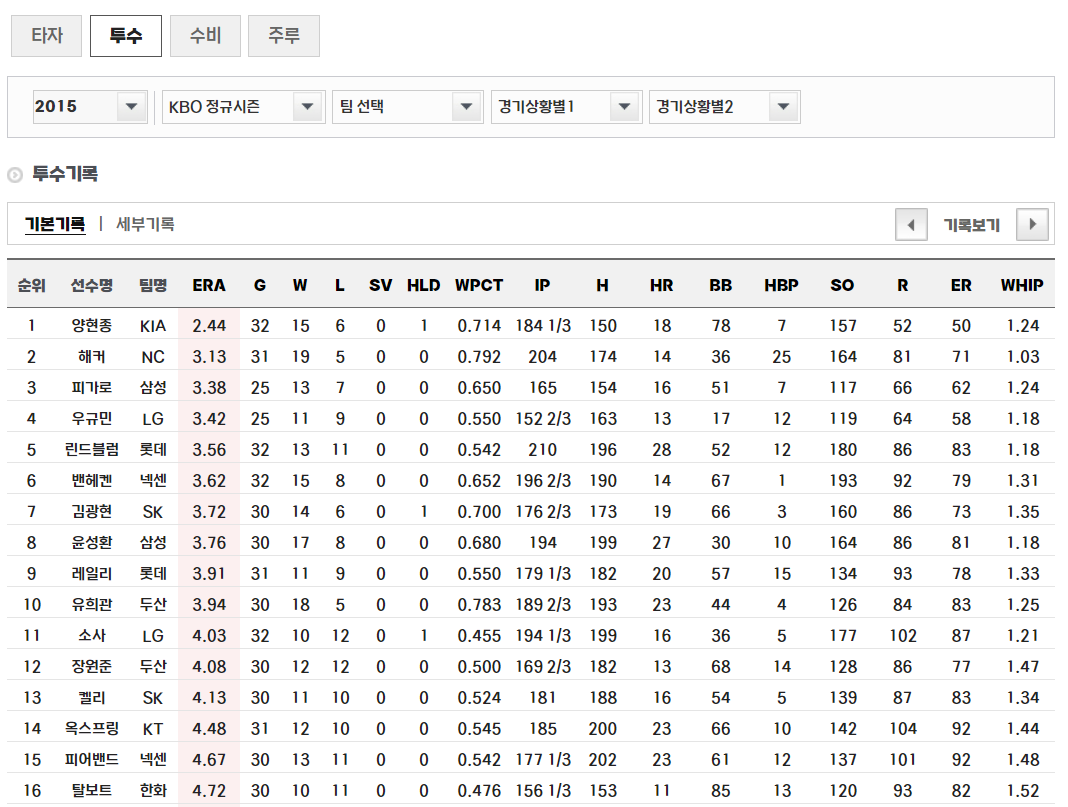
2015-2020년 데이터 수집
#2015-2020 크롤링
#데이터 적재
name = []; team = []; ERA = []; G = []; CG = []; SHO = []; W = []; L = []; year= []; WHIP=[];
SV = []; HLD = []; WPCT = []; TBF = []; IP = []; H = []; HR = []; BB = []; HBP = []; SO = []; R = []; ER = []
for season_index in range(34, 42):
# 시즌 선택
btn = driver.find_element(By.CSS_SELECTOR, f"#cphContents_cphContents_cphContents_ddlSeason_ddlSeason > option:nth-child({season_index})")
btn.click()
# 팀 정보 요소의 ID를 사용하여 대기
element_id = "cphContents_cphContents_cphContents_ddlSeason_ddlSeason"
# 대기 조건을 해당 요소의 존재로 변경
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, element_id)))
# 선택한 시즌의 데이터 수집
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
length = len(soup.select('#cphContents_cphContents_cphContents_udpContent > div.record_result > table > tbody > tr')) + 1
for i in range(1, length):
get_source = soup.select('#cphContents_cphContents_cphContents_udpContent > div.record_result > table > tbody > tr:nth-child(' + str(i) + ')')
# 이름 수집 파트
name_element = get_source[0].select_one('td:nth-child(2) a').get_text(strip=True)
name.append(name_element)
# 팀 수집 파트
team_element = get_source[0].select_one('td:nth-child(3)').get_text(strip=True)
team.append(team_element)
#ERA
era_element = get_source[0].select_one('td.asc').get_text()
ERA.append(era_element)
g_element = get_source[0].select_one('td:nth-child(5)').get_text()
G.append(g_element)
w_element = get_source[0].select_one('td:nth-child(6)').get_text()
W.append(w_element)
l_element = get_source[0].select_one('td:nth-child(7)').get_text()
L.append(l_element)
sv_element = get_source[0].select_one('td:nth-child(8)').get_text()
SV.append(sv_element)
hld_element = get_source[0].select_one('td:nth-child(9)').get_text()
HLD.append(hld_element)
wpct_element = get_source[0].select_one('td:nth-child(10)').get_text()
WPCT.append(wpct_element)
ip_element = get_source[0].select_one('td:nth-child(11)').get_text()
IP.append(ip_element)
h_element = get_source[0].select_one('td:nth-child(12)').get_text()
H.append(h_element)
hr_element = get_source[0].select_one('td:nth-child(13)').get_text()
HR.append(hr_element)
bb_element = get_source[0].select_one('td:nth-child(14)').get_text()
BB.append(bb_element)
hbp_element = get_source[0].select_one('td:nth-child(15)').get_text()
HBP.append(hbp_element)
so_element = get_source[0].select_one('td:nth-child(16)').get_text()
SO.append(so_element)
r_element = get_source[0].select_one('td:nth-child(17)').get_text()
R.append(r_element)
er_element = get_source[0].select_one('td:nth-child(18)').get_text()
ER.append(er_element)
whip_element = get_source[0].select_one('td:nth-child(19)').get_text()
WHIP.append(whip_element)
year_element = 1983 + season_index - 3
year.append(year_element)
pd.set_option('display.max_columns', None)
df_pitcher2 = pd.DataFrame(
{'name' : name,
'team' : team,
'ERA' : ERA,
'G' : G,
'W' : W,
'L' : L,
'SV' : SV,
'HLD' : HLD,
'WPCT' : WPCT,
'IP' : IP,
'H' : H,
'HR' : HR,
'BB' : BB,
'HBP' : HBP,
'SO' : SO,
'R' : R,
'ER' : ER,
'WHIP' : WHIP,
'year' : year})
df_pitcher2
특성 파악
- ERA : 평균 자책점 Earned Run Average (투수에게만 해당되는 확률), 낮을 수록 투수가 점수를 허용하지 않았다는 뜻
- G : 게임 횟수
- W : win
- L :lose
- SV : save, 마무리 투수를 평가할 때 많이 사용하는 지표(역전을 허용하지 않고 경기를 마무리했을 때 주어지는 기록)
- HLD: 홀드, 세이브 규칙을 준수하여 해당 조건을 충족시키고 경기 도중 물러난 (중간계투) 구원투수에게 홀드 기록 (어쩌면 최동훈 투수에게는 필요없는 카테고리일 수 있겠다)
- WPCT : Winning percentage, 게임 횟수에서 승리한 경기 기록
- IP:Inning Piched, 투수 이닝(한 회를 이르는 말, 양 팀이 공격과 수비를 한 번 씩 끝내는 동안을 이른다.) 수
- H:Hits, 피안타(안타를 맞은 갯수)
- HR : Home runs 홈런을 맞은 개수
- BB : Bases on balls 볼 넷의 갯수(볼넷이 많을 수록 제구에 의심)
- HBP : hit by pitch 사구(데드볼)
- SO : strike out 삼진아웃 (볼넷과 반대개념)
- R : Runs 특점 당한 갯수
- ER : Earned run, 투수가 허용한 자책점
- WHIP : wallk plus hits divided by inning pitched 한 이닝에 볼넷이나 안타를 허용하는 횟수 (출루가 많을 수록 방어율이 떨어진다.)
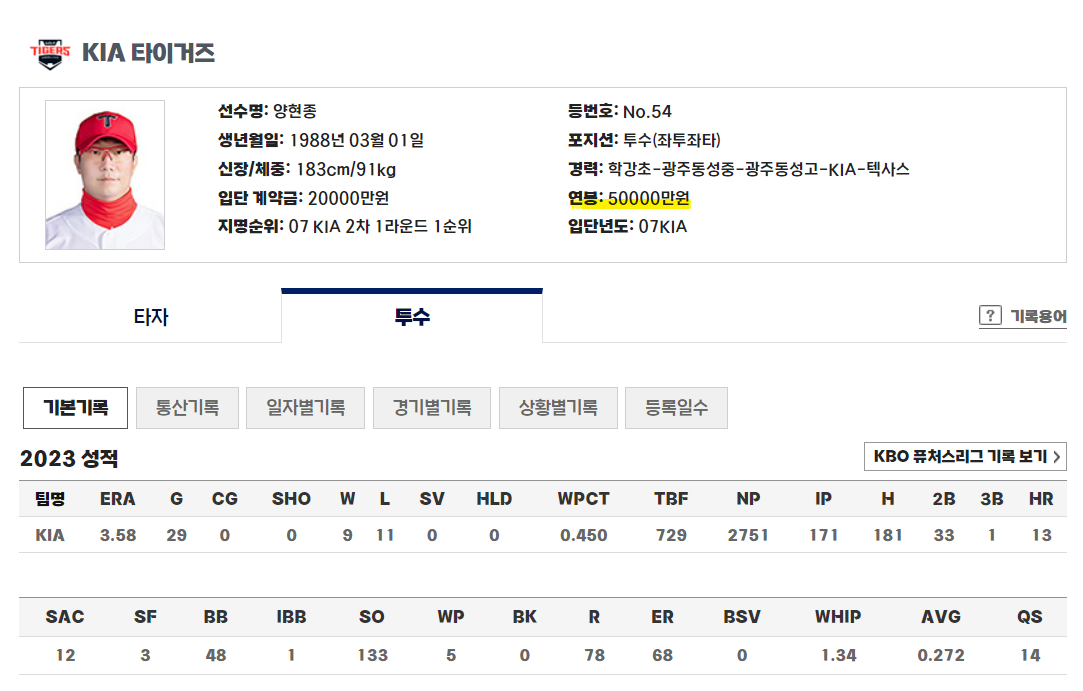
연봉 데이터 크롤링
KBO 기록실에서 선수를 클릭하면 연봉데이터가 있음을 알 수 있었음
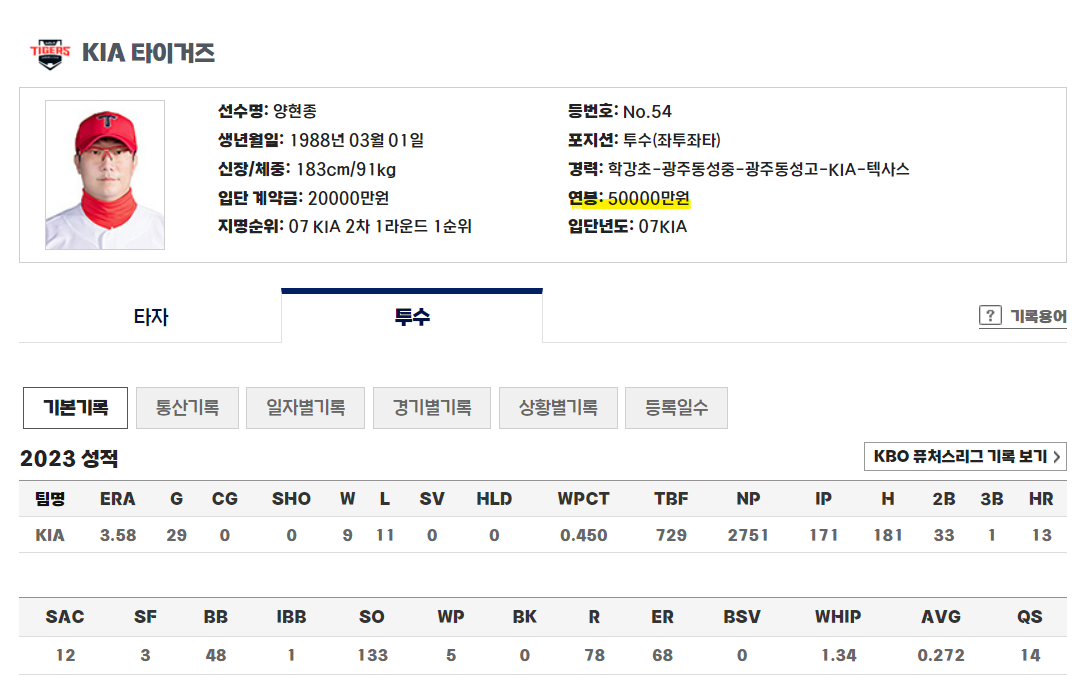
하지만 없는 선수들도 있음

연봉 데이터로 statiz 자료도 고민했지만, kbo 데이터 만큼 양이 적었고, 그렇다면 어떤 데이터가 더 신뢰가 있을까 했을 때 KBO 데이터여서 해당 데이터를 웹크롤링해서 데이터를 수집했다.
salary = []
salary_n = []
#길이가 맞지 않은 관계로 열로 만들어서 진행
length = [21, 18, 20, 26, 28, 21]
num = 0
for season_index in range(34, 40):
# 시즌 선택
btn = driver.find_element(By.CSS_SELECTOR, f"#cphContents_cphContents_cphContents_ddlSeason_ddlSeason > option:nth-child({season_index})")
btn.click()
# 팀 정보 요소의 ID를 사용하여 대기
element_id = "cphContents_cphContents_cphContents_ddlSeason_ddlSeason"
# 대기 조건을 해당 요소의 존재로 변경
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, element_id)))
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
# # WebDriverWait를 이용하여 length 값을 정확하게 가져올 때까지 대기
# length = len(soup.select('#cphContents_cphContents_cphContents_udpContent > div.record_result > table > tbody > tr')) + 1
for i in range(1, length[num]):
btn1 = driver.find_element(By.CSS_SELECTOR, f"#cphContents_cphContents_cphContents_udpContent > div.record_result > table > tbody > tr:nth-child({i}) > td:nth-child(2) > a")
time.sleep(2)
btn1.click()
# element_id = "cphContents_cphContents_cphContents_playerProfile_lblName"
# # 대기 조건을 해당 요소의 존재로 변경
# WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, element_id)))
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
#이름 수집
get_name = soup.select_one("#cphContents_cphContents_cphContents_playerProfile_lblName")
get_name_re = soup.select_one("#cphContents_cphContents_cphContents_ucRetireInfo_lblName")
if get_name:
salary_n.append(get_name.get_text(strip=True))
elif get_name_re:
salary_n.append(get_name_re.get_text(strip=True))
#연봉 수집
get_salary = soup.select_one("#cphContents_cphContents_cphContents_playerProfile_lblSalary")
if get_salary:
salary.append(get_salary.get_text(strip=True))
else:
salary.append(None)
driver.back()
if num < len(length):
num += 1
else:
break
df_s = pd.DataFrame({'name' : salary_n,
'salary' : salary})
df_s
전처리
- 크롤링 과정에서 생긴 불필요한 자료 삭제
- 1980년대 자료와 2010년대 자료 행 통일하기 위해서 일부 삭제하고 'WHIP'라는 파생변수 생성
- 연봉자료가 없는 2010년대 자료 삭제
#pitcher1과 pitcher2 열을 정리하기 전에 pitcher2와 salary 먼저 정리하기
df_salary.info() #연봉이 50개밖에 없음
df_salary.name.nunique() #이름도 67개로 겹치는 게 꽤 많음
df_salary2.name.unique()
df_salary2[df_salary2.name == '이용찬'] #이름마다 같은 연봉

df_p2s = pd.merge(df_pitcher2, df_salary.drop_duplicates('name'), on='name', how='left')
df_p2s_c = df_p2s.dropna(subset=['salary'])
print(df_p2s_c.shape) #(48,20)
#salary 형식 변경 ('만원' 떼기)
df_p2s_c['salary'] = df_p2s_c['salary'].apply(lambda x : x[:-2])
df_p2s_c['salary'] = df_p2s_c['salary'].astype('int')
df_p2s_c = df_p2s_c.reset_index(drop=True)
df_p2s_c
상관관계를 살펴봐을 때,
-
연봉과 가장 상관있어보이는 것은 WHIP(음), ERA(음)으로 보인다.
-
상관 없어보이는 요소 (-0.2 ~ 0.2) : G, L, SV, HLD, H, HBP, SO
-
상관 없어보이는 요소 (-0.3 ~ 0.3) : W, WPCT
#공동 열로만 정리하기
df_pitcher1.drop(columns=['CG', 'SHO', 'TBF'], inplace=True)
#이닝 분수를 실수로 만들기
from fractions import Fraction
df_pitcher1['IP_f'] = df_pitcher1['IP'].apply(lambda x: round(float(sum(Fraction(part) for part in str(x).split())),3))
df_pitchers2_s['IP_f'] = df_pitchers2_s['IP'].apply(lambda x: round(float(sum(Fraction(part) for part in str(x).split())),3))
df_pitcher1
int_col = ['G', 'W', 'L', 'SV', 'HLD', 'H', 'HR', 'BB', 'HBP', 'SO', 'R', 'ER', 'year']
float_col = ['ERA', 'WPCT']
df_pitcher1[float_col] = df_pitcher1[float_col].astype('float')
df_pitcher1[int_col] = df_pitcher1[int_col].astype('int')
df_pitchers2_s[float_col] = df_pitchers2_s[float_col].astype('float')
df_pitchers2_s[int_col] = df_pitchers2_s[int_col].astype('int')
#파생변수 만들기
df_pitcher1['WHIP'] = round((df_pitcher1['BB'] + df_pitcher1['H'])/df_pitcher1['IP_f'],2)
df_pitcher1.drop(columns='IP', inplace=True)
df_pitchers2_s.drop(columns='IP', inplace=True)
df_pitchers2_s['WHIP'] = df_pitchers2_s['WHIP'].astype('float')
#합치기
df_p = pd.concat([df_pitcher1, df_pitchers2_s], axis=0, ignore_index=True)
df_p
df_p[df_p.name == '최동원']
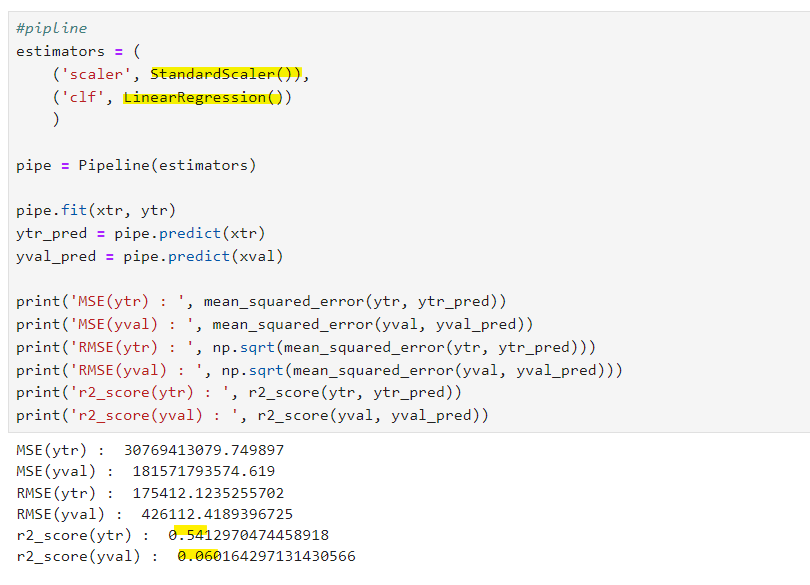
예측하기 : 회귀모델 사용
회귀모델 평가지표를 봤을 때 성능이 좋지 못함
-
r2_score이 1에 가까울 수록 성능이 높다. 선형회귀는 성능이 좋지 않다고 판단할 수 있다.
성능을 높이기 위해서는..1) 스케일링을 Standard로 변경
2) Lasso, Ridge 활용
3) 상관관계가 적은 열 제거
4) 교차검증
5) 앙상블 활용 RandomForest, Gradient Boosting
1) Lasso, Ridge 활용
- 라쏘, 릿지 모두 오히려 선형회귀보다 성능이 좋지 않음
- 상관없는 열을 제거하는 방향 진행
2) 상관관계가 적은 열 제거
#3. 상관관계가 적은 열 제거
#위에서 확인했을 때 -0.2~0.2사이에 있는 요소 삭제
scaled_feature2 = ['ERA', 'W', 'WPCT', 'HR', 'BB', 'R', 'ER', 'IP_f', 'WHIP']
X2 = df_pitchers2_s[scaled_feature2]
test2 = df_pitcher1[scaled_feature2]
test2
추가 전처리 전에는
- r2_score(ytr) : 0.5412970474458918
- r2_score(yval) : 0.06016429713143056
전처리 후
- r2_score(ytr) : 0.3967469329391605
- r2_score(yval) : 0.0553630539498690
로 성능이 저하됨
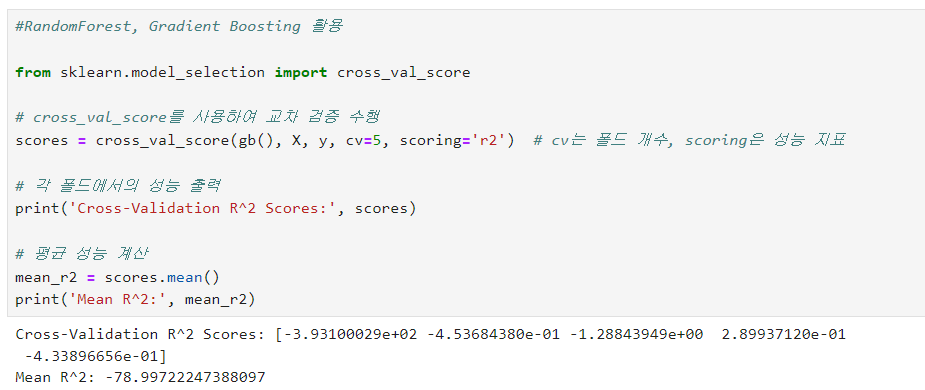
3) 앙상블 활용 RandomForest, Gradient Boosting
다른 모델을 써볼까해서 써봤다가
극한의 마이너스 값이... 나와서
초반에 설마했지만, 데이터 수집이 잘못되었다는 것을 인정하고 다시 수집
이 때는 statiz 사이트 자료를 사용해서 다시 같은 과정을 쭈욱 반복했지만
으로 여전히 결과가 처참했다.
✅ 그렇다면 아예 다른 자료를 구해야 한다. 자료의 중요성을 ML 프로젝트뿐만 아니라 테스트에서도 경험했다.. 양도 중요하다.
off the record
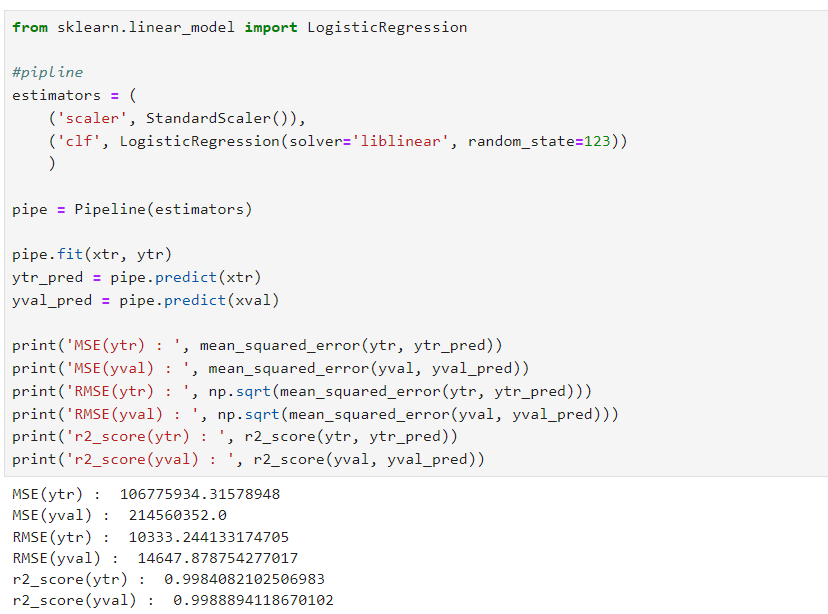
로지스틱 회귀(분류)인데 성능이 좋게나왔다.
실수로 선형회귀 대신 로지스틱 회귀를 했는데, 성능이 정말 높게 나왔다.
최동원 선수의 2010년대 연봉을 5억으로 예측했다.
응??
추측컨대,
이는 데이터가 적고, 100만원 단위로 끊어져서 분류에서 높은 성능을 발휘했을 수 있지 않을까?
결론 : 데이터 수집을 잘해야 한다.
🤔 그런데 그걸 어떻게 알 수 있을까?
해보는 수밖에 없다. 다시 시도하는 것! 중요한 건 시기적절하게 계속 분석할 지 새로 수집할 지 판단하는 것 아닐까.
나는 결론에 도달하지 못했지만, 과제 해설 영상이 여러 개였고, 비교하는 재미가 있었다. 과제 끝
