None과 np.NaN 차이
🤔 결측치를 표현할 때 None과 NaN이 있다. 문제를 풀면서 둘의 차이를 모른다는 것을 깨달았다. 그 둘은 어떤 차이가 있을까?
🔎 NaN
- 정의 : Not a Number, 값이 없다
- 타입 : float
- 표현 방법 : 1) np.nan 2)float('nan')
🔎 None
- 정의 : python에서의 존재하지 않음(null) 의미
- 타입 : NoneType
- 종류 : 비어있는 list, dictionary, set, string, 0 ,False가 해당
차이점
1) 일단 파이썬에서 둘은 다르다고 인식해서 비교연산자를 넣었을 때 False가 나온다.
2) NaN는 float 타입이기 때문에 수치계산이 가능하고, None은 계산이 불가능하다.
np.isnan(np.nan)
>>> True
np.isnan(None)
>>> False
print('np.nan +10=", np.nan +10)
>>> np.nan +10= np.nan
print('None +10=", None +10)
>>> Type Error3) None은 동일한 id를 가지기 때문에 ==에서 True가 나오지만, NaN은 각각의 float를 생성해서 == 에서 False가 나온다.

+pd.NA
판다스에서 따로 제공하는 결측치로 np.NaN과 None 과 다르게 interger(정수) 타입의 강제 형변환을 방지하기위해 사용된다. np.NaN과 None는 자동으로 타입이 float로 변경하는 이슈가 있다.
isnull(), isna() 등 결측치를 찾는 함수에서 True로 반환한다.
- type : pandas.libs.missing.NAType _return NA
all( ) 과 any( )의 차이
🤔 어떤 함수인지는 알겠는데, 헷갈려
all( )
: 인자로 받은 모든 요소가 True이면 True를 반환 | 하나라도 False이면 False 반환
다 True 여야 True
- 조건 : 반복가능한 자료형(이터러블) [리스트, 튜플, 딕셔너리 등 for문 사용이 가능한 자료형] 을 받는다.
def all(iterable):
for element in iterable:
if not element:
return False
return Trueany( )
: 인자로 받은 요소 중 하나라도 True이면 True를 반환 | 모든 요소 False이면 False 반환
하나라도 True면 True~
인자로 받은 요소가 비어있으면 Flase
def any(iterable):
for element in iterable:
if element:
return True
return False🔎 any와 all의 함수의 경우 단순하다는 장점이 있으며, generator이다. 처리해야 할 값이 클수록 적용할 때 시간이 오래걸리는 이슈가 있는 듯하다.
추가) what is generator?
제너레이터
- 정의 : 여러 개의 데이터를 미리 만들어 놓지 않고 필요할 때마다 즉석해서 하나씩 만들어낼 수 있는 객체 / iterator를 생성해주는 함수 출처
객체를 호출할 때마다 yield (yield : 함수를 잠깐 중단하고 코드 실행을 함수 밖에 양보)가 작동하여 값은 순차적으로 산출 ➡️ yield를 사용하면 yield 값은 변수를 지정하고, 그 함수는 제너레이터가 됨 ➡️ 제너레이터는 이터레이터를 생성하는 함수!
- 이터레이터는 클래스에
iter,next또는getitem메서드를 구현해야 하지만, 제너레이터는 함수 안에서 yield라는 키워드만 사용하면 끝. ➡️ generator는 iter를 사용할 필요없이 바로 next로 yield 값을 함수 밖으로 산출 ➡️ 그래서 제너레이터는 이터레이터보다 훨씬 간단하게 작성할 수 있다. (yield로 생성된 제너레이터는 이미 iter와 next를 갖고 있는 것을generator_func()로 확인할 수 있다.)
함수의 return과 제너레이터의 yield의 차이점은 return은 함수가 호출되면 값을 반환하고 함수를 종료시키지만, yield는 함수 내부에서 함수 외부로 값을 순차적으로 전달해 준다는 점입니다. 뿐만아니라 send함수를 통해 mianroutine에서 값을 받아와 양방향 통신도 할 수 있습니다.
➡️ 제너레이터는 제너레이터의 객체(함수)가 호출되었을 때, yield 오른쪽의 값을 반환하고 바로 다음 yield의 위치를 기억한 상태로 다음 제네레이터 호출(실행 양보)을 기다린다.
def number_gen():
yield 0
yield 1
yield 2
for i in number_gen():
print(i)
>>> 0
1
2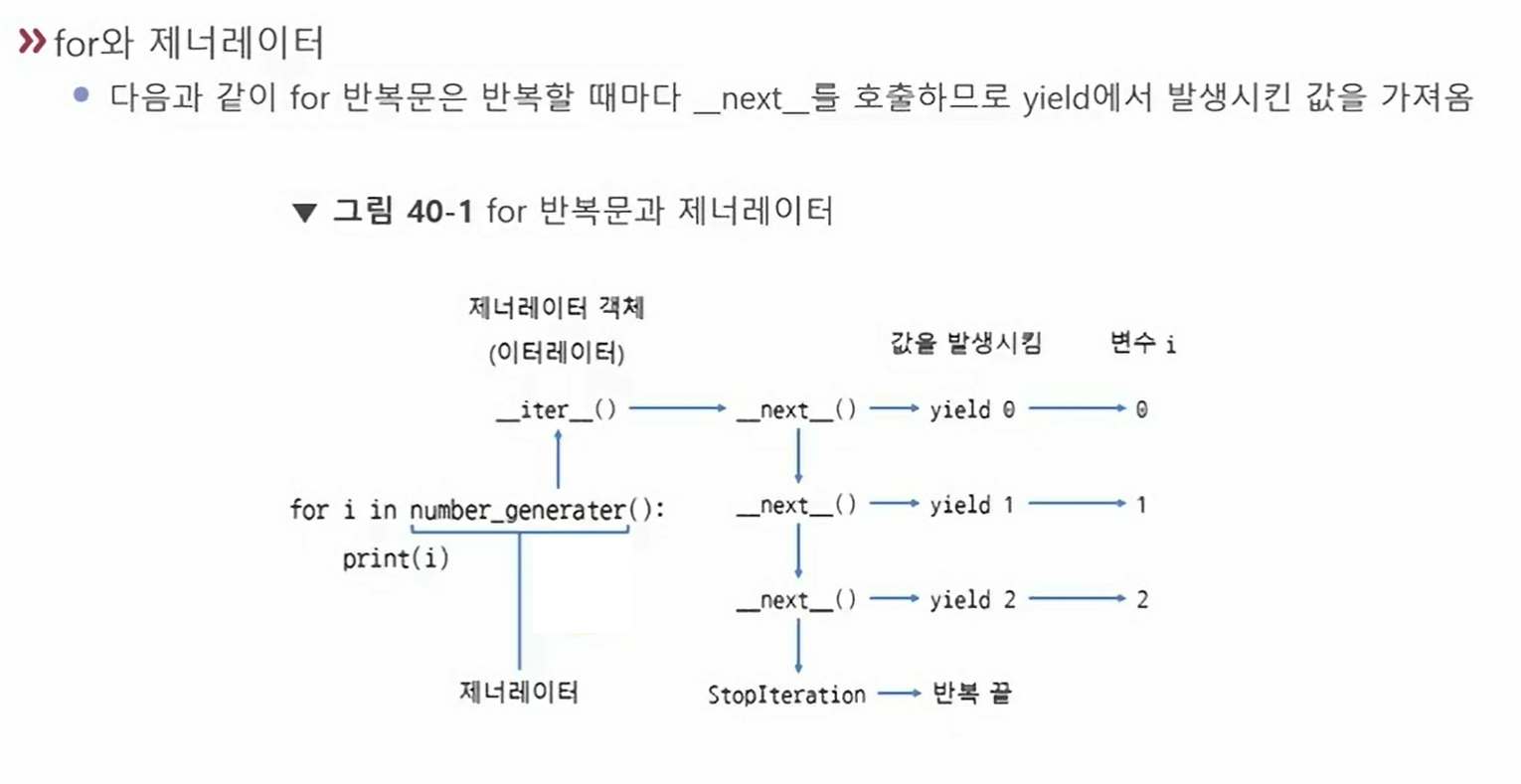
generator를 사용해 iterator를 만들면 메모리 효율성이 좋다.
제너레이터로 이터레이터를 만들지 않으면 선언과 동시에 메모리 소모
제너레이터를 통해 이터레이터를 생성하면 다음 순서를 기억한 상태로 객체가 생성, 호출하기 전까지는 모든 값을 메모리에 올리지 않는다. ( = 지연평가) 좀더 공부해보기
리스트 컴프리헨션보다 제너레이터의 메모리 효율성이 높다
제너레이터의 경우 모든 값의 순서를 기억한 상태로 작동되기 전까지 메모리에 할당하지 않지만, 리스트 컴프리헨션은 작동되는 순간 모든 값이 메모리에 올려버린다.
