

[DG times] 뉴스 검색 및 분석 사이트

"키워드 기반의 빠르고 간편한 뉴스 검색 및 분석 서비스" DG times 입니다
🐨 빠르고 간편한 뉴스 검색이 왜 필요할까요?
최근 기술의 발전으로 우리는 쉽게 뉴스를 접할 수 있습니다. 그러나 접할 수 있는 뉴스가 너무 많기 때문에 우리가 원하는 자료를 찾가 어렵습니다. 따라서 우린 찾고자 하는 키워드를 입력하면 관련된 뉴스를 신속 정확하게 제공해주는 서비스를 구현했습니다.
🐨 DG times 개발팀은 DG times를 어떻게 구현했나요?
📌 Full Text Index를 활용하여 빠른 키워드 검색 구현
-
LIKE %keyword% 방식의 키워드 검색은 Index를 타지 않아 느림
-
Full Text Index를 도입하여 검색 성능 향상(18s → 0.8ms)
📌 Redis를 활용한 캐싱으로 분석 결과 응답 구현
-
뉴스 분석은 초, 분 단위의 변화로 결과 값에 영향을 주지 않고 반복되는 계산은 서버에 부하 발생
-
Redis에 캐싱하여 응답 속도 향상(4s → 0.43ms) 및 부하 해소
📌 Main - Replica 구조를 활용하여 Database 부하 분산
-
특정 시간대(오전 11시 ~ 오후 1시) 뉴스 조회 요청과 뉴스 주입 요청이 몰려 트래픽 부하가 심함
-
DB를 Main - Replica 구조로 이분화하여 DB 부하를 분산시켜 성능 향상
📌 Word2Vec을 활용하여 빠르고 정확하게 연관 키워드 분석
-
연관 키워드 분석을 위해 키워드 간의 유사도 분석이 필요
-
Word2vec 모델을 사용하여 뉴스 내의 키워드 간의 유사도 분석 진행
📌 Rabbitmq & Scheduled를 활용하여 배치 처리 방식으로 뉴스 데이터 수집 성능 향상
-
Full Text Index 매핑으로 데이터 개별 삽입은 많은 시간이 소요되며 일괄로 처리하는 것이 성능이 더 좋음
-
Rabbitmq로 뉴스 데이터를 모아 Scheduled를 사용하여 일정 시간마다 배치로 일괄 처리
📌 ALB를 활용하여 오토스케일링 방식으로 유동적인 트래픽에 효율적으로 대응
-
한국언론진흥재단에 따르면 하루 뉴스 조회 요청 최대 최소 트래픽 차이가 약 5배 차이가 난다고 함
-
효율적인 인프라 관리를 위해 ALB의 오토스케일링 기능 도입
🐨 시스템 구조도
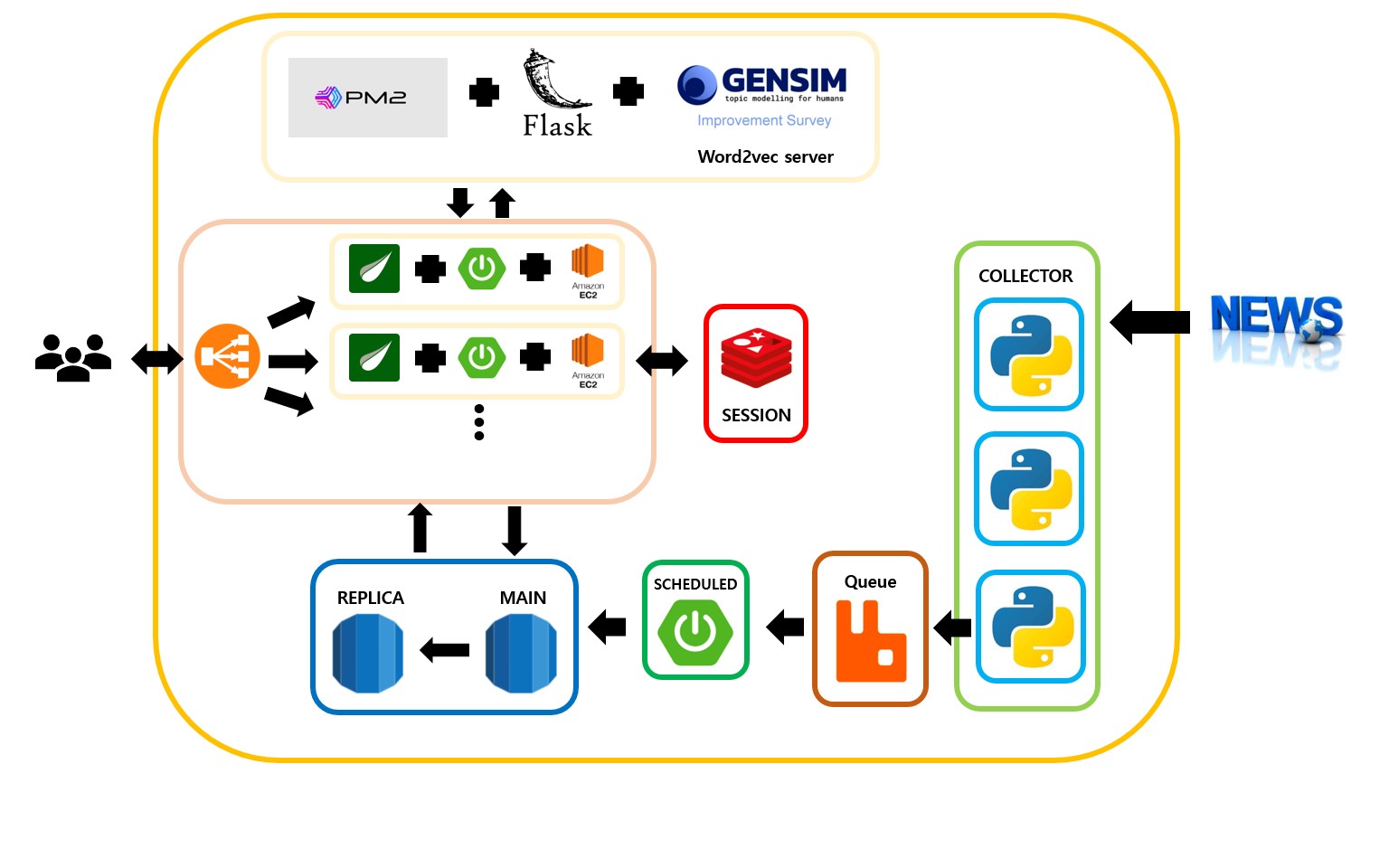
🐨 설계 고려 사항
서비스 목표치 계산 : 300만건의 데이터 & 1~2초 내 반환
- 하루 뉴스 생산량

한국 언론 진흥 재단에서 작성한 기사를 보면 하루에 뉴스가 약 6만 건이 생산된다고 한다. 이를 1년 기준으로 계산하면 약 2천만 건이며 5년 간 약 1억 건의 데이터가 생산된다.
뉴스 데이터의 제목이 최대 100자, 본문이 최대 1000자라고 가정하면, 한 건의 뉴스 데이터 당 약 100 + 1000bytes가 필요로 하며 1억 건의 데이터를 저장하기 위해선 최소 110GB가 필요하다.
현재 개발 단계에서 1억 건 데이터 수집 및 저장을 하기 어렵기 때문에 약 300만 건의 데이터로 프로토 타입을 제작한다.
- 서비스 최소 응답 시간

https://www.nngroup.com/articles/response-times-3-important-limits
위 블로그 글은 약 30년 간 웹 개발을 한 해외 개발자가 정리한 글로 사용자가 응답 시간 별로 느끼는 만족감에 대해 정리한 글이다.
가볍게 해석하면 사용자는 1초 ~ 10초 까지 견딜 수 있으며 10초가 넘어가면 이탈율이 급증한다는 것이다. 따라서 우리는 뉴스 검색은 1초 ~ 2초, 뉴스 분석은 3초 ~ 5초 사이로 결과가 반환되도록 한다.
서버 부하 분산을 위한 AWS ALB & Redis 도입
- 시간대별 많이 본 뉴스 배출 실적
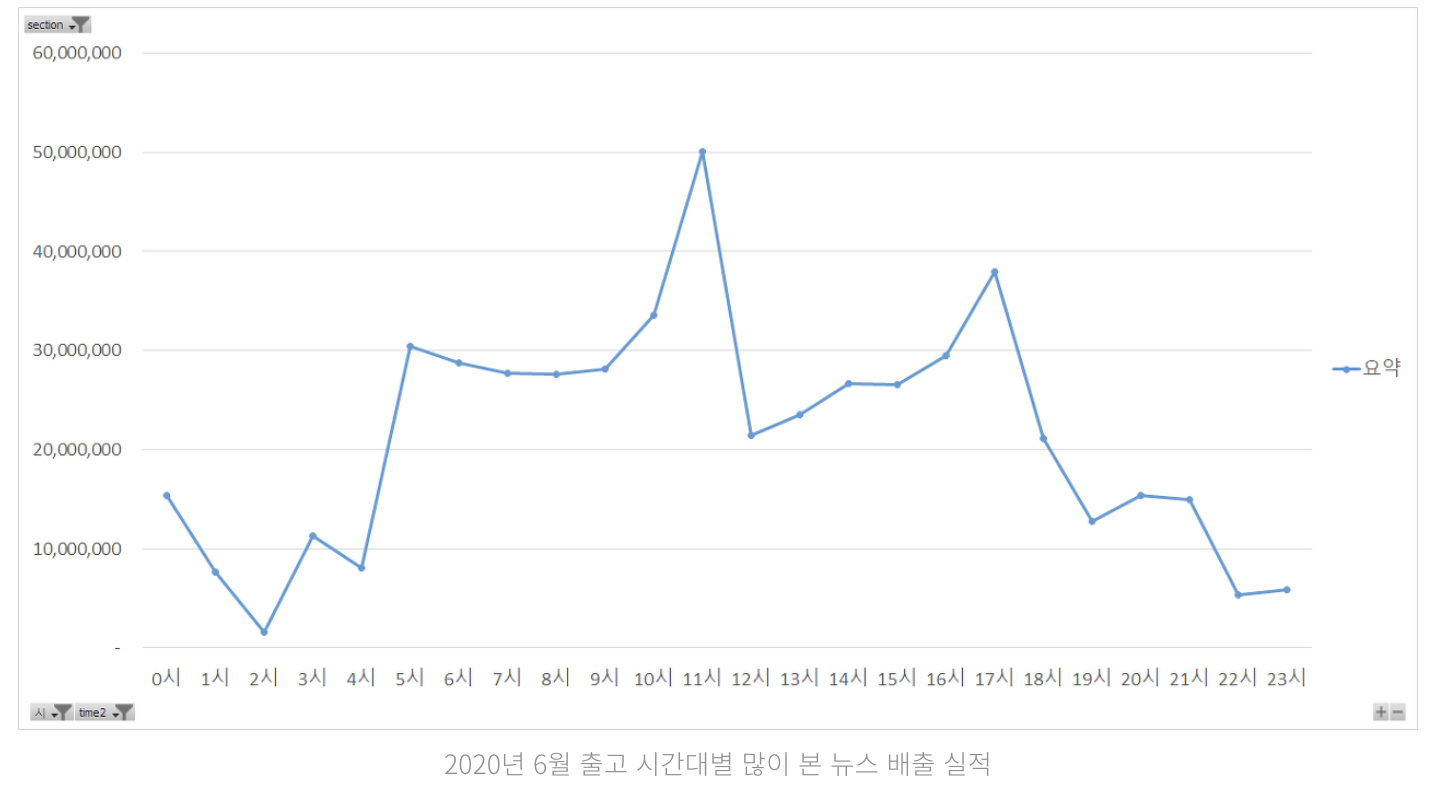
위 그래프는 한 기자 분이 빅카인즈 데이터를 토대로 블로그에 정리한 글로 최대 조회 실적과 최소 조회 실적이 약 5배 가량 차이나는 것을 볼 수 있다. 그리고 특정 시간대(10시 ~ 11시, 16시 ~ 17시)가 매우 높고 그 외 시간대는 낮은 것을 볼 수 있다.
이를 토대로 실제 조회 트래픽도 이와 유사하다고 가정했을 때, 트래픽이 몰리는 시간대와 그 외 시간대의 차이가 크다고 볼 수 있다. 따라서 이에 맞게 컴퓨터 자원을 효율적으로 사용하기 위해 로드밸런서 & 오토 스케일링을 구축하고 세션 기반의 인증 로직을 구현할 것이기 때문에 공유 세션으로 Redis를 사용하고자 한다.
데이터베이스 부하 분산을 위한 Main - Replica 도입
- 2017년도 JTBC 뉴스 자료
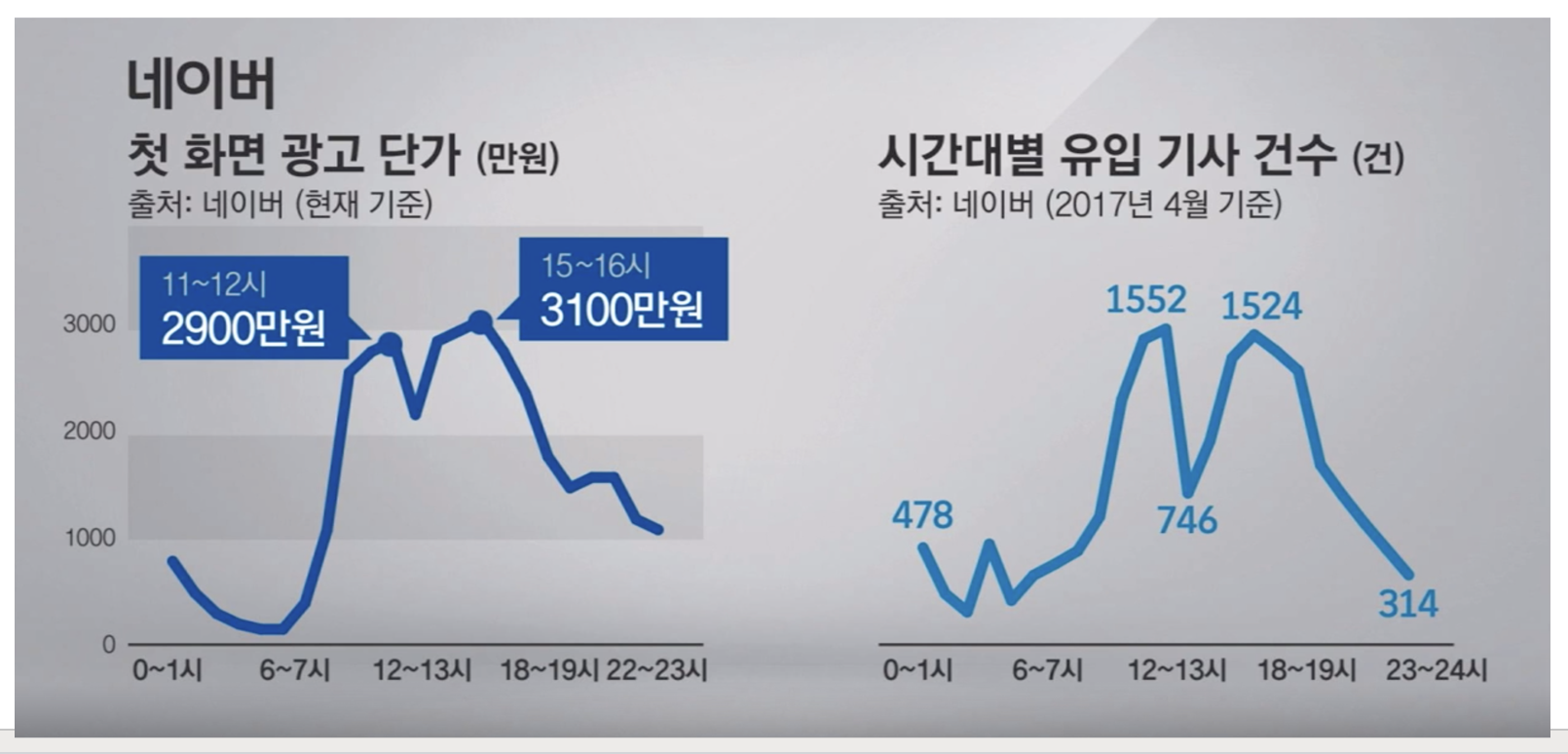
위 자료를 보면 네이버 광고 단가 와 뉴스 유입 기사 건수 그래프 형태가 거의 일치하는 것을 볼 수 있다. 네이버 광고 단가는 사용자 조회와 큰 관련이 있는데 이를 토대로 신문 기사의 유입 건수와 사용자 조회 수량이 비례한다고 볼 수 있다.
즉 데이터베이스에 읽기 요청과 쓰기 요청이 특정 시간대에 한꺼번에 몰릴 것으로 예상되며 이를 위해 Main - Replica 구조로 데이터베이스를 이중화 하여 구현하고자 한다.
뉴스 데이터 수집 성능 향상을 위한 Rabbitmq & Scheduled 배치 처리
- Insert vs Bulk Insert
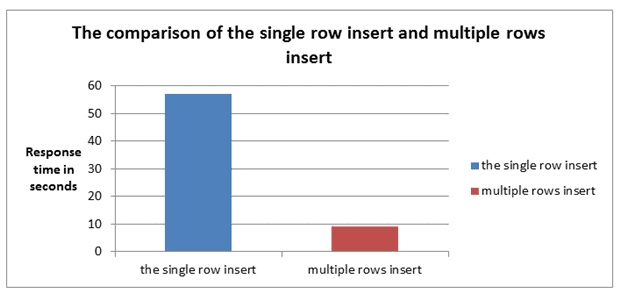
위 표는 Insert와 Bulk Insert의 성능을 비교한 표다. 이 자료에 따르면 단일 Insert 처리보다 Bulk Insert가 성능이 약 5배 정도 더 뛰어나다. 따라서 뉴스 데이터를 Rabbitmq로 모아서 특정 시간 마다(1초 or 10초) Bulk Insert를 하도록 구현한다.
🐨 프로젝트 관리
지속적인 배포(CD)
- 지속적인 배포의 필요성
- 기능이 추가될 때마다 배포해야하는 불편함이 있어 배포 자동화의 필요성 인식
- 대안
Jenkins Github Actions 무료 일정 사용량 이상 시 유료 서버 설치 필요 클라우드가 있으므로, 별도 설치 필요 없음 작업 또는 작업이 동기화되어 제품을 시장에 배포하는데 더 많은 시간이 소요 비동기 CI / CD 달성 계정 및 트리거를 기반으로하며 Github 이벤트를 준수하지 않는 빌드를 중심으로 함 모든 Github 이벤트에 대한 작업을 제공하고 다양한 언어와 프레임워크를 지원 전 세계 많은 사람들이 이용해 문서가 다양 젠킨스에 비해 문서가 없음 캐싱 메커니즘을 지원하기 위해 플러그인 사용 가능 캐싱이 필요한 경우 자체 캐싱 메커니즘을 작성해야함 - 선택
- Jenkins가 Github Actions에 비해 별도의 서버 설치가 필요하는 등 인프라 세팅이 까다롭긴 하나 무료이고 다양한 기능들을 제공하기 때문에 선택했음
코딩 컨벤션
코딩 컨벤션의 필요성
정해진 규칙없이 협업을 하다보니 팀원 들의 코드를 이해하기 어려웠고 Git에서 Merge할 때 어려움이 있어서 코딩 컨벤션의 필요성 인식
코딩 컨벤션의 장점
- 정해진 규칙이 있기 때문에 명칭이나 구조를 빠르고 정확하게 정할 수 있다.
- 통일된 규약이 있기 때문에 모든 사람들이 코드를 이해하기 쉽고 편리하다.
- 유지보수 비용을 줄일 수 있다.
최종 컨벤션
/*
설명 : 유저 클래스를 구현햇습니다.
- save() 이함수는 뭐를 저장합니다.
작성일 : 2022.00.00
마지막 수정한 사람 :
Todo > 차후 이름을 반환하기 위한 함수를 구현해야 합니다.
- 뭘 구현해야 한다.
*/
// Controller
@RequirementContructure
class ObjectController(){ // Object는 다루는 Model 이름으로
// 의존성 주입은 무조건 final
private final ObjectService objectService;
/* DTO -> Model은 무조건 서비스에서 */
public ResponseEntity<ResponseDto> methodName(RequestDto requestDto){
..
return new ResponseEntity(responseDto, HttpStatus.OK)
}
}
// Service
class ObjectService(){
public ResponseDto methodName(RequestDto requestDto){
Model model = requestDto.toModel()
// Model model = this.DtoToModel(requestDto)
..
return new ResponseDto(model);
}
}
//Lombok -> Setter 제외, 필용한 경우에는 직접 구현
@Getter
@No```
@All```
@Entity
class DTO or Model(){
}
/*
dto naming -> ObjectRequestDto & ObjectResponseDto
*/
// 예외발생 시, if else, try catch
// -> throw new RuntimeException()
// 에러는 상속 받아서 케이스에 맞게 만들겁니다.
// 만약 keyword가 중복이다,
// -> throw new BookmarkDupl();
규칙 1. **한 메서드에 오직 한 단계의 들여쓰기만 한다**
// 한 메소드에 한 단계의 들여쓰기만 한다.
// 만약 추가 예외처리나 반복문이 발생할 경우, 별도의 메소드로 분리한다.
// Before
public void valid(){
for(int i = 0; i < 10; i++){
if(i == 5){
System.out.println("5");
}
}
}
// After
public void valid(){
for(int i = 0; i < 10; i++{
checkFive(i);
}
}
public void checkFive(int value){
if(value == 5)
System.out.println("5");
}규칙 2. **else 예약어를 쓰지 않는다**
// else 예약어를 쓰지 않는다.
// 불 필요한 분기문과 지역 변수를 줄일 수 있다.
//Before
public boolean isFiveOrTen(int value){
boolean result;
if(value == 5){
result = True;
}else if(value == 10){
result = True;
}else{
result = False;
}
return result;
}
//After
public boolean isFiveOrTen(int value){
if(value == 5){
return True;
}
if(value == 10){
return True;
}
return False;
}규칙 3. **모든 원시값과 문자열을 포장한다**
// 모든 파라미터와 아규먼트는 포장, 즉 객체로 만들어서 반환해야 한다.
// 다만 모든 메소드에 적용하기 어렵기 때문에, 계층 간의 이동,
// Controller -> Service 또는 Service -> Controller 등, 다른 계층에서 호출하는 메소드 경우에만 적용한다.
// Before
public void findObjectService(String filter, String sort){
}
// After
public class Condition(){
private String filter;
private String sort;
}
public void findObjectService(Condition condition){
}
규칙 4. **한 줄에 점을 하나만 찍는다**
// 한 줄에 점 하나만을 찍는다.
// Java 8 부터 Stream이 생겼고, 그 외에도 method chain pattern으로 구현된 메소드를 사용할 경우,
// 점을 사용하고 무조건 줄을 바꿔준다.
// 원래는 점을 찍을 경우, 많은 메소드를 호출해서 의존성을 높힌다.
// 따라서 원래 이 규칙의 목표는 최대한 . 을 찍지 말자!! 이다.
// 즉 객체를 메소드를 통해서 타고 다니지 말란거다.
// Before
public void test(){
new A().setint(10).setfloat(20).display();
}
// After
public void test(){
new A().setint(10)
.setfloat(20)
.display();
}규칙 5. **getter/setter/property를 쓰지 않는다**
// 이 규칙은 DTO나 Cotroller 등에서는 제외한다.
// getter & setter을 써선 안된다. 왜냐하면 객체 지향의 핵심은 바로 메시지 전송이다.
// getter를 통해 데이터를 가져와서 로직을 수행하면, 객체의 역할이 제대로 분배되지 않은 것이다.
// 따라서 getter를 최대한 지양한다. 다만 데이터 전달을 목표로 하는 객체(DTO) 등에서는 구현해야 한다.
// 단 Setter의 경우는 최대한 최대한 지양한다.
// Before
public void saveBenefit(Member member) {
if (VIP_DEPOSIT_AMOUNT.compareTo(member.getTotalDepositAmount()) > 0) {
throw new IllegalStateException("VIP 고객이 아닙니다.");
}
// ...
}
// After
public void saveBenefit(Member member) {
if (!member.isVip()) {
throw new IllegalStateException("VIP 고객이 아닙니다.");
}
// ...
}예시
우리가 가져갈 객체 체조
1,2,3,4,9 ← 입니다.
'프로그래밍/클린코드 & 리팩토링' 카테고리의 글 목록
- 예
public class filterDto(){ filters filters; 조건 조건; public filterDto (String filter,String sort,String word,String minPrice,String maxPrice){ validFilter(filter); validFilter(filter); filter = validFilter(filter); filter = validFilter(filter); filter = validFilter() } } public class filters(){ String filter; String sort; public validFilter(String filter){ if (filter == "") { this.filter = null; this.filter = filter } // sort public validFilter(String filter){ if (filter == "") { this.filter = null; this.filter = filter } } public class 조건(){ String word; Price price; // word public validFilter(String filter){ if (filter == "") { this.filter = null; this.filter = filter } } public class price(){ String minPrice; String maxPrice; public validFilter(String maxprice){ if (filter == "") { this.filter = null; this.filter = filter } public validFilter(String maxprice){ if (filter == "") { this.filter = null; this.filter = filter } } public class getStoreWithAllFilterService(){ // main logic public List<StoreResponseDto> getStores(filterDto) { // store list를 가져옵니다. List<Store> stores = getStoreList(filterDto); // DTO로 변환해서 반환합니다. return modelToDto(stores); } // 추가 로직 public List<Store> getStoreList(filterDto){ if(sort != null){ return sortValid(filterDto.getSort); } if(word != null){ return wordValid(word) } return storeRepository.findAllByOrderByIdDesc(); } public List<Store> wordValid(String word){ return storeRepository.findByStorenameIsContaining(word); } public List<Store> sortValid(String sort){ if (sort.equals("Desc")) { return storeRepository.findAllByOrderByIdDesc(); } if (sort.equals("Asc")) { return storeRepository.findAllByOrderByIdAsc(); } if (sort.equals("reviewAvg")) { return storeRepository.findAllByOrderByReviewAvgDesc(); } // 리뷰 갯수 순 if (sort.equals("reviewCount")) { return storeRepository.findAllByOrderByReviewCountDesc(); } throw RuntimeException("적절하지 않은 sort 양식입니다."); } public List<StoreResponseDto> modelToDto(List<Store> stores){ List<StoreResponseDto> result = new ArrayList<>(); for(Store store : stores) { // 가게 이미지 가져오기 List<StoreImageURL> storeImageURLS = store.getStoreImageURLS(); // 이미지 dto 매핑 List<StoreImageDto> storeImageDtos = addURLToDto(storeImageURLS); StoreResponseDto responseDto = new StoreResponseDto(store, averageReviewScore(store),reviewCount(store), storeImageDtos); result.add(responseDto); } } } public List<StoreImageDto> checkImgUrlSize(List<StoreImageURL> storeImageURLS){ validUrlSize(storeImageURLS.size()); // 사이즈 0 이하면 밑에는 무조건 0 이상 List<StoreImageDto> storeImageDtos = new ArrayList<>(); addURLToDto(storeImageURLS, storeImageDtos) return storeImageDtos; } public void addURLToDto(List<StoreImageURL> storeImageURLS, List<StoreImageDto> storeImageDtos){ for(StoreImageURL storeImageURL : storeImageURLS) { StoreImageDto storeImageDto = new StoreImageDto(storeImageURL); storeImageDtos.add(storeImageDto); } } public void validUrlSize(int size){ if(storeImageURLS.size() < 0){ throw new RuntimeException(); } } // test case1 /* queryString으로 값이 들어 왔을 때, ""이게 들어보면 null로 바꿔줘야 한다. @Test public void test1(){ String sort = ""; String result = validInputs(sort); assertEqueal(null, result); List<Store> stores = getStores } */
Git
- Git Commit 메시지 컨벤션의 필요성
- commit된 코드가 어떤 내용을 작성 했는 지 파악하려면 commit을 확인해야 한다.
- 프로젝트 진행 중에는 수 많은 코드가 commit되기 때문에 일일이 내용을 확인하기 힘들기 때문에
메시지 컨벤션을 통해서 제목이나 description을 통해서 commit의 정보를 전달한다.
- Git Commit 메시지 컨벤션 전략
**Feat : 새로운 기능에 대한 커밋 Fix : 기능에 대한 버그 수정에 대한 커밋 Build : 빌드 관련 파일 수정에 대한 커밋 Chore : 그 외 자잘한 수정에 대한 커밋(기타 변경)** Ci : CI 관련 설정 수정에 대한 커밋 Docs : 문서 수정에 대한 커밋 Style : 코드 스타일 혹은 포맷 등에 관한 커밋 Refactor : 코드 리팩토링에 대한 커밋 Test : 테스트 코드 수정에 대한 커밋
🐨 담당 트러블 슈팅
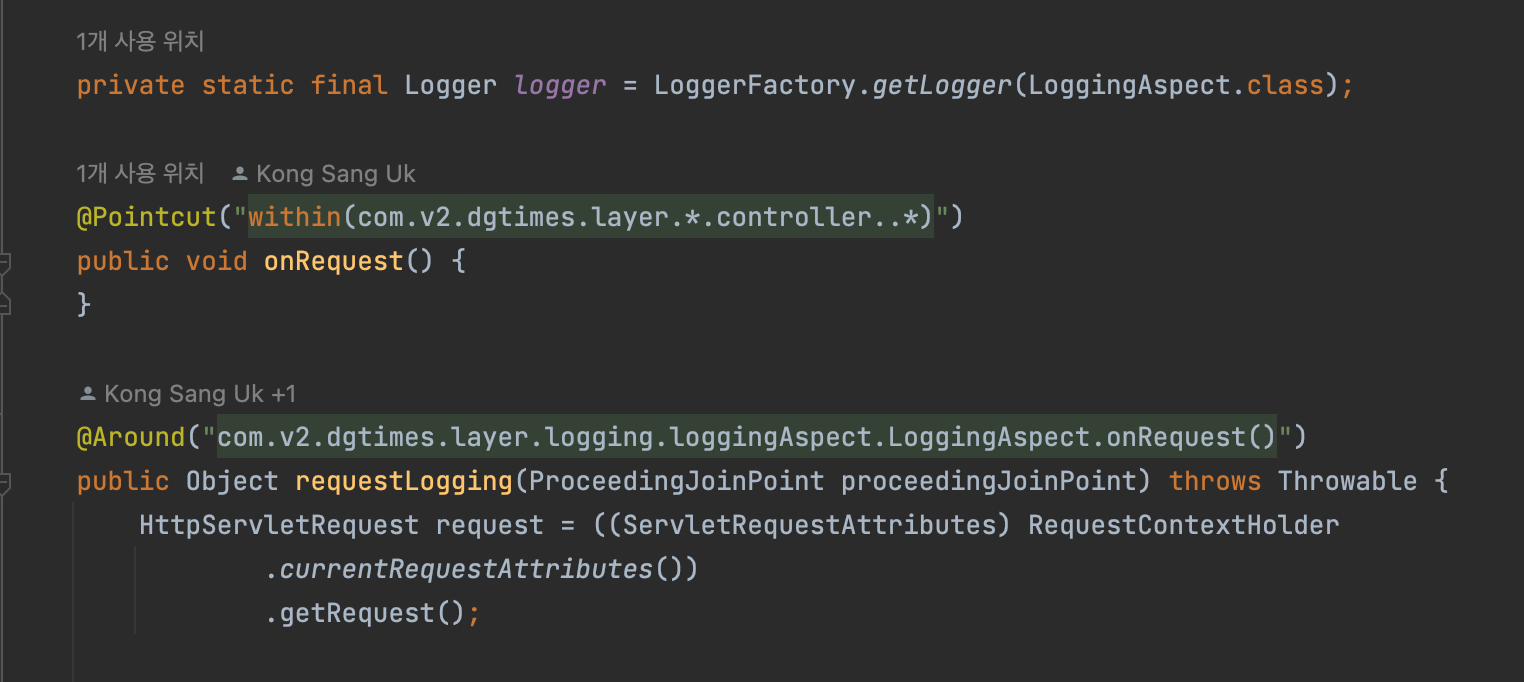
검색 로그 남기기 : AOP에 로그 구현하여 유지보수 및 코드 생산성 향상
🍀 도입 이유
유저의 키워드 검색 기록을 수집하여 통계 자료를 제공하기 위함
☘️ 문제 상황
로그를 남기려고 하는데 어느 곳에서 수집하는 것이 적절한가?
🍃 해결 방안
1. Filter 영역에서 검색 로그 수집(장단점)
2. AOP(interceptor) 영역에서 검색 로그 수집(장단점)
🍂 의견 조율
1번 장점 : Request / Response 조작이 가능하며, 모든 요청의 로깅이 가능하다.
1번 단점 : HTML / 이미지 모두 로깅을 하며, 컨트롤하기 까다롭다.
2번 장점 : 중복 코드 제거, 효율적인 유지 보수, 높은 생산성, 재활용성 극대화, 변화 수용의 용이
2번 단점 : 객체지향의 기본원칙을 지키면서 횡단관심사를 모듈화하는 것은 매우 어렵고, 코드의 복잡성을 증대시키는 단점이 있다.
🌷 의견 결정
Filter 영역은 Spring 영역에 들어오기 전에 동작하고 Request가 바이트 단위로 구성되서 휘발성이 있다. 따라서 잘못 처리하면 요청 자체가 날라가기 때문에 위험하며 AOP 영역에서는 Spring 영역의 도움을 받을 수 있어서 문자열 처리가 쉽기 때문에 AOP 영역에서 검색 로그 수집하기로 결정 했다.
AWS 로드 밸런서 & 오토스케일링 도입 : 시간 당 최대 요청 1만건, 최소 2천건 처리
🍀 도입 이유
로드밸런서 & 오토 스케일링 도입을 통해 합리적인 비용의 인프라 구축
☘️ 문제 상황
한국 언론 진흥 재단에서 작성한 블로그 글을 참고하면 하루 최대 최소 트래픽 차이가 약 5배이며 최대 트래픽 기준으로 인프라를 세팅하면 자원 낭비(돈)가 심함.
🍃 해결 방안
1. ELB(Elastic Beanstalk) 도입
2. ALB(Application Load Balancer) 도입
🍂 의견 조율
-
현재 별도의 RDB를 구축하여 사용 중임
-
ELB는 별도의 세팅없이 모니터링 및 오토스케일링 등의 기능을 제공하며 배포 난이도가 쉽다.
-
ELB는 배포할 때 전용 RDB가 생성되며 기존의 RDB를 쓸 수 없다.
-
ALB는 배포 난이도가 조금 어려우며 별도의 모니터링 및 오토스케일링 기능을 세팅해야한다.
-
ALB는 기존의 RDB를 쓸 수 있다.
🌷 의견 결정
ELB 경우, 새로운 서버를 배포할 때 마다 RDB를 새로 생성해야 한다. 따라서 기존 데이터베이스의 데이터를 옮기는 작업이 필요하다. 이는 매우 비용이 많이 든다. 따라서 우리는 기존의 데이터베이스를 재사용할 수 있는 ALB를 사용하기로 결정
Full Text Search 도입 : 조회 시간 18초 → 0.8초 개선
🍀 도입 이유
뉴스 키워드 검색 성능을 향상시키기 위해서
☘️ 문제 상황
LIKE % keyword % 쿼리 사용 시, index를 타지 않아 Full Table Scan이 발생하여 검색 성능이 좋지 않음
🍃 해결 방안
1. Mysql의 Full-Text Index를 사용
2. Elastic Search 사용
🍂 의견 조율
1번 장점 - 학습 비용이 낮다.
1번 단점 - 유사도 검색 등 검색 성능을 높히기 위해선 테이블 & 쿼리 복잡도가 높아진다.
2번 장점 - 유사도 검색이나 메타 데이터 추가 등 검색 성능을 높히기 쉽다.
2번 단점 - 학습 비용이 높다.
🌷 의견 결정
데이터 1억 건의 경우, Mysql과 Elastic Search의 성능 차이가 크지 않다. 짧은 프로젝트 기간을 고려했을 때, Elastic Search의 학습 비용은 부담이 된다. 따라서 Mysql의 Full-text Index를 사용한다. 다만 차후 검색 로직 or 쿼리가 복잡해지면 Elastic Search로의 이전을 고려한다.
인덱스 생성


select * from news where title like '%뉴스%' and content like '%뉴스%';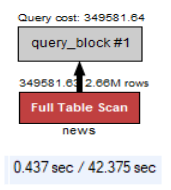
select * from news where match(title, content) against('뉴스' in boolean mode);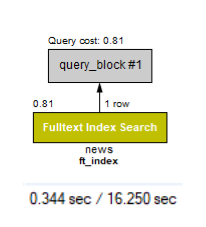
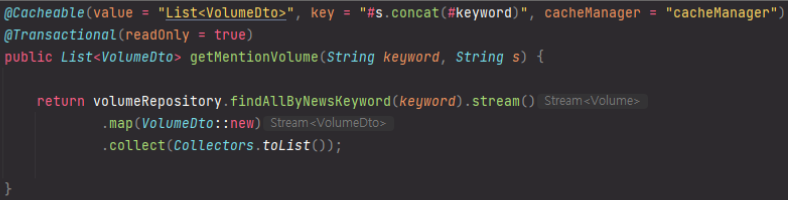
캐싱 전략 : 조회 시간 4초 → 0.382초 개선
🍀 도입 이유
검색 및 분석 기능의 Latency를 낮추기 위해 도입
☘️ 문제 상황
검색의 경우 1~2초, 분석의 경우 3~5초 내에 결과를 반환해야한다. 이때 반복적으로 DB에 값을 조회하거나 분석하여 성능이 저하됨
🍃 해결 방안
1. 쿼리 로직을 개선한다.
- 반복적인 데이터 결과물을 캐싱한다.
🍂 의견 조율
-
검색 결과 및 분석 결과는 초, 분 단위로 바뀌지 않는다.
-
검색 및 분석의 경우, 자원을 많이 소비한다.
🌷 의견 결정
검색 및 분석은 DB 및 서버에 부하를 많이 주기 때문에 세션 서버로 사용하고 있는 Redis를 활용하여 반복적인 검색 및 분석 결과를 캐싱하기로 결정
CacheManager

VolumeService
Database Main, Replica 라우팅 전략 : 시간당 최대 읽기 1만 건, 최대 쓰기 시간당 2500 건 동시 처리
🍀 도입 이유
효율적인 트랜잭션 관리 및 데이터베이스 부하 분산을 위함
☘️ 문제 상황
Main, Replica 구조를 도입했는데 트랜잭션 상황에서 별도의 커넥션이 잡혀서 영속성 컨택스트로 관리가 되지 않음
🍃 해결 방안
-
MainRepository & ReplicaRepository를 구축하여 상황에 맞는 Repository를 사용
-
ReadOnly=True 인 경우에만 ReplicaRepository를 사용
🍂 의견 조율
1번 장점
각 상황에 맞는 repository를 가져와 사용하므로 Connetion 객체 관련 오류가 줄어든다.
1번 단점
모든 Repository에 추가로 ReplicaRepository를 구축해야 하므로 Repository가 많아 질수록 코드관리에 어려움이 있다.
2번 장점
@Transational를 사용해 ReadOnly의 참/거짓에 따라 상황에 맞는 DB server와 연결되어 간편하다.
2번 단점
@Transational(ReadOnly=True)를 사용하면 쿼리문을 실행하기전 읽기 전용 Replica 서버의 Connection 객체를 확보하고 동작하기 때문에 중간에 읽기 이외의 쿼리문이 실행될 경우 오류가 걸린다.
🌷 의견 결정
Replica DB에 읽기 요청 외의 요청을 보내면 무시된다. 따라서 개발자가 SELECT 요청만 사용한다고 확신할 수 있는 경우, 즉 ReadOnly=True 인 경우에만 Replica DB를 사용한다.
DataSourceConfig
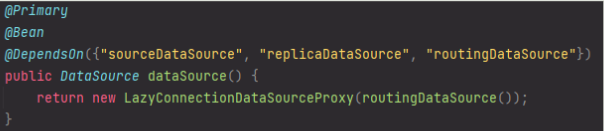
RoutingDataSource

NewsService

🐨 API 기술문서
- API 기술문서
목차
Base URL
Base URL : http://dgtimes.or.kr/api
News
GET /news
Method Request URI GET /news 요청 헤더
헤더명 설명 Content-Type application/json **요청 쿼리 스트링**
Name 설명 Type Requirement example keyword 검색을 원하는 키워드를 입력해주세요
중간에 “ “가 포함되면 안됩니다.String Required “뉴스” include 검색에 꼭 포함시켜야 할 키워드를 입력해주세요. 여러 키워드 입력 시, “,”로 구분해주세요 중간에 “ “가 포함되면 안됩니다. String Optional “정치,dgtimes” exclude 검색에 제외시킬 키워드를 입력해주세요 여러 키워드 입력 시, “,”로 구분해주세요 중간에 “ “가 포함되면 안됩니다. String Optional “연예,사회” 응답 바디
- 응답은 아래 속성을 가진 아이템들의 List로 반환됩니다.
Name 설명 Type Requirement example title 뉴스 제목입니다. String Required “’컬투쇼’,’오징어게임’차용해 …” content 뉴스 본문 내용입니다. String Required “’컬투쇼’가 넷플릭스 화제작 ‘오징어게임’을 차용한 …” writer 뉴스 기사 작성자입니다. String Required “작성자” publisher 뉴스를 발행한 언론사입니다. String Required “무슨일보” publishedDate 뉴스 발행 날짜입니다. String Required “2022 Jul 12” thumbnailUrl 뉴스 썸네일 주소입니다. String Required “https://pds.saram…” mainUrl 뉴스 본문 주소입니다. String Required “https://www.joyne…” category 뉴스 카테고리 정보입니다. Integer Required 1 **Example**
요청 **(cURL shell)**
Text curl --location --request GET '${Base URL}/api/news keyword=”뉴스”&include=”정치,dgtimes”&exclude=”연애,사회”' \ --header 'Content-Type: application/json' 응답 **(Json)**
Json [ { title : “’컬투쇼’,’오징어게임’차용해 …” content : “’컬투쇼’가 넷플릭스 화제작 ‘오징어게임’을 차용한 …” writer: “작성자” publisher : “무슨일보” publishedDate: “2022 Jul 12” thumbnailUrl : “https://pds.saram/…” mainUrl : “https://www.joyne/…” category: 1 }, {…}, {…}, ]
- 응답은 아래 속성을 가진 아이템들의 List로 반환됩니다.
# Bookmark
## GET /bookmark
| Method | Request URI |
| --- | --- |
| GET | /bookmark |
## 요청 헤더
| 헤더명 | 설명 |
| --- | --- |
| Content-Type | application/json |
## 응답 바디
| Name | 설명 | Type | Requirement | example |
| --- | --- | --- | --- | --- |
| include | 사용자가 이전에 등록한 포함 키워드 리스트 입니다. | String | Required | “정치,dgtimes” |
| exclude | 사용자가 이전에 등록한 제외 키워드 리스트 입니다. | String | Required | “연예,사회” |
## ****Example****
### 요청 ****(cURL shell)****
| Text |
| --- |
| curl --location --request GET '${Base URL}/api/bookmark \
--header 'Content-Type: application/json' |
### 응답 ****(Json)****
| Json |
| --- |
| {
include : [정치,dgtimes],
exclude : [연예,사회]
} |
# Search Ranking
## GET /search/ranking
| Method | Request URI |
| --- | --- |
| GET | /search/ranking |
## 요청 헤더
| 헤더명 | 설명 |
| --- | --- |
| Content-Type | application/json |
## 응답 바디
- 응답은 아래 속성을 가진 아이템들의 List로 반환됩니다.
| Name | 설명 | Type | Requirement | example |
| --- | --- | --- | --- | --- |
| value | 실시간 랭킹에 올라와있는 키워드 명입니다. | String | Required | “이정재” |
| isRankingUp | 이전과 비교했을 때, 랭킹이 상승했는 지 아닌 지를 나타냅니다.
”+” : 이전에 비해 랭킹이 상승했습니다.
”-” : 이전에 비해 랭킹이 하락했습니다.
”new” : 새로 랭킹에 추가된 키워드입니다.
null : 이전과 변동이 없습니다. | String | Required | “+” |
## ****Example****
### 요청 ****(cURL shell)****
| Text |
| --- |
| curl --location --request GET '${Base URL}/api/search/ranking' \
--header 'Content-Type: application/json' |
### 응답 ****(Json)****
| Json |
| --- |
| [
{
value : “오징어게임”
isRankingUp : “+”
},
{…},
{…}
] |
# Volume
## GET /volume
| Method | Request URI |
| --- | --- |
| GET | /volume |
## 요청 헤더
| 헤더명 | 설명 |
| --- | --- |
| Content-Type | application/json |
## ****요청 쿼리 스트링****
| Name | 설명 | Type | Requirement | example |
| --- | --- | --- | --- | --- |
| keyword | 분석을 원하는 키워드를 입력해주세요
중간에 “ “가 포함되면 안됩니다. | String | Required | “뉴스” |
| type | 키워드 언급량 요청인지, 키워드 검색량인지 알려주세요
”search” : 키워드 검색량 요청
”mention” : 키워드 언급량 요청 | String | Required | “search” or “mention” |
## 응답 바디
- 응답은 아래 속성을 가진 아이템들의 List로 반환됩니다.
| Name | 설명 | Type | Requirement | example |
| --- | --- | --- | --- | --- |
| date | 통계량 날짜 입니다. | String | Required | “2022-09-14” |
| count | 통계 수량입니다. | Integer | Required | 5 |
## ****Example****
### 요청 ****(cURL shell)****
| Text |
| --- |
| curl --location --request GET '${Base URL}/api/volume?keyword=”뉴스”&type=”search” \
--header 'Content-Type: application/json' |
### 응답 ****(Json)****
| Json |
| --- |
| [
{
date : “2022-09-14”
count : 5
},
{…},
{…},
{…},
] |
# Relation
## GET /relation
| Method | Request URI |
| --- | --- |
| GET | /relation |
## 요청 헤더
| 헤더명 | 설명 |
| --- | --- |
| Content-Type | application/json |
## ****요청 쿼리 스트링****
| Name | 설명 | Type | Requirement | example |
| --- | --- | --- | --- | --- |
| keyword | 분석을 원하는 키워드를 입력해주세요
중간에 “ “가 포함되면 안됩니다. | String | Required | “뉴스” |
| type | 뉴스 언급 기준인지, 뉴스 검색 기준인지 알려주세요
”search” : 뉴스 검색 요청
”mention” : 뉴스 언급 요청 | String | Required | “search” or “mention” |
## 응답 바디
- 응답은 아래 속성을 가진 아이템들의 List로 반환됩니다.
| Name | 설명 | Type | Requirement | example |
| --- | --- | --- | --- | --- |
| keyword | 연관 키워드 입니다. | String | Required | “국회” |
| value | 유사성 수치입니다. | Double | Required | 0.985144742105 |
## ****Example****
### 요청 ****(cURL shell)****
| Text |
| --- |
| curl --location --request GET '${Base URL}/api/relation?keyword=”뉴스”&type=”search” \
--header 'Content-Type: application/json' |
### 응답 ****(Json)****
| Json |
| --- |
| [
{
keyword : “국회”
value : 0.985144742105
},
{…},
{…},
{…},
] |
# Exception(차후 업데이트 예정)
## Bookmark
| Msg | Name | status | code |
| --- | --- | --- | --- |
| 빈 키워드 | BOOKMARK_KEYWORD_EMPTY_CODE | 400 | B001 |
| 로그인 되지 않음 | USER_LOGIN_NOT_CODE | 400 | U006 |
| 기존에 등록한 키워드 | BOOKMARK_KEYWORD_EXIST_USER_CODE | 400 | B002 |
| 금지된 키워드 | BOOKMARK_KEYWORD_FORBIDDEN_CODE | 400 | B003 |
## News
| Msg | Name | status | code |
| --- | --- | --- | --- |
| 키워드를 입력해주세요. | SEARCH_KEYWORD_EMPTY_CODE | 400 | S001 |
| 검색한 키워드 금지어입니다. | SEARCH_KEYWORD_FORBIDDEN_CODE | 400 | S002 |
| 검색된 뉴스가 없습니다. | SEARCH_NEWS_NOT_FOUND_CODE | 404 | S003 |
| 찾는 키워드의 검색 결과가 없습니다. | SEARCH_KEYWORD_NOT_FOUND_CODE | 404 | S004 |
## User
| Msg | Name | status | code |
| --- | --- | --- | --- |
| 유효하지 않은 아이디 길이 | ID_VALID_LENGTH_CODE | 400 | U001 |
| 유효하지 않은 아이디 형식 | ID_VALID_PATTERN_MATCHES_CODE | 400 | U002 |
| 유효하지 않은 비밀번호 길이 | PASSWORD_VALID_LENGTH_CODE | 400 | U003 |
| 비밀번호에 아이디 포함 | PASSWORD_CONTAIN_ID_CODE | 400 | U004 |
| 중복된 아이디 | ID_EXIST_USER_CODE( | 400 | U005 |
