📗 빅데이터를 통찰하는 힘 : 실무활용 편
5장 통계 분석방법의 총정리와 사용 순서
통계학의 이해도를 높여주는 단 한장의 도표

덧붙여 t검정은 '두 값의 설명변수를 하나만 사용한 다중회귀분석이나 마찬가지인 것처럼, z검정이나 카이제곱검정 역시 '두 값을 설명변수를 하나만 사용한 로지스틱 회귀분석'과 완전히 동일한 결과를 얻는다. 310쪽
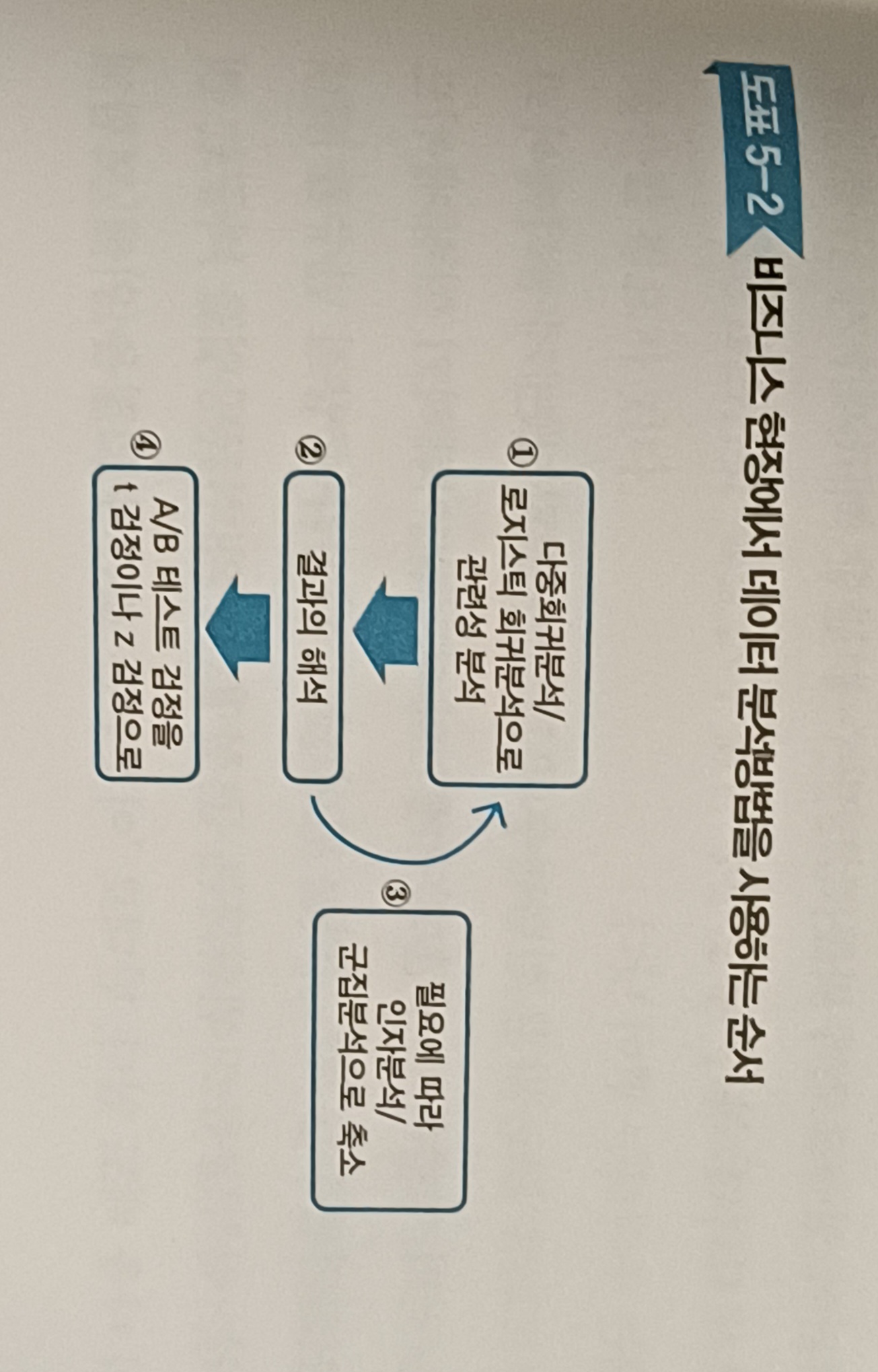
비즈니스에서 활용하는 경우 분석 순서
-대략적인 데이터의 정리와 확인이 끝나면,
-그 중 최대화 혹은 최소화해야 할 아웃컴이 무엇인지 정한 다음
-설명변수 후보에 모든 항목을 올려놓고(혹은 변수선택법으로 선택) 다중,로지스틱 회귀분석 진행
-대부분 석연찮은 결과가 나올 것이다. 이제부터 설명변수를 선별 선택하여 문제를 해결한다.
-설명변수의 선택선별과 결과해석이라는 시행착오를 거치는 과정에서 인자분석이나 군집분석을 사용하면 적절한 결과를 얻는데 큰 도움이 된다.
예를 들어,
'다른 설명변수의 값이 동일하다는 가정 하에서'라는 식의 영향이 특정한 회귀계수의 해석을 이해하기 어렵게 만드는 설명변수는 제외시키는 편이 낫고, 나이라는 양적 변수를 세대라는 질적 분류로 변환하는 등 설명변수의 취급방법을 바꾸는 것이 나을 때도 있다. 312쪽
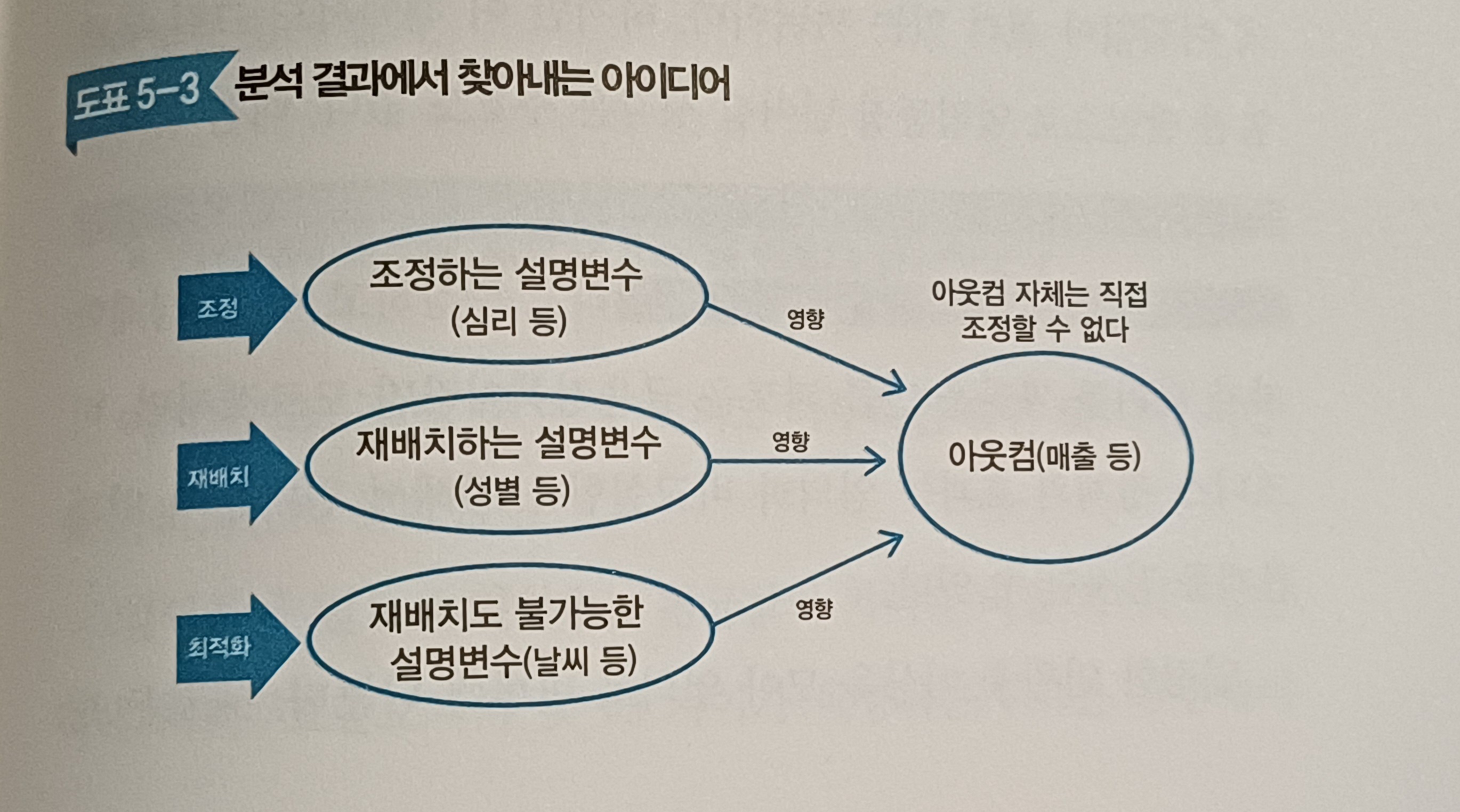
분석 결과에서 아이디어를 찾아내는 세 가지 방법
1) 아웃컴과 관련된 설명변수가 광고나 상품 생산, 연수 등에 의해 '조정이 가능하다면 그 설명변수를 조정하는 것이 이익을 낳는 아이디어가 된다.
가급적 회귀계수를 바탕으로 '설명변수를 조정하여 얼마만큼의 영향력이 있는지'를 대략적으로나마 계산할 필요가 있다.
(예) 브랜드 신뢰할 수 있다 응답자가 연간 구매금액이 1만엔 높아진다. 신뢰하지 않다 응답자를 브랜드를 신뢰하게 만들기만 해도 매출을 올릴 수 있는 여짖가 있다.
2) '조정'할 수 없는 설명변수와 아웃컴 사이의 관련성이 발견되는 경우에 재배치의 가능성도 있다.
(예) 여성의 구매금액이 높을 때 개개인의 성별은 바꿀 수 없어도 방문자 비율을 바꿀 수 있다. (여성의 비율이 80%인 매장 만들기 지향)
3) 조정도 재배치도 불가능한 설명변수는 예측 및 최적화 하여 비용삭감이 가능하다.
(예) 날씨와 계절에 맞춰 재고, 구입, 생산 상태를 예측하고 최적화 한다.
315쪽
마지막에는 임의화 비교실험이나 A/B테스트로 검정
통계학에서 어려운 부분이 '상관과 인과를 혼동하지 않는' 것이다. 필자는 '이익이 될 것 같은 아이디어를 찾았으면 적절한 임의화 비교실험 또는 A/B 테스트를 통해 검정합시다'라고 주장하고 싶다.
어느 정도의 데이터 수가 필요한가
현재 아웃컴의 표준편차로부터 생각하여 '어느 정도의 데이터 수가 필요한가'라고 계산하는 것이 임의화 비교실험에서 표본 크기를 설계하는 방법이다.
(예)
-예상되는 차이의 3분의 1로 표준오차를 설정하고 싶을 때
-원시 데이터의 표준 편차를 예상되는 차이로 나눈 값을 제곱하고
-그 36배의 계산을 통해 전체 데이터의 수를 구하며 이를 반반씩 나누어 각 그룹의 표본 크기로 계산한다.
예를 들어 객 단가를 1000엔 상승시킬 것으로 예상되는 방법에 대해 임의화 비교실험을 하고 싶은 경우 본래 객단가의 표준편차가 5000엔이라면 (5000/1000)의 제곱 X 36=900명이라는 데이터 수가 구해지고, 이것을 반반씩 나눈 수의 450명이 한 그룹에 해당하는 데이터 수이다.
318쪽
이 책 이상으로 공부해야할 부분
1) 회귀모형에 의한 아이디어 탐색단계에서 '시간적인 요소'를 분석할 수 있게 되었다는 것
🔍 생존분석, 콕스회귀분석, 하자드비
🔍 시계열분석, 자기상관
2) 잠재적 인자 간의 관계성이 중요할 때도 있다.
🔍 구조방정식모형 : 직간접을 불문하고 변수 사이의 다양한 관계성을 명백히 하는 분석방법
🔍 항목반응이론
🔍 군집분석의 개량
3) 임의화 비교실험 검정의 발전
🔍 통계적 인과추론 - 주변구조모형
