스케일링
Label Encoder: 문자를 숫자로 변경
from sklearn.preprocessing import LabelEncoder
#0 과 n_classes-1 사이 값으로 변환.
.
MinMax Scaler: 0과 1사이에 위치하게 스케일링
-원리 :
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min-문법
MinMaxScaler(feature_range=(0, 1), *, copy=True, clip=False)
-사용 :
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)
mms.data_max_, mms.data_min_ #데이터 최소값, 최댓값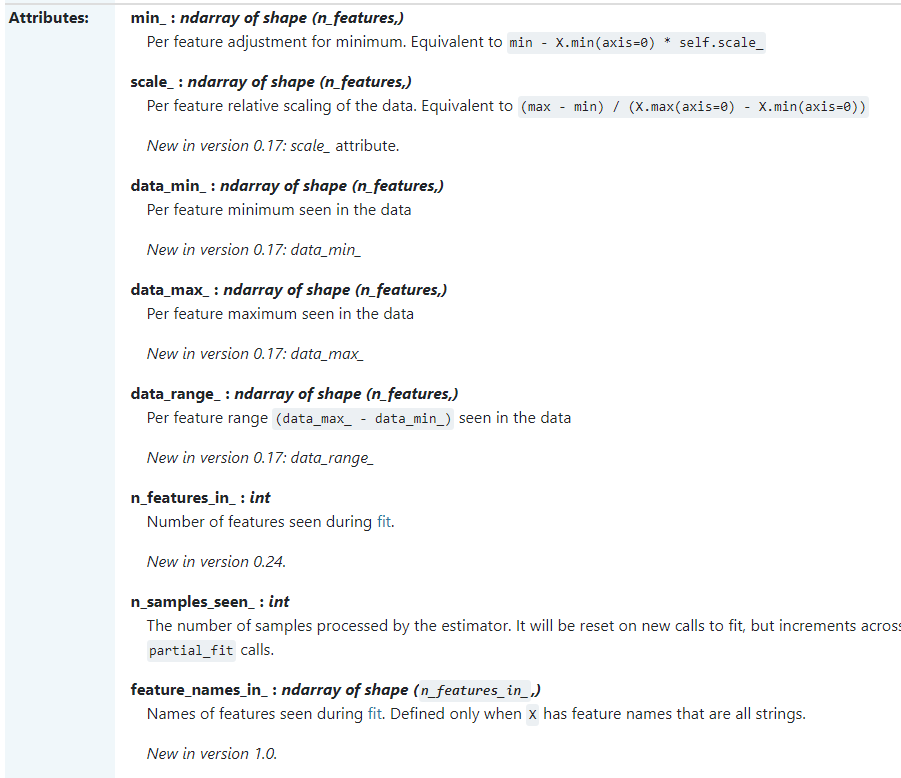
자주쓰는 속성 : datamin, datamax, nfeatures_in
출처
.
.
StandardScaler: 평균과 분산을 사용한 스케일링
-문법
StandardScaler(*, copy=True, with_mean=True, with_std=True)
-사용
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.mean_, ss_scale_ #평균과 표준편차-속성

.
.
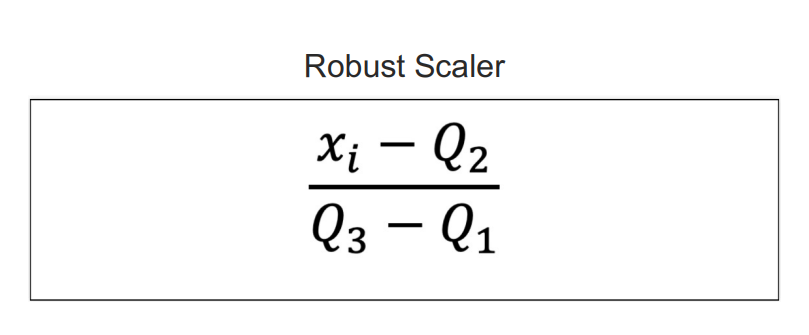
RobustScaler: 중간값과 사분위수를 사용한 스케일링
-문법
RobustScaler(*, with_centering=True, with_scaling=True, quantile_range=(25.0, 75.0), copy=True, unit_variance=False)
-사용
from sklearn.preprocessing import RobustScaler-속성


데이터로 경로를 탐색합니다.