🔎 퀴즈에서 헷갈린 내용 정리하기
1) np.linsplace 와 np.arrange 차이
np.linsplace 는 범위 내 값들의 간격을 설정할 수 있고,
np.arrange는 범위 내 값들의 개수를 설정 가능
2) np.polyfit() vs np.poly1d()
np.polyfit() 주어진 데이터를 설명하는 다항식을 생성하고, 계수를 반환
np.poly1d() 다항식 함수를 계산해 값 출력
3) get_level_values(level)
: ⭐Multi Index에서 특정 단계의 레이블을 추출해야하는 경우 사용하는 메서드
level : 레이블을 추출하기 위한 단계를 입력하는 곳
4) df.columns.droplevel(level, axis = 0)
: ⭐Multi Index나 Multi Columns⭐에서 특정 레벨을 제거하는 메서드. 참고문서
remove_unused_levels()도 삭제하는데 이용한다. 참고문서
🔎 개념 정리하기
1) list comprehension
- comprehension은 '이해력'이라는 영어 단어이다. 리스트 컴프리헨션은 프로그래머가 반복 가능한 항목을 한 줄로 반복하고 변환할 수 있도록 하는 파이썬 구문 형식이다. (리스트를 짧게 한줄로 만들 수 있는 문법)
기존 방식
1) 배열을 선언한다 2) 배열의 원소에 값을 할당한다
list comprehension은 이 과정을 간략하게 해주는데,
[(변수로 활용할 값) for (사용할 변수 이름) in (순회할 수 있는 값)]
예1) [i ** 2 for i in range(1, 20)]
예2) [n for n in range(5) if n /2 == 0] #조건문도 가능
#원하는 표현 방식에 따라 순서가 달라지니까!
- 기본구조 : [표현식 for 변수 in list]
- 반복문 + 조건문 : [표현식 for 변수 in list 조건문]
- 조건문 + 반복문 : [표현식 if 조건 else 표현식 for 변수 in list]
- 중첩 for 문 : [표현식 for 변수 in list for 변수 in list]
예)
pos = []
for i in range(1, 4) :
for j in range(1, 3) :
pos.append(i*j)
pos = [ i*i for i in range(1, 4) for j in range(1, 3) ] # [1, 2, 2, 4, 3, 6]
- 중첩 comprehension : [[표현식 (내부 list comprehension) for 변수 in list] for 변수 in list]
예)
# 중첩 list comprehension으로 2차원 배열 만들기
result = [ [ 0 for i in range(2) ] for j in range(3) ] # [ [0, 0], [0, 0], [0, 0] ]
.
.
2) date_range
-
문법: pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, inclusive='both') *start, end 제외 모두 optional -
시작일과 종료일 (또는 기간)을 입력하면 해당 범위 내 데이터를 반환한다.
start <= x <= end그 기간 사이 일자가 모두 DatetimeIndex로 나오고, 시간대도 함께 설정할 수 있다. (시간대는 freq를 설정하면 된다) -
파라미터
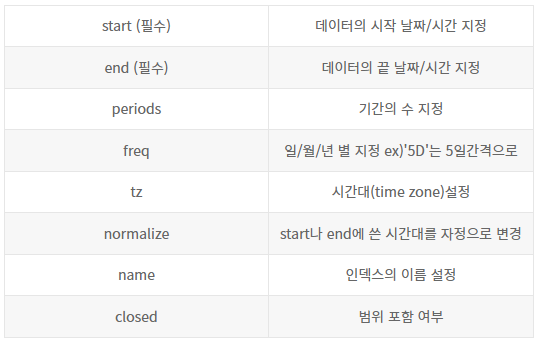
-
frequ 설정
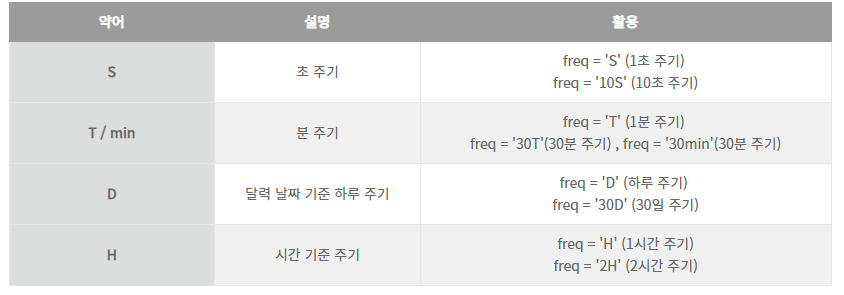
3) iterrows()
문법: pandas.DateFrame.iterrows(index 행의 인덱스, Series 행의 데이터를 시리즈로 표현)- 이 메소드는 데이터 프레임의 행-열/데이터 정보를 튜플 형태로 만드는 generator 객체로 반환한다.
- 반환 값은 (행 이름, 내용의 Series 객체)로 나오며, Series는 열 - 값 형태로 반환된다. ... 자세히 말하자면,
-첫 번째 데이터 자리에는 DataFrame의 index 정보가 들어있으며,
-두 번째 데이터 자리에는 해당 index를 가지는 DataFrame의 행 정보가 Series 형태로 들어있다. - for loop 가 돌면서 하나씩 tuple 형태로 출력되기에 일일이 출력할 번거로움을 줄여주는 method이다.
- iterrows가 갖게되는 행 순서는 DataFrame의 index와는 상관 없이 iterrows가 적용된 DataFrame의 가장 위쪽 행부터 참조하기에 index 기준이 아닌 DataFrame의 첫 번째 행부터 차례대로 반복문으 돌려야하는 상황에서 효과적이다.
import pandas as pd
dict_1 = {
'col1': [4, 1, 5, 3, 2],
'col2': [6, 7, 8, 9, 10],
'col3': [11, 12, 13, 14, 15],
'col4': [16, 17, 18, 19, 20]
}
df_1 = pd.DataFrame(dict_1)
print(df_1)
print(df_1.iterrows())
-- Result
col1 col2 col3 col4
0 4 6 11 16
1 1 7 12 17
2 5 8 13 18
3 3 9 14 19
4 2 10 15 20
>> for row in df_1.iterrows():
print(row)
-- Result
(0, col1 4
col2 6
col3 11
col4 16
Name: 0, dtype: int64)
(1, col1 1
col2 7
col3 12
col4 17
Name: 1, dtype: int64)
(2, col1 5
col2 8
col3 13
col4 18
Name: 2, dtype: int64)
(3, col1 3
col2 9
col3 14
col4 19
Name: 3, dtype: int64)
(4, col1 2
col2 10
col3 15
col4 20
Name: 4, dtype: int64)
# iterrows 객체에 있는 정보를 하나씩 print한 모습, iterrows 객체는 보면 (index, row_series) g형태를 띤다.
