집계함수 Aggregate Functions

- 예시
#함수를 적용하고 싶은 column을 지칭하는 코드를 감싸서 적용
SELECT COUNT(DISTINCT police_station) FROM crime_status;
추가 집계 함수
GROUP BY : 그룹화 하여 데이터를 조회
SELECT columns1, columns2, ...
FROM table
WHERE condition
GROUP BY column1, columns2, ...
ORDER BY column1, columns2, ...;HAVING : 조건에 집계함수가 포함되는 경우 WHERE 대신 HAVING 사용
- GROUP BY 조건에서 WHERE을 사용할 수 없기 때문에
SELECT columns1, columns2, ...
FROM table
WHERE condition
GROUP BY column1, columns2, ...
HAVING condition (Aggregatet Functions)
ORDER BY column1, columns2, ...;- 예시
SELECT police_station, sum(case_number) count #alias임
FROM crime_status
WHERE status_type LIKE '발생'
GROUP BY police_station
HAVING count > 4000;스칼라 함수 Scalar Functions
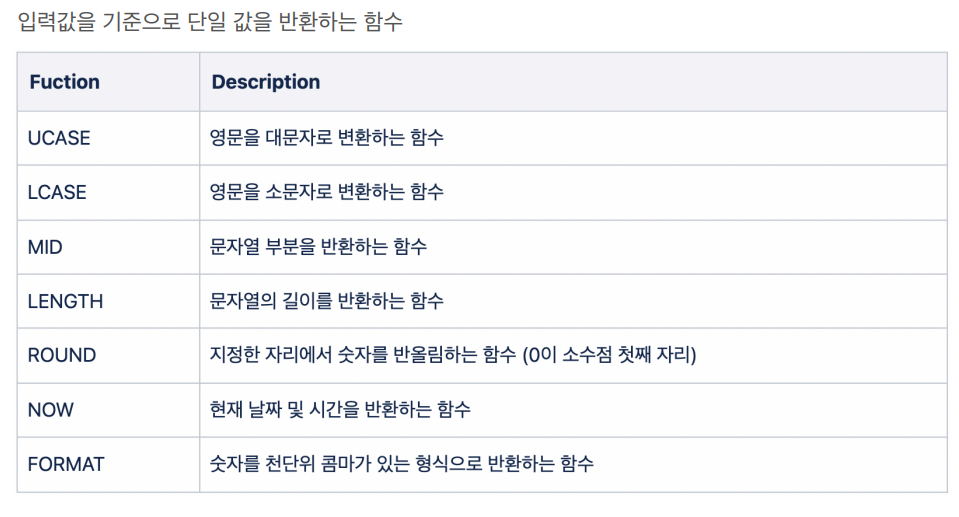
- 예제
SELECT UCASE(menu) FROM sandwich WHERE price > 15;
#위와 같이 원하는 입력값을 ()로 감싼다.
SELECT MID(string, start_position, length);
## string : 원본 문자열 / start : 문자열 반환 시작 위치 / length : 반환할 문자열 길이
SELECT FORMAT(number, decimal_palce):
## number : 포맷을 적용할 문자 혹은 숫자 / deciamls : 표시할 소수점 위치- 예제
SELECT FORMAT(가격, 0) FROM oil_price WHERE ROUND(가격, -3) >= 2000;SQL subquery
: 하나의 SQL 문 안에 포함되어 있는 또 다른 SQL문을 말한다.
■ 메인 쿼리가 서브쿼리를 포함하는 종속적인 관계이다.
- 서브쿼리는 메인쿼리의 칼럼을 사용 O
- 메인쿼리는 서브쿼리의 칼럼을 사용 X
■ 서브 쿼리는 괄호로 묶어서 사용
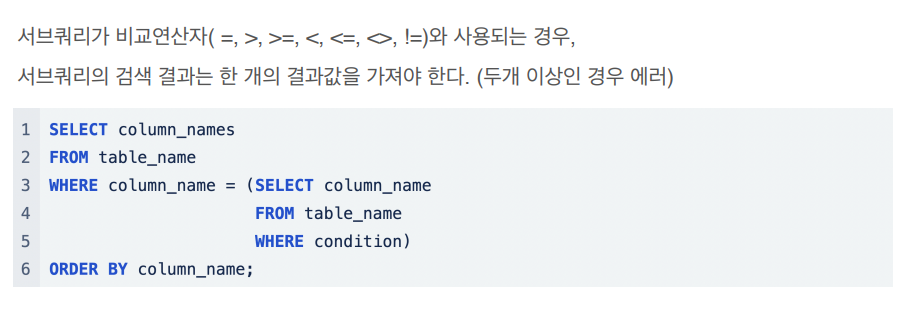
■ 단일 행 혹은 복수 행 비교 연산자와 함께 사용 가능
■ SUBQUERY는 ORDER BY 사용 X
Subquery 종류
■ 스칼라 서브쿼리 (Scalar Subquery) : SELECT 절에 사용
#결과는 COLUMN 1개여야 한다.
SELECT column1, (SELECT column2 FROM table2 WHERE condition)
FROM table1
WHERE condition;
■ 인라인 뷰 (Inline View) : FROM 절에 사용
#메인 쿼리에서는 인라인뷰에서 조회된 COLUMN만 사용 가능하다.
SELECT a.column, b.column
FROM table1 a, (SELECT column1, column2 FROM table2) b
WHERE condition;■ 중첩 서브쿼리(Nestest Subquery) : WHERE 절에 사용
-
Single Row : 하나의 열을 검색하는 서브쿼리
-
Multiple Row : 하나 이상의 열을 검색하는 서브쿼리
-
Multiple Column : 하나 이상의 행을 검색하는 서브쿼리
◎ Multiple Row에서 IN : 서브쿼리 결과 중에 포함될 때
SELECT column_names
FROM table_name
WHERE column_name IN (SELECT column_name FROM table_name WHERE condition)
ORDER BY column_names;◎ Multiple Row에서 EXIST : 서브쿼리 결과에 값이 있으면 반환
SELECT column_names
FROM table_name
WHERE EXISTS IN (SELECT column_name FROM table_name WHERE condition)
ORDER BY column_names;◎ Multiple Row에서 ANY : 서브쿼리 결과 중에 최소한 하나라도 만족하면 (비교연산자 이용)
SELECT column_names
FROM table_name
WHERE column_names = ANY (SELECT column_names FROM table_name WHERE condition)
ORDER BY column_names;◎ Multiple column subquery : 서브쿼리 내에 메인 쿼리 컬럼이 같이 사용되는 경우
SELECT column_names
FROM table_name a
WHERE (a.column1, a.column2, ...) IN (SELECT b.column1, b.column2, ...) FROM tablename b WHERE a.column_name = b.column_name)
ORDER BY column_names;
데이터로 경로를 탐색합니다.