

백업과 복구
보통 강제 종료에는 task manager를 이용하나, MySQL 서버는 애플리케이션이 아닌 서비스로 실행. 따라서, Windows 동작 중에는 계속 백그라운드에서 동작. 강제 종료하려면 프로세스 탭을 선택해 이미지 명(mysqld.exe)을 지정하든지 서비스 탭을 선택해 서비스 이름(MySQL57)을 지정.
지속성과 성능이 양립하는 구조
DBMS의 3가지 구조
DBMS에서 데이터를 보존하는 기억장치는 대부분 하드디스크. 데이터베이스의 쓰기는 기억장치의 임의 장소에 무작위로 액세스해서 쓰기를 수행하기 때문에 동기화 쓰기는 느려 성능 면에서 실용적이지 않음. 따라서, 다음 구조를 사용.
로그 선행 쓰기
데이터베이스의 데이터 파일 변경을 직접 수행하지 않고, 우선 로그로 변경 내용을 기술한 로그 레코드를 써서 동기화하는 구조. (InnoDB 로그)
1. 디스크에 연속해서 쓰기 때문에 무작위로 쓰는 것보다 성능이 좋다.
2. 디스크에 쓰는 용량과 횟수를 줄일 수 있다.
3. 데이터베이스 버퍼를 이용해 데이터베이스의 데이터 파일로의 변경을 효율성 높게 수행한다.
데이터베이스 버퍼
- 갱신 대상의 데이터를 포함한 페이지가 버퍼 풀에 있는지를 확인하고 없다면 데이터 파일로부터 읽어 들인다.
- 버퍼 풀의 해당 페이지에서 갱신을 수행한다.
- 2의 갱신 내용이 커밋과 함께 로그에 기록된다. 버퍼 풀에 갱신되었지만, 아직 데이터 파일에 써지지 않은 페이지는 버퍼 풀 내에서 더티 페이지로 다룬다.
- 4의 체크포인트 이전 로그 파일은 불필요해진다. 또한, 갱신과 더불어 1부터 순서가 반복된다.
- 더티 페이지는 일반적으로 메모리로 읽어서 갱신된 페이지를 가르킴.
크래시 복구
크래시가 발생하면...
1. WAL
마지막으로 커밋된 트랜잭션의 갱신 정보를 가짐
2. 데이터베이스 버퍼
크래시로 내용이 전부 소실
3. 데이터베이스 파일
최후 체크포인트까지의 갱신 정보를 가짐
크래시 이후 MySQL 서버를 재시작하면 3과 1의 체크포인트 이후 갱신 정보를 사용해 데이터베이스 파일을 크래시 때까지 커밋된 최신 상태로 수정. 이 동작을 롤 포워드(Roll-Forward)라고 함.
백업과 복구
PITR이란
임의의 시점에서의 데이터 변경을 포함한 복원을 PITR(Point-in-time Recovery)라고 함.
PITR에 이용하는 로그는 대부분 WAL을 이용.
크래시 복구용으로는 불필요한 로그도 PITR용으로 보존이 필요할 수 있으며 이를 위한 모드가 '아카이브 지정'.
바이너리 로그란
MySQL에서는 PITR에 바이너리 로그, 크래시 복구에 InnoDB 로그를 이용.
백업의 3가지 관점
- 핫 백업과 콜드 백업
- 논리 백업과 물리 백업
- 풀 백업과 부분(증분/차등) 백업
핫 백업과 콜드 백업
핫 백업
온라인 백업, 백업 대상의 데이터베이스를 정지하지 않고 가동한 채로 백업 데이터를 얻음.
콜드 백업
오프라인 백업, 백업 대상의 데이터베이스를 정지한 후 백업 데이터를 얻음.
논리 백업과 물리 백업
논리 백업은 SQL 기반 텍스트 형식으로 백업 데이터가 기록.
물리 백업은 데이터 영역을 그대로 덤프하는 이미지로 바이너리 형식으로 기록.
풀 백업과 부분 백업
풀 백업은 전체 백업, 데이터베이스 전체 데이터를 매일 백업하는 방식.
부분 백업은 우선 풀 백업을 한 후에 이후 갱신된 데이터를 백업.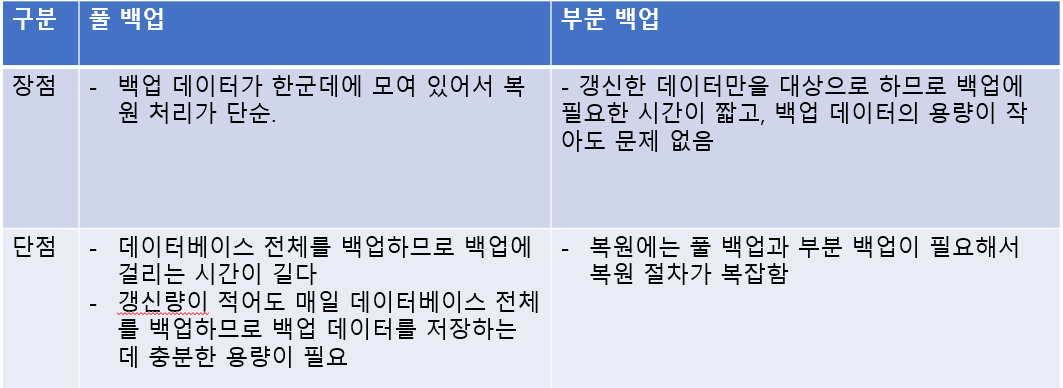
부분 백업의 2가지 방법
차등 백업은 최근에 풀 백업한 이후에 갱신된 데이터를 백업하는 것.
증분 백업은 최근 백업(풀 백업에 한정되지 않음)한 이후에 갱신된 데이터를 백업하는 것.
증분 백업은 데이터의 양이 차등 백업보다 적으나, 복원 시 모든 증분 백업을 차례로 적용해야 해서 절차가 복잡함.
롤 포워드 리커버리
현재의 데이터 베이스 = 풀 백업한 데이터 + 풀 백업 후 얻은 모든 증분 백업
데이터베이스 관리 시 주의점
데이터베이스와 백업 데이터를 다른 디스크 장치로 나눠 보관해야 함. 장애 대비 방법을 선택할 때, 상황에 맞게 백업 방식을 고려.
복수의 테이블 다루기
집합 연산
UNION으로 합집합 구하기
U, 합집합, 공통된 요소를 출력.
UNION 명령어를 사용.
SELECT * FROM sample71_a;
| a |
|---|
| 1 |
| 2 |
| 3 |
SELECT * FROM sample71_b;
| a |
|---|
| 2 |
| 10 |
| 11 |
SELECT * FROM sample71_a UNION SELECT * FROM sample71_b;
| a |
|---|
| 1 |
| 2 |
| 3 |
| 10 |
| 11 |
UNION ORDER BY
가장 마지막 SELECT 명령에 대해서만 ORDER BY 구를 지정 가능함.
ORDER BY 구에 지정하는 열은 별명을 붙여 이름을 일치시킴.
UNION ALL
보통 UNION 명령을 사용하게 되면 중복된 값은 제거하고 하나로만 출력하게 되는 DISTINCT 명령의 기질이 있음.
만약, 이때 중복된 값들은 제거하지 말고 모두 출력하고 싶을 때는 UNION 대신 UNION ALL을 사용하면 됨.
교집합과 차집합
SQL을 기준으로 교집합은 INTERSECT, 차집합은 EXCEPT를 사용.
테이블 결합
곱집합과 교차결합
곱집합
합집합이나 교집합처럼 집합의 연산 방법 중 하나, 두 개의 집합을 곱하는 연산 방법.
'직접 합' 또는 '카티전곱(Cartesian product)'로 불림.
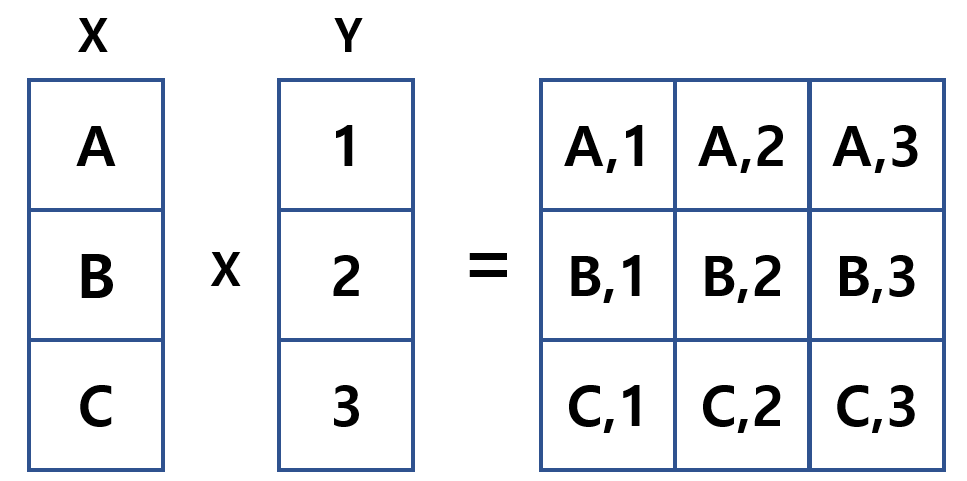
교차결합
데이터베이스의 테이블은 집합의 한 종류. 만약 테이블을 두 개 지정하면 이들은 곱집합으로 계산.
SELECT * FROM 테이블명1, 테이블명2;
UNION 연결과 결합 연결의 차이
두 가지 방식이 서로 비슷하다만 확대 방향이 다름.
UNION으로 합집합을 구했을 경우에는 세로 방향으로 더해짐.
FROM 구로 테이블을 결합할 경우에는 가로 방향으로 확대.
내부결합, INNER JOIN
교차결합은 테이블 수가 많아지면 조합 수가 집합이 거대해짐. 따라서, 결합 방법으로는 교차결합보다는 내부결합이 더 많이 사용됨.
테이블을 연결하여 사용하는데, 이때 기본키를 지정해두는 것이 좋음.
(참조할 테이블의 기본키와 동일한 이름과 자료형으로 행을 연결)
WHERE 조건을 지정해 곱집합에서 필요한 조합만 검색.
SELECT * FROM 테이블명1 INNER JOIN 테이블명2 ON 결합조건 (WHERE구);
내부 결합을 활용한 데이터 관리
외부키
다른 테이블의 기본키를 참조하는 열
자기결합 (Self Join)
테이블에 별명을 붙일 수 있는 기능을 이용해 같은 테이블끼리 결합하는 것
외부 결합
외부결합은 교차결합으로 결합 조건을 지정하여 검색한다는 기본적인 것은 내부결합과 같음. 다만, 어느 한쪽에만 존재하는 데이터 행을 어떻게 다룰지를 변경할 수 있음.
만약 A 테이블에 존재하는 값이 아직 B 테이블에 존재하지 않는다면 LEFT JOIN을 이용해, A 테이블에 기준을 맞출 수 있음.
이 경우, A 테이블에 존재하는 값에 대해서는 B 테이블은 NULL로 표시.
| A | B |
|---|---|
| 추가상품 | NULL |
SELECT 상품3.상품명, 재고수.재고수
FROM 상품3 LEFT JOIN 재고수
ON 상품3.상품코드=재고수.상품코드
WHERE 상품3.상품분류 = '식료품';오른쪽 테이블을 기준으로 삼고 싶은 경우에는 RIGHT JOIN 이용.
