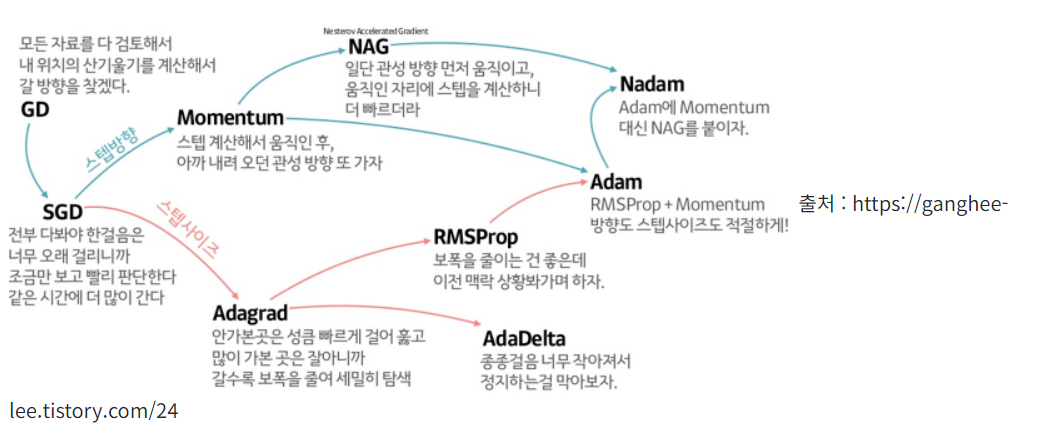
Optimizer
- 최적화과정
- 손실함수를 설정하고 Error가 감소하는 방향으로 학습하기 위해서 각각 맞는 가중치와 기울기 값을 계산하고, 가중치를 재설정하는 과정을 거쳐 최적의 가중치(weight)를 갖는 모델을 찾아낸다.
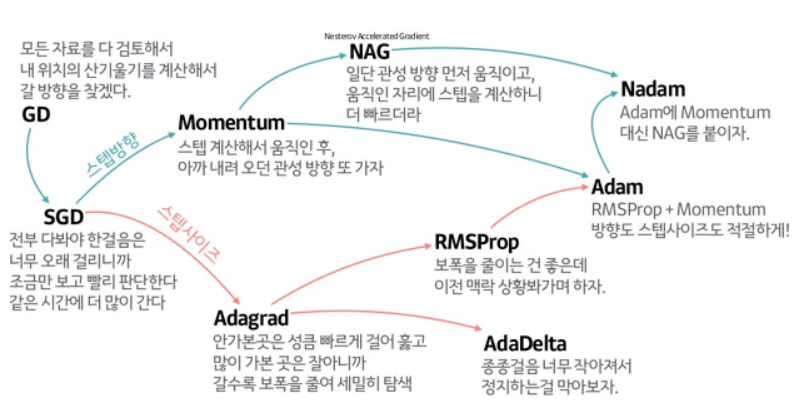
Gradient Descent
- 개념 : 가장 기본이 되는 최적화 알고리즘으로, 흔히 알고 있는 경사하강법
- 방법 : 경사를 따라 내려가면서 weight를 업데이트해 최솟값을 찾는 방법
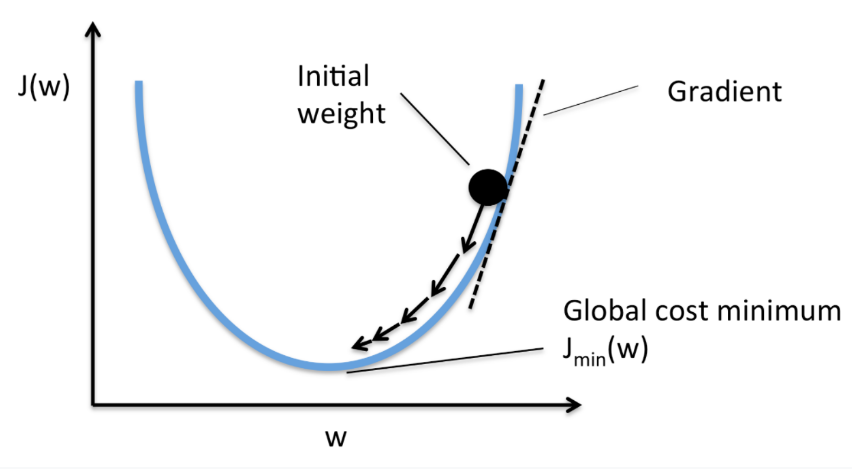
gradient가 - 가 되도록 값을 이동시키면 최솟값을 찾을 수 있다는 아이디어
- 단점 : 모든 자료의 기울기를 다 검토하기에 데이터셋이 클수록 계산량↑
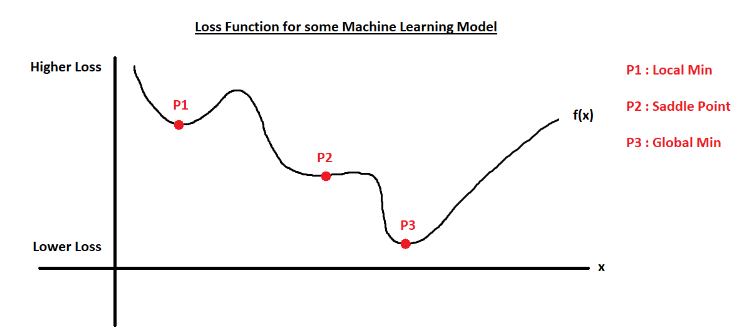
전체에서 가장 최소가 되는 부분(global minimum)을 찾아야 하는데, local minimum (즉, u그래프 맨 하단에 위치해 기울기값이 0이 되나, 가장 최솟값은 아닌)을 찾으면 업데이트 과정이 끝난다.
local minimum
saddle point(안장점) : 기울기가 0이지만 해당 지점이 극대점이나 극소점이 아닌 경우
Stochastic Gradient Descent (SGD)
- GD는 아래와 같이 모든 기울기값을 모두 구해 합쳐 업데이트 진행한다면
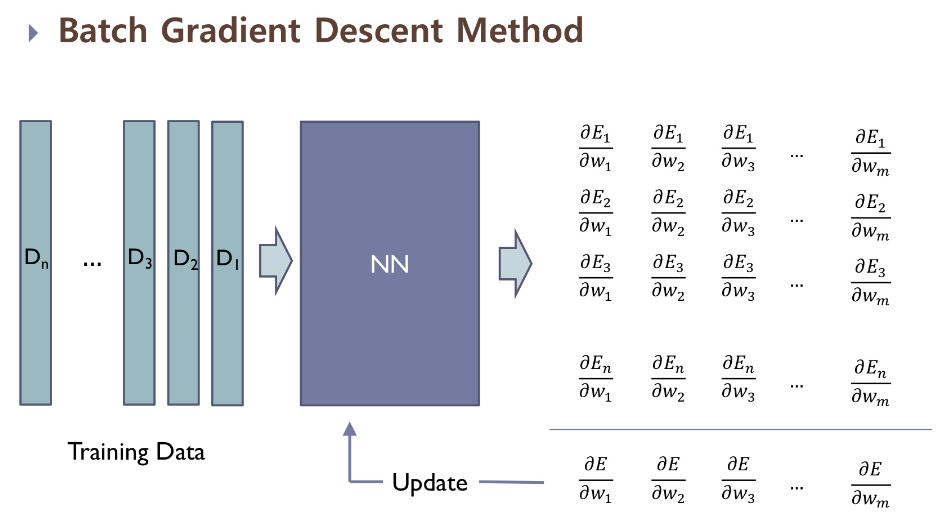
- SGD는 다음과 같이 데이터의 개수를 n개로 보았을 때,
하나의 데이터당 gradient를 구해 업데이트 과정을 진행한다. 모든 데이터를 활용했을 때는 n번의 업데이트 과정을 진행한다.
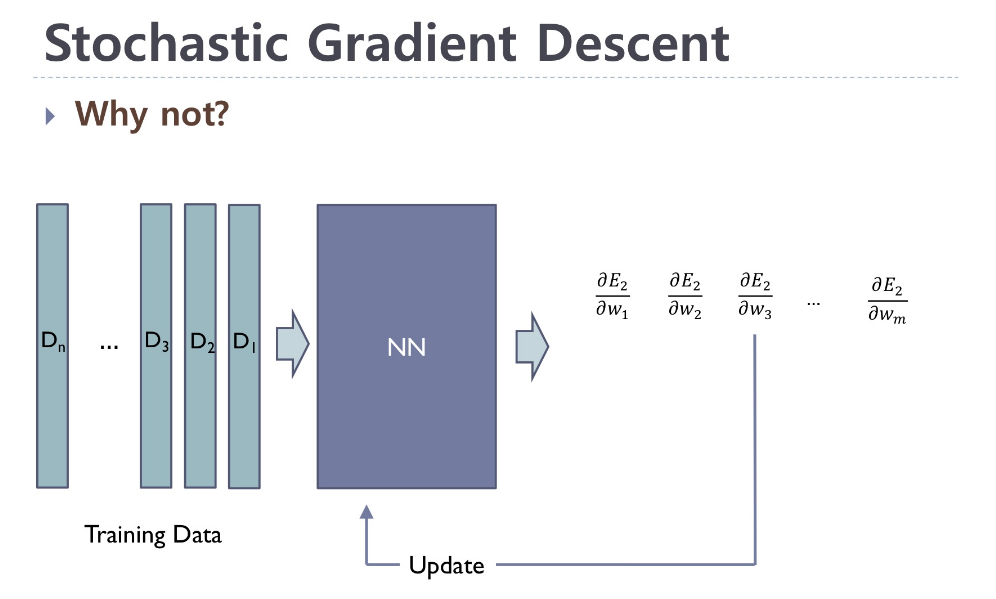
비교 GD와 비교해서 속도가 좀더 빠르지만 local minimum 문제는 해결하지 못했다.
⭐⭐⭐이를 해결하기 위해 Momentem 등장⭐⭐⭐
Momentum
물리의 운동량의 개념을 활용해 기존에 가지고 있는 momentum과 현재 위치의 기울기를 고려해 변수를 업데이트한다.
단점 global minimum을 찾았는데도 계속 진행하려는 과도한 업데이트 가능성이 있다.
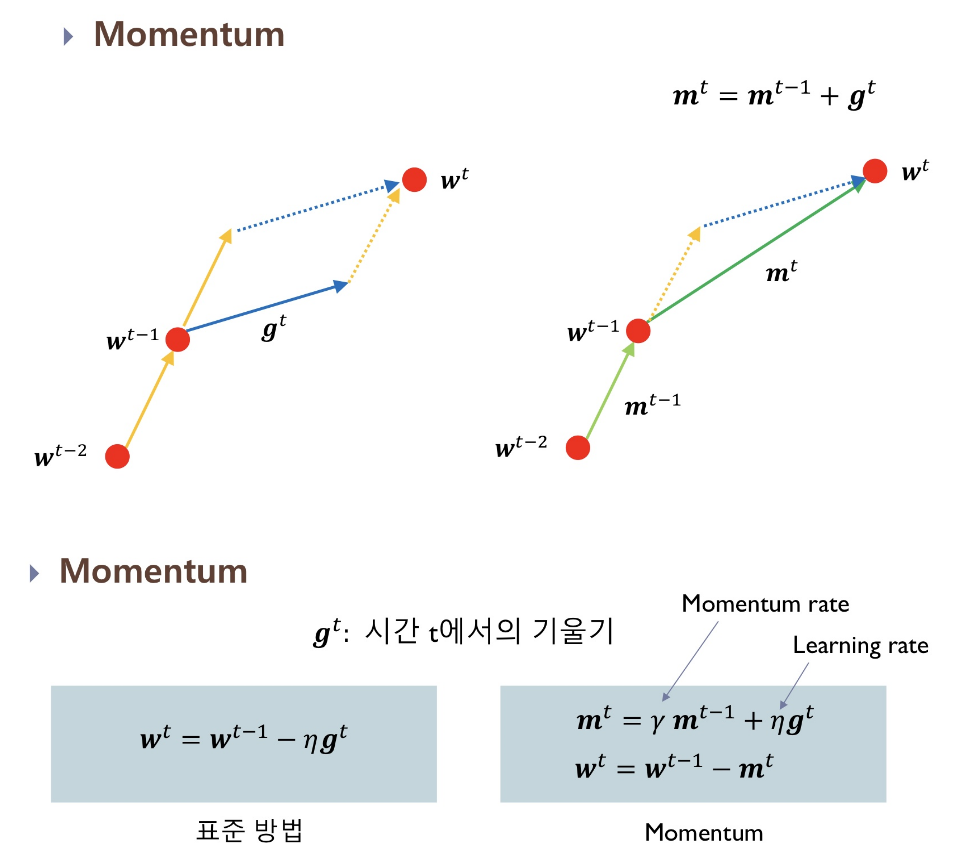
Nesterov Accelerated Gradient (NAG)
⭐⭐⭐Momentum에서 한 발짝 나아가 미래 위치를 추정해서 거기의 기울기를 구한다면? 그리고 그 기울기로 미래 위치를 다시 계산한다면?⭐⭐⭐
모멘텀과 NAG를 비교하였을 때
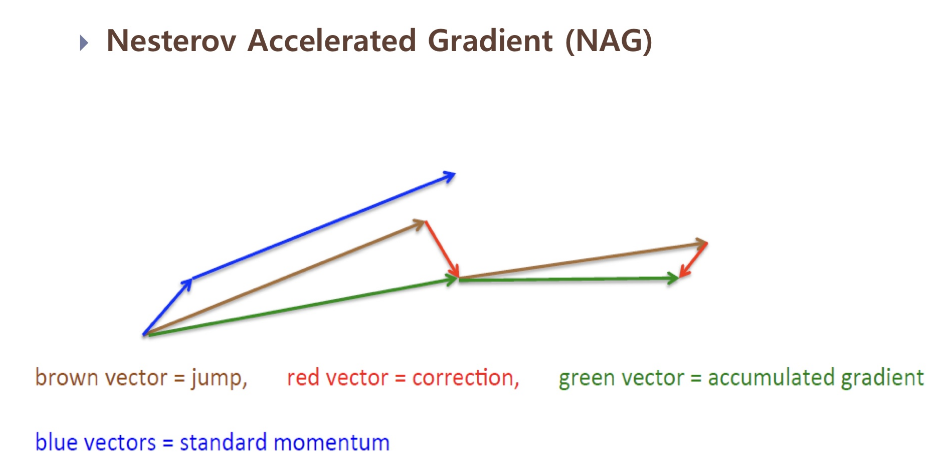

장점 미래의 gradient를 이해할 수 있다. 경사 값이 작거나 경사가 낮을 때 운동량을 감소시키고 경사가 급할 때 운동량을 증가시킬 수 있다.
단점 모든 파라미터는 동일한 방법으로 갱신
.
.
이 과정에서 의문이 생긴다는데 모든 weight에 대해 동일한 learning rate를 적용해야 할까? 많이 업데이트된 변수는 적게, 적게 업데이트된 변수는 더 많이 업데이트할 수는 없을까?
Adagrad
Adaptive Gradient Algorithm
지금까지 비교적 훨씬 많이 업데이트된 변수는 적게, 적게 업데이트된 변수는 많이 업데이트하는 방법이다.

식에서 Gt는 업데이트 된 총량을 나타내는데 이 값이 커질 수 록 (즉, 분모가 커질수록) 업데이트하는 양은 감소한다. 반대로 분모가 작아지면 업데이트하는 양이 커진다.
장점 : 누락된 샘플이 있거나 희박한 데이터셋에 매우 적합
단점 : Gt는 시간이 지날 수록 증가하기 때문에 학습률이 계속 감소한다
⭐⭐⭐이걸 개선하기 위해서..⭐⭐⭐
RMSProp
Root Mean Square Propagation
Adagrad는 지금까지 업데이트한 전체 총량을 고려해서 업데이트를 진행한다면,
RMSProp는 최근에 업데이트한 양을 고려 한다.

장점 : Adagrad는 시간 단계별로 학습 속도를 낮추지만, RMS-Prop는 각 단계별로 학습속도의 증감에 적응할 수 있다.
단점 : 느린 학습속도
.
.
Adam
Adaptive Moment Estimation
RMSProp와 Momentum의 장점을 모아 만든 옵티마이저

장점 대규모 데이터셋에 적합하며 계산 효율이 높다
단점 성능은 제공한 데이터 유형고 속도, 일반화의 균형에 따라 달라진다.
PyTorch에서 사용하기
class torch.optim.Optimizer( 매개변수 , 기본값 )
import torch
from torch import optim
model = MyNetwork()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = torch.optim.Adam([var1, var2], lr=0.0001)-
Method
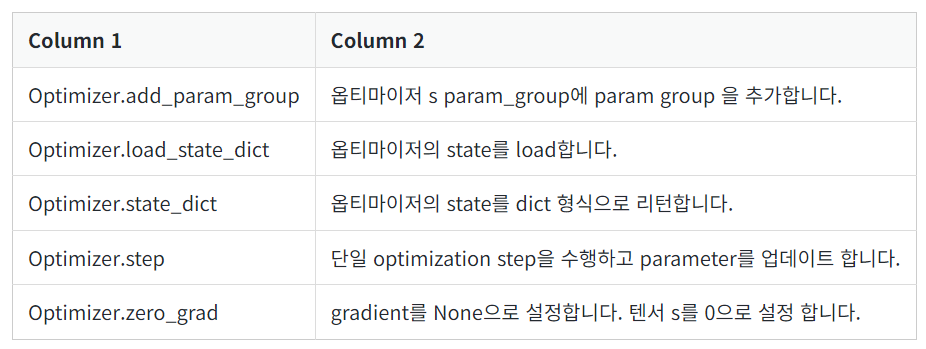
-
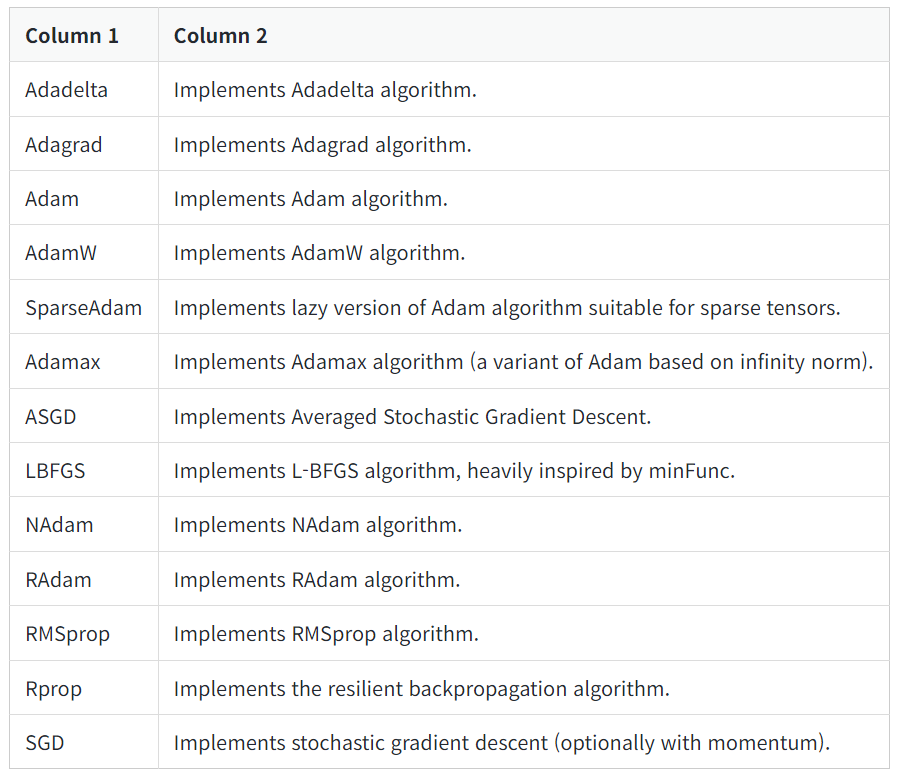
Algorithm
SGD를 기본으로 하고 있다.
.
.
TensorFlow에서 사용하기
#SGD
>>> keras.optimizers.SGD(learning_rate=0.01, momentum=0.0)
#RMSprop(Root Mean Square Propagation)
#SGD의 단점 중 하나인 학습률을 설정하기 어려운 문제를 해결하기 위해 고안된 알고리즘입니다.
#기울기 제곱의 이동평균 값을 구하여 학습률을 조절합니다.
>>> keras.optimizers.RMSprop(learning_rate=0.001, rho=0.9, momentum=0.0)
#Adagrad
#학습을 진행할수록 학습률을 낮추는 방식으로 가중치 업데이트
>>> keras.optimizers.Adagrad(learning_rate=0.001)
#Adadelta
#기울기 제곱과 업데이트 제곱의 이동평균 값을 계산해서 학습률 조절
>>> keras.optimizers.Adadelta(learning_rate=0.001, rho=0.95)
#Adam
#기울기 제곱과 모멘텀의 이동평균 값을 계산하여 학습률을 조절
>>> keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999)
#Nadam
#(Nesterov-accelerated Adaptive Moment Estimation)
# Adam 알고리즘에서 Nesterov momentum을 추가
>>> keras.optimizers.Nadam(learning_rate=0.001, beta_1=0.9, beta_2=0.999)
#Ftrl
#Follow the Regularized Leader
#대규모 데이터셋에서 사용하는 알고리즘으로, L1/L2 정규화와 함께 사용
>>> tf.keras.optimizers.Ftrl(learning_rate=0.001,learning_rate_power=-0.5)
