개요
model을 학습시키기 위해선 optimization라는 작업을 해준다. weight의 torch.backward()라는 함수로, gradient를 구해서 weight의 값을 변화시켜주는 역활을 한다. 가장 기본적인 방법으로
SGD가 있는데, 아래 나오는 모든 opimizer는 SGD의 응용이다.
SGD의 원리
우리가 data를 model에 입력했을 때, model은 그 data의 실제갑과 model의 예측값을 비교하여 loss를 알려준다. SGD란 loss를 줄이기 위해 고안된 방법으로, loss의 미분을 이용하여 loss를 줄이는 것이 그 목표이다.
위의 이미지를 보자.우리가 model에 data를 구했을 떄, loss를 미분하였을 때, 현재의 위치를 점 이라고 해보자.
1. 우리가 구하고 싶은 것은 loss가 최소가 되는 지점, 즉 그래프의 최소점(위의 그림은 2차함수)을 구하고 싶다.
2. 미분은 그래프의 기울기를 나타낸다. (사진의 gradient)
- 즉 우리는 gradient가 -가 되도록 값을 이동시키면 언젠가 최소값을 찾을 수 있다는 아이디어에서 출발한 것이 SGD이다.
사용
가장 기본적인 SGD의 사용이다.import torch from torch import optim model = MyNetwork() optimizer = torch.optim.SGD(model.parameters() , lr= 0.01)여기서 lr은 Learning Rate의 줄임말이며, 미분값을 얼만큼 이동시킬 것인가를 결정한다. 초기값이 크다면 초반엔 loss값이 빠르게 줄겠지만, 나중에 가면 underfitting이 발생하게 된다.

SGD + Momentum
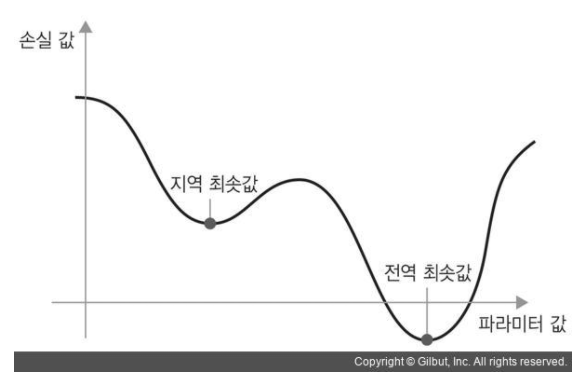
하지만 sgd에도 단점이 있는데, 위의 그래프처럼 구하려는 함수의 미분 그래프가 2차함수가 아닌 3차 이상의 그래프일 경우 최소점이 2개 이상 생기는 경우가 발생한다.
- loss의 미분값이 파라미터의 값이 0에 존재한다고 생각해보자. 위의 사진을 보면, 우리가 구하려는 전역 최소값에 가기전, 지역 최소값에 도달하면 미분값이 0이 되면서 더 이상 움직이지 않는다. 그래서 sgd에 약간의 변형을 준 것이 SGD+Momentum이라는 개념이다.
optimizer = optim.SGD(model.parameters() , lr =0.01, momentum = 0.9)sgd에다가 이전의 이동값을 고려하도록 설계하여 momentum. 즉 관성을 주었다. 혹여 지역 최소값에 도달하더라도 앞으로 나아가서 지역 최소값을 탈출할 수 있도록 설정해준다.
- momentum값은 0.9에서 시작하며, 0.95, 0.99로 증가시키며 사용!
AdaGrad
loss가 최소값이 되도록 찾아가는 과정은 다음과 같은데, 최적의 해에 가까워 질 수록 optimizer의 보폭이 줄어드는 것을 확인할 수 있다.
- optimizer의 step은 답에 가까워 질 수록 줄어들어야 최적의 해를 구할 수 있는데, 위에서 SGD의 경우 underfitting이 일어날 떄마다 lr을 줄여주면 된다. 이런 개념에서 탄생한 것이 AdaGrad이다.
그러나, step별로 lr를 줄이다 보니 최적의 답에 도달하기 전에 0에 가까워 져서 더 이상 움직이지 않는 문제가 생긴다.
그것을 방지하기 위해 RMSprop이라는 것을 사용한다. RMSprop은 AdaGrad를 응용한 것으로, 일정한 비율로 step을 조절한다.
- adagrad는 gradient가 0에 수렴하는 문제가 있어서, 사용하지 않는다. 대신 Rmsprop을 사용한다.

Adam
위에서 설명한 모든 개념을 합친 것으로,
sgd + momentum, RMSprop을 같이 사용하여 더욱 효율적으로 gradient를 조절한다.
- 보통 Adam을 쓰는 것을 권장한다!

보충(scheduler)
running을 돌리다 보면, lr을 직접 수정해 줘야 할 때가 있다. 이때 사용하는 것으로, step_size를 정해서, 정해진 epoch을 돌리면, lr을 줄여준다.
scheduler = StepLR(optimizer,step_size = 30, gamma = 0.01) for e in epochs: for data, labels in trainloader: train() # 학습하고 for data, labels in valid_loader: validation() validation으로 검증해보고, scheduler.step() # step_size = 30이 되면 lr에 gamma를 곱해준다.

추가 보충
step_size를 조절해주는 것 말고도 설정이 가능하다.
- 사용법
optimizer = optim.Adam(model.parameters(), lr = 0.01) scheduler = ReduceLROnPlateau(optimizer, 'min') for e in epochs: train()... valid_loss = valid().. scheduler.step(val_loss)
- optimizer이 onplateau(평지대) 상태에 도달하면, 즉 0에 가까워 지면, lr를 떨어 트려라!
'min'은 patience = 10 즉, 10번을 반복할 동안 loss가 안 줄어 들면 lr를 떨어 트린다.

