

테이블 설계의 기초
정규형
정규형이란
데이터의 갱신이 발생한 경우에도 부정합이 발생하기 어려운 테이블의 형태.
제 1정규형부터 제 5정규형까지 있음.
제1정규형(1NF)
테이블 셀에 복합적인 값을 포함하지 않음, 스칼라(단일) 값 이외의 값을 포함하지 않는 테이블.
제2정규형(2NF)
제1정규화를 진행한 테이블에 완전 함수 종속을 만족하는 테이블.
부분함수 종속성이 있으면 제2정규형이 될 수 없음.
부부함수 종속성
기본키를 구성하는 열의 일부에만 함수 종속이 존재하는 것.
제3정규형(3NF)
제2정규화를 진행한 테이블에서 이행적 종속을 없애도록 한 테이블.
ER 다이어그램
너무 많아진 테이블을 어떻게 할까
정규화를 수행하면 테이블이 나누어져 그 수가 증가함. 어디까지나 갱신 이상의 위험을 없애는 것이 목적이지만, 결과적으로 테이블의 수가 늘어나는 것이 사실.
그래서 이런 테이블 간의 관련성을 한눈에 알 수 있게 고안된 기술이 ER 다이어그램. Entity Relationship, 즉 테이블 간의 관계를 의미.
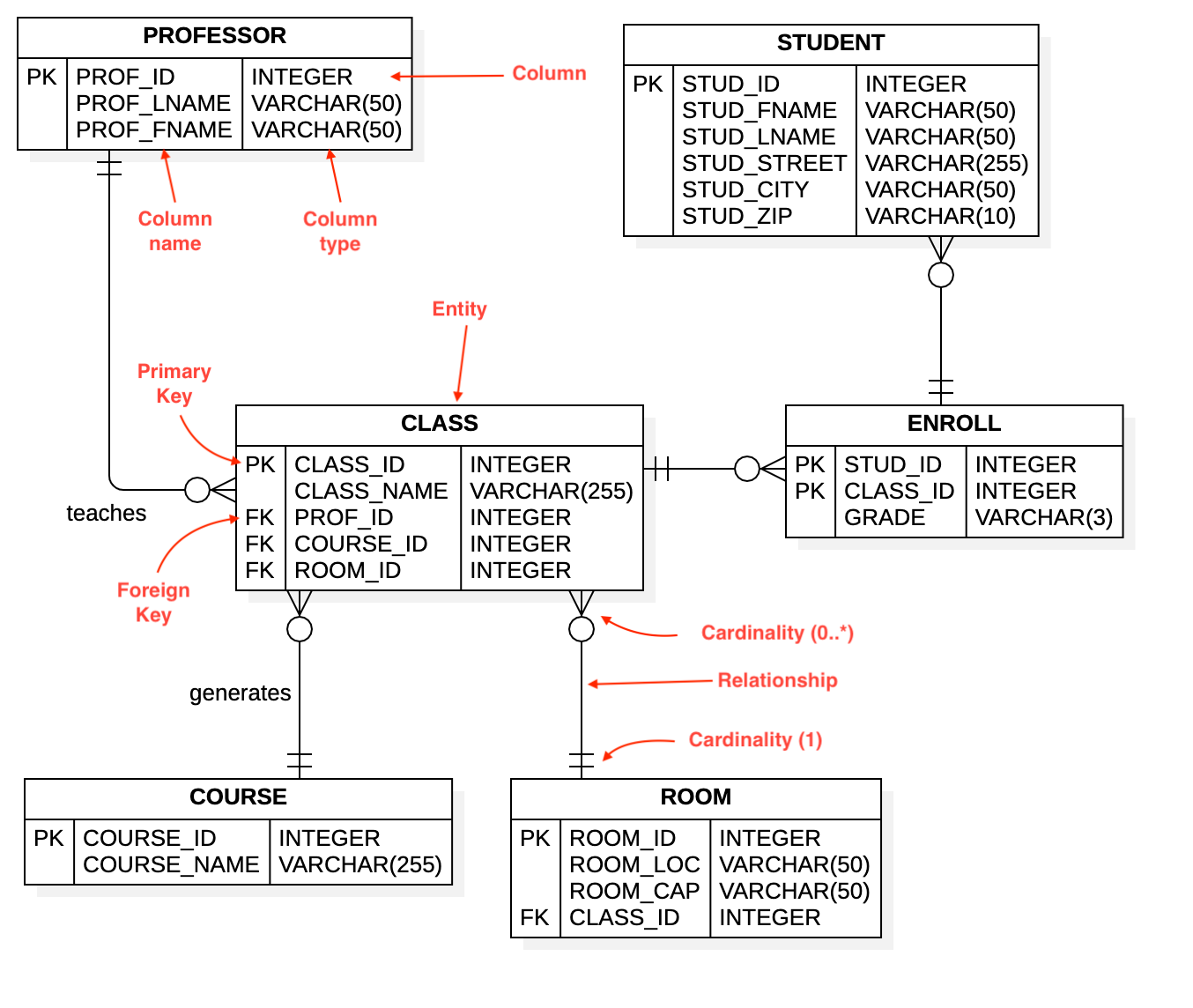
(이미지 출처 : https://docs.staruml.io/working-with-additional-diagrams/entity-relationship-diagram)
데이터베이스 객체 작성과 삭제
인덱스 구조
인덱스
테이블에 붙여진 색인. 인덱스의 역할은 검색속도의 향상. 책의 목차나 색인처럼 인덱스의 구조도 비슷함.
인덱스는 테이블과는 별개로 독립된 데이터베이스 객체로 작성. 하지만, 인덱스만으로는 아무런 의미가 없음. 인덱스는 테이블에 의존하는 객체로 테이블을 삭제하면 인덱스도 같이 삭제됨.
검색에 사용하는 알고리즘
데이터베이스의 인덱스에 쓰이는 대표적인 검색 알고리즘으로는 '이진 트리(binary tree)'가 있으며, 다음으로는 '해시'가 유명함.
이진 트리는 정확히 말하면 탐색 방법이라기보다는 데이터 구조에 가까움. 탐색 방법으로는 '이진 탐색(binary search)'이 됨.
풀 테이블 스캔 (full table scan)
인덱스가 지정되지 않은 테이블을 검색. 테이블에 저장된 모든 값을 처음부터 차례로 조사.
이진 탐색 (binary search)
차례로 나열된 집합에 대해 유효한 검색 방법. 집합을 반으로 나누어 조사.
이진 트리 (binary tree)
이진 탐색은 고속으로 검색할 수 있는 탐색 방법이지만 데이터가 미리 정렬되어 있어야 함.
일반적으로는 테이블에 인덱스를 작성하면 테이블 데이터와 별개로 인덱스용 데이터가 저장장치에 만들어짐. 이때 이진 트리라는 데이터 구조로 작성.
유일성
이진 트리에서는 집합 내에 중복하는 값을 가질 수 없음. 하지만, 이진 트리에서 '같은 값을 가지는 노드를 여러 개 만들 수 없다'라는 특성은 키에 대하여 유일성을 가지게 할 경우에만 유용. 그래서 기본키 제약은 이진 트리로 인덱스를 작성하는 데이터베이스가 많은 것 같음.
" 이진 트리에는 중복하는 값을 등록할 수 없다!"
인덱스 작성과 삭제
CREATE INDEX
DROP INDEX
인덱스는 데이터베이스 객체의 하나로 DDL을 사용해서 작성하거나 삭제.
인덱스 작성
CREATE INDEX 인덱스명 ON 테이블명 (열명1, 열명2, ...)
인덱스 삭제
스키마 객체의 경우
DROP INDEX 인덱스명
테이블 내 객체의 경우
DROP INDEX 인덱스명 ON 테이블명
EXPLAIN
인덱스 작성을 통해 쿼리의 성능 향상을 기대할 수 있음.
EXPLAIN SQL 명령
어떤 상태로 실행되는지를 데이터베이스가 설명.
최적화
실행계획에서는 인덱스의 유무뿐만 아니라 인덱스를 사용할 것인지 여부에 대해서도 데이터베이스 내부의 최적화 처리를 통해 판단. 이때 판단 기준으로 인덱스의 품질도 고려.
뷰 작성과 삭제
CREATE VIEW 뷰명 AS SELECT 명령
DROP VIEW 뷰명
뷰
SELECT 명령을 기록하는 데이터베이스 객체 중 하나. 복잡한 SQL 명령을 간략하게 표현할 수 있음.
가상 테이블
뷰는 테이블처럼 취급할 수 있지만 '실체가 존재하지 않는다'라는 의미로 '가상 테이블'이라 불리기도 함. 뷰는 테이블처럼 데이터를 쓰거나 지울 수 있는 저장공간을 가지지 않음. 따라서, SELECT 명령에서만 사용하는 것을 권장.
INSERT, DELETE, UPDATE 명령에서도 조건이 맞으면 가능하지만 사용에 주의할 필요가 있음.
뷰 작성과 삭제
DDL로 작성하거나 삭제. 작성할 때는 CREATE VIEW, 삭제할 때는 DROP VIEW.
뷰의 작성
CREATE VIEW 뷰명 AS SELECT 명령
뷰 삭제
DROP VIEW 뷰명
뷰의 약점
저장공간을 소비하지 않는 대신 CPU 자원을 사용.
머티리얼라이즈드 뷰(Materialized View)
처음 참조되었을 때 데이터를 저장해둠. 이후 다시 참조할 때 이전에 저장해 두었던 데이터를 그대로 사용. 뷰에 지정된 테이블의 데이터가 변경된 경우에는 SELECT 명령을 재실행하여 데이터를 다시 저장. 변경 유무를 확인하여 재실행하는 것은 RDBMS가 자동으로 실행.
MySQL에서는 사용할 수 없고, Oracle과 DB2에서만 사용 가능.
함수 테이블
뷰를 구성하는 SELECT 명령은 단독으로도 실행할 수 있어야 함. 이 약점을 함수 테이블을 사용하여 회피할 수 있음. 함수 테이블은 테이블을 결괏값으로 반환해주는 사용자정의 함수.
